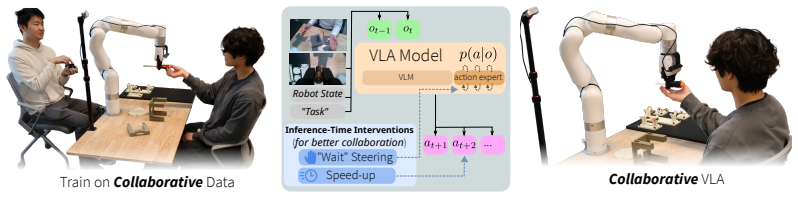
Learning to Assist: Collaborative VLAs for Implicit Human-Robot Collaboration
Pith reviewed 2026-06-27 09:55 UTC · model grok-4.3
The pith
Vision-language-action models support implicit human-robot collaboration when inference-time steering corrects premature assistance caused by action chunking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
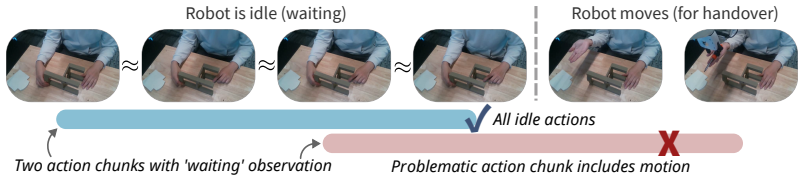
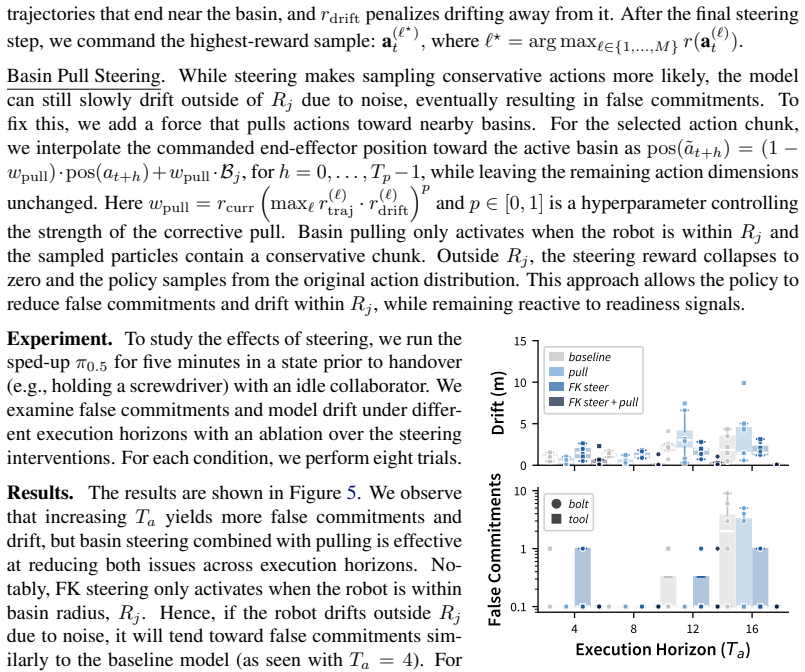
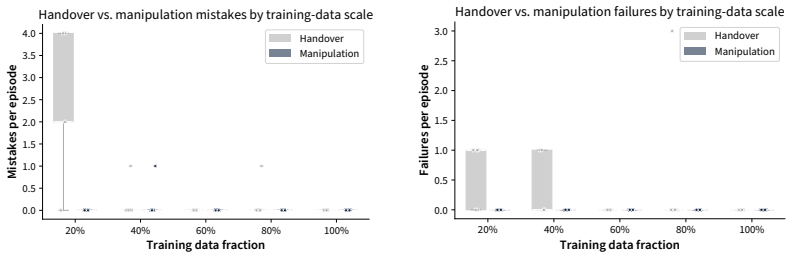
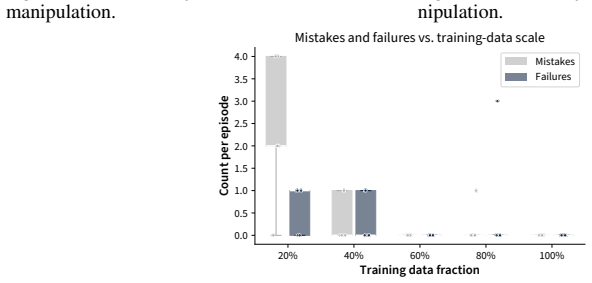
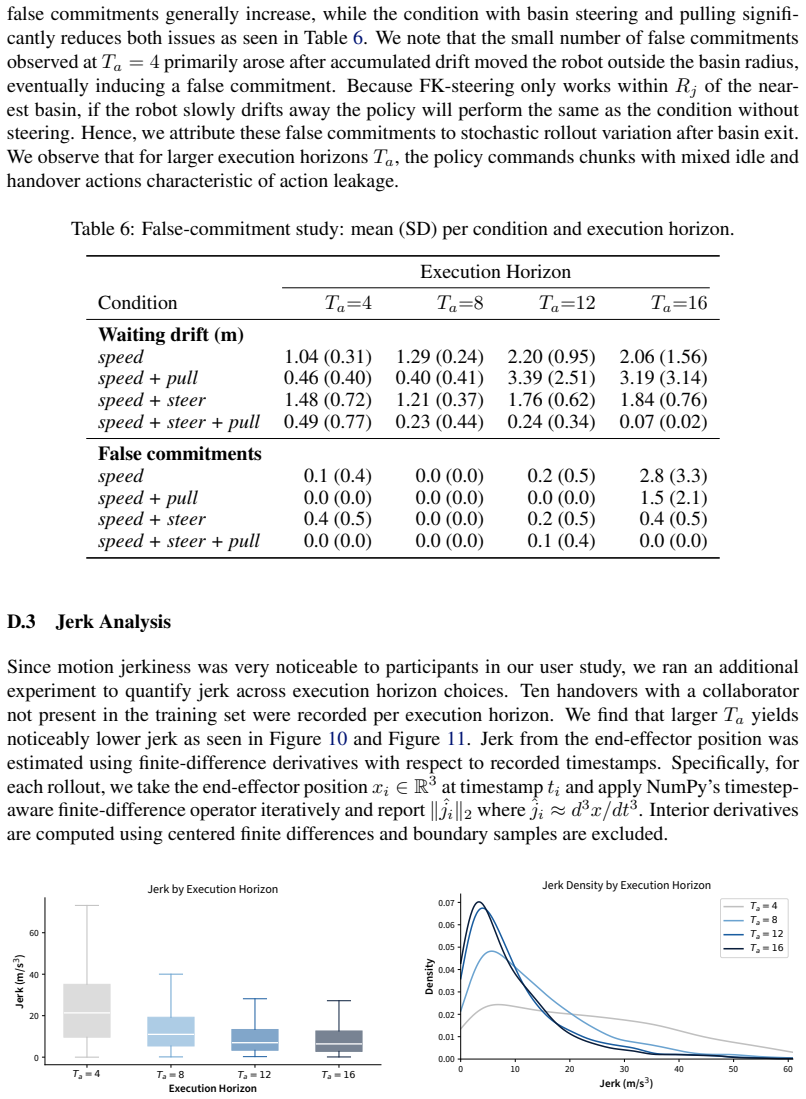
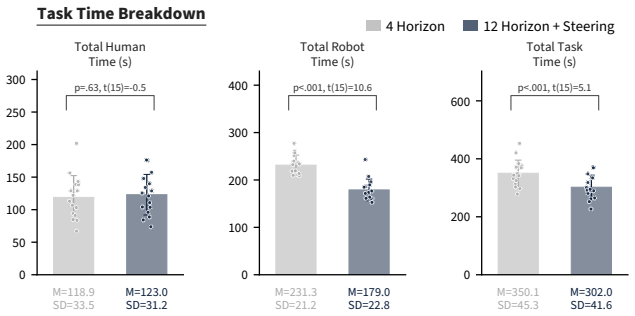
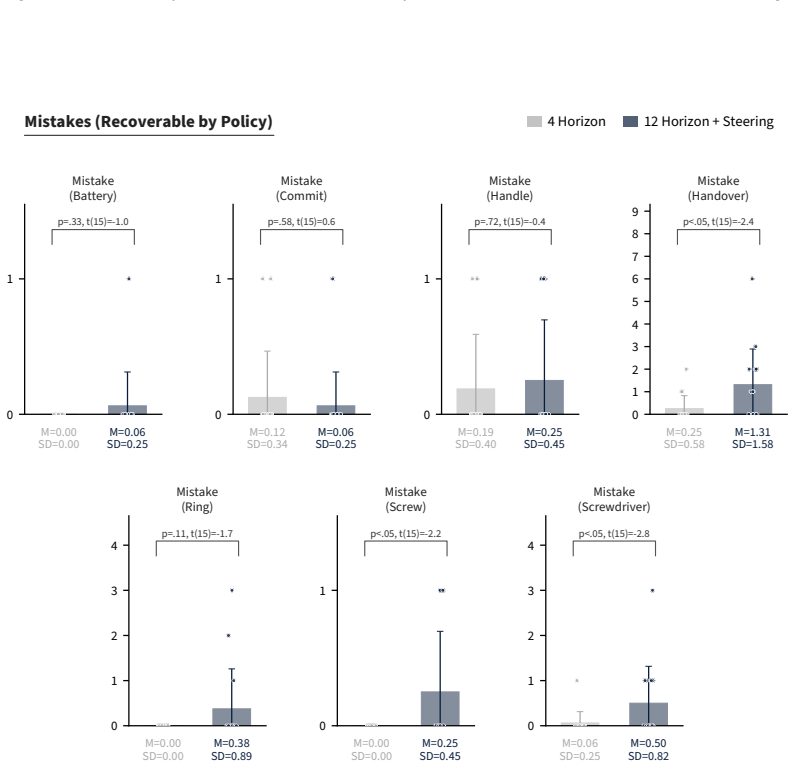
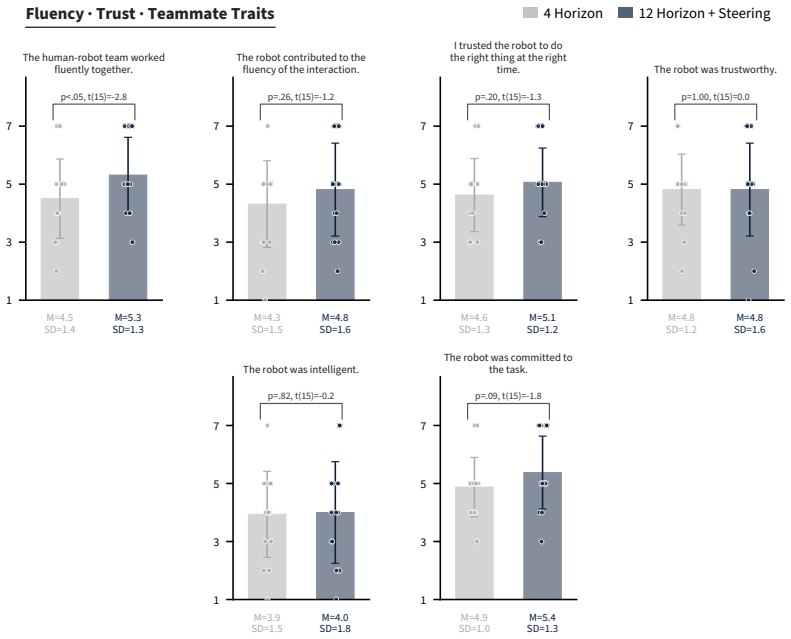
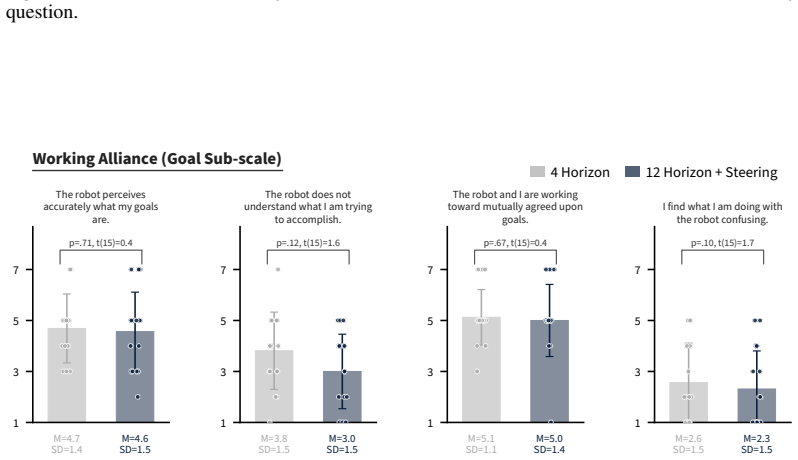
Models trained end-to-end with imitation learning on vision-language-action data can support collaborative manipulation. Action-chunking policies exhibit a failure mode in which demonstration action leakage across latent task transitions produces premature assistive behavior. This issue grows with longer execution horizons and appears in real-world settings. An inference-time steering method mitigates the erroneous actions without degrading performance on the target distribution. In a 16-participant user study on a long-horizon collaborative assembly task, steering permits longer horizons that produce faster collaboration and fewer failures than a shorter-horizon policy.
What carries the argument
Inference-time steering applied to action-chunking VLA policies to suppress premature assistive actions arising from demonstration action leakage.
If this is right
- Longer execution horizons become usable in collaborative VLA systems without raising rates of premature assistance.
- End-to-end imitation learning is sufficient for implicit human-robot collaboration in manipulation tasks.
- Real-world VLA systems can avoid premature tool handovers and similar errors through the steering adjustment.
- The leakage failure mode is tied directly to chunk length and appears consistently across evaluated models.
Where Pith is reading between the lines
- The steering approach could extend to other sequential prediction settings where training data contains predictable future states that a model might over-anticipate.
- Online monitoring of human readiness signals might be combined with steering to handle more variable partner behavior.
- Applying the correction during training rather than only at inference could reduce the need for post-hoc adjustments in new tasks.
Load-bearing premise
That demonstration action leakage across latent transitions is the dominant source of premature assistance and that steering corrects it without introducing new failure modes or reducing performance on the intended tasks.
What would settle it
A user study result in which the steered longer-horizon policy produces more failures or slower task times than the unsteered shorter-horizon baseline would falsify the performance benefit.
Figures



read the original abstract
Human-robot collaboration (HRC) combines the complementary strengths of humans and robots to improve task efficiency. However, many existing collaborative systems rely on hand-engineered pipelines, limiting their scalability and flexibility for new tasks. In this work, we show that models trained end-to-end with imitation learning, specifically vision-language-action (VLA) models, can support collaborative manipulation, and characterize the key factors affecting their real-world performance. We evaluate two state-of-the-art models and identify a failure mode of action-chunking policies in implicit HRC, where demonstration action leakage (i.e., action chunks crossing latent task transitions) can cause premature assistive behavior. We find that this issue increases with longer execution horizons and occurs in real-world collaborative VLA systems, such as when a robot attempts to hand over a tool before the person is ready. We propose an inference-time steering method to mitigate these erroneous assistive actions while preserving policy performance. Finally, through a 16-participant user study on a long-horizon collaborative assembly task, we show that steering enables a longer execution horizon while mitigating premature assistance, leading to faster collaboration and fewer failures compared to a shorter-horizon policy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vision-language-action (VLA) models trained end-to-end via imitation learning can enable implicit human-robot collaboration. It identifies demonstration action leakage in action-chunking policies as causing premature assistance (increasing with longer horizons), proposes an inference-time steering method to mitigate this while preserving performance, and reports that a 16-participant user study on a long-horizon assembly task shows steering yields faster collaboration and fewer failures than a shorter-horizon baseline.
Significance. If validated, the work shows a path to scalable learned HRC without hand-engineered pipelines by diagnosing and correcting a specific failure mode of chunked VLAs. The identification of leakage across latent transitions and the steering intervention, together with the real-world user study, would be a concrete contribution to making imitation-learned policies viable for collaborative manipulation.
major comments (2)
- [User study / empirical evaluation] User study (abstract and empirical evaluation): the 16-participant study is presented as showing quantitative gains from steering, yet reports no error bars, statistical tests, details on steering implementation, or data-collection protocol. This leaves the central empirical claim without verifiable support for robustness or effect size.
- [Proposed inference-time steering] Steering method description: the claim that steering removes leakage-induced premature assistance without new failure modes or capability loss on the target distribution rests on the unablated user-study outcomes. No controlled isolation (e.g., synthetic trajectories with known transition points or ablation on non-leakage rollouts) is described to establish that leakage is the dominant driver or that steering specifically corrects it.
minor comments (1)
- [Abstract / Method] The abstract and method sections should explicitly name the two state-of-the-art VLA models evaluated and the precise metrics (e.g., task completion time, failure types) used to quantify "faster collaboration and fewer failures."
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional details and analysis would strengthen the empirical claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [User study / empirical evaluation] User study (abstract and empirical evaluation): the 16-participant study is presented as showing quantitative gains from steering, yet reports no error bars, statistical tests, details on steering implementation, or data-collection protocol. This leaves the central empirical claim without verifiable support for robustness or effect size.
Authors: We agree that these details are necessary to support the claims. In the revised manuscript we will add error bars to all user-study metrics, report statistical tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values), provide the precise implementation details and hyperparameters of the inference-time steering procedure, and expand the experimental protocol section with participant demographics, recruitment, consent, task instructions, and data-collection procedures. These additions will be placed in the empirical evaluation section and will allow readers to assess robustness and effect sizes directly. revision: yes
-
Referee: [Proposed inference-time steering] Steering method description: the claim that steering removes leakage-induced premature assistance without new failure modes or capability loss on the target distribution rests on the unablated user-study outcomes. No controlled isolation (e.g., synthetic trajectories with known transition points or ablation on non-leakage rollouts) is described to establish that leakage is the dominant driver or that steering specifically corrects it.
Authors: The primary validation in the paper is the real-world 16-participant study because that is the target setting for implicit collaboration. We acknowledge, however, that the manuscript does not include controlled ablations isolating leakage. In revision we will add an analysis subsection (or appendix) that applies the steering method to held-out demonstration trajectories with annotated transition points to quantify its effect on premature actions. If space constraints prevent a full new experiment, we will explicitly note this as a limitation while retaining the user-study results as the main evidence. revision: partial
Circularity Check
No circularity: results from independent training and user study
full rationale
The paper reports empirical outcomes from end-to-end VLA training plus a 16-participant user study comparing steered longer-horizon policies against shorter-horizon baselines. No equations, fitted parameters, or derivations are shown that reduce the claimed performance gains (faster collaboration, fewer failures) to quantities defined or fitted on the same data. Failure-mode identification and steering proposal are presented as observations, not self-referential constructions. No load-bearing self-citations or uniqueness theorems appear in the provided text. This is the common case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ajoudani, A
A. Ajoudani, A. M. Zanchettin, S. Ivaldi, A. Albu-Sch ¨affer, K. Kosuge, and O. Khatib. Progress and prospects of the human–robot collaboration.Autonomous robots, 42(5):957–975, 2018
2018
-
[2]
Rrapi, B
F. Rrapi, B. Portelli, G. Serra, and L. Scalera. From ai foundations to large language models: A survey on challenges and opportunities in collaborative robotics.Robotics and Computer- Integrated Manufacturing, 100:103269, 2026
2026
-
[3]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[4]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[5]
Dasari, O
S. Dasari, O. Mees, S. Zhao, M. K. Srirama, and S. Levine. The ingredients for robotic dif- fusion transformers. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15617–15625. IEEE, 2025
2025
-
[6]
E. E. Entin and D. Serfaty. Adaptive team coordination.Human factors, 41(2):312–325, 1999
1999
-
[7]
R. Rico, M. S ´anchez-Manzanares, F. Gil, and C. Gibson. Team implicit coordination processes: A team knowledge–based approach.Academy of management review, 33(1):163–184, 2008
2008
-
[8]
B. D. Argall, S. Chernova, M. Veloso, and B. Browning. A survey of robot learning from demonstration.Robotics and autonomous systems, 57(5):469–483, 2009
2009
-
[9]
Kawaharazuka, J
K. Kawaharazuka, J. Oh, J. Yamada, I. Posner, and Y . Zhu. Vision-language-action models for robotics: A review towards real-world applications.IEEE Access, 2025
2025
-
[10]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[11]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[12]
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video- action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025
Pith/arXiv arXiv 2025
-
[13]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[14]
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021. 9
Pith/arXiv arXiv 2021
-
[15]
Hagenow, M
M. Hagenow, M. Selvaggio, X. Yu, Y . Wang, Y . Demiris, A. Bobu, Y . Du, H. Soh, D. Losey, and J. Shah. Shared control/autonomy: A historical perspective, current trends, and the role of generative ai.Authorea Preprints, 2025
2025
-
[16]
L. X. Shi, Z. Hu, T. Z. Zhao, A. Sharma, K. Pertsch, J. Luo, S. Levine, and C. Finn. Yell at your robot: Improving on-the-fly from language corrections.arXiv preprint arXiv:2403.12910, 2024
arXiv 2024
-
[17]
F. Lin, R. Nai, Y . Hu, J. You, J. Zhao, and Y . Gao. Onetwovla: A unified vision-language-action model with adaptive reasoning.arXiv preprint arXiv:2505.11917, 2025
arXiv 2025
-
[18]
Y . Chen, K. Gu, Y . Wen, Y . Zhao, T. Wang, and L. Nie. Intentionvla: Generalizable and efficient embodied intention reasoning for human-robot interaction.arXiv preprint arXiv:2510.07778, 2025
arXiv 2025
-
[19]
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language- action models.arXiv preprint arXiv:2502.19417, 2025
Pith/arXiv arXiv 2025
- [20]
-
[21]
L. Sun, J. Ji, X. Tan, and M. Walter. Flashback: Consistency model-accelerated shared auton- omy. InConference on Robot Learning, pages 924–940. PMLR, 2025
2025
-
[22]
A. Wang, X. Yan, B. McMahan, M. Zhou, Y . Yuan, J. Y . Lee, A. Shreif, M. Li, Z. Peng, B. Zhou, et al. Disco: Diffusion sequence copilots for shared autonomy. InProceedings of the 21st ACM/IEEE International Conference on Human-Robot Interaction, pages 982–990, 2026
2026
-
[23]
T. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.Robotics: Science and Systems XIX, 2023
2023
-
[24]
D. Jing, G. Wang, J. Liu, W. Tang, Z. Sun, Y . Yao, Z. Wei, Y . Liu, Z. Lu, and M. Ding. Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
Pith/arXiv arXiv 2025
-
[25]
H. Wang, G. Zhang, Y . Yan, R. R. Kompella, and G. Liu. Vla knows its limits.arXiv preprint arXiv:2602.21445, 2026
Pith/arXiv arXiv 2026
-
[26]
Matheson, R
E. Matheson, R. Minto, E. G. Zampieri, M. Faccio, and G. Rosati. Human–robot collaboration in manufacturing applications: a review.Robotics, 8(4):100, 2019
2019
-
[27]
J. A. Marvel, S. Bagchi, M. Zimmerman, and B. Antonishek. Towards effective interface designs for collaborative hri in manufacturing: Metrics and measures.ACM Transactions on Human-Robot Interaction (THRI), 9(4):1–55, 2020
2020
-
[28]
Ortenzi, A
V . Ortenzi, A. Cosgun, T. Pardi, W. P. Chan, E. Croft, and D. Kuli ´c. Object handovers: a review for robotics.IEEE Transactions on Robotics, 37(6):1855–1873, 2021
2021
-
[29]
Hoffman, M
G. Hoffman, M. Cakmak, and C. Chao. Timing in human-robot interaction. InProceedings of the 2014 ACM/IEEE international conference on Human-robot interaction, pages 509–510, 2014
2014
-
[30]
D. P. Losey, C. G. McDonald, E. Battaglia, and M. K. O’Malley. A review of intent detection, arbitration, and communication aspects of shared control for physical human–robot interaction. Applied Mechanics Reviews, 70(1):010804, 2018
2018
-
[31]
Candon, Q
K. Candon, Q. Zhang, A. Lew, H. Claure, L. Qian, A. Quarles, C. Sarkar, and M. V ´azquez. Learning human preferences over a human-robot collaboration based on explicit and implicit human feedback. InProceedings of the 21st ACM/IEEE International Conference on Human- Robot Interaction, pages 1040–1049, 2026. 10
2026
-
[32]
Zhong, B
R. Zhong, B. Hu, Z. Liu, Q. Qin, Y . Feng, X. V . Wang, L. Wang, and J. Tan. A two-stage framework for learning human-to-robot object handover policy from 4d spatiotemporal flow. Robotics and Computer-Integrated Manufacturing, 98:103171, 2026
2026
-
[33]
A. Cuellar, M. Hagenow, and J. Shah. Multi-cycle spatio-temporal adaptation in human-robot teaming.arXiv preprint arXiv:2604.19670, 2026
Pith/arXiv arXiv 2026
-
[34]
J. F. Fisac, A. Bajcsy, S. L. Herbert, D. Fridovich-Keil, S. Wang, C. J. Tomlin, and A. D. Dragan. Probabilistically safe robot planning with confidence-based human predictions.arXiv preprint arXiv:1806.00109, 2018
Pith/arXiv arXiv 2018
-
[35]
S. Li, N. Figueroa, A. Shah, and J. Shah. Provably safe and efficient motion planning with uncertain human dynamics. 2021
2021
-
[36]
Cuellar, C
A. Cuellar, C. K. Fourie, and J. A. Shah. An alignment-based approach to learning motions from demonstrations.IEEE Robotics and Automation Letters, 2025
2025
-
[37]
Huang, M
C.-M. Huang, M. Cakmak, and B. Mutlu. Adaptive coordination strategies for human-robot handovers. InRobotics: science and systems, volume 11, pages 1–10. Rome, Italy, 2015
2015
-
[38]
M. Kim, S. Yang, B. Kim, J. Kim, and D. Kim. Human-to-robot handover based on reinforce- ment learning.Sensors, 24(19):6275, 2024
2024
-
[39]
H. Duan, P. Wang, Y . Li, D. Li, and W. Wei. Learning human-to-robot dexterous handovers for anthropomorphic hand.IEEE Transactions on Cognitive and Developmental Systems, 15 (3):1224–1238, 2022
2022
-
[40]
E. Ng, Z. Liu, and M. Kennedy. Diffusion co-policy for synergistic human-robot collaborative tasks.IEEE Robotics and Automation Letters, 9(1):215–222, 2023
2023
-
[41]
S. Li, J. Wang, R. Dai, W. Ma, W. Y . Ng, Y . Hu, and Z. Li. Robonurse-vla: Robotic scrub nurse system based on vision-language-action model. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3986–3993. IEEE, 2025
2025
-
[42]
B. An, C. Yang, and R. Katzschmann. Robotic assistant: Completing collaborative tasks with dexterous vision-language-action models.arXiv preprint arXiv:2510.25713, 2025
arXiv 2025
-
[43]
X. Wang, X. Dengxiong, S. Bai, P. Zheng, and Y . Zhang. Vlabot: A human vision–language– action models interaction framework for robotic assembly.Robotics and Computer-Integrated Manufacturing, 100:103268, 2026
2026
-
[44]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[45]
Barreiros, A
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eaea6201, 2026
2026
-
[46]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[47]
Brown, W
D. Brown, W. Goo, P. Nagarajan, and S. Niekum. Extrapolating beyond suboptimal demon- strations via inverse reinforcement learning from observations. InInternational conference on machine learning, pages 783–792. PMLR, 2019. 11
2019
-
[48]
J. Tang, Y . Sun, Y . Zhao, S. Yang, Y . Lin, Z. Zhang, J. Hou, Y . Lu, Z. Liu, and S. Han. Vlash: Real-time vlas via future-state-aware asynchronous inference.arXiv preprint arXiv:2512.01031, 2025
arXiv 2025
-
[49]
N. R. Arachchige, Z. Chen, W. Jung, W. C. Shin, R. Bansal, P. Barroso, Y . H. He, Y . C. Lin, B. Joffe, S. Kousik, et al. Sail: Faster-than-demonstration execution of imitation learning policies.arXiv preprint arXiv:2506.11948, 2025
arXiv 2025
-
[50]
R. Singhal, Z. Horvitz, R. Teehan, M. Ren, Z. Yu, K. McKeown, and R. Ranganath. A gen- eral framework for inference-time scaling and steering of diffusion models.arXiv preprint arXiv:2501.06848, 2025
arXiv 2025
-
[51]
Fukunaga and L
K. Fukunaga and L. Hostetler. The estimation of the gradient of a density function, with applications in pattern recognition.IEEE Transactions on information theory, 21(1):32–40, 1975
1975
-
[52]
S. G. Hart. Nasa-task load index (nasa-tlx); 20 years later. InProceedings of the human factors and ergonomics society annual meeting, volume 50, pages 904–908. Sage publications Sage CA: Los Angeles, CA, 2006
2006
-
[53]
Brooke et al
J. Brooke et al. Sus-a quick and dirty usability scale.Usability evaluation in industry, 189 (194):4–7, 1996
1996
-
[54]
G. Hoffman. Evaluating fluency in human–robot collaboration.IEEE Transactions on Human- Machine Systems, 49(3):209–218, 2019
2019
-
[55]
A. D. Dragan, K. C. Lee, and S. S. Srinivasa. Legibility and predictability of robot motion. In2013 8th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 301–308. IEEE, 2013
2013
-
[56]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic ma- nipulation.arXiv preprint arXiv:2508.19236, 2025
Pith/arXiv arXiv 2025
- [57]
-
[58]
Y . Hu, J.-N. Zaech, N. Nikolov, Y . Yao, S. Dey, G. Albanese, R. Detry, L. Van Gool, and D. Paudel. Ar-vla: True autoregressive action expert for vision-language-action models.arXiv preprint arXiv:2603.10126, 2026
Pith/arXiv arXiv 2026
-
[59]
Swamy, S
G. Swamy, S. Choudhury, D. Bagnell, and S. Wu. Causal imitation learning under tempo- rally correlated noise. InInternational Conference on Machine Learning, pages 20877–20890. PMLR, 2022
2022
-
[60]
K. Mark, L. Galustian, M. P.-P. Kovar, and E. Heid. Feynman-kac-flow: Inference steering of conditional flow matching to an energy-tilted posterior.arXiv preprint arXiv:2509.01543, 2025
arXiv 2025
-
[61]
Bangor, P
A. Bangor, P. T. Kortum, and J. T. Miller. An empirical evaluation of the system usability scale. Intl. Journal of Human–Computer Interaction, 24(6):574–594, 2008. 12 A Model Architecture and Training For all policies, while demonstrations were recorded at 20 Hz, all training was done with a down- sampled 10 Hz feed and images resized to224×224pixels. We ...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.