Missing-Token Prompted Reliability-Aware Fusion for Robust Polyglot Speaker Identification
Pith reviewed 2026-06-27 08:10 UTC · model grok-4.3
The pith
A learnable missing token for absent faces combined with reliability-aware cross-attention achieves perfect accuracy on some polyglot speaker identification tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
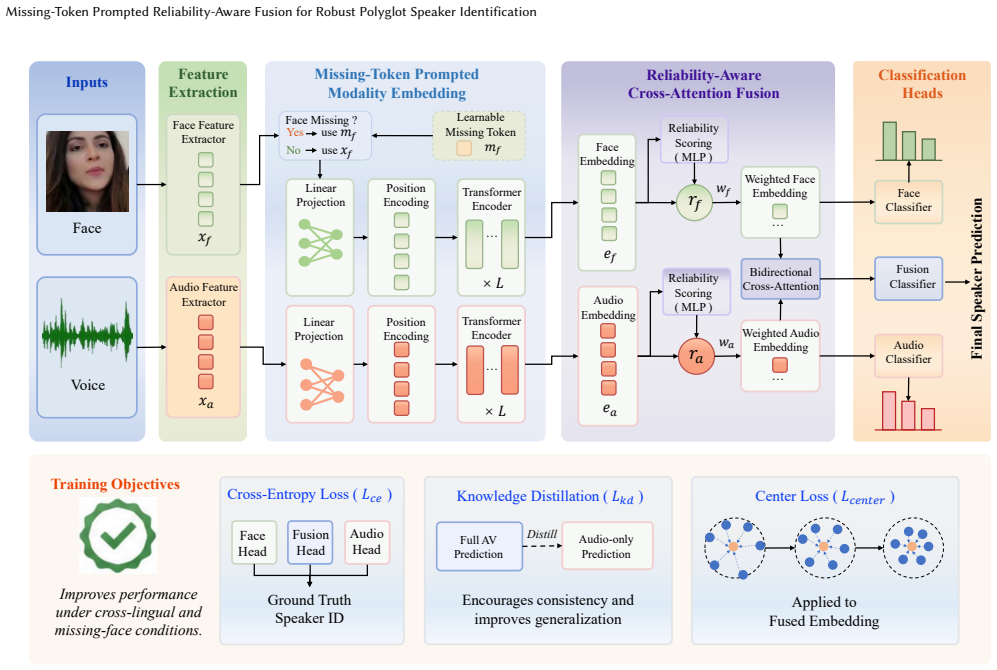
MRAF represents unavailable face inputs with a learnable missing token rather than fixed zero-valued features. This reduces the distribution gap and lets reliability estimation and cross-modal fusion operate inside one token space. A reliability-aware cross-attention module computes face and audio reliability scores, normalizes them into weights, and applies the weights to the token representations before bidirectional cross-attention. Joint optimization of multi-branch classification losses, audio-only knowledge distillation, and center loss produces the final model. On the POLY-SIM 2026 test set the approach reaches 100 percent accuracy on protocols P3 and P5 while remaining competitive on
What carries the argument
The learnable missing token that stands in for absent face features, paired with a reliability-aware cross-attention module that derives modality weights from estimated reliability scores and applies them before fusion.
If this is right
- Speaker identification remains reliable when face input is absent by shifting emphasis to audio through the reliability weights.
- The framework supports operation across complete-modality, missing-face, and cross-lingual scenarios on the same model.
- Joint training with classification, distillation, and center losses improves both speaker discrimination and missing-modality handling.
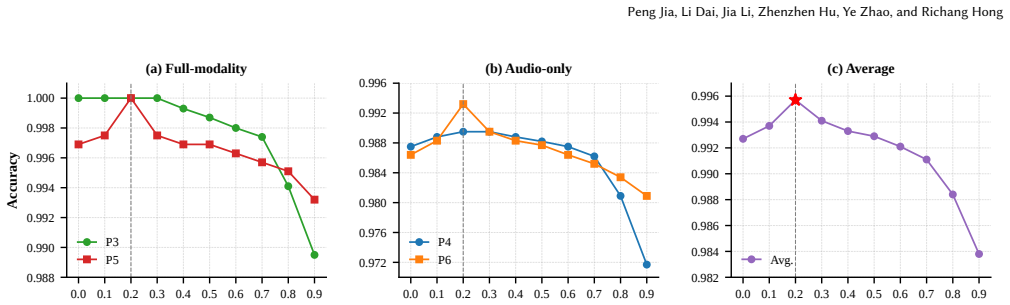
- The method reaches 100 percent accuracy on P3 and P5 while staying competitive on P4 and P6.
Where Pith is reading between the lines
- The missing-token approach could be tested on other modality pairs where one stream is prone to dropout.
- Biometric systems that must function without constant camera access might adopt similar reliability weighting.
- Varying the set of languages in evaluation would help check how far the cross-lingual performance generalizes.
- The unified token space created by the missing token might allow simpler addition of further input types.
Load-bearing premise
That a single learnable missing token can provide a trainable representation of the missing visual state that reduces distribution gap enough for the reliability estimation and cross-attention to operate effectively in a unified token space.
What would settle it
An ablation that swaps the learnable missing token for fixed zero features and measures whether accuracy falls sharply on the missing-face protocols P4 and P6 would test whether the token is necessary for the claimed robustness.
Figures

read the original abstract
Accurate and robust multimodal speaker identification is essential for multimedia understanding and biometric authentication. However, real-world polyglot scenarios pose two key challenges: speaker-discriminative representations should generalize across languages, and the model should remain reliable when face information is unavailable. To address these challenges, we propose MRAF, a Missing-Token Prompted Reliability-Aware Fusion framework for polyglot speaker identification across complete-modality, missing-face, and cross-lingual scenarios. MRAF represents unavailable face inputs with a learnable missing token instead of fixed zero-valued features, providing a trainable representation of the missing visual state. This design reduces the distribution gap caused by missing inputs and allows subsequent reliability estimation and cross-modal fusion to operate within a unified token space. To adaptively integrate modalities with different reliability, MRAF further introduces a reliability-aware cross-attention fusion module, which estimates face and audio reliability scores, normalizes them into modality weights, and applies these weights to token representations before bidirectional cross-attention. In this way, the model can emphasize reliable modality cues while suppressing unreliable ones. During training, MRAF jointly optimizes multi-branch classification losses, audio-only knowledge distillation, and center loss to improve speaker discrimination and missing-modality robustness. Experiments on the official POLY-SIM 2026 test set demonstrate the effectiveness of the proposed framework. In the final evaluation, MRAF achieves 100% accuracy on P3 and P5, and obtains competitive results on the more challenging missing-face settings P4 and P6. The source code will be released at https://github.com/MSA-LMC/MRAF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MRAF, a Missing-Token Prompted Reliability-Aware Fusion framework for polyglot speaker identification. It replaces missing face inputs with a learnable missing token to reduce distribution shift, employs reliability-aware cross-attention to weight modalities, and optimizes multi-branch classification losses plus audio distillation and center loss. On the official POLY-SIM 2026 test set, MRAF reports 100% accuracy on protocols P3 and P5 with competitive results on the missing-face protocols P4 and P6.
Significance. If the reported accuracies hold under the described training and inference procedures, the work offers a practical approach to robust multimodal biometrics in cross-lingual and missing-modality settings. The explicit plan to release source code at the cited GitHub repository is a positive contribution to reproducibility.
minor comments (1)
- [Abstract] Abstract: performance numbers are stated without any reference to the number of runs, statistical tests, or baseline comparisons; a one-sentence summary of the evaluation protocol would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical multimodal fusion framework (MRAF) with a learnable missing token, reliability-aware cross-attention, and joint training losses, then reports test-set accuracies on POLY-SIM 2026 protocols. No equations, derivations, fitted-parameter predictions, or self-citation chains appear in the abstract or described content. The central claims are performance numbers obtained from held-out evaluation rather than any reduction of outputs to inputs by construction. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable missing token parameters
invented entities (1)
-
missing token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
John Arevalo, Thamar Solorio, Manuel Montes-y Gómez, and Fabio A González
-
[2]
Gated multimodal units for information fusion.arXiv preprint arXiv:1702.01992(2017)
Pith/arXiv arXiv 2017
-
[3]
Massa Baali, Sarthak Bisht, Francisco Teixeira, Kateryna Shapovalenko, Rita Singh, and Bhiksha Raj. 2025. SVeritas: Benchmark for Robust Speaker Verifica- tion under Diverse Conditions. InFindings of the Association for Computational Linguistics: EMNLP 2025. 9714–9731
2025
-
[4]
Jiajun Chen, Sai Cheng, Yuan Yutao, Yirui Zhang, Haitao Yuan, Peng Peng, and Yi Zhong. 2026. PROMISE: Prompt-Attentive Hierarchical Contrastive Learning for Robust Cross-Modal Representation with Missing Modalities. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 20076–20082
2026
-
[5]
Yin Chen, Jia Li, Shiguang Shan, Meng Wang, and Richang Hong. 2024. From Static to Dynamic: Adapting Landmark-Aware Image Models for Facial Expres- sion Recognition in Videos.IEEE Transactions on Affective Computing(2024), 1–15. doi:10.1109/TAFFC.2024.3453443
-
[6]
Yin Chen, Jia Li, Yu Zhang, Zhenzhen Hu, Shiguang Shan, Meng Wang, and Richang Hong. 2025. Static for Dynamic: Towards a Deeper Understanding of Dynamic Facial Expressions Using Static Expression Data.IEEE Transactions on Affective Computing(2025), 1–15. doi:10.1109/TAFFC.2025.3623135 Missing-Token Prompted Reliability-Aware Fusion for Robust Polyglot Spe...
-
[7]
Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. 2018. VoxCeleb2: Deep Speaker Recognition. InInterspeech 2018. 1086–1090. doi:10.21437/Interspeech. 2018-1929
-
[8]
Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck. 2020. ECAPA- TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification. InInterspeech 2020. 3830–3834. doi:10.21437/ Interspeech.2020-2650
2020
-
[9]
Jakaria Islam Emon, Md Abu Salek, and Kazi Tamanna Alam. 2025. Whisper Speaker Identification: Leveraging Pre-Trained Multilingual Transformers for Robust Speaker Embeddings.arXiv preprint arXiv:2503.10446(2025)
arXiv 2025
-
[10]
Zhihua Fang, Shumei Tao, Junxu Wang, and Liang He. 2026. XM-ALIGN: Unified cross-modal embedding alignment for face-voice association. InICASSP 2026- 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 21760–21762
2026
-
[11]
Aref Farhadipour, Masoumeh Chapariniya, Teodora Vuković, and Volker Dellwo
-
[12]
InProceedings of the 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024)
Comparative analysis of modality fusion approaches for audio-visual person identification and verification. InProceedings of the 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024). 168–177
2024
-
[13]
Aref Farhadipour, Jan Marquenie, Srikanth Madikeri, and Eleanor Chodroff. 2026. TidyVoice: A Curated Multilingual Dataset for Speaker Verification Derived from Common Voice.arXiv preprint arXiv:2601.16358(2026)
arXiv 2026
-
[14]
Aref Farhadipour, Jan Marquenie, Srikanth Madikeri, Teodora Vukovic, Volker Dellwo, Kathy Reid, Francis M Tyers, Ingo Siegert, and Eleanor Chodroff. 2026. TidyVoice 2026 Challenge Evaluation Plan.arXiv preprint arXiv:2601.21960 (2026)
arXiv 2026
-
[15]
Christian Ganhör, Marta Moscati, Anna Hausberger, Shah Nawaz, and Markus Schedl. 2024. A multimodal single-branch embedding network for recommenda- tion in cold-start and missing modality scenarios. InProceedings of the 18th ACM conference on recommender systems. 380–390
2024
-
[16]
Zirun Guo, Tao Jin, and Zhou Zhao. 2024. Multimodal prompt learning with missing modalities for sentiment analysis and emotion recognition. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers). 1726–1736
2024
-
[17]
Xing Han, Huy Nguyen, Carl Harris, Nhat Ho, and Suchi Saria. 2024. Fusemoe: Mixture-of-experts transformers for fleximodal fusion.Advances in Neural Information Processing Systems37 (2024), 67850–67900
2024
-
[18]
Abdul Hannan, Furqan Malik, Hina Jabbar, Syed Suleman Sadiq, and Mubashir Noman. 2026. RFOP: Rethinking fusion and orthogonal projection for face- voice association. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 21778–21780
2026
-
[19]
Abdul Hannan, Muhammad Arslan Manzoor, Shah Nawaz, Muhammad Irzam Liaqat, Markus Schedl, and Mubashir Noman. 2025. PAEFF: Precise Alignment and Enhanced Gated Feature Fusion for Face-Voice Association. InInterspeech
2025
-
[20]
doi:10.21437/Interspeech.2025-268
2710–2714. doi:10.21437/Interspeech.2025-268
-
[21]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531(2015)
Pith/arXiv arXiv 2015
-
[22]
Shota Horiguchi, Naoyuki Kanda, and Kenji Nagamatsu. 2018. Face-voice match- ing using cross-modal embeddings. InProceedings of the 26th ACM international conference on Multimedia. 1011–1019
2018
-
[23]
Lianyu Hu, Tongkai Shi, Wei Feng, Fanhua Shang, and Liang Wan. 2024. Deep correlated prompting for visual recognition with missing modalities.Advances in Neural Information Processing Systems37 (2024), 67446–67466
2024
-
[24]
Guanzhou Ke, Shengfeng He, Xiao Li Wang, Bo Wang, Guoqing Chao, Yuanyang Zhang, Yi Xie, and HeXing Su. 2025. Knowledge bridger: Towards training-free missing multi-modality completion.arXiv e-prints(2025), arXiv–2502
2025
-
[25]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
Pith/arXiv arXiv 2014
-
[26]
Ze Li, Xiaoxiao Miao, Juan Liu, and Ming Li. 2026. Language-Invariant Multi- lingual Speaker Verification for the TidyVoice 2026 Challenge.arXiv preprint arXiv:2603.08092(2026)
arXiv 2026
-
[27]
Muhammad Irzam Liaqat, Qaiser Abbas, Shah Nawaz, Zaigham Zaheer, Marta Moscati, Yufang Hou, Muhammad Haris Khan, Salman Khan, Elisabeth Andre, and Markus Schedl. 2025. Multimodal Learning Under Imperfect Data Conditions: A Survey.Authorea Preprints(2025)
2025
-
[28]
Hong Liu, Dong Wei, Donghuan Lu, Jinghan Sun, Liansheng Wang, and Yefeng Zheng. 2023. M3AE: multimodal representation learning for brain tumor seg- mentation with missing modalities. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 1657–1665
2023
-
[29]
Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang, AmirAli Bagher Zadeh, and Louis-Philippe Morency. 2018. Efficient low-rank multimodal fusion with modality-specific factors. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2247–2256
2018
-
[30]
Yi Ma, Shuai Wang, Tianchi Liu, and Haizhou Li. 2025. ExPO: Explainable phonetic trait-oriented network for speaker verification.IEEE Signal Processing Letters32 (2025), 731–735
2025
-
[31]
Marta Moscati, Ahmed Abdullah, Muhammad Saad Saeed, Shah Nawaz, Ro- han Kumar Das, Muhammad Zaigham Zaheer, Junaid Mir, Muhammad Haroon Yousaf, Khalid Mahmood Malik, and Markus Schedl. 2026. Linking faces and voices across languages: Insights from the fame 2026 challenge. InICASSP 2026- 2026 IEEE International Conference on Acoustics, Speech and Signal Pr...
2026
-
[32]
Marta Moscati, Oleksandr Kats, Mubashir Noman, Muhammad Zaigham Zaheer, Yufang Hou, Markus Schedl, and Shah Nawaz. 2026. Face-Voice Association with Inductive Bias for Maximum Class Separation. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE
2026
-
[33]
Marta Moscati, Muhammad Saad Saeed, Marina Zanoni, Mubashir Noman, Ro- han Kumar Das, Monorama Swain, Yufang Hou, Elisabeth Andre, Khalid Mah- mood Malik, Markus Schedl, et al . 2026. POLY-SIM: Polyglot Speaker Identi- fication with Missing Modality Grand Challenge 2026 Evaluation Plan.arXiv preprint arXiv:2603.24569(2026)
arXiv 2026
-
[34]
Arsha Nagrani, Samuel Albanie, and Andrew Zisserman. 2018. Seeing voices and hearing faces: Cross-modal biometric matching. InProceedings of the IEEE conference on computer vision and pattern recognition. 8427–8436
2018
-
[35]
Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. 2017. VoxCeleb: A Large-Scale Speaker Identification Dataset. InInterspeech 2017. 2616–2620. doi:10. 21437/Interspeech.2017-950
2017
-
[36]
Shah Nawaz, Muhammad Kamran Janjua, Ignazio Gallo, Arif Mahmood, and Alessandro Calefati. 2019. Deep latent space learning for cross-modal mapping of audio and visual signals. In2019 Digital Image Computing: Techniques and Applications (DICTA). IEEE, 1–7
2019
-
[37]
Shah Nawaz, Muhammad Saad Saeed, Pietro Morerio, Arif Mahmood, Ignazio Gallo, Muhammad Haroon Yousaf, and Alessio Del Bue. 2021. Cross-modal speaker verification and recognition: A multilingual perspective. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1682–1691
2021
-
[38]
Chong Peng, Liqiang He, and Dan Su. 2024. Fuse after Align: Improving Face-Voice Association Learning via Multimodal Encoder.arXiv preprint arXiv:2404.09509(2024)
arXiv 2024
-
[39]
R Gnana Praveen and Jahangir Alam. 2023. Audio-Visual Speaker Verification via Joint Cross-Attention.arXiv preprint arXiv:2309.16569(2023)
arXiv 2023
-
[40]
R Gnana Praveen and Jahangir Alam. 2024. Dynamic cross attention for audio- visual person verification. In2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 1–5
2024
-
[41]
Anindya Roy and Sébastien Marcel. 2010. Introducing crossmodal biometrics: Person identification from distinct audio & visual streams. In2010 Fourth IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS). IEEE, 1–6
2010
-
[42]
Muhammad Saad Saeed, Shah Nawaz, Muhammad Haris Khan, Muham- mad Zaigham Zaheer, Karthik Nandakumar, Muhammad Haroon Yousaf, and Arif Mahmood. 2023. Single-branch network for multimodal training. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[43]
Muhammad Saad Saeed, Shah Nawaz, Marta Moscati, Rohan Kumar Das, Muham- mad Salman Tahir, Muhammad Zaigham Zaheer, Muhammad Irzam Liaqat, Muhammad Haris Khan, Karthik Nandakumar, Muhammad Haroon Yousaf, et al
-
[44]
InProceedings of the 32nd ACM International Conference on Multimedia
A synopsis of fame 2024 challenge: Associating faces with voices in multi- lingual environments. InProceedings of the 32nd ACM International Conference on Multimedia. 11333–11334
2024
-
[45]
Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. Facenet: A unified embedding for face recognition and clustering. InProceedings of the IEEE conference on computer vision and pattern recognition. 815–823
2015
-
[46]
Saqlain Hussain Shah, Muhammad Saad Saeed, Shah Nawaz, and Muhammad Ha- roon Yousaf. 2023. Speaker recognition in realistic scenario using multimodal data. In2023 3rd International Conference on Artificial Intelligence (ICAI). IEEE, 209–213
2023
-
[47]
Qituan Shangguan, Junhao Du, Kunyang Peng, Feng Xue, Hui Zhang, Xinsheng Wang, Kai Yu, and Shuai Wang. 2026. Dual-LoRA: Parameter-Efficient Adver- sarial Disentanglement for Cross-Lingual Speaker Verification.arXiv preprint arXiv:2604.26327(2026)
Pith/arXiv arXiv 2026
-
[48]
Christopher Simic, Korbinian Riedhammer, and Tobias Bocklet. 2026. Shared multi-modal embedding space for face-voice association. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 21766–21768
2026
-
[49]
David Snyder, Daniel Garcia-Romero, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur. 2018. X-vectors: Robust dnn embeddings for speaker recognition. In2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 5329–5333
2018
-
[50]
Haoqin Sun, Shiwan Zhao, Shaokai Li, Xiangyu Kong, Xuechen Wang, Jiaming Zhou, Aobo Kong, Yong Chen, Wenjia Zeng, and Yong Qin. 2025. Enhancing emotion recognition in incomplete data: A novel cross-modal alignment, recon- struction, and refinement framework. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASS...
2025
-
[51]
Ruijie Tao, Rohan Kumar Das, and Haizhou Li. 2020. Audio-visual speaker recog- nition with a cross-modal discriminative network.arXiv preprint arXiv:2008.03894 (2020). Peng Jia, Li Dai, Jia Li, Zhenzhen Hu, Ye Zhao, and Richang Hong
arXiv 2020
-
[52]
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2019. Multimodal transformer for unaligned multimodal language sequences. InProceedings of the 57th annual meeting of the association for computational linguistics. 6558–6569
2019
-
[53]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[54]
Hu Wang, Yuanhong Chen, Congbo Ma, Jodie Avery, Louise Hull, and Gustavo Carneiro. 2023. Multi-modal learning with missing modality via shared-specific feature modelling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15878–15887
2023
-
[55]
Hu Wang, Congbo Ma, Jianpeng Zhang, Yuan Zhang, Jodie Avery, Louise Hull, and Gustavo Carneiro. 2023. Learnable cross-modal knowledge distillation for multi-modal learning with missing modality. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 216–226
2023
-
[56]
Shicai Wei, Yang Luo, and Chunbo Luo. 2023. One-stage modality distillation for incomplete multimodal learning.arXiv preprint arXiv:2309.08204(2023)
arXiv 2023
-
[57]
Yandong Wen, Kaipeng Zhang, Zhifeng Li, and Yu Qiao. 2016. A discriminative feature learning approach for deep face recognition. InEuropean conference on computer vision. Springer, 499–515
2016
-
[58]
Renjie Wu, Hu Wang, Hsiang-Ting Chen, and Gustavo Carneiro. 2024. Deep mul- timodal learning with missing modality: A survey.arXiv preprint arXiv:2409.07825 (2024)
Pith/arXiv arXiv 2024
-
[59]
Sukwon Yun, Inyoung Choi, Jie Peng, Yangfan Wu, Jingxuan Bao, Qiyiwen Zhang, Jiayi Xin, Qi Long, and Tianlong Chen. 2024. Flex-moe: Modeling arbitrary modality combination via the flexible mixture-of-experts.Advances in Neural Information Processing Systems37 (2024), 98782–98805
2024
-
[60]
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2017. Tensor fusion network for multimodal sentiment analysis. In Proceedings of the 2017 conference on empirical methods in natural language processing. 1103–1114
2017
-
[61]
Qingyang Zhang, Yake Wei, Zongbo Han, Huazhu Fu, Xi Peng, Cheng Deng, Qinghua Hu, Cai Xu, Jie Wen, Di Hu, et al. 2024. Multimodal fusion on low-quality data: A comprehensive survey.arXiv preprint arXiv:2404.18947(2024)
arXiv 2024
-
[62]
Yiyang Zhao, Shuai Wang, Guangzhi Sun, Zehua Chen, Chao Zhang, Mingxing Xu, and Thomas Fang Zheng. 2024. Whisper-pmfa: Partial multi-scale fea- ture aggregation for speaker verification using whisper models.arXiv preprint arXiv:2408.15585(2024)
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.