Foresight: Iterative Reasoning About Clues that Matter for Navigation
Pith reviewed 2026-06-27 09:33 UTC · model grok-4.3
The pith
Foresight uses a VLM to iteratively propose and critique image-space motion plans, refined by a human-feedback reward model, to handle sparse instructions in open-world navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
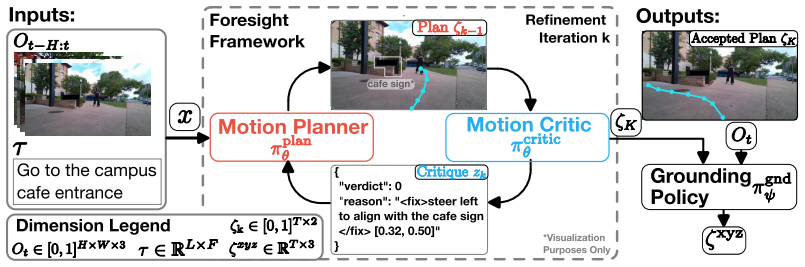
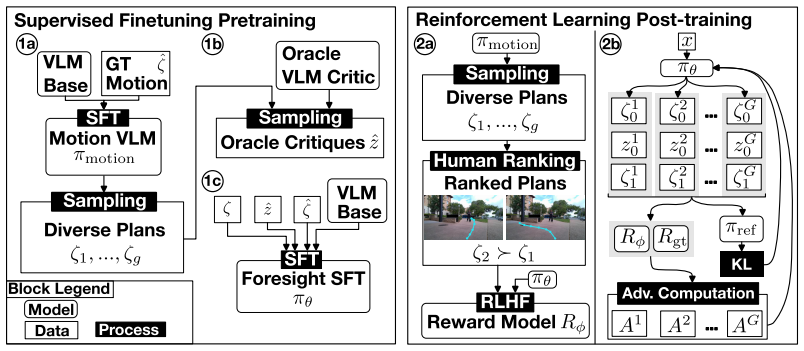
Foresight is a test-time framework in which a finetuned VLM alternates between proposing image-space motion plans and critiquing them using the language goal and visual context, with subsequent plans conditioned on prior critiques; a reward model from human feedback post-trains the VLM with reinforcement learning inside this plan-critique loop to align with open-set behavior preferences.
What carries the argument
The plan-critique loop in which a VLM proposes then critiques image-space motion plans before execution, with plans conditioned on prior critiques and aligned by a human-feedback reward model via RL.
If this is right
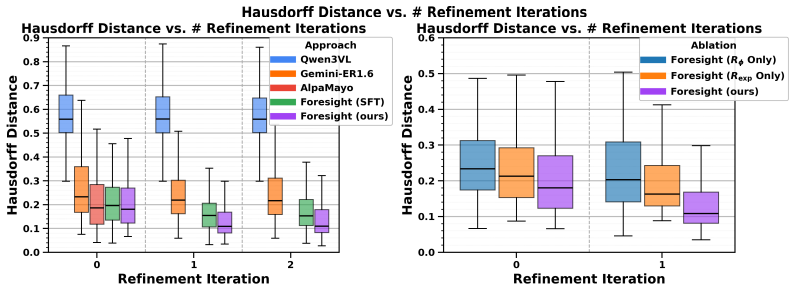
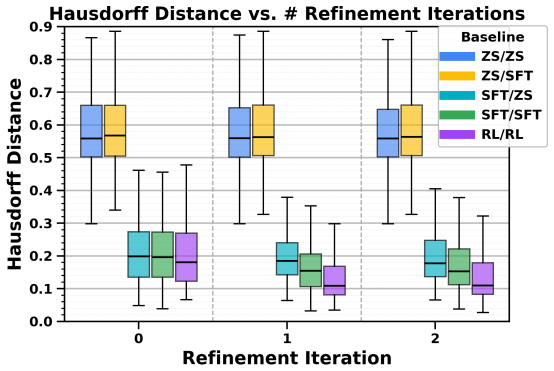
- Task success rises by 37 percent on average in offline and real-world tests.
- Human interventions per mission fall by 52 percent.
- The system runs in real time on a Jetson AGX Orin across six real-world environments.
- Navigation succeeds without pre-defined closed-set factor categories or known navigation factors.
Where Pith is reading between the lines
- The loop structure could transfer to other VLM-driven robot skills that need to discover plan-dependent context from language.
- Collecting more diverse human feedback on critiques might let the reward model generalize to longer-horizon or multi-goal instructions.
- Combining the cue-discovery loop with partial maps could test whether mapless refinement complements map-based planning.
- Failures in new environments might trace to the reward model rather than the VLM itself, suggesting targeted data collection as a fix.
Load-bearing premise
A reward model trained on human feedback can reliably align VLM plan critiques and refinements with open-set behavior preferences so the loop surfaces relevant cues.
What would settle it
A controlled test replacing the learned reward model with random scores or omitting the RL step entirely, then measuring whether cue identification and task success still exceed non-iterative VLM baselines in the same environments.
Figures




read the original abstract
Open-world mapless navigation from sparse language instructions requires resolving underspecified goals and inferring which environmental cues are relevant for reaching the goal. For instance, reaching an out-of-view destination may require interpreting ramps, signs, or detours that reveal where to go or which route to take. Prior works are limited by their reliance on known navigation factors and closed-set factor categories, or identify cues before motion planning and miss plan-dependent cues. We argue that pretrained Vision-Language Models (VLMs) can discover novel instruction-relevant cues, but require adaptation to focus on which cues matter and how they should influence motion planning. We realize these ideas in Foresight, a test-time framework in which a finetuned VLM alternates between proposing image-space motion plans and critiquing them using the language goal and visual context. Subsequent plans are conditioned on prior critiques, enabling iterative motion refinement before execution. To align plan critiques and refinements with open-set behavior preferences, we learn a reward model from human feedback and use it to post-train the VLM with reinforcement learning in the plan-critique loop. In offline evaluations and 6 real-world environments, Foresight improves average task success by 37% and reduces interventions per mission by 52% relative to state-of-the-art test-time reasoning and foundation-model baselines, while running in real-time on a Jetson AGX Orin. We will release code, data, and training details to support future work on test-time reasoning for robot motion refinement. Additional videos at: https://amrl.cs.utexas.edu/foresight
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Foresight, a test-time framework for open-world mapless navigation from sparse language instructions. A finetuned VLM alternates between proposing image-space motion plans and critiquing them conditioned on the goal and visual context; subsequent plans are refined iteratively before execution. A reward model trained on human feedback is used to post-train the VLM via reinforcement learning within the plan-critique loop, with the goal of aligning critiques to open-set preferences. Offline and real-world experiments in 6 environments report a 37% average increase in task success and 52% reduction in interventions relative to test-time reasoning and foundation-model baselines, with real-time operation on Jetson AGX Orin. Code, data, and training details will be released.
Significance. If the empirical gains hold under rigorous controls, the work provides evidence that iterative VLM-based critique can surface plan-dependent, instruction-relevant cues missed by prior cue-identification methods, advancing test-time adaptation for robot navigation. The explicit commitment to releasing code, data, and training details supports reproducibility and future work on reward-model alignment for open-set behavior.
major comments (3)
- [§4.3] §4.3 (real-world experiments): The manuscript reports aggregate 37% success and 52% intervention improvements but does not specify the number of trials per environment, the exact baseline implementations (including any hyperparameter tuning or prompt engineering), or the statistical test used to establish significance. These omissions make it impossible to verify whether the gains are robust or environment-specific.
- [§3.2] §3.2 (reward model): The description of the human-feedback collection protocol, volume of annotations, inter-annotator agreement, and held-out validation of the reward model is insufficient to substantiate the claim that the model reliably aligns VLM critiques with open-set preferences. Without these details the central mechanism remains under-specified.
- [§4.1] §4.1 (offline evaluations): The comparison tables do not report per-baseline variance or failure-mode breakdowns; this weakens the claim that Foresight discovers cues missed by prior methods rather than simply benefiting from more iterations.
minor comments (2)
- [Figure 3] Figure 3 caption and §3.1: The notation for the iterative loop (e.g., how prior critiques are concatenated into the VLM prompt) is introduced without an explicit equation; adding a compact recurrence would improve clarity.
- [§5] §5 (limitations): The discussion of failure cases is brief; expanding it with concrete examples of when the reward model misaligns would strengthen the paper.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional experimental details will strengthen the manuscript's clarity and reproducibility. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [§4.3] §4.3 (real-world experiments): The manuscript reports aggregate 37% success and 52% intervention improvements but does not specify the number of trials per environment, the exact baseline implementations (including any hyperparameter tuning or prompt engineering), or the statistical test used to establish significance. These omissions make it impossible to verify whether the gains are robust or environment-specific.
Authors: We agree these details are required for rigorous verification. The revised manuscript will report the exact number of trials per environment, provide complete specifications of all baseline implementations (including hyperparameter values and prompt templates), and state the statistical test(s) used to assess significance. These additions will appear in §4.3 and will also be documented in the released code and data. revision: yes
-
Referee: [§3.2] §3.2 (reward model): The description of the human-feedback collection protocol, volume of annotations, inter-annotator agreement, and held-out validation of the reward model is insufficient to substantiate the claim that the model reliably aligns VLM critiques with open-set preferences. Without these details the central mechanism remains under-specified.
Authors: We concur that the reward-model section requires greater specificity. The revision will expand §3.2 with a full description of the feedback collection protocol, the total number of annotations, inter-annotator agreement metrics, and held-out validation results demonstrating alignment with open-set preferences. revision: yes
-
Referee: [§4.1] §4.1 (offline evaluations): The comparison tables do not report per-baseline variance or failure-mode breakdowns; this weakens the claim that Foresight discovers cues missed by prior methods rather than simply benefiting from more iterations.
Authors: We will update the tables in §4.1 to include per-baseline variance (standard deviations across repeated runs). We will also add a concise failure-mode analysis that examines whether performance gains arise from cue discovery versus iteration count alone, thereby supporting the central claim more robustly. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external robot evaluations, not self-referential definitions or fitted predictions
full rationale
The paper describes an empirical method (VLM plan-critique loop post-trained via RL on a human-feedback reward model) and reports measured improvements (37% success, 52% fewer interventions) in offline and real-world tests. No equations, derivations, or uniqueness theorems are supplied that reduce these metrics to inputs by construction. The reward model is learned from external human data and the evaluations use held-out environments; nothing in the provided text indicates a self-definitional loop, fitted-input prediction, or load-bearing self-citation chain. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhang, H
A. Zhang, H. Sikchi, A. Zhang, and J. Biswas. Creste: Scalable mapless navigation with internet scale priors and counterfactual guidance. InProceedings of Robotics: Science and Systems XXI. Robotics: Science and Systems, 2025
2025
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
- [3]
-
[4]
Hirose, C
N. Hirose, C. Glossop, A. Sridhar, O. Mees, and S. Levine. Lelan: Learning a language- conditioned navigation policy from in-the-wild video. In8th Annual Conference on Robot Learning, 2024
2024
-
[5]
Zawalski, W
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine. Robotic control via embodied chain-of-thought reasoning. InConference on Robot Learning, pages 3157–3181. PMLR, 2025
2025
-
[6]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, et al. Cot- vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[7]
Y . Wang, W. Luo, J. Bai, Y . Cao, T. Che, K. Chen, Y . Chen, J. Diamond, Y . Ding, W. Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π {0.5}: a vision-language-action model with open-world general- ization.eprint arXiv: 2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
J. Kim, C. Min, B. Kim, and J. Choi. Pre-emptive action revision by environmental feedback for embodied instruction following agents. In8th Annual Conference on Robot Learning, 2024
2024
-
[10]
M. Han, Y . Zhu, S. Zhu, and Y . Wu. Interpret: Interactive predicate learning from language feedback for generalizable task planning. In2024 IEEE International Conference on Intelligent Robots and Systems (IROS). IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
2024
-
[11]
Huang, F
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models. InConference on Robot Learning, pages 1769–1782. PMLR, 2023
2023
-
[12]
Zhang, X
A. Zhang, X. Meng, L. Calliari, D.-K. Kim, S. Omidshafiei, J. Biswas, A. Agha, and A. Sha- ban. Ventura: Adapting image diffusion models for unified task conditioned navigation. In IEEE International Conference on Robotics and Automation (ICRA), 2026. 9
2026
-
[13]
C. Qi, X. Wang, S. Yong, S. Sheng, H. Mao, M. Nambi, A. Zhang, Y . Dattatreya, et al. Self- refining vision language model for robotic failure detection and reasoning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[14]
J. Hu, R. Hendrix, A. Farhadi, A. Kembhavi, R. Mart ´ın-Mart´ın, P. Stone, K.-H. Zeng, and K. Ehsani. Flare: Achieving masterful and adaptive robot policies with large-scale reinforce- ment learning fine-tuning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3617–3624. IEEE, 2025
2025
-
[15]
H. Li, Y . Zuo, J. Yu, Y . Zhang, Z. Yang, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
K.-H. Zeng, Z. Zhang, K. Ehsani, R. Hendrix, J. Salvador, A. Herrasti, R. Girshick, A. Kem- bhavi, and L. Weihs. Poliformer: Scaling on-policy rl with transformers results in masterful navigators. InConference on Robot Learning, pages 408–432. PMLR, 2025
2025
-
[17]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
H. He, Y . Ma, W. Wu, and B. Zhou. From seeing to experiencing: Scaling navigation founda- tion models with reinforcement learning.arXiv preprint arXiv:2507.22028, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [19]
- [20]
- [21]
-
[22]
W. Xia, Y . Yang, H. Wu, X. Ma, T. Kong, and D. Hu. Human-assisted robotic policy refinement via action preference optimization.Advances in Neural Information Processing Systems, 38: 36746–36768, 2026
2026
-
[23]
J. Lee, J. Duan, H. Fang, Y . Deng, B. Li, S. Liu, B. Fang, J. Zhang, Y . R. Wang, S. Lee, et al. Molmoact: Action reasoning models that can reason in space. InWorkshop on Making Sense of Data in Robotics: Composition, Curation, and Interpretability at Scale at CoRL 2025, 2025
2025
-
[24]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[25]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
R. A. Bradley and M. E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39:324, 1952. URLhttps://api.semanticscholar. org/CorpusID:125209808. 10
1952
-
[28]
P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y . Li, D. Chen, Y . Wu, and Z. Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
2024
-
[29]
Huang, Z
Y . Huang, Z. Tian, Q. Jiang, and J. Xu. Path tracking based on improved pure pursuit model and pid. In2020 IEEE 2nd International Conference on Civil Aviation Safety and Information Technology (ICCASIT, pages 359–364. IEEE, 2020
2020
-
[30]
Karnan, A
H. Karnan, A. Nair, X. Xiao, G. Warnell, S. Pirk, A. Toshev, J. Hart, J. Biswas, and P. Stone. Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022
2022
-
[31]
Pichai, D
S. Pichai, D. Hassabis, and K. Kavukcuoglu. A new era of intelligence with gem- ini 3.Mountain View, CA: Google). Available online at: https://blog. google/products- andplatforms/products/gemini/gemini-3/(Accessed February 1, 2026), 2025
2026
-
[32]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[34]
Cheng, Y
A.-C. Cheng, Y . Fu, Y . Chen, Z. Liu, X. Li, S. Radhakrishnan, S. Han, Y . Lu, J. Kautz, P. Molchanov, et al. 3d aware region prompted vision language model.arXiv e-prints, pages arXiv–2509, 2025
2025
-
[35]
M. D. Donsker and S. R. S. Varadhan. Asymptotic evaluation of certain markov process ex- pectations for large time, i.Communications on Pure and Applied Mathematics, 28(1):1–47,
-
[36]
URLhttps://onlinelibrary.wiley
doi:https://doi.org/10.1002/cpa.3160280102. URLhttps://onlinelibrary.wiley. com/doi/abs/10.1002/cpa.3160280102
-
[37]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao. Depth anything v2. Advances in Neural Information Processing Systems, 37:21875–21911, 2024
2024
-
[38]
B. Koonce. Efficientnet. InConvolutional neural networks with swift for Tensorflow: image recognition and dataset categorization, pages 109–123. Springer, 2021
2021
-
[39]
C. Finn, X. Y . Tan, Y . Duan, T. Darrell, S. Levine, and P. Abbeel. Deep spatial autoencoders for visuomotor learning. In2016 IEEE International Conference on Robotics and Automation (ICRA), pages 512–519. IEEE, 2016
2016
-
[40]
Sheng, C
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu. Hy- bridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025. 11 A Appendix This appendix supplements the main paper with additional experimental analysis, reward deriva- tions, dataset ...
2025
-
[41]
1" with the string
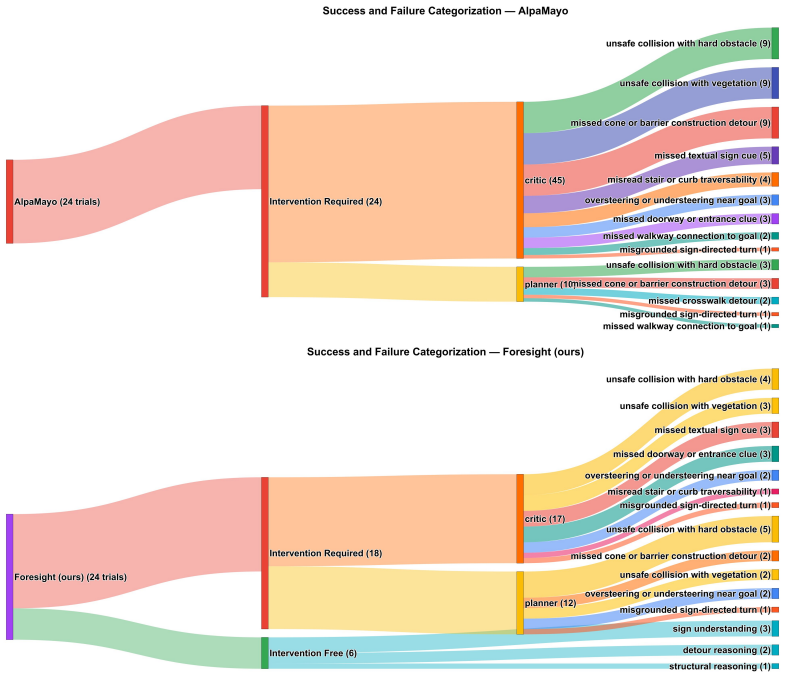
We convert this distance into a bounded reward by linearly mapping zero error to1 and a distance of √ 2/2to−1, then clipping larger errors: Rexp(x, ζ) = clip 1− 4√ 2 dH(ζ, ˆζ),−1,1 .(10) 13 Figure 7: Success and Failure Taxonomy for Real World Experiments. We categorize the failures based on if they are caused by the critic or planner before describing th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.