Crossing the Validation Crisis: Cross-Validation Reduces Benchmarking Variance Surprisingly Well
Pith reviewed 2026-06-27 10:06 UTC · model grok-4.3
The pith
Cross-validation with multiple splits reduces variance in machine learning performance estimates through virtual sample gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
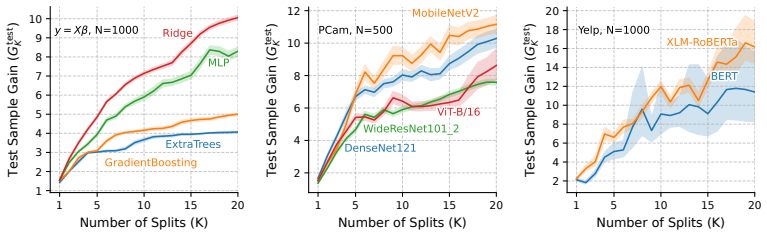
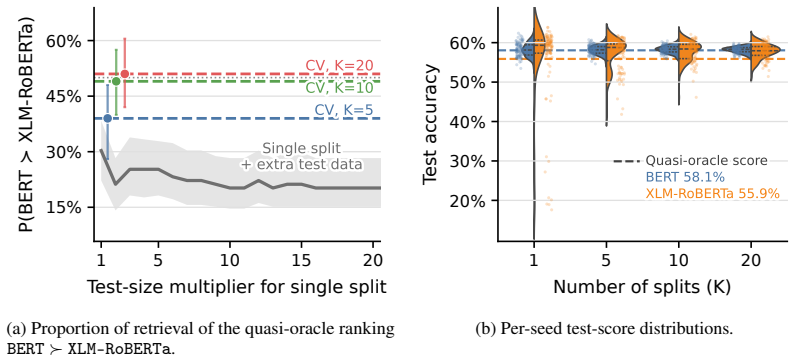
Cross-validation improves markedly confidence when evaluating and comparing learning algorithm performances. Multiple splits can substantially improve the reliability and stability of performance estimates, with diminishing returns often setting in later than expected. Sample gain quantifies the virtual data augmentation achieved by using multiple cross-validation splits to reduce benchmarking variance. A procedure exists to dynamically early-stop cross-validation by estimating from the first few folds if subsequent folds will bring large sample gains.
What carries the argument
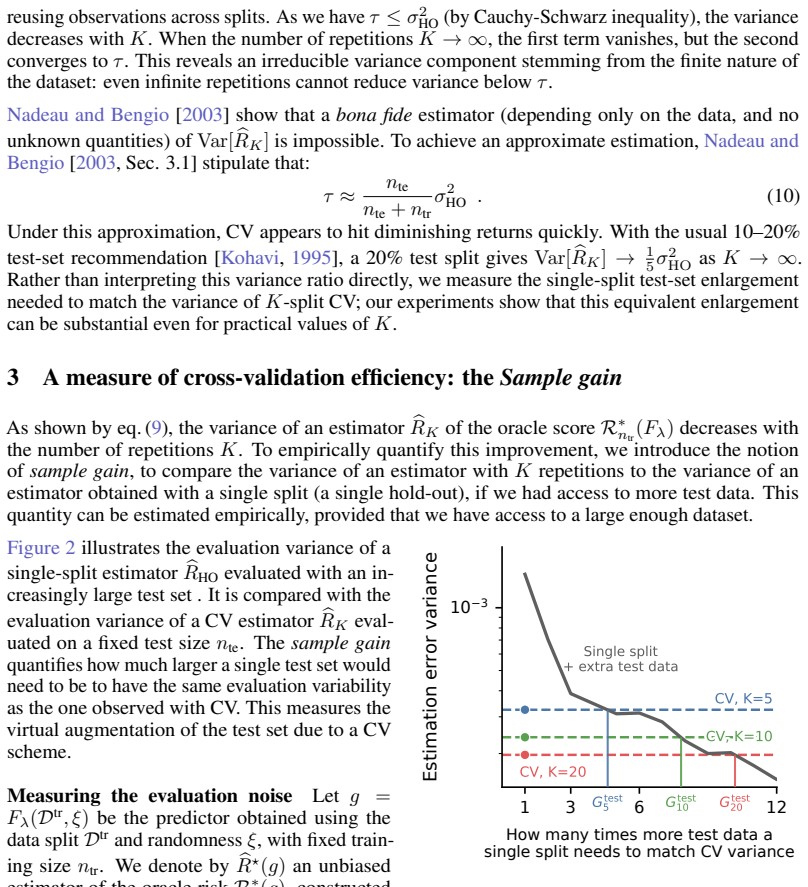
Sample gain, which quantifies the virtual data augmentation achieved by using multiple cross-validation splits to reduce benchmarking variance.
If this is right
- Multiple cross-validation splits produce more stable performance estimates than single splits.
- Diminishing returns on additional splits often occur later than commonly assumed.
- An early-stopping rule can decide after a few folds whether further splits are likely to add value.
- Pushing cross-validation on available samples yields more robust benchmarking overall.
Where Pith is reading between the lines
- Standard single-split test sets in many published benchmarks may systematically understate the uncertainty of reported scores.
- The sample-gain framing could be used to compare the efficiency of different resampling strategies beyond cross-validation.
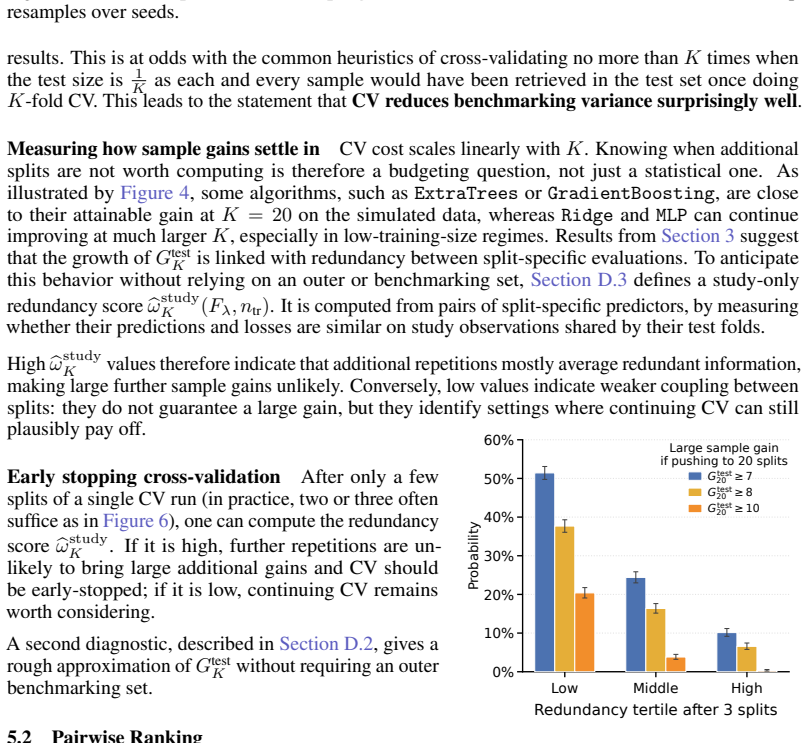
- If the early-stopping procedure works reliably, it could lower the computational cost of thorough evaluation without sacrificing stability.
Load-bearing premise
That the observed variance reduction and sample-gain behavior generalize beyond the specific synthetic setups and the two real-world domains examined in the experiments.
What would settle it
A new set of datasets and algorithms where adding cross-validation folds beyond the first produces no measurable reduction in the variance of performance estimates.
Figures



read the original abstract
Modern machine learning progresses through empirical work, benchmarking new methods to evaluate relative performance. However, the statistical variability inherent to evaluation - exacerbated by the stochastic nature of many algorithms - often makes performance estimation unreliable due to the limited test samples available, leading to a validation crisis in which genuine advances are difficult to discern. In this work, we show that cross-validation improves markedly confidence when evaluating and comparing learning algorithm performances. We introduce the concept of sample gain, which quantifies the virtual data augmentation achieved by using multiple cross-validation splits to reduce benchmarking variance. Experiments on both synthetic and real-world datasets (histopathologic scans and NLP fine-tuning) demonstrate that multiple splits can substantially improve the reliability and stability of performance estimates, with diminishing returns often setting in later than expected. We also introduce a procedure to dynamically early-stop cross-validation by estimating from the first few folds if subsequent folds will bring large sample gains. Our findings highlight the value of pushing cross-validation on available samples to achieve robust and reliable benchmarking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that cross-validation with multiple splits substantially reduces variance in ML performance estimates, thereby improving reliability when comparing algorithms. It introduces the concept of 'sample gain' as a measure of virtual data augmentation achieved by additional CV folds, supports the claim with experiments on synthetic data plus two real-world domains (histopathologic scans and NLP fine-tuning), and proposes an early-stopping rule that estimates future sample gains from the first few folds.
Significance. If the empirical findings and the sample-gain metric hold beyond the tested regimes, the work would supply a concrete, low-cost procedure for increasing the statistical reliability of benchmarking without collecting new data, directly addressing the validation crisis described in the abstract. The early-stopping procedure could also reduce unnecessary computation once diminishing returns are detected.
major comments (2)
- [Experiments] Experiments section: the central claim that multiple CV splits deliver 'substantial' and generalizable reliability gains rests on synthetic data plus only two real-world domains (histopathology, NLP fine-tuning). No broader coverage or sensitivity analysis to dimensionality, label noise, or model stochasticity is reported, so the headline assertion that CV 'markedly improves confidence' in general benchmarking does not yet follow from the presented evidence.
- [Method] Method / sample-gain definition: the paper introduces 'sample gain' as a new quantifiable entity but provides no derivation or closed-form expression showing under what conditions the variance-reduction formula holds; the reported behavior therefore remains an empirical observation whose scope is limited to the tested setups.
minor comments (2)
- [Abstract] Abstract: the phrase 'diminishing returns often setting in later than expected' is used without defining the baseline expectation or supplying quantitative thresholds for when returns become negligible.
- Ensure that all dataset sizes, number of repeats, exact CV schemes, and statistical tests used to support the variance-reduction claims are stated with sufficient precision for independent reproduction.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major comment below, indicating where revisions will be made to improve clarity and scope.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that multiple CV splits deliver 'substantial' and generalizable reliability gains rests on synthetic data plus only two real-world domains (histopathology, NLP fine-tuning). No broader coverage or sensitivity analysis to dimensionality, label noise, or model stochasticity is reported, so the headline assertion that CV 'markedly improves confidence' in general benchmarking does not yet follow from the presented evidence.
Authors: We acknowledge that the real-world experiments are confined to two domains and that a systematic sensitivity analysis across additional factors such as label noise levels or varying degrees of model stochasticity is not reported. The synthetic experiments do vary data dimensionality and noise, but these do not constitute a full sensitivity study. We will revise the discussion section to explicitly qualify the generalizability claims, highlight the limitations of the tested regimes, and avoid implying broader applicability than the evidence supports. This constitutes a partial revision. revision: partial
-
Referee: [Method] Method / sample-gain definition: the paper introduces 'sample gain' as a new quantifiable entity but provides no derivation or closed-form expression showing under what conditions the variance-reduction formula holds; the reported behavior therefore remains an empirical observation whose scope is limited to the tested setups.
Authors: The sample-gain metric is introduced as an empirical quantity that measures the effective variance reduction achieved by additional CV splits relative to a single split. We intentionally present it without a closed-form derivation because the precise mapping from folds to variance reduction is distribution- and model-dependent and would require assumptions that do not hold across the diverse regimes we study. We will add a short paragraph in the method section clarifying the empirical nature of the definition and the conditions under which the observed behavior is expected to hold, thereby addressing the concern without altering the core contribution. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper is an empirical study that introduces the 'sample gain' concept to quantify observed variance reduction from multiple CV splits and validates it via experiments on synthetic data plus two real domains. No mathematical derivation, fitted parameter renamed as prediction, or self-citation chain is present that reduces the central claim to its own inputs by construction. The findings rest on direct experimental measurements rather than any closed-loop definition or imported uniqueness result, rendering the work self-contained.
Axiom & Free-Parameter Ledger
invented entities (1)
-
sample gain
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Naddaf, Yavar and Veness, Joel and Bowling, Michael , journal =
Bellemare, Marc G. and Naddaf, Yavar and Veness, Joel and Bowling, Michael , journal =
-
[2]
Bouthillier, Xavier and Delaunay, Pierre and Bronzi, Mirko and Trofimov, Assya and Nichyporuk, Brennan and Szeto, Justin and Mohammadi Sepahvand, Nazanin and Raff, Edward and Madan, Kanika and Voleti, Vikram and Ebrahimi Kahou, Samira and Michalski, Vincent and Serdyuk, Dmitriy and Arbel, Tal and Pal, Chris and Varoquaux, Gael and Vincent, Pascal , booktitle =
-
[3]
2024 , eprint =
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference , author =. 2024 , eprint =
2024
-
[4]
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , booktitle =
-
[5]
, journal =
Dietterich, Thomas G. , journal =
-
[6]
Machine Learning , volume =
Extremely Randomized Trees , author =. Machine Learning , volume =
-
[7]
2024 , eprint =
SKADA-Bench: Benchmarking Unsupervised Domain Adaptation Methods with Realistic Validation , author =. 2024 , eprint =
2024
-
[8]
Pedregosa, Fabian and Varoquaux, Gael and Gramfort, Alexandre and Michel, Vincent and Thirion, Bertrand and Grisel, Olivier and Blondel, Mathieu and Prettenhofer, Peter and Weiss, Ron and Dubourg, Vincent and Vanderplas, Jake and Passos, Alexandre and Cournapeau, David and Brucher, Matthieu and Perrot, Matthieu and Duchesnay, Edouard , journal =
-
[9]
Torch. manual\_seed (3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision , author=. arXiv preprint arXiv:2109.08203 , year=
-
[10]
Saquib Sarfraz and Mei
M. Saquib Sarfraz and Mei. International Conference on Machine Learning (ICML) , year =
-
[11]
2024 , howpublished =
The Largest EEG-based BCI Reproducibility Study for Open Science: The MOABB Benchmark , author =. 2024 , howpublished =
2024
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Benchopt: Reproducible, Efficient and Collaborative Optimization Benchmarks , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Deep Reinforcement Learning that Matters , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[14]
Journal of Machine Learning Research (JMLR) , volume =
Improving Reproducibility in Machine Learning Research: A Report from the NeurIPS 2019 Reproducibility Program , author =. Journal of Machine Learning Research (JMLR) , volume =
2019
-
[15]
Reporting Score Distributions Makes a Difference: Performance Study of
Reimers, Nils and Gurevych, Iryna , booktitle =. Reporting Score Distributions Makes a Difference: Performance Study of. 2017 , publisher =
2017
-
[16]
Recht, Benjamin and Roelofs, Rebecca and Schmidt, Ludwig and Shankar, Vaishaal , booktitle =. Do
-
[17]
2018 , eprint =
Deep Learning: A Critical Appraisal , author =. 2018 , eprint =
2018
-
[18]
, journal =
Litjens, Geert and Kooi, Thijs and Bejnordi, Babak Ehteshami and Setio, Arnaud Arindra Adiyoso and Ciompi, Francesco and Ghafoorian, Mohsen and van der Laak, Jeroen and van Ginneken, Bram and Sánchez, Clara I. , journal =
-
[19]
Kohavi, Ron , booktitle =
-
[20]
, edition =
Hastie, Trevor and Tibshirani, Robert and Friedman, Jerome H. , edition =
-
[21]
Statistics Surveys , volume =
A Survey of Cross-Validation Procedures for Model Selection , author =. Statistics Surveys , volume =
-
[22]
Bengio, Yoshua and Grandvalet, Yves , journal =
-
[23]
Nadeau, Claude and Bengio, Yoshua , journal =
-
[24]
Picard and R
Richard R. Picard and R. Dennis Cook , journal =. 1984 , mrnumber =
1984
-
[25]
and Linmans, Jasper and Winkens, Jim and Cohen, Taco and Welling, Max , booktitle=
Veeling, Bastiaan S. and Linmans, Jasper and Winkens, Jim and Cohen, Taco and Welling, Max , booktitle=. 2018 , publisher=
2018
-
[26]
Zhang, Xiang and Zhao, Junbo and LeCun, Yann , booktitle=
-
[27]
and Kennard, Robert W
Hoerl, Arthur E. and Kennard, Robert W. , journal =
-
[28]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =
-
[29]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author =. arXiv preprint arXiv:1907.11692 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[30]
A Modern Bidirectional Encoder for Fast, Memory Efficient, and Scalable Language Understanding , author =. arXiv preprint arXiv:2412.13663 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh , booktitle =
-
[32]
, booktitle =
Huang, Gao and Liu, Zhuang and Van Der Maaten, Laurens and Weinberger, Kilian Q. , booktitle =
-
[33]
Proceedings of the British Machine Vision Conference (BMVC) , year =
Sergey Zagoruyko and Nikos Komodakis , title =. Proceedings of the British Machine Vision Conference (BMVC) , year =
-
[34]
2022 , publisher=
Pocock, Johnathan and Graham, Simon and Vu, Quoc Dang and Jahanifar, Mostafa and Deshpande, Srijay and Hadjigeorghiou, Giorgos and Shephard, Adam and Bashir, Raja Muhammad Saad and Bilal, Mohsin and Lu, Wenqi and others , journal=. 2022 , publisher=
2022
-
[35]
and Burgos, Ninon and Boutaj, Sofiène and Loizillon, Sophie and Solal, Maëlys and Rieke, Nicola and Cheplygina, Veronika and Antonelli, Michela and Mayer, Leon D
Christodoulou, Evangelia and Reinke, Annika and Houhou, Rola and Kalinowski, Piotr and Erkan, Selen and Sudre, Carole H. and Burgos, Ninon and Boutaj, Sofiène and Loizillon, Sophie and Solal, Maëlys and Rieke, Nicola and Cheplygina, Veronika and Antonelli, Michela and Mayer, Leon D. and Tizabi, Minu D. and Cardoso, M. Jorge and Simpson, Amber and Jäger, P...
-
[36]
Evangelia Christodoulou and Annika Reinke and Pascaline Andrè and Patrick Godau and Piotr Kalinowski and Rola Houhou and Selen Erkan and Carole H. Sudre and Ninon Burgos and Sofiène Boutaj and Sophie Loizillon and Maëlys Solal and Veronika Cheplygina and Charles Heitz and Michal Kozubek and Michela Antonelli and Nicola Rieke and Antoine Gilson and Leon D....
-
[37]
PyTorch:
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and others , booktitle=. PyTorch:
-
[38]
and Wolf, Thomas , booktitle =
Lhoest, Quentin and Villanova del Moral, Albert and Jernite, Yacine and Thakur, Abhishek and von Platen, Patrick and Patil, Suraj and Chaumond, Julien and Drame, Mariama and Plu, Julien and Tunstall, Lewis and Davison, Joe and Šaško, Mario and Chhablani, Gunjan and Malik, Bhavitvya and Brandeis, Simon and Le Scao, Teven and Sanh, Victor and Xu, Canwen and...
-
[39]
Proceedings of the 18th ACM International Conference on Multimedia , year =
Torchvision the Machine-Vision Package of Torch , author =. Proceedings of the 18th ACM International Conference on Multimedia , year =
-
[40]
and Ba, Jimmy , booktitle =
Kingma, Diederik P. and Ba, Jimmy , booktitle =. 2015 , eprint =
2015
-
[41]
2019 , eprint =
Loshchilov, Ilya and Hutter, Frank , booktitle =. 2019 , eprint =
2019
-
[42]
BMC Medicine , author =
Sampling inequalities affect generalization of neuroimaging-based diagnostic classifiers in psychiatry , volume =. BMC Medicine , author =. 2023 , keywords =
2023
-
[43]
and Etmann, Christian and McCague, Cathal and Beer, Lucian and Weir-McCall, Jonathan R
Roberts, Michael and Driggs, Derek and Thorpe, Matthew and Gilbey, Julian and Yeung, Michael and Ursprung, Stephan and Aviles-Rivero, Angelica I. and Etmann, Christian and McCague, Cathal and Beer, Lucian and Weir-McCall, Jonathan R. and Teng, Zhongzhao and Gkrania-Klotsas, Effrossyni and Rudd, James H. F. and Sala, Evis and Schönlieb, Carola-Bibiane , ye...
-
[44]
Science Progress , author =
Machine learning on small size samples:. Science Progress , author =. 2022 , pages =
2022
-
[45]
Yim, Wen-wai and Fu, Yujuan and Ben Abacha, Asma and Snider, Neal and Lin, Thomas and Yetisgen, Meliha , journal =
-
[46]
Ben Abacha, Asma and Yim, Wen-wai and Fan, Yadan and Lin, Thomas , booktitle =
-
[47]
Soni, Sarvesh and Gudala, Meghana and Pajouhi, Atieh and Roberts, Kirk , booktitle =
-
[48]
and Wiest, Olaf and Zhang, Xiangliang , booktitle =
Guo, Kehan and Nan, Bozhao and Zhou, Yujun and Guo, Taicheng and Guo, Zhichun and Surve, Mihir and Liang, Zhenwen and Chawla, Nitesh V. and Wiest, Olaf and Zhang, Xiangliang , booktitle =
-
[49]
Vladika, Juraj and Schneider, Phillip and Matthes, Florian , booktitle =
-
[50]
2025 , eprint=
RelationalFactQA: A Benchmark for Evaluating Tabular Fact Retrieval from Large Language Models , author=. 2025 , eprint=
2025
-
[51]
T ruthful QA : Measuring How Models Mimic Human Falsehoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Annual Meeting of the Association for Computational Linguistics (ACL). 2022
2022
-
[52]
S ci DTB : Discourse Dependency T ree B ank for Scientific Abstracts
Yang, An and Li, Sujian. S ci DTB : Discourse Dependency T ree B ank for Scientific Abstracts. Annual Meeting of the Association for Computational Linguistics (ACL). 2018
2018
-
[53]
Advances in Neural Information Processing Systems (NeurIPS) -- Datasets and Benchmarks Track , author =
-
[54]
Advances in Neural Information Processing Systems (NeurIPS) , author =
-
[55]
Scientific Data , publisher =
Yang, Jiancheng and Shi, Rui and Wei, Donglai and Liu, Zequan and Zhao, Lin and Ke, Bilian and Pfister, Hanspeter and Ni, Bingbing , year =. Scientific Data , publisher =
-
[56]
ACM Computing Surveys , author =
A. ACM Computing Surveys , author =
-
[57]
A comprehensive benchmark of active learning strategies with
Bi, Jinghou and Xu, Yuanhao and Conrad, Felix and Wiemer, Hajo and Ihlenfeldt, Steffen , year =. A comprehensive benchmark of active learning strategies with. Scientific Reports , publisher =
-
[58]
Shmuel, Assaf and Glickman, Oren and Lazebnik, Teddy , year =. A
-
[59]
2023 , booktitle =
McElfresh, Duncan and Khandagale, Sujay and Valverde, Jonathan and C., Vishak Prasad and Ramakrishnan, Ganesh and Goldblum, Micah and White, Colin , title =. 2023 , booktitle =
2023
-
[60]
and Litjens, Geert and Menze, Bjoern and Ronneberger, Olaf and Summers, Ronald M
Antonelli, Michela and Reinke, Annika and Bakas, Spyridon and Farahani, Keyvan and Kopp-Schneider, Annette and Landman, Bennett A. and Litjens, Geert and Menze, Bjoern and Ronneberger, Olaf and Summers, Ronald M. and van Ginneken, Bram and Bilello, Michel and Bilic, Patrick and Christ, Patrick F. and Do, Richard K. G. and Gollub, Marc J. and Heckers, Step...
-
[61]
The Emerging Science of Machine Learning Benchmarks , author =
-
[62]
Eriksson, Maria and Purificato, Erasmo and Noroozian, Arman and Vinagre, Joao and Chaslot, Guillaume and Gomez, Emilia and Fernandez-Llorca, David , booktitle=. Can
-
[63]
2018 , author =
Cross-validation failure: Small sample sizes lead to large error bars , journal =. 2018 , author =
2018
-
[64]
Annual Meeting of the Association for Computational Linguistics (ACL)
Strubell, Emma and Ganesh, Ananya and McCallum, Andrew. Annual Meeting of the Association for Computational Linguistics (ACL). 2019
2019
-
[65]
Journal of Machine Learning Research (JMLR) , year =
Janez Dem. Journal of Machine Learning Research (JMLR) , year =
-
[66]
Expert Review of Pharmacoeconomics & Outcomes Research , author =
Systematic reviews of machine learning in healthcare: a literature review , volume =. Expert Review of Pharmacoeconomics & Outcomes Research , author =. 2024 , keywords =
2024
-
[67]
Zuo, Yuxin and Qu, Shang and Li, Yifei and Chen, Zhangren and Zhu, Xuekai and Hua, Ermo and Zhang, Kaiyan and Ding, Ning and Zhou, Bowen , journal=
-
[68]
Nagler, Thomas and Schneider, Lennart and Bischl, Bernd and Feurer, Matthias , booktitle =
-
[69]
Machine Learning , volume =
Reducing Cross-Validation Variance through Seed Blocking in Hyperparameter Tuning , author =. Machine Learning , volume =
-
[70]
Advances in Neural Information Processing Systems (NeurIPS) -- Datasets and Benchmarks Track , year =
Erickson, Nick and Purucker, Lennart and Tschalzev, Andrej and Holzm. Advances in Neural Information Processing Systems (NeurIPS) -- Datasets and Benchmarks Track , year =
-
[71]
Journal of the American Statistical Association , volume =
Seymour Geisser , title =. Journal of the American Statistical Association , volume =. 1975 , publisher =
1975
-
[72]
Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Alexis Conneau and Kartikay Khandelwal and Naman Goyal and Vishrav Chaudhary and Guillaume Wenzek and Francisco Guzm. Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[73]
Proceedings of the 9th International Conference on Learning Representations (ICLR) , year =
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. Proceedings of the 9th International Conference on Learning Representations (ICLR) , year =
-
[74]
Friedman , journal =
Jerome H. Friedman , journal =
-
[75]
Leo Breiman and J. H. Friedman and Richard A. Olshen and C. J. Stone , title =. 1984 , isbn =
1984
-
[76]
Cover and Peter E
Thomas M. Cover and Peter E. Hart , title =
-
[77]
Machine Learning , author =
Support-vector networks , volume =. Machine Learning , author =. 1995 , keywords =
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.