HairPort: In-context 3D-aware Hair Import and Transfer for Images
Pith reviewed 2026-06-27 09:55 UTC · model grok-4.3
The pith
HairPort transfers hairstyles across large pose and scale gaps by first making the target face bald then re-rendering the source hair in 3D before synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
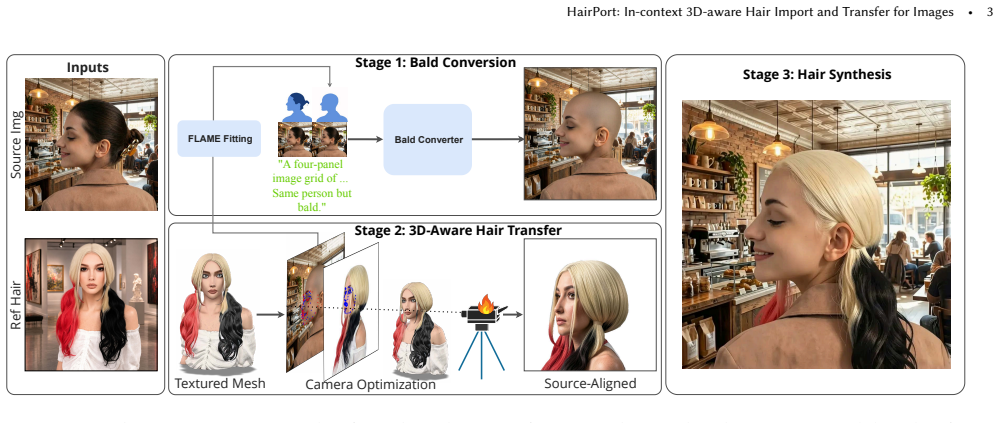
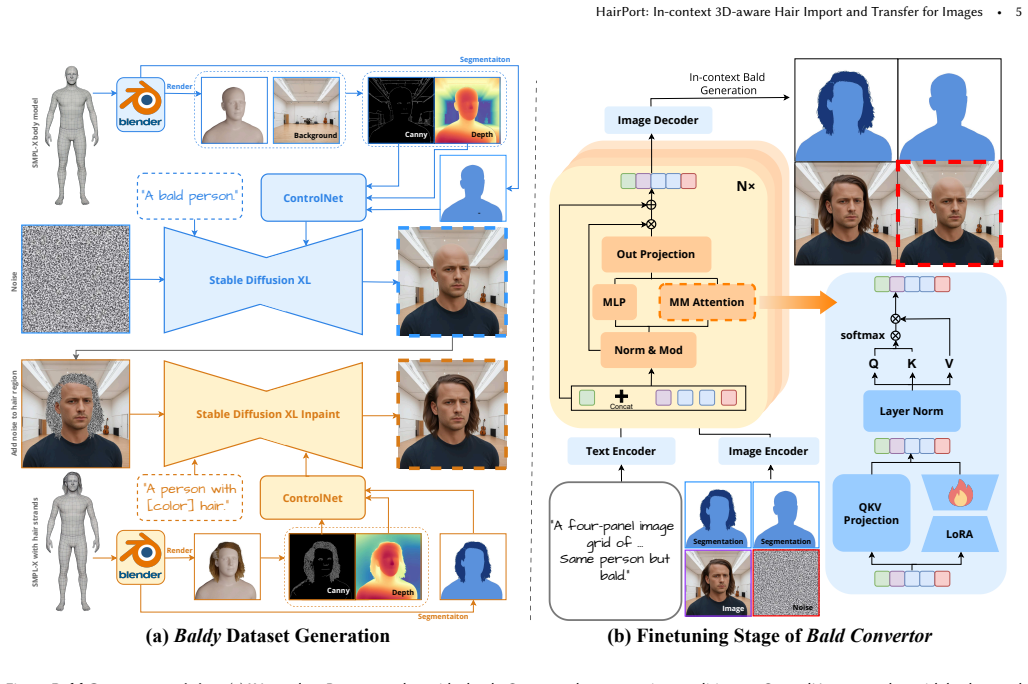
HairPort separates hair removal from transfer by training a Bald Converter on the Baldy dataset of 6,000 paired images via LoRA-based in-context adaptation of FLUX.1 Kontext, then applies a 3D-Aware Transfer Pipeline that reconstructs and re-renders the reference hairstyle from the target viewpoint, and finally feeds the bald source plus geometry-aligned reference into a conditional flow-matching generator to synthesize the result, producing accurate, pose-consistent, and identity-preserving transfers that outperform prior methods under large viewpoint and scale differences.
What carries the argument
The 3D-Aware Transfer Pipeline, which reconstructs the reference hairstyle in 3D and re-renders it from the target viewpoint to enforce geometric consistency before compositing onto the bald source image.
If this is right
- The method supports hairstyle transfer when source and target differ greatly in viewpoint or scale, cases where missing hair must be synthesized.
- Results remain identity-preserving and pose-consistent across the transfer.
- Performance exceeds existing methods in both visual quality and quantitative metrics.
- The approach directly enables use cases in virtual try-on, augmented reality, and entertainment media.
Where Pith is reading between the lines
- The separation of bald conversion from geometry transfer could be applied to other facial attributes such as beards or accessories.
- The Baldy dataset might serve as a starting point for training models that generate or remove other hair-related features.
- Combining the pipeline with real-time 3D face tracking could support live hairstyle preview in video applications.
Load-bearing premise
The Bald Converter produces realistic bald faces and the 3D reconstruction accurately captures hairstyle geometry so it can be re-rendered from any viewpoint.
What would settle it
A collection of source-target image pairs with extreme pose and scale differences where the output hair either fails to match the expected 3D geometry when viewed from a new angle or looks inconsistent with the bald base would show the method does not achieve the claimed accuracy and consistency.
Figures













read the original abstract
Transferring hairstyles between images is an important but challenging task in computer graphics, computer vision, and visual effects. It enables users to explore new looks without physically altering their hair, with applications in virtual try-on systems, augmented reality, and entertainment. Most prior works operate best under small pose gaps, and they fall short under large viewpoint and scale differences, where missing hair content must be synthesized rather than transferred. We propose HairPort, a 3D-aware hairstyle transfer framework that attempts to solve these issues by explicitly separating hair removal from transfer and enforcing geometric consistency before synthesis. We introduce a Bald Converter, which produces realistic bald versions of faces through LoRA-based in-context adaptation of FLUX.1 Kontext. To train our Bald Converter, we introduce a new dataset, Baldy, containing 6,000 paired bald and original images across diverse identities and conditions. We also use a 3D-Aware Transfer Pipeline that reconstructs and re-renders the reference hairstyle from the target viewpoint before compositing it onto the source image. Being 3D aware, our method supports large pose and scale discrepancies between the source and target. Finally, a conditional flow-matching generator synthesizes the transferred result from the bald source and geometry-aligned reference guidance. Together, our method enables accurate, pose-consistent, and identity-preserving hairstyle transfer, outperforming existing methods both qualitatively and quantitatively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HairPort, a 3D-aware hairstyle transfer framework for images that handles large pose and scale differences. It introduces a Bald Converter (LoRA-based in-context adaptation of FLUX.1 Kontext) trained on the new Baldy dataset of 6,000 paired bald/original images, a 3D-Aware Transfer Pipeline that reconstructs and re-renders reference hairstyle geometry from the target viewpoint before compositing, and a conditional flow-matching generator for final synthesis. The central claim is that this enables accurate, pose-consistent, and identity-preserving transfers that outperform prior methods both qualitatively and quantitatively.
Significance. If the 3D reconstruction and transfer steps hold, the work would advance virtual try-on and AR applications by addressing a key limitation of prior 2D methods under large viewpoint changes. The explicit separation of hair removal from transfer, the new Baldy dataset, and the use of modern components (LoRA adaptation, flow-matching) are concrete strengths. The approach provides a falsifiable pipeline whose components can be ablated.
major comments (3)
- [§3] §3 (3D-Aware Transfer Pipeline): The central claim of pose-consistent transfer under large discrepancies rests on the assumption that the 3D reconstruction 'accurately captures hairstyle geometry for re-rendering from arbitrary viewpoints.' No quantitative metrics (e.g., strand-level reconstruction error, novel-view PSNR/SSIM on held-out poses, or ablation removing the 3D step) are referenced, which directly risks the downstream conditional flow-matching generator failing to deliver the claimed consistency.
- [§4] §4 (Quantitative Evaluation): The abstract asserts outperformance 'both qualitatively and quantitatively,' yet no tables, metrics (identity cosine similarity, pose error, FID under large pose gaps), or cross-method comparisons with error bars are cited. This is load-bearing for the superiority claim and cannot be verified from the stated results.
- [Bald Converter] Bald Converter description: The pipeline assumes the converter produces 'realistic bald versions' without hair-region artifacts that would break identity preservation. No ablation on converter quality (e.g., perceptual metrics on bald outputs or effect on final transfer identity scores) is provided, leaving the identity-preserving claim unsupported.
minor comments (2)
- [Related Work] The paper would benefit from explicit comparison to recent 3D hair modeling baselines (e.g., strand-based or Gaussian splatting methods) in the related work section.
- Notation for the flow-matching conditioning (bald source + geometry-aligned reference) could be formalized with an equation for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting gaps in quantitative validation. We address each major comment below and will perform a major revision to incorporate the requested metrics, ablations, and clarifications.
read point-by-point responses
-
Referee: [§3] §3 (3D-Aware Transfer Pipeline): The central claim of pose-consistent transfer under large discrepancies rests on the assumption that the 3D reconstruction 'accurately captures hairstyle geometry for re-rendering from arbitrary viewpoints.' No quantitative metrics (e.g., strand-level reconstruction error, novel-view PSNR/SSIM on held-out poses, or ablation removing the 3D step) are referenced, which directly risks the downstream conditional flow-matching generator failing to deliver the claimed consistency.
Authors: We agree that the 3D reconstruction requires explicit quantitative validation. The submitted manuscript relies primarily on qualitative results for this component. In the revised version we will add novel-view PSNR/SSIM metrics on held-out poses, strand-level error where measurable, and an ablation that removes the 3D re-rendering step to quantify its contribution to final pose consistency. These additions will appear in an expanded §3. revision: yes
-
Referee: [§4] §4 (Quantitative Evaluation): The abstract asserts outperformance 'both qualitatively and quantitatively,' yet no tables, metrics (identity cosine similarity, pose error, FID under large pose gaps), or cross-method comparisons with error bars are cited. This is load-bearing for the superiority claim and cannot be verified from the stated results.
Authors: We acknowledge that the submitted manuscript does not present the detailed quantitative tables or error bars referenced in the abstract. In revision we will expand §4 with tables reporting identity cosine similarity, pose error, and FID under large pose gaps, including cross-method comparisons and error bars. The abstract will be updated to explicitly cite these metrics and link to the new tables. revision: yes
-
Referee: [Bald Converter] Bald Converter description: The pipeline assumes the converter produces 'realistic bald versions' without hair-region artifacts that would break identity preservation. No ablation on converter quality (e.g., perceptual metrics on bald outputs or effect on final transfer identity scores) is provided, leaving the identity-preserving claim unsupported.
Authors: We agree that an ablation study on Bald Converter quality is needed. The revised manuscript will include perceptual metrics (e.g., LPIPS) on bald outputs versus ground truth and will measure the converter's effect on downstream identity preservation scores in the transfer pipeline. This will be added as a dedicated ablation subsection. revision: yes
Circularity Check
No circularity: method components are independently described and trained
full rationale
The paper introduces a Bald Converter via LoRA adaptation on a newly collected Baldy dataset, a 3D reconstruction/re-rendering pipeline, and a conditional flow-matching generator. These are presented as engineering steps with external training data and standard techniques; no equations, fitted parameters, or predictions are shown reducing to self-defined inputs. No self-citation chains or uniqueness theorems are invoked as load-bearing. The central claim is an empirical performance statement, not a derivation that collapses by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Bald Converter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2022 , eprint=
Style Your Hair: Latent Optimization for Pose-Invariant Hairstyle Transfer via Local-Style-Aware Hair Alignment , author=. 2022 , eprint=
2022
-
[2]
2022 , eprint=
HairFIT: Pose-Invariant Hairstyle Transfer via Flow-based Hair Alignment and Semantic-Region-Aware Inpainting , author=. 2022 , eprint=
2022
-
[3]
2020 , eprint=
MichiGAN: Multi-Input-Conditioned Hair Image Generation for Portrait Editing , author=. 2020 , eprint=
2020
-
[4]
Barbershop: GAN-based image compositing using segmentation masks , volume=
Zhu, Peihao and Abdal, Rameen and Femiani, John and Wonka, Peter , year=. Barbershop: GAN-based image compositing using segmentation masks , volume=. ACM Transactions on Graphics , publisher=. doi:10.1145/3478513.3480537 , number=
-
[5]
2021 , eprint=
LOHO: Latent Optimization of Hairstyles via Orthogonalization , author=. 2021 , eprint=
2021
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wu, Yiqian and Yang, Yong-Liang and Jin, Xiaogang , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[7]
2022 , eprint=
HairCLIP: Design Your Hair by Text and Reference Image , author=. 2022 , eprint=
2022
-
[8]
2023 , eprint=
HairCLIPv2: Unifying Hair Editing via Proxy Feature Blending , author=. 2023 , eprint=
2023
-
[9]
2019 , eprint=
A Style-Based Generator Architecture for Generative Adversarial Networks , author=. 2019 , eprint=
2019
-
[10]
2024 , eprint=
Stable-Hair: Real-World Hair Transfer via Diffusion Model , author=. 2024 , eprint=
2024
-
[11]
2025 , eprint=
Stable-Hair v2: Real-World Hair Transfer via Multiple-View Diffusion Model , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
Edit Transfer: Learning Image Editing via Vision In-Context Relations , author=. 2025 , eprint=
2025
-
[14]
2024 , eprint=
HairFastGAN: Realistic and Robust Hair Transfer with a Fast Encoder-Based Approach , author=. 2024 , eprint=
2024
-
[15]
2024 , eprint=
What to Preserve and What to Transfer: Faithful, Identity-Preserving Diffusion-based Hairstyle Transfer , author=. 2024 , eprint=
2024
-
[16]
Hair-GANs: Recovering 3D Hair Structure from a Single Image
Zhang, Meng and Zheng, Youyi , title = ". doi:10.48550/arXiv.1811.06229 , archivePrefix =. 1811.06229 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1811.06229
-
[17]
Advances in Intelligent Systems and Computing , publisher =
GAN with Multivariate Disentangling for Controllable Hair Editing , author =. Advances in Intelligent Systems and Computing , publisher =
-
[18]
Computer Vision -- ECCV 2022 , series=
HairNet: Hairstyle Transfer with Pose Changes , author=. Computer Vision -- ECCV 2022 , series=. 2022 , doi=
2022
-
[19]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Hairnerf: Geometry-aware image synthesis for hairstyle transfer , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=. 2023 , publisher=
2023
-
[20]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Khwanmuang, Sasikarn and Phongthawee, Pakkapon and Sangkloy, Patsorn and Suwajanakorn, Supasorn , title =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =. 2023 , publisher =
2023
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Few-shot head swapping in the wild , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2022 , publisher=
2022
-
[22]
2022 , eprint=
Hierarchical Text-Conditional Image Generation with CLIP Latents , author=. 2022 , eprint=
2022
-
[23]
2022 , eprint=
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding , author=. 2022 , eprint=
2022
-
[24]
SKED: Sketch-guided Text-based 3D Editing , booktitle =
Aryan Mikaeili and Or Perel and Mehdi Safaee and Daniel Cohen-Or and Ali Mahdavi-Amiri , pages=. SKED: Sketch-guided Text-based 3D Editing , booktitle =
-
[25]
2024 , howpublished=
Black Forest Labs , title=. 2024 , howpublished=
2024
-
[26]
2025 , eprint =
ASIA: Adaptive 3D Segmentation Using Few Image Annotations , author =. 2025 , eprint =
2025
-
[27]
2023 , eprint=
Sdxl: Improving latent diffusion models for high-resolution image synthesis , author=. 2023 , eprint=
2023
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=. 2022 , publisher=
2022
-
[29]
2024 , eprint=
SLiMe: Segment Like Me , author=. 2024 , eprint=
2024
-
[30]
2024 , eprint=
EmerDiff: Emerging Pixel-level Semantic Knowledge in Diffusion Models , author=. 2024 , eprint=
2024
-
[31]
2023 , eprint=
MasaCtrl: Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing , author=. 2023 , eprint=
2023
-
[32]
2025 , eprint=
h-Edit: Effective and Flexible Diffusion-Based Editing via Doob's h-Transform , author=. 2025 , eprint=
2025
-
[33]
2024 , eprint=
Zero-Shot Video Semantic Segmentation based on Pre-Trained Diffusion Models , author=. 2024 , eprint=
2024
-
[34]
2025 , eprint=
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space , author=. 2025 , eprint=
2025
-
[35]
2019 , eprint=
Expressive Body Capture: 3D Hands, Face, and Body from a Single Image , author=. 2019 , eprint=
2019
-
[36]
and Li, Hao and Romero, Javier , journal=
Li, Tianye and Bolkart, Timo and Black, Michael J. and Li, Hao and Romero, Javier , journal=. Learning a Model of Facial Shape and Expression from. 2017 , month=nov, doi=
2017
-
[37]
2025 , eprint=
DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models , author=. 2025 , eprint=
2025
-
[38]
ACM Transactions on Graphics (Proceedings of SIGGRAPH) , volume =
Liwen Hu and Chongyang Ma and Linjie Luo and Hao Li , title =. ACM Transactions on Graphics (Proceedings of SIGGRAPH) , volume =. 2015 , url =
2015
-
[39]
2024 , howpublished =
Hair20K: A Large 3D Hairstyle Database for Hair Modeling , author =. 2024 , howpublished =
2024
-
[40]
Computer Graphics Forum , volume =
Matt Jen-Yuan Chiang and Benedikt Bitterli and Chuck Tappan and Brent Burley , title =. Computer Graphics Forum , volume =. 2016 , doi =
2016
-
[41]
2023 , eprint=
BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion , author=. 2023 , eprint=
2023
-
[42]
2024 , note =
ControlNet++: All-in-one ControlNet for Image Generation and Editing , author =. 2024 , note =
2024
-
[43]
Bovik and Hamid R
Zhou Wang and Alan C. Bovik and Hamid R. Sheikh and Eero P. Simoncelli , title =. IEEE Transactions on Image Processing , volume =
-
[44]
Jiankang Deng and Jia Guo and Niannan Xue and Stefanos Zafeiriou , title =. Proc. CVPR , pages =. 2019 , publisher =
2019
-
[45]
Jia Guo and Jiankang Deng and others , title =
-
[46]
Alec Radford and Jong Wook Kim and Chris Hallacy and Aditya Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever , title =. Proc. ICML , series =. 2021 , publisher =
2021
-
[47]
2025 , eprint=
DINOv3 , author=. 2025 , eprint=
2025
-
[48]
2025 , eprint=
Ultra3D: Efficient and High-Fidelity 3D Generation with Part Attention , author=. 2025 , eprint=
2025
-
[49]
2025 , eprint=
Hi3DGen: High-fidelity 3D Geometry Generation from Images via Normal Bridging , author=. 2025 , eprint=
2025
-
[50]
2025 , eprint=
Insert Anything: Image Insertion via In-Context Editing in DiT , author=. 2025 , eprint=
2025
-
[51]
2024 , eprint=
AnyDoor: Zero-shot Object-level Image Customization , author=. 2024 , eprint=
2024
-
[52]
2026 , howpublished=
Black Forest Labs , title=. 2026 , howpublished=
2026
-
[53]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Cao, Zhe and Simon, Tomas and Wei, Shih-En and Sheikh, Yaser , title=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2017 , publisher=
2017
-
[54]
2024 , howpublished=
2024
-
[55]
2025 , month=nov, howpublished=
Introducing. 2025 , month=nov, howpublished=
2025
-
[56]
2018 , eprint=
Progressive Growing of GANs for Improved Quality, Stability, and Variation , author=. 2018 , eprint=
2018
-
[57]
2024 , eprint=
Zero-shot Image Editing with Reference Imitation , author=. 2024 , eprint=
2024
-
[58]
2018 , eprint=
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , author=. 2018 , eprint=
2018
-
[59]
2025 , eprint=
SAM 3: Segment Anything with Concepts , author=. 2025 , eprint=
2025
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Mv-adapter: Multi-view consistent image generation made easy , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=. 2025 , publisher=
2025
-
[61]
2025 , eprint=
SHeaP: Self-Supervised Head Geometry Predictor Learned via 2D Gaussians , author=. 2025 , eprint=
2025
-
[62]
2025 , eprint=
Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.