Arbor: Tree Search as a Cognition Layer for Autonomous Agents
Pith reviewed 2026-06-27 09:58 UTC · model grok-4.3
The pith
Arbor maintains an explicit search tree of scored hypotheses as shared working memory so multi-agent systems can run stable, multi-day optimization in complex spaces like full-stack LLM inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
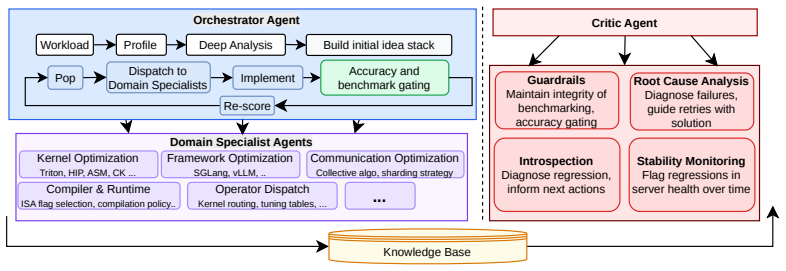
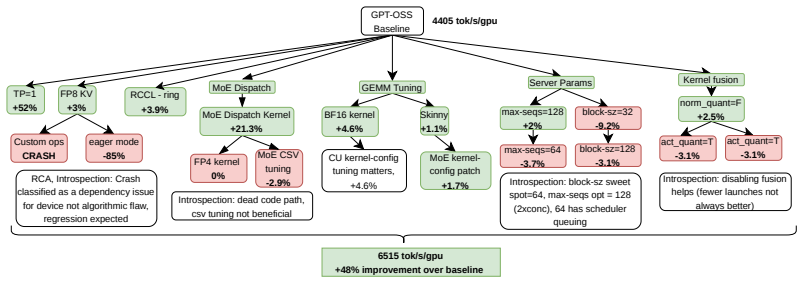
Arbor maintains an explicit search tree of scored hypotheses that serves as the shared working memory across agents, evolving with every measurement, treating failures as diagnostic signals that reshape subsequent exploration, and expanding as prior successes shift the bottleneck distribution; it pairs an Orchestrator that drives optimization by delegating to Domain Specialists with a Critic that safeguards stability through root-cause analysis and measurement validation, enabling fully autonomous multi-day campaigns on full-stack LLM inference optimization.
What carries the argument
Explicit search tree of scored hypotheses maintained as shared working memory across agents, combined with Orchestrator-Critic checks-and-balances architecture.
If this is right
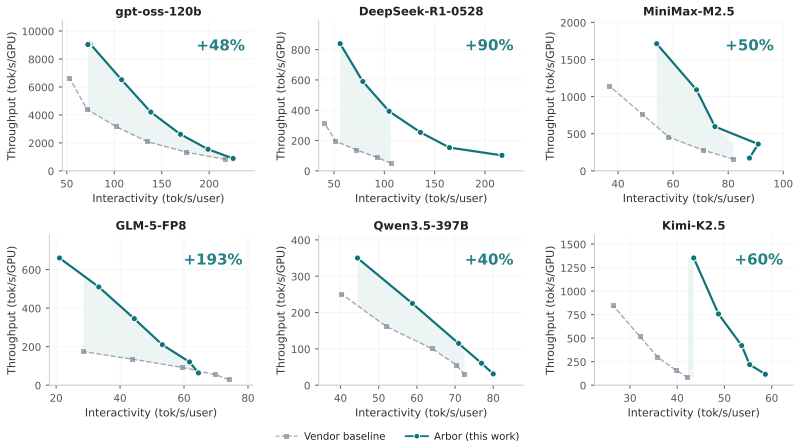
- Delivers up to 193% inference throughput-latency Pareto improvement over vendor-optimized baselines.
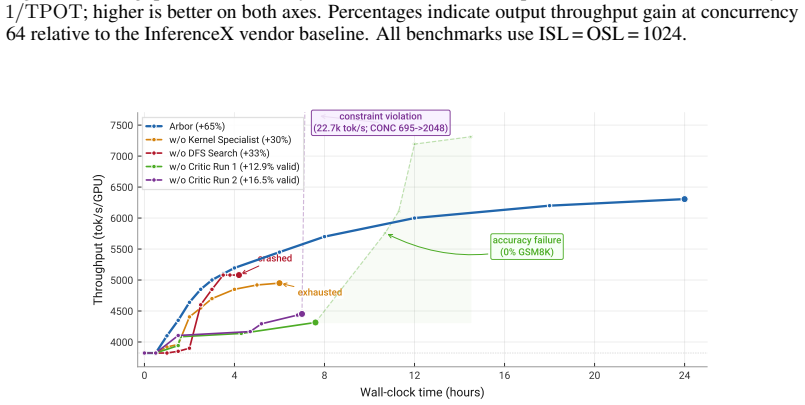
- Prevents the irrecoverable crashes that occur in single-agent runs within hours.
- Generalizes across multiple generations of hardware platforms with run-to-run variance within 2 percentage points.
- Allows agent capabilities to be decomposed into hard domain skills and soft coordination protocols that compose reliably.
- Supports treating the search tree as evolving collective memory that shifts focus as bottlenecks move.
Where Pith is reading between the lines
- The same tree-as-memory structure could be tested on other stateful engineering optimization tasks outside LLM stacks.
- Adding more specialized agents might extend the checks-and-balances pattern without losing the stability observed with two agents.
- Low run-to-run variance suggests the method could support standardized autonomous pipelines that require minimal human oversight after setup.
Load-bearing premise
That an explicit shared search tree of scored hypotheses plus the dual-agent checks-and-balances will consistently convert failures into diagnostic signals that keep the campaign stable rather than letting errors accumulate into collapse.
What would settle it
A side-by-side multi-day run on the same LLM inference optimization task in which the single-agent baseline without the tree crashes irrecoverably while Arbor continues to improve and remains stable.
Figures
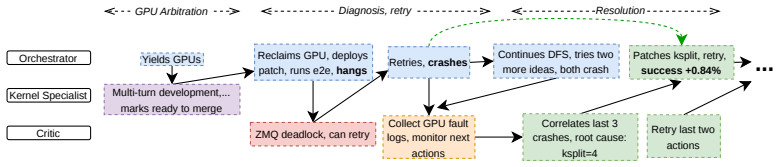
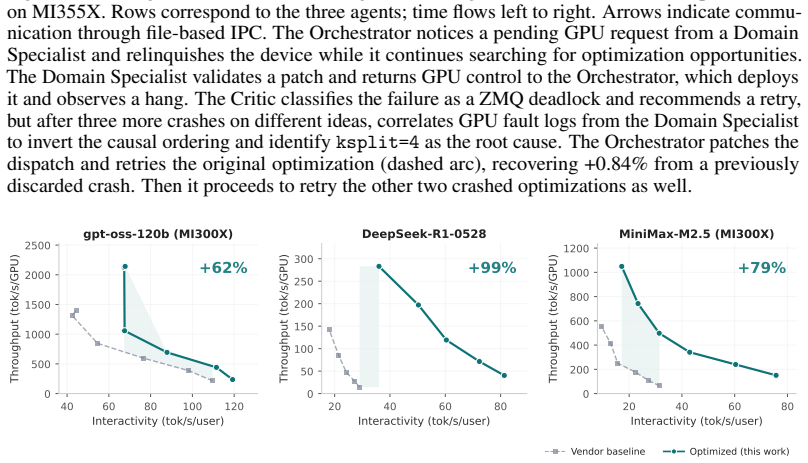
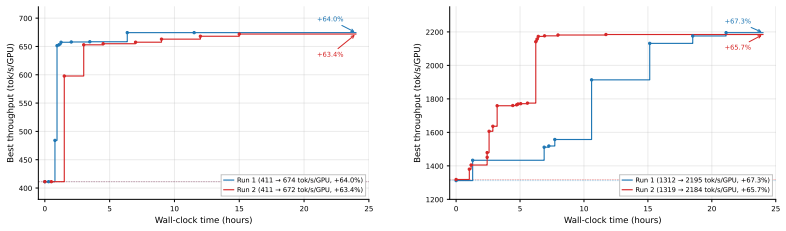
read the original abstract
Arbor is a multi-agent framework that introduces structured tree search as a cognition layer for autonomous agents operating in large, stateful action spaces. Prior autonomous optimization systems operate on isolated targets with stateless evaluation. Arbor instead maintains an explicit search tree of scored hypotheses that serves as the shared working memory across agents, evolving with every measurement, treating failures as diagnostic signal that reshapes subsequent exploration, and expanding as prior successes shift the bottleneck distribution. We validate Arbor on full-stack LLM inference optimization, a domain where achieving peak performance has historically required coordinated effort from engineering teams across the application, framework, compiler, kernel, and hardware stack. Arbor pairs an Orchestrator agent, which drives optimization by delegating to Domain Specialists across the inference stack, with a Critic agent that safeguards stability through root-cause analysis, introspection, and measurement validation -- a checks-and-balances architecture where neither agent can unilaterally drive the system. Agent capabilities are decomposed into hard skills (domain expertise) and soft skills (coordination protocols that determine how contributions compose), enabling fully autonomous multi-day campaigns. Arbor achieves up to 193% inference throughput-latency Pareto improvement over vendor-optimized baselines, while a single agent without the harness plateaus at +33% throughput improvement and crashes irrecoverably within hours. Arbor generalizes to multiple generations of hardware platform, and run-to-run variance is within 2 percentage points demonstrating that the method is hardware-agnostic and reproducible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Arbor, a multi-agent framework that uses structured tree search as a cognition layer for autonomous agents in large stateful action spaces. It describes an Orchestrator agent delegating to domain specialists paired with a Critic agent for stability checks, applied to full-stack LLM inference optimization. The central claims are up to 193% inference throughput-latency Pareto improvement over vendor baselines, multi-day campaign stability via shared scored-hypothesis trees and failure-as-diagnostic signals, generalization across hardware generations, and contrast with a single-agent baseline that plateaus at +33% and crashes irrecoverably within hours.
Significance. If the empirical claims hold under scrutiny, the work could be significant for autonomous agent research by showing how explicit search trees as shared memory plus dual-agent checks-and-balances can sustain stable, long-running optimization campaigns in complex domains. The reported low run-to-run variance and hardware-agnostic results would be a notable strength if substantiated.
major comments (2)
- [Abstract] Abstract: The performance and stability claims (193% Pareto improvement, single-agent crash within hours, multi-day stability via tree + Orchestrator-Critic) are asserted without any experimental protocol, benchmark descriptions, scoring function, failure-handling rules, measurement methodology, or dataset details. This gap is load-bearing because the central contrast between the multi-agent harness and the crashing baseline cannot be evaluated from the provided text.
- [Abstract] Abstract: No error bars, run counts, or validation steps are supplied for the throughput-latency numbers or the 2-percentage-point variance claim, preventing assessment of whether the reported outcomes follow from the architecture or from unstated implementation choices.
minor comments (1)
- The manuscript would benefit from an explicit experimental section (or appendix) detailing the optimization targets, tree scoring, and stability metrics to make the claims verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The concerns about missing experimental details and statistical reporting are valid for a self-contained abstract, and we will revise accordingly while preserving conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance and stability claims (193% Pareto improvement, single-agent crash within hours, multi-day stability via tree + Orchestrator-Critic) are asserted without any experimental protocol, benchmark descriptions, scoring function, failure-handling rules, measurement methodology, or dataset details. This gap is load-bearing because the central contrast between the multi-agent harness and the crashing baseline cannot be evaluated from the provided text.
Authors: We agree the abstract omits these elements due to length limits. The full manuscript contains sections detailing the benchmark (full-stack LLM inference optimization), scoring (throughput-latency Pareto frontier), failure handling (Critic-driven root-cause analysis treating failures as diagnostic signals), and measurement protocol. To address the load-bearing gap, we will expand the abstract with a concise description of the domain, baseline, tree-based shared memory, and Orchestrator-Critic checks-and-balances. revision: yes
-
Referee: [Abstract] Abstract: No error bars, run counts, or validation steps are supplied for the throughput-latency numbers or the 2-percentage-point variance claim, preventing assessment of whether the reported outcomes follow from the architecture or from unstated implementation choices.
Authors: The reported 2-percentage-point variance is based on repeated multi-day campaigns across hardware generations, but the abstract does not include run counts or error bars. We will revise the abstract to state the number of independent runs and observed variance, and ensure the methods section explicitly describes the validation protocol so readers can assess reproducibility. revision: yes
Circularity Check
No circularity; empirical system description without derivations
full rationale
The paper is a purely empirical description of a multi-agent framework (Arbor) that uses tree search as shared memory and an Orchestrator-Critic architecture. No equations, derivations, fitted parameters, or first-principles predictions appear in the abstract or full text. Performance claims (193% Pareto improvement, single-agent crash) are presented as measured experimental outcomes rather than results derived from any internal model or self-referential input. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing way. The work is therefore self-contained against external benchmarks with no reduction of claims to their own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Orchestrator agent
no independent evidence
-
Critic agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SWE-bench: Can Language Models Resolve Real-world Github Issues? , url =
Jimenez, Carlos E and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =. SWE-bench: Can Language Models Resolve Real-world Github Issues? , url =
-
[2]
2024 , url=
John Yang and Carlos E Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik R Narasimhan and Ofir Press , booktitle=. 2024 , url=
2024
-
[3]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents , url =
Wang, Xingyao and Li, Boxuan and Song, Yufan and Xu, Frank F and Tang, Xiangru and Zhuge, Mingchen and Pan, Jiayi and Song, Yueqi and Li, Bowen and Singh, Jaskirat and Tran, Hoang and Li, Fuqiang and Ma, Ren and Zheng, Mingzhang and Qian, Bill and Shao, Daniel and Muennighoff, Niklas and Zhang, Yizhe and Hui, Binyuan and Lin, Junyang and Brennan, Robert a...
-
[4]
2026 , url=
Bing Xu, Terry Chen, Fengzhe Zhou, Tianqi Chen, Yangqing Jia, Vinod Grover, Haicheng Wu, Wei Liu, Craig Wittenbrink, Wen-mei Hwu, Roger Bringmann, Ming-Yu Liu, Luis Ceze, Michael Lightstone, Humphrey Shi , journal=. 2026 , url=
2026
-
[5]
43 Nature625(7995), 468–475 (2024) https://doi.org/10.1038/s41586-023-06924-6
Romera-Paredes, Bernardino and Barekatain, Mohammadamin and Novikov, Alexander and Balog, Matej and Kumar, M. Pawan and Dupont, Emilien and Ruiz, Francisco J. R. and Ellenberg, Jordan S. and Wang, Pengming and Fawzi, Omar and Kohli, Pushmeet and Fawzi, Alhussein , title=. Nature , year=. doi:10.1038/s41586-023-06924-6 , url=
-
[6]
2025 , eprint=
AlphaEvolve: A coding agent for scientific and algorithmic discovery , author=. 2025 , eprint=
2025
-
[7]
2026 , eprint=
AVO: Agentic Variation Operators for Autonomous Evolutionary Search , author=. 2026 , eprint=
2026
-
[8]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , url =
Dao, Tri and Fu, Dan and Ermon, Stefano and Rudra, Atri and R\'. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , url =. Advances in Neural Information Processing Systems , editor =
-
[9]
2026 , eprint=
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling , author=. 2026 , eprint=
2026
-
[10]
Proceedings of the 13th USENIX Conference on Operating Systems Design and Implementation , pages =
Chen, Tianqi and Moreau, Thierry and Jiang, Ziheng and Zheng, Lianmin and Yan, Eddie and Cowan, Meghan and Shen, Haichen and Wang, Leyuan and Hu, Yuwei and Ceze, Luis and Guestrin, Carlos and Krishnamurthy, Arvind , title =. Proceedings of the 13th USENIX Conference on Operating Systems Design and Implementation , pages =. 2018 , isbn =
2018
-
[11]
and Stoica, Ion , title =
Zheng, Lianmin and Jia, Chengfan and Sun, Minmin and Wu, Zhao and Yu, Cody Hao and Haj-Ali, Ameer and Wang, Yida and Yang, Jun and Zhuo, Danyang and Sen, Koushik and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 14th USENIX Conference on Operating Systems Design and Implementation , articleno =. 2020 , isbn =
2020
-
[12]
and Cao, Yuan and Narasimhan, Karthik , title =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Thomas L. and Cao, Yuan and Narasimhan, Karthik , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[13]
2023 , html =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , html =
2023
-
[14]
Tillet, Philippe and Kung, H. T. and Cox, David , title =. Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages , pages =. 2019 , isbn =. doi:10.1145/3315508.3329973 , abstract =
-
[15]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =. 2023 , isbn =. doi:10.1145/3600006.3613165 , abstract =
-
[16]
and Barrett, Clark and Sheng, Ying , title =
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E. and Barrett, Clark and Sheng, Ying , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[17]
Ragan-Kelley, Jonathan and Barnes, Connelly and Adams, Andrew and Paris, Sylvain and Durand, Fr\'. Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines , year =. Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation , pages =. doi:10.1145/2491956.24...
-
[18]
Evolution Through Large Models
Lehman, Joel and Gordon, Jonathan and Jain, Shawn and Ndousse, Kamal and Yeh, Cathy and Stanley, Kenneth O. Evolution Through Large Models. Handbook of Evolutionary Machine Learning. 2024. doi:10.1007/978-981-99-3814-8_11
-
[19]
Learning to optimize halide with tree search and random programs , year =
Adams, Andrew and Ma, Karima and Anderson, Luke and Baghdadi, Riyadh and Li, Tzu-Mao and Gharbi, Micha\". Learning to optimize halide with tree search and random programs , year =. ACM Trans. Graph. , month = jul, articleno =. doi:10.1145/3306346.3322967 , abstract =
-
[20]
Schkufza, Eric and Sharma, Rahul and Aiken, Alex , title =. Proceedings of the Eighteenth International Conference on Architectural Support for Programming Languages and Operating Systems , pages =. 2013 , isbn =. doi:10.1145/2451116.2451150 , abstract =
-
[21]
International Conference on Learning Representations , year=
Neural Architecture Search with Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[22]
2019 , url=
Hanxiao Liu and Karen Simonyan and Yiming Yang , booktitle=. 2019 , url=
2019
-
[23]
, title =
Snoek, Jasper and Larochelle, Hugo and Adams, Ryan P. , title =. Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2 , pages =. 2012 , publisher =
2012
-
[24]
Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages =
Non-stochastic Best Arm Identification and Hyperparameter Optimization , author =. Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages =. 2016 , editor =
2016
-
[25]
2024 , eprint=
ChatDev: Communicative Agents for Software Development , author=. 2024 , eprint=
2024
-
[26]
Sirui Hong and Mingchen Zhuge and Jonathan Chen and Xiawu Zheng and Yuheng Cheng and Jinlin Wang and Ceyao Zhang and Zili Wang and Steven Ka Shing Yau and Zijuan Lin and Liyang Zhou and Chenyu Ran and Lingfeng Xiao and Chenglin Wu and J. Meta. The Twelfth International Conference on Learning Representations , year=
-
[27]
2011 , publisher=
Kahneman, Daniel , title=. 2011 , publisher=
2011
-
[28]
2026 , eprint=
Autonomous Evolution of EDA Tools: Multi-Agent Self-Evolved ABC , author=. 2026 , eprint=
2026
-
[29]
2026 , eprint=
KernelSkill: A Multi-Agent Framework for GPU Kernel Optimization , author=. 2026 , eprint=
2026
-
[30]
2025 , eprint=
Astra: A Multi-Agent System for GPU Kernel Performance Optimization , author=. 2025 , eprint=
2025
-
[31]
2026 , eprint=
AccelOpt: A Self-Improving LLM Agentic System for AI Accelerator Kernel Optimization , author=. 2026 , eprint=
2026
-
[32]
2025 , eprint=
Autonomous Code Evolution Meets NP-Completeness , author=. 2025 , eprint=
2025
-
[33]
2026 , url=
Juncheng Dong and Yang Yang and Tao Liu and Yang Wang and Feng Qi and Vahid Tarokh and Kaushik Rangadurai and Shuang Yang , booktitle=. 2026 , url=
2026
-
[34]
2026 , howpublished =
2026
-
[35]
Bandit Based Monte-Carlo Planning
Kocsis, Levente and Szepesv \'a ri, Csaba. Bandit Based Monte-Carlo Planning. Machine Learning: ECML 2006. 2006
2006
-
[36]
and Powley, Edward and Whitehouse, Daniel and Lucas, Simon M
Browne, Cameron B. and Powley, Edward and Whitehouse, Daniel and Lucas, Simon M. and Cowling, Peter I. and Rohlfshagen, Philipp and Tavener, Stephen and Perez, Diego and Samothrakis, Spyridon and Colton, Simon , journal=. A Survey of Monte Carlo Tree Search Methods , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.