Pythagoras-Prover: Advancing Efficient Formal Proving via Augmented Lean Formalisation
Pith reviewed 2026-06-27 09:54 UTC · model grok-4.3
The pith
Augmented Lean formalisation lets 4B and 32B models outperform far larger theorem provers on MiniF2F and PutnamBench.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
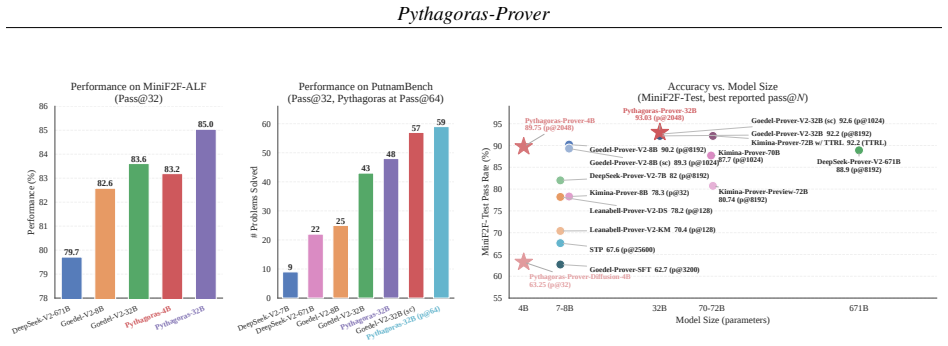
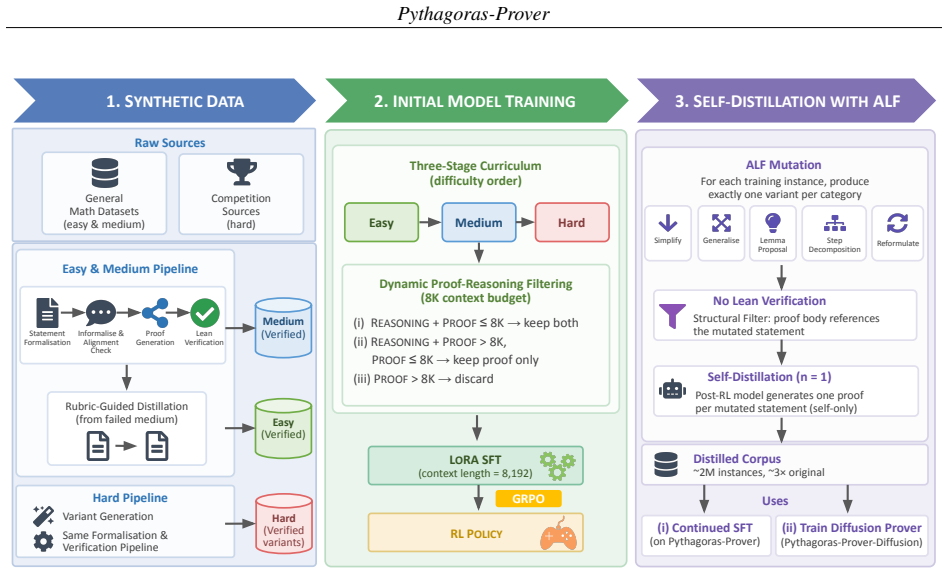
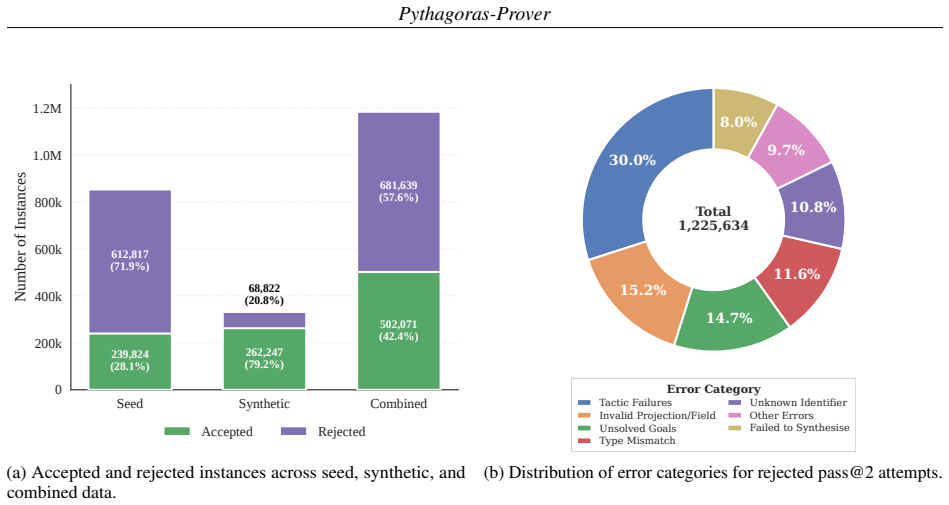
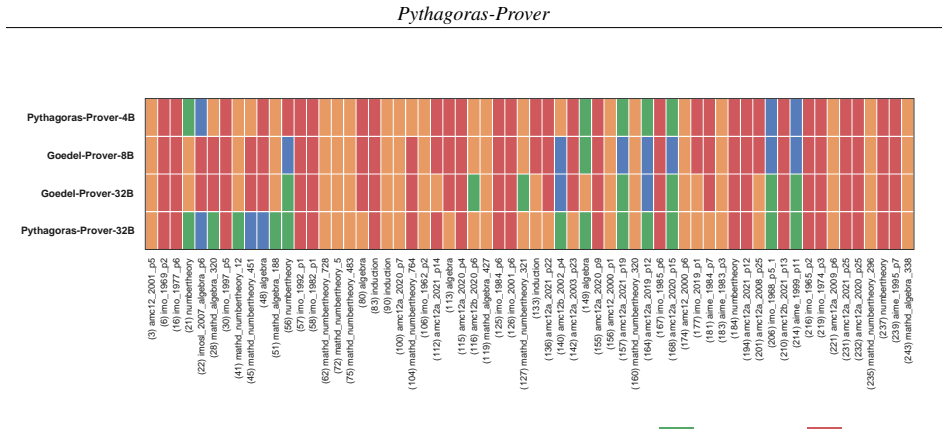
Pythagoras-Prover-4B reaches 86.1 percent pass@32 on MiniF2F-Test, surpassing DeepSeek-Prover-V2-671B's 82.4 percent with roughly 167 times fewer parameters, while Pythagoras-Prover-32B attains 93.0 percent on the same test and solves 93 of 672 PutnamBench problems. These outcomes follow from training on a Lean-verified corpus divided into easy-medium-hard tiers for progressive learning, dynamic proof-reasoning filtering, and Augmented Lean Formalisation that perturbs known statements and populates variants via self-distillation to enlarge the training signal.
What carries the argument
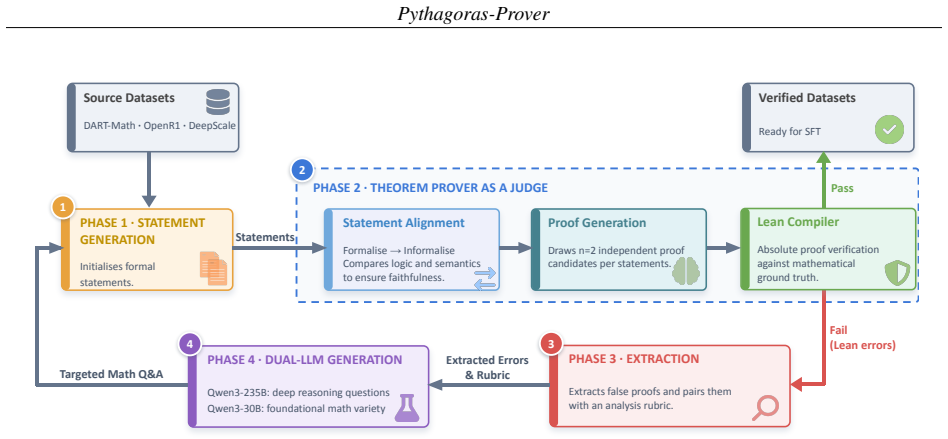
Augmented Lean Formalisation (ALF), a process that perturbs known formal statements while preserving their formal character and fills the variants with self-distilled proofs to supply extra training signal without full verification of each instance.
If this is right
- Curriculum ordering from short simple proofs to longer harder ones allows models to acquire proof skills progressively within fixed context budgets.
- Dynamic filtering that keeps only informative traces while respecting token limits makes supervised fine-tuning practical on scarce verified data.
- A diffusion-based prover offers an iterative refinement path at inference time that differs from standard autoregressive sampling.
- The 32B model remains strongest on the contamination-sensitive MiniF2F-ALF benchmark while the 4B model matches prior state-of-the-art accuracy there.
Where Pith is reading between the lines
- The same augmentation approach could be applied to other interactive theorem provers beyond Lean to reduce dependence on surface forms of statements.
- If the unverified mutations prove reliable across domains, the method could lower the barrier to training formal systems for domains with even scarcer verified data.
- Releasing MiniF2F-ALF as a harder benchmark suggests that future work should routinely test on mutated variants to guard against overfitting to surface forms.
Load-bearing premise
Mutated formal statements generated by Augmented Lean Formalisation via self-distillation supply valid and useful training signal even though they are not formally verified for every instance.
What would settle it
Run the trained models on a fresh collection of formally verified mutated statements or on MiniF2F-ALF with every variant manually checked; a sharp drop relative to the reported numbers would indicate the unverified mutations were not supplying reliable signal.
Figures


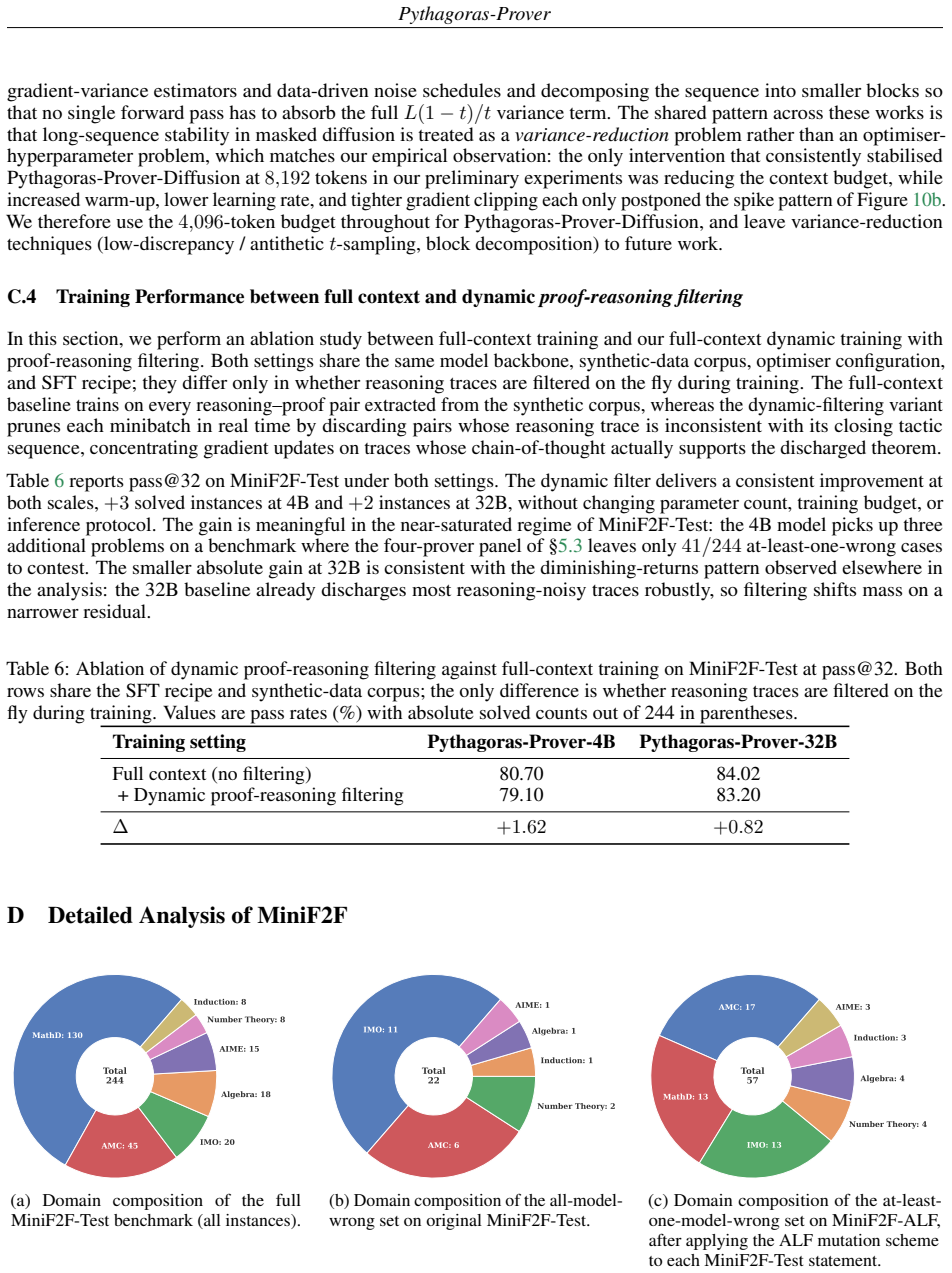
read the original abstract
Modern Lean theorem provers achieve strong performance only with substantial training and inference compute, driven in part by scarce verified proof data and the long reasoning traces of formal proof search, making both supervised fine-tuning (SFT) and sampling expensive. We introduce Pythagoras-Prover, a compute-efficient open-source family of Lean theorem provers built for practical compute budgets. The family spans two generation paradigms: autoregressive models at 4B and 32B parameters, and a first proof-of-concept diffusion-based prover (4B) that iteratively refines Lean proofs at inference time. For training efficiency, we build a Lean-verified corpus stratified into easy, medium, and hard problems for curriculum SFT, so models acquire proof skills progressively from shorter, simpler proofs to longer, harder ones. During SFT, a dynamic proof-reasoning filtering scheme preserves informative proof traces while keeping each instance within an 8k-token context budget. We also introduce Augmented Lean Formalisation (ALF), which expands scarce verified corpora into variants of formal statements, populated via self-distillation for extra training signal without formally verifying every mutated instance. By perturbing known problems while preserving their formal character, ALF reduces reliance on any statement's surface form. Empirically, Pythagoras-Prover-4B surpasses DeepSeek-Prover-V2-671B at pass@32 on MiniF2F-Test (86.1% vs 82.4%) with ~167x fewer parameters, while Pythagoras-Prover-32B sets the open-source state of the art at 93.0% on MiniF2F-Test and solves 93 of 672 PutnamBench problems. We release MiniF2F-ALF, an ALF-mutated contamination-sensitive benchmark on which every evaluated model loses accuracy; here our 32B remains strongest and our 4B matches the prior state of the art, Goedel-Prover-V2-32B.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Pythagoras-Prover, a family of parameter-efficient Lean theorem provers (autoregressive 4B/32B models and a 4B diffusion model) trained via curriculum SFT on a stratified Lean-verified corpus with dynamic proof filtering. It proposes Augmented Lean Formalisation (ALF) to generate mutated formal statements via self-distillation without per-instance verification, claiming this expands training data while preserving formal character. Key results: the 4B model achieves 86.1% pass@32 on MiniF2F-Test (surpassing DeepSeek-Prover-V2-671B's 82.4%), the 32B reaches 93.0% (open-source SOTA) and solves 93/672 PutnamBench problems; a new MiniF2F-ALF benchmark is released where all models drop in accuracy.
Significance. If the performance claims and ALF validity hold, the work demonstrates that smaller models can outperform much larger ones on formal proving benchmarks through data augmentation and curriculum training, advancing practical compute-efficient provers. The release of MiniF2F-ALF as a contamination-sensitive test set and the open-source models are concrete strengths that enable further verification of the results.
major comments (2)
- [Abstract / ALF section] Abstract and ALF description (likely §3): the central training pipeline relies on the unverified claim that ALF self-distilled mutations 'preserve their formal character' and logical validity without Lean checking every instance. No empirical validation (e.g., manual audit rate, semantic equivalence checks, or error analysis on a sample of mutations) is reported, which directly undermines the claim that the observed gains reflect improved proof skill rather than noisy or invalid training signal.
- [Experimental results section] Experimental results (likely §4, Table on MiniF2F-Test): headline numbers such as 86.1% (4B) and 93.0% (32B) at pass@32 are presented without run-to-run variance, statistical tests, exact train/eval splits, or confirmation that ALF mutations were excluded from evaluation data. This makes it impossible to assess robustness of the comparison to DeepSeek-Prover-V2-671B.
minor comments (2)
- [Model description] The diffusion-based 4B prover is mentioned as a proof-of-concept but receives little quantitative comparison to the autoregressive models; clarify its role and results relative to the main claims.
- [Training methodology] Notation for pass@k and context-length filtering could be made more precise with explicit equations or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / ALF section] Abstract and ALF description (likely §3): the central training pipeline relies on the unverified claim that ALF self-distilled mutations 'preserve their formal character' and logical validity without Lean checking every instance. No empirical validation (e.g., manual audit rate, semantic equivalence checks, or error analysis on a sample of mutations) is reported, which directly undermines the claim that the observed gains reflect improved proof skill rather than noisy or invalid training signal.
Authors: We acknowledge that the manuscript does not report a quantitative error analysis or manual audit of ALF mutations. ALF generates variants via self-distillation from Lean-verified statements using syntactic perturbations intended to maintain logical structure. To address this, the revised manuscript will add an appendix reporting a manual audit of 200 sampled mutations, including the rate at which they type-check and preserve semantic equivalence under Lean. This will provide empirical support for the training signal quality. revision: yes
-
Referee: [Experimental results section] Experimental results (likely §4, Table on MiniF2F-Test): headline numbers such as 86.1% (4B) and 93.0% (32B) at pass@32 are presented without run-to-run variance, statistical tests, exact train/eval splits, or confirmation that ALF mutations were excluded from evaluation data. This makes it impossible to assess robustness of the comparison to DeepSeek-Prover-V2-671B.
Authors: The reported figures are from single runs owing to training compute limits. The revised version will explicitly state the train/eval splits, confirm that ALF mutations were generated only from the training corpus (and thus absent from MiniF2F-Test), and note the single-run limitation. We will attempt to add variance from additional runs if resources allow; otherwise the limitation will be stated clearly. revision: partial
Circularity Check
No significant circularity; empirical results on held-out benchmarks
full rationale
The paper reports pass rates measured on standard held-out benchmarks (MiniF2F-Test, PutnamBench) after training on a separately constructed corpus that includes ALF-augmented statements. No equations, fitted parameters, or self-citations reduce the reported accuracies to quantities defined by the evaluation data itself. The ALF perturbation claim is an unverified modeling assumption rather than a definitional loop, and the central performance numbers remain independent measurements.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Lean theorem prover correctly verifies the validity of proofs in the corpus and benchmarks.
- ad hoc to paper Self-distilled mutations generated by ALF preserve the formal character and logical validity of the original statements.
Reference graph
Works this paper leans on
-
[1]
URLhttps://aclanthology.org/2025.emnlp-main.1024/
doi: 10.18653/v1/2025.emnlp-main.1024. URLhttps://aclanthology.org/2025.emnlp-main.1024/. Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison- Burch. Faithful Chain-of-Thought Reasoning. In Jong C. Park, Yuki Arase, Baotian Hu, Wei Lu, Derry Wijaya, Ayu 15 Pythagoras-Prover Purwarianti, and Adila ...
-
[2]
Thierry Coquand and Christine Paulin-Mohring
URLhttps://doi.org/10.1016/0890-5401(88)90005-3. Yuri Chervonyi, Trieu H. Trinh, Miroslav Olsák, Xiaomeng Yang, Hoang H. Nguyen, Marcelo Menegali, Junehyuk Jung, Junsu Kim, Vikas Verma, Quoc V . Le, and Thang Luong. Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2.J. Mach. Learn. Res., 26:241:1–241:39, 2025. URL https://jmlr.org/...
-
[3]
doi: 10.52202/079017-0368. URL https://proceedings.neurips.cc/paper_files/paper/2024/ file/1582eaf9e0cf349e1e5a6ee453100aa1-Paper-Datasets_and_Benchmarks_Track.pdf. Joshua Ong Jun Leang, Giwon Hong, Wenda Li, and Shay B Cohen. Theorem Prover as a Judge for Synthetic Data Generation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pil...
-
[4]
Notion Blog. Hugging Face. Open R1: A fully open reproduction of DeepSeek-R1, January 2025. URL https://github.com/ huggingface/open-r1. Qwen Team, An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, et al. Qwen3 Technical Report, 2025. URLhttps://arxiv.org/abs/2505.09388. Seungone Kim, Juyoung Suk, Xiang Yue, Vijay Viswanathan, Seongy...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.acl-long.320 2025
-
[5]
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al
URLhttps://openreview.net/forum?id=yaqPf0KAlN. Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions, 2024. URL https://github.com/project-numina/aimo-progr...
2024
-
[6]
URLhttps://openreview.net/forum?id=nZeVKeeFYf9. Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, et al. Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning, 2025b. URLhttps://arxiv.org/abs/2504.11354. Zhihong Shao, Peiyi Wang, Qihao Z...
-
[7]
URLhttps://arxiv.org/abs/2402.03300. 17 Pythagoras-Prover Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, juncai liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/079017-4135 2025
-
[8]
URLhttps://openreview.net/forum?id=AjXkRZIvjB. OpenAI. OpenAI GPT-5 System Card, 2026. URLhttps://arxiv.org/abs/2601.03267. Anthropic. System Card: Claude Opus 4.5.https://anthropic.com/claude-opus-4-5-system-card, 2025. Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia LI, Mengzhou Xia, Danqi Chen, Sanjeev Arora, and Chi Jin. Goe...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z 2026
-
[9]
URLhttps://doi.org/10.18653/v1/2025.emnlp-demos.44. Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data, 2024. URL https://arxiv.org/abs/2405.14333. Xingguang Ji, Yahui Liu, Qi Wang, Jingyuan Zhang, Yang Yue, Rui ...
-
[10]
(e.g., If the error involves Point F, you MUST state the exact coordinates of Point F in the question)
**COMPLETELY SELF-CONTAINED & SOLVABLE:** The generated question MUST include the actual mathematical values, coordinates, formulas, or premises involved in the failed step. (e.g., If the error involves Point F, you MUST state the exact coordinates of Point F in the question). It must be solvable without looking at the Lean code
-
[11]
Frame it purely as a standard math competition or textbook problem
**PURE MATHEMATICS (NO CODE):** The question and solution MUST NOT contain Lean 4 code, tactics (`simp`,`rw`), Lean keywords (`let`, `have`), or backticks (` `). Frame it purely as a standard math competition or textbook problem
-
[12]
WHY" QUESTIONS:** Do not ask
**NO DIAGNOSTIC OR "WHY" QUESTIONS:** Do not ask "Why did this fail?" or "What is the correct logical approach?". Ask direct mathematical questions like "Calculate X", "Find Y", or "Prove that Z is true given [Premises]."
-
[13]
Why does the`intro`tactic fail when applied to Point F?
**EXPLICIT STEP-BY-STEP SOLUTION:** You must provide a clear, logically sound, step-by-step mathematical solution to the synthetic question you just generated. ### EXAMPLES (Bad vs. Good) - **BAD (Diagnostic/Code-heavy):** "Why does the`intro`tactic fail when applied to Point F?" - **GOOD (Synthetic Math Problem):** "Point A is at (0, 0) and Point B is at...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.