Constrained Semantic Decompression in LLMs through Persian Proverb-Conditioned Story Generation
Pith reviewed 2026-06-27 09:40 UTC · model grok-4.3
The pith
Large language models generate fluent proverb-based stories but routinely fail to embed the intended moral and causal structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
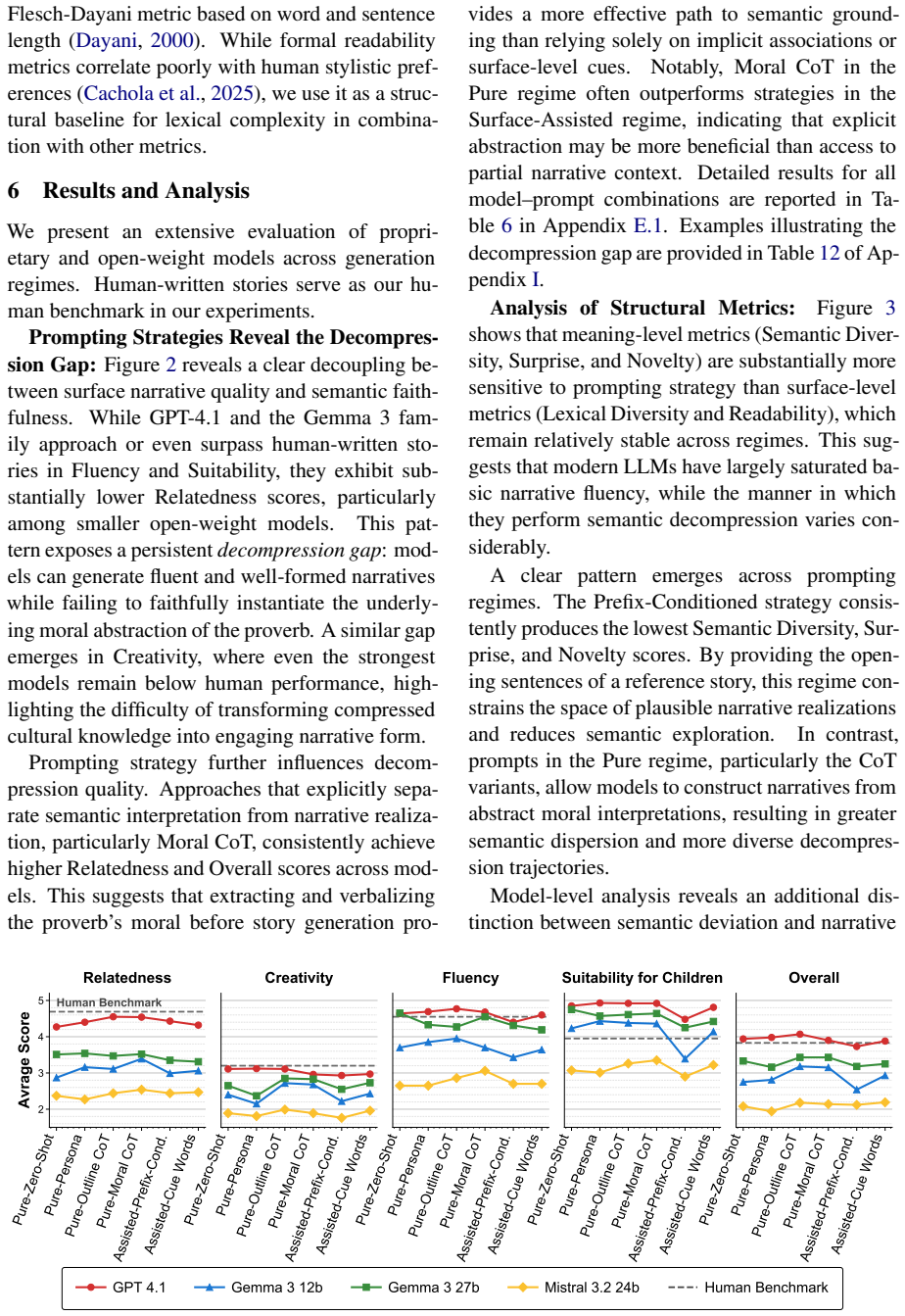
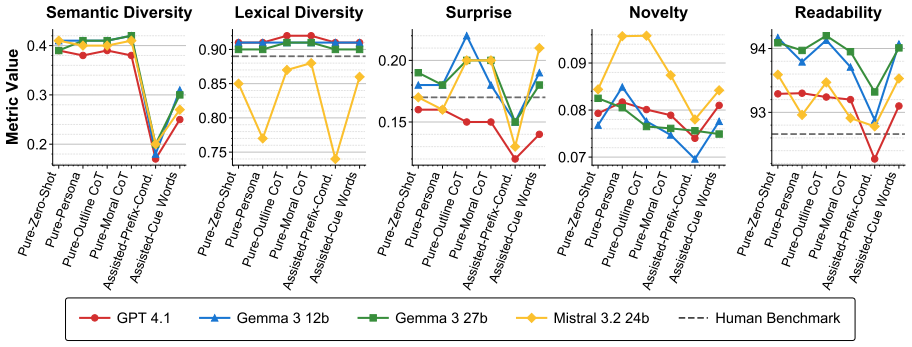
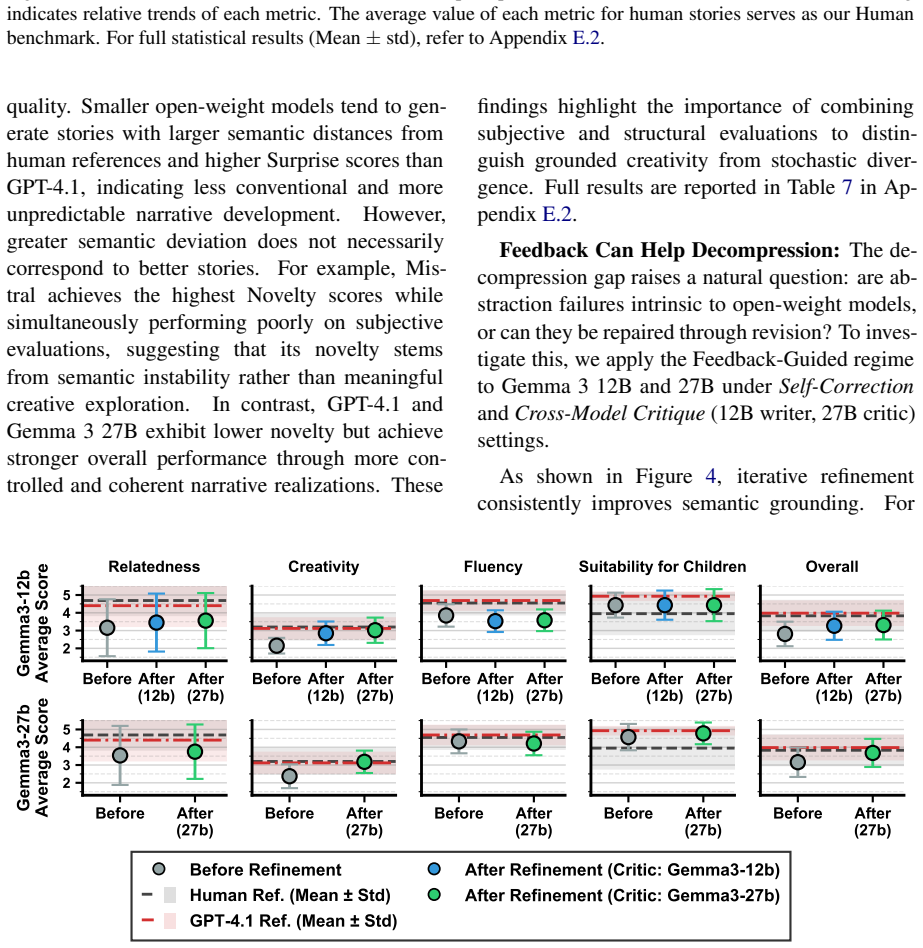
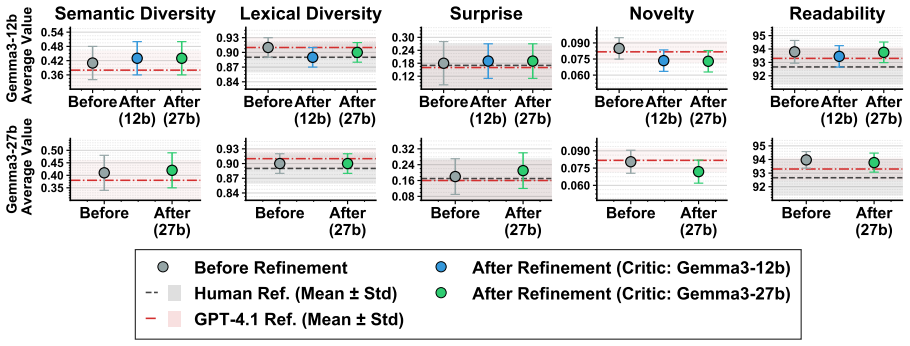
Current LLMs achieve strong surface-level fluency in proverb-conditioned story generation while failing to faithfully instantiate the underlying moral and causal structure encoded in the proverbs; explicit reasoning and iterative refinement partially mitigate these failures, indicating that many errors stem from difficulties in translating abstract meaning into narrative form.
What carries the argument
The decompression gap, measured by a hybrid evaluation framework that pairs human-calibrated LLM-as-a-Judge scores with structural metrics on moral and causal fidelity.
If this is right
- Explicit chain-of-thought prompting and iterative refinement improve moral fidelity but leave a residual gap.
- The observed failures are more consistent with translation difficulties than with missing cultural knowledge.
- The same decompression task applies to other compressed cultural forms beyond Persian proverbs.
- Surface fluency metrics alone are insufficient to certify semantic grounding in cultural abstraction tasks.
Where Pith is reading between the lines
- Architectural changes that strengthen explicit mapping from abstract constraints to narrative constraints may be needed beyond scale or prompting.
- The gap could serve as a diagnostic for testing whether future models possess robust mechanisms for cultural semantic grounding.
- Similar evaluation setups could be applied to other languages to check whether the decompression gap is language-specific or general.
Load-bearing premise
The hybrid evaluation framework correctly identifies failures to instantiate moral and causal structure rather than reflecting judge bias or metric limitations.
What would settle it
An independent human annotation study on a held-out set of model-generated stories that finds no systematic shortfall in moral or causal fidelity compared with human-written references.
Figures



















read the original abstract
Transforming a dense, abstract proverb into an engaging and morally faithful narrative requires deep cultural understanding and robust semantic grounding. We frame this problem as a \emph{constrained semantic decompression} task and study proverb-conditioned story generation as a testbed for abstraction-to-realization in large language models (LLMs). Focusing on Persian, we introduce the Proverb Aligned Narrative Dataset (PAND), pairing proverbs with human-written stories and explicit meanings. By a hybrid evaluation framework that combines human-calibrated LLM-as-a-Judge with structural metrics, we analyze model behavior across multiple prompting regimes. Our findings reveal a persistent \emph{decompression gap}: current LLMs often achieve strong surface-level fluency while failing to faithfully instantiate the underlying moral and causal structure encoded in proverbs. We further show that explicit reasoning and iterative refinement can partially mitigate these failures, suggesting that many decompression errors arise from difficulties in translating abstract meaning into narrative form rather than a complete lack of relevant knowledge. Our proposed task naturally extends to other forms of compressed cultural knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames proverb-conditioned story generation as a constrained semantic decompression task and introduces the Proverb Aligned Narrative Dataset (PAND) pairing Persian proverbs with human-written stories and explicit meanings. Using multiple prompting regimes and a hybrid evaluation framework (human-calibrated LLM-as-a-Judge combined with structural metrics), it reports a persistent 'decompression gap' in which current LLMs produce surface-fluent narratives but fail to instantiate the underlying moral and causal structures. Explicit reasoning and iterative refinement are shown to partially mitigate the gap, suggesting the errors often reflect translation difficulties rather than absent knowledge. The task is positioned as extensible to other forms of compressed cultural knowledge.
Significance. If the empirical findings and evaluation hold, the work is significant for providing a concrete testbed and dataset to probe LLMs' handling of abstract cultural semantics beyond surface fluency. The PAND dataset, the explicit distinction between knowledge absence and translation failure, and the partial mitigation results constitute concrete, falsifiable contributions that can ground future work on cultural grounding and semantic decompression in LLMs.
major comments (1)
- [Evaluation Framework] Evaluation Framework section: the central claim of a decompression gap rests on the hybrid judge+metrics framework correctly isolating failures of moral/causal instantiation; the manuscript should report inter-annotator agreement, exact calibration procedure, and concrete criteria used by the LLM judge to avoid the possibility that observed gaps reflect metric or judge artifacts rather than model behavior.
minor comments (3)
- [Abstract and §3] Abstract and §3: the term 'decompression gap' is used as a key finding but lacks an explicit operational definition or formal characterization; adding one would improve precision.
- [Dataset] Dataset section: report basic statistics for PAND (number of proverbs, story length distribution, inter-annotator agreement on meanings) to allow readers to assess scale and quality.
- [Results] Results tables: ensure all prompting regimes and mitigation conditions are labeled consistently between text and tables so that the reported gap and mitigation effects can be directly traced.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive recommendation of minor revision. We address the single major comment on the evaluation framework below, agreeing that greater transparency is warranted.
read point-by-point responses
-
Referee: [Evaluation Framework] Evaluation Framework section: the central claim of a decompression gap rests on the hybrid judge+metrics framework correctly isolating failures of moral/causal instantiation; the manuscript should report inter-annotator agreement, exact calibration procedure, and concrete criteria used by the LLM judge to avoid the possibility that observed gaps reflect metric or judge artifacts rather than model behavior.
Authors: We agree that reporting these details is essential for validating the hybrid evaluation and ruling out judge artifacts. In the revised manuscript we will add: (i) inter-annotator agreement statistics (Cohen’s kappa and percentage agreement) computed on the human calibration subset; (ii) a precise description of the calibration procedure, including how human ratings were used to iteratively refine the LLM-judge prompt and temperature settings; and (iii) the full rubric of concrete criteria (moral fidelity, causal coherence, proverb instantiation) supplied to the judge. These additions will be placed in the Evaluation Framework section and an accompanying appendix. revision: yes
Circularity Check
No significant circularity; empirical study with no load-bearing derivations or self-referential steps
full rationale
The paper introduces the PAND dataset, multiple prompting regimes, and a hybrid human-calibrated LLM-as-Judge plus structural metrics evaluation to observe LLM behavior on proverb-conditioned story generation. The central finding of a 'decompression gap' is presented as an empirical observation from these experiments, not as a derivation or prediction that reduces to fitted inputs or self-citations. No equations, ansatzes, uniqueness theorems, or self-citation chains appear in the provided abstract or description. The mitigation via explicit reasoning is also framed as an experimental result. This is a self-contained empirical contribution with external grounding via human calibration, consistent with the default expectation of no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-as-a-Judge scores can be calibrated to human judgments of moral and causal faithfulness
invented entities (1)
-
decompression gap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long con- text, and next generation agentic capabilities . Preprint, arXiv:2507.06261. Mohammad-Hossein Dayani. 2000. A criteria for assessing the persian texts readability. Jour- nal of Social Sciences and Humanities of Shiraz University, 10(1):35--48. DeepSeek-AI, Daya Guo, Dejian ...
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[2]
In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (V ol- ume 1: Long Papers) , pages 889--898, Mel- bourne, Australia
Hierarchical neural story generation . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (V ol- ume 1: Long Papers) , pages 889--898, Mel- bourne, Australia. Association for Computa- tional Linguistics. Angela Fan, Mike Lewis, and Y ann Dauphin
-
[3]
In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 2650--2660, Florence, Italy
Strategies for structuring story generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 2650--2660, Florence, Italy. Association for Computational Linguistics. Sayan Ghosh and Shashank Srivastava. 2022. ePiC: Employing proverbs in context as a bench- mark for abstract language understanding . In Proc...
2022
-
[4]
In Findings of the Association for Com- putational Linguistics: EMNLP 2023 , pages 14504--14528, Singapore
A confederacy of models: a compre- hensive evaluation of LLMs on creative writ- ing. In Findings of the Association for Com- putational Linguistics: EMNLP 2023 , pages 14504--14528, Singapore. Association for Com- putational Linguistics. Kazjon Grace, Mary Lou Maher, Douglas Fisher, and Katherine Brady. 2015. Modeling expecta- tion for evaluating surprise...
2023
-
[5]
In Proceedings of the 1st Workshop on NLP for Languages Using Arabic Script , pages 37--43
Dadmatools v2: an adapter-based natural language processing toolkit for the persian lan- guage. In Proceedings of the 1st Workshop on NLP for Languages Using Arabic Script , pages 37--43. Dan R Johnson, James C Kaufman, Brendan S Baker, John D Patterson, Baptiste Barbot, Adam E Green, Janet van Hell, Evan Kennedy, Grace F Sullivan, Christa L Taylor, and 1...
2023
-
[6]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card . Preprint, arXiv:2508.10925. OpenAI, :, Aaron Hurst, Adam Lerer, Adam P . Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mdry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, and 401 others. 2024a. Gpt-4o sys...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Median: Agreement between the LLM and the median human score, mitigat- ing outlier influence
LLM vs. Median: Agreement between the LLM and the median human score, mitigat- ing outlier influence
-
[8]
Mean: Agreement between the LLM and the average human score
LLM vs. Mean: Agreement between the LLM and the average human score
-
[9]
D.3 Results and Selection The comparative results of these experiments are presented in Table 5
Pooled Consensus (All): Treating the LLM as a fourth independent annotator alongside the three humans to calculate group inter- rater reliability. D.3 Results and Selection The comparative results of these experiments are presented in Table 5. SOTA vs. Open-Weight Gap A clear di- chotomy emerged between proprietary and open- weight models. While open-weig...
2020
-
[10]
• 1: Not related: No meaningful connection to the proverb
Relatedness This criterion measures how well a story reflects the meaning of the corresponding proverb. • 1: Not related: No meaningful connection to the proverb. 5https://labelstud.io/ 17 Type Model Measure Relatedness Creativity Fluency Suitability for Ch. Overall Mean Med All Mean Med All Mean Med All Mean Med All Mean Med All Closed-Source GPT-4o ICC2k...
-
[11]
• 1: V ery uninteresting: V ery bor- ing/uninteresting
Creativity This metric assesses how much the story is like a short, creative, or interesting story. • 1: V ery uninteresting: V ery bor- ing/uninteresting. • 2: Slightly interesting: Limited creativity or entertainment value. • 3: Moderately interesting: Somewhat engag- ing and creative. • 4: V ery interesting: Creative and engaging. • 5: Highly creative:...
-
[12]
• 1: V ery poor: multiple grammatical errors; difficult to read
Fluency Fluency assesses the grammatical correctness, clarity, and overall readability of the story. • 1: V ery poor: multiple grammatical errors; difficult to read. • 2: Poor: Contains noticeable errors. • 3: Average: Generally readable but includes some issues. • 4: Good: Mostly accurate and fluent. • 5: Excellent: Clear, well-written, and free of errors
-
[13]
• 1: Completely unsuitable: Includes themes or elements inappropriate for children
Suitability for Children This criterion determines whether the storys lan- guage, tone, and content are appropriate for a child audience. • 1: Completely unsuitable: Includes themes or elements inappropriate for children. 18 Story Details Judge Scores Decompression Regime Prompt Writer/Model Relatedness Creativity Fluency Suitability for Children Overall ...
-
[14]
What you read from the page, I know by heart
Overall This rating reflects a general evaluation of the over- all quality of the story. • 1: V ery poor: Lacks coherence or value. • 2: Poor: Contains significant weaknesses. • 3: Average: Acceptable but unremarkable. • 4: Good: Coherent, well-structured, and of solid quality. • 5: Excellent: High-quality. General Annotation Instructions • Objectivity: Ann...
2025
-
[19]
relatedness
Overall: Provide your overall impression of the story on a 1–5 scale. This can be based on a subjective average of the previous criteria or your general judgment. - 1: Very poor: Lacks coherence or value. - 2: Poor: Contains significant weaknesses. - 3: Average: Acceptable but unremarkable. - 4: Good: Coherent, well-structured, and of solid quality. - 5: ...
2025
-
[20]
- 1: Not related: No meaningful connection to the proverb
Relatedness: Assess how well the story reflects the meaning of the proverb. - 1: Not related: No meaningful connection to the proverb. - 2: Weakly related: Only minimal or indirect reference. - 3: Moderately related: Partially conveys the intended meaning. - 4: Well related: Clearly communicates the meaning. - 5: Fully related: Completely and accurately r...
-
[21]
- 1: Very uninteresting: Very boring / uninteresting
Creativity: Assess how engaging and creative the story is. - 1: Very uninteresting: Very boring / uninteresting. - 2: Slightly interesting: Limited creativity or entertainment value. - 3: Moderately interesting: Somewhat engaging and creative. - 4: Very interesting: Creative and engaging. - 5: Highly creative: Very creative/story-like
-
[22]
- 1: Very poor: multiple grammatical errors; difficult to read
Fluency: Assess how grammatically correct and smooth the text is. - 1: Very poor: multiple grammatical errors; difficult to read. - 2: Poor: Contains noticeable errors. - 3: Average: Generally readable but includes some issues. - 4: Good: Mostly accurate and fluent. - 5: Excellent: Clear, well-written, and free of errors
-
[23]
- 1: Completely unsuitable: Includes themes or elements inappropriate for children
Suitability for Children: Assess how appropriate the story is for children in terms of content, tone, language, and message. - 1: Completely unsuitable: Includes themes or elements inappropriate for children. - 2: Slightly unsuitable: Contains issues that reduce child-appropriateness or appeal. - 3: Moderately suitable: Generally acceptable but not strong...
-
[24]
This can be based on a subjective average of the previous criteria or your general judgment
Overall: Provide your overall impression of the story on a 1–5 scale. This can be based on a subjective average of the previous criteria or your general judgment. - 1: Very poor: Lacks coherence or value. - 2: Poor: Contains significant weaknesses. - 3: Average: Acceptable but unremarkable. - 4: Good: Coherent, well-structured, and of solid quality. - 5: ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.