Towards Provably Fair Machine Learning: Bayesian Approaches For Consistent and Transparent Predictions
Pith reviewed 2026-06-27 09:54 UTC · model grok-4.3
The pith
The Fair Bayesian classifier achieves zero consistency error by construction across every subgroup while exceeding baseline accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By requiring predictions to be deterministic for identical individuals and statistically consistent with the inferred Bayesian optimal target distribution for every subgroup at significance level alpha, the authors construct the Fair Bayesian classifier that enforces both conditions simultaneously across all groups and subgroups, abstains when no consistent deterministic prediction exists, and delivers zero consistency error while surpassing baseline accuracy and multicalibration on the Adult, COMPAS, and Bank Marketing datasets.
What carries the argument
The Fair Bayesian classifier, which enforces determinism and statistical consistency with the Bayesian optimal target distribution for every subgroup and abstains when no consistent deterministic prediction is possible.
If this is right
- Standard classifiers produce statistically inconsistent predictions for a substantial proportion of subgroups on the tested datasets.
- The Fair Bayesian classifier exceeds baseline accuracy and multicalibration on every dataset tested.
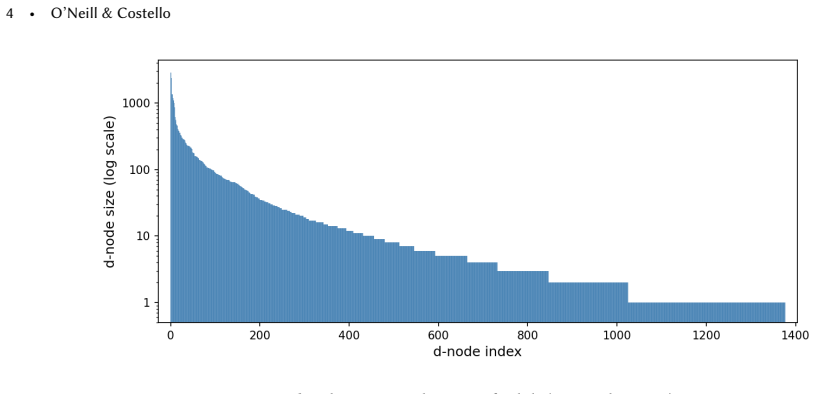
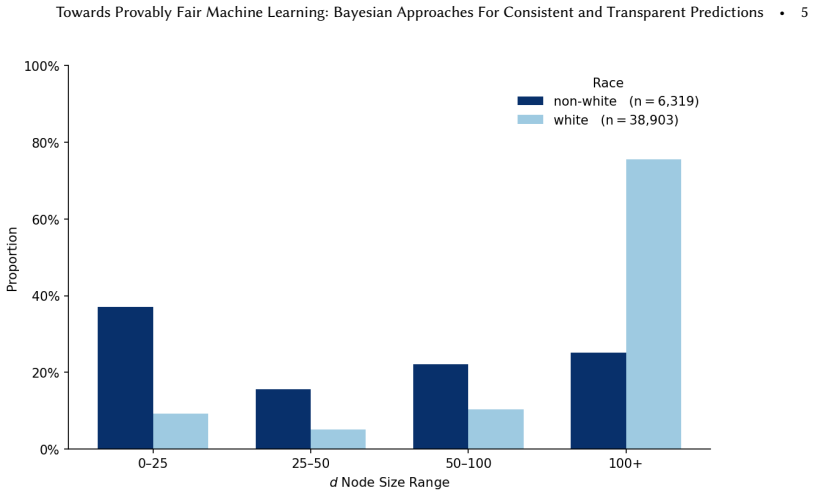
- Minority demographics are disproportionately concentrated in small subgroups where inconsistency is most common.
- Statistical consistency with Bayesian targets supplies a principled foundation for prediction quality and algorithmic fairness.
- Exhaustive subgroup fairness with principled abstention is achievable in practice.
Where Pith is reading between the lines
- The method could be applied to regression or ranking tasks to test whether the same consistency requirements scale beyond classification.
- Better inference techniques for small-subgroup distributions would directly strengthen the reliability of the approach.
- Models trained with heavy regularization may need re-examination when fairness at fine granularity is required.
- The abstention mechanism offers a concrete way to flag cases where data cannot support a fair deterministic decision.
Load-bearing premise
The Bayesian optimal target distribution can be inferred reliably for every subgroup including small ones, and statistical consistency with this distribution at significance level alpha is a sufficient standard for fair and consistent prediction.
What would settle it
On one of the benchmark datasets, a statistical test at the chosen alpha level rejects the hypothesis that the classifier's predictions for some subgroup were drawn from the inferred Bayesian optimal target distribution.
Figures
read the original abstract
ML classifiers deployed in high-stakes domains produce predictions whose quality varies systematically across subgroups. For granular subgroups defined by intersections of multiple features, predictions are often inconsistent with the observed data: the model's outputs contradict the evidence available for that subgroup. This problem is exacerbated by regularisation, which improves aggregate performance by collapsing small subgroups into larger groups, disproportionately affecting demographic minorities. We define two requirements for consistent prediction: determinism (identical individuals receive identical predictions) and statistical consistency (we cannot reject, at significance level alpha, the hypothesis that the predictions for a subgroup were drawn from the Bayesian optimal target distribution inferred for that subgroup). From these requirements we derive the Fair Bayesian classifier, which enforces both across every group and subgroup simultaneously and abstains whenever no consistent deterministic prediction is possible. On three benchmark datasets (Adult, COMPAS, and Bank Marketing), standard classifiers produce statistically inconsistent predictions for a substantial proportion of subgroups. Our classifier achieves zero consistency error by construction while exceeding baseline accuracy and multicalibration on every dataset tested. Statistical consistency provides a principled foundation for prediction quality with direct implications for algorithmic fairness. Minority demographics are disproportionately concentrated in small subgroups, precisely where frequentist inference is least reliable; addressing this inference problem is therefore a necessary step toward fair ML. By enforcing Bayesian consistency at the finest resolution the data supports, the our classifier demonstrates that exhaustive subgroup fairness with principled abstention is achievable in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines determinism and statistical consistency (non-rejection at level alpha of the hypothesis that subgroup predictions are drawn from the inferred Bayesian optimal target) as requirements for consistent prediction. From these it derives the Fair Bayesian classifier, which enforces both requirements across all groups and subgroups simultaneously and abstains when no consistent deterministic prediction exists. The manuscript claims this yields zero consistency error by construction, exceeds baseline accuracy and multicalibration on Adult, COMPAS, and Bank Marketing, and improves fairness for minorities in small subgroups.
Significance. If the derivation is non-circular and the method is robust for small subgroups, the approach supplies a principled, abstention-based route to subgroup-consistent predictions that directly targets the inference problem for granular demographic intersections.
major comments (2)
- [Abstract / derivation of Fair Bayesian classifier] Abstract and central construction: the claim of 'zero consistency error by construction' is load-bearing for both the fairness and accuracy results, yet the manuscript provides no explicit verification that the hypothesis test at level alpha produces an independent guarantee rather than a definitional property once the target is inferred from the same data.
- [Method and experiments] Subgroup inference procedure: the central construction requires inferring a Bayesian optimal target for every subgroup (including those with very few samples) and then testing consistency at level alpha; the paper supplies no analysis of prior sensitivity or test power, leaving open whether the zero-error guarantee and minority-fairness claims hold when the target is prior-dominated.
minor comments (1)
- [Notation and method] Clarify the precise inference procedure for the Bayesian optimal target distribution and the exact form of the hypothesis test used for statistical consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below, providing clarifications on the derivation and offering revisions where appropriate to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract / derivation of Fair Bayesian classifier] Abstract and central construction: the claim of 'zero consistency error by construction' is load-bearing for both the fairness and accuracy results, yet the manuscript provides no explicit verification that the hypothesis test at level alpha produces an independent guarantee rather than a definitional property once the target is inferred from the same data.
Authors: The zero-consistency-error property follows directly from the construction: the Fair Bayesian classifier enumerates candidate deterministic predictions for each subgroup and outputs one only if it is not rejected by the level-alpha test against the Bayesian optimal target inferred for that subgroup; otherwise it abstains. The target is obtained via the Bayesian posterior predictive, while the test evaluates whether the chosen deterministic output is compatible with that distribution. Although both steps use the same data, the guarantee is operational rather than purely definitional because the procedure explicitly withholds any prediction that would fail the test. We agree that an explicit lemma formalizing this independence from the inference step would improve clarity and will add it (with proof) to the revised manuscript. revision: yes
-
Referee: [Method and experiments] Subgroup inference procedure: the central construction requires inferring a Bayesian optimal target for every subgroup (including those with very few samples) and then testing consistency at level alpha; the paper supplies no analysis of prior sensitivity or test power, leaving open whether the zero-error guarantee and minority-fairness claims hold when the target is prior-dominated.
Authors: The Bayesian formulation is chosen precisely because the prior regularizes inference for small subgroups, preventing the collapse that occurs under frequentist estimation. The abstention rule ensures that whenever the test (under the chosen prior) cannot certify consistency, no prediction is issued; this mechanism itself protects the zero-error guarantee and the fairness claims for minorities concentrated in small subgroups. We acknowledge that the original submission does not contain a dedicated sensitivity study across priors or explicit power calculations. We will therefore add a short appendix with prior-sensitivity results on the three benchmark datasets and a brief discussion of test power under the sample sizes observed in the data. revision: partial
Circularity Check
Zero consistency error holds by construction as the classifier is defined to enforce the consistency requirement
specific steps
-
self definitional
[abstract]
"Our classifier achieves zero consistency error by construction while exceeding baseline accuracy and multicalibration on every dataset tested."
The classifier is explicitly constructed to enforce the two requirements (determinism and statistical consistency with the inferred Bayesian optimal target) across every subgroup; therefore the zero consistency error follows immediately from the definition of the method rather than from any independent derivation or empirical result.
full rationale
The paper's strongest claim reduces directly to its definitional construction: the Fair Bayesian classifier is derived from the requirements of determinism and statistical consistency, and is stated to achieve zero consistency error by construction. This matches the self-definitional pattern exactly, as the zero-error outcome is enforced by the method's definition rather than derived independently. No other load-bearing steps in the abstract reduce to self-citation, fitted inputs renamed as predictions, or imported uniqueness theorems. The inference robustness concerns for small subgroups are validity issues, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Machine Bias
“Machine Bias. ”ProPublica, (May 23, 2016). Retrieved Mar. 13, 2022 from https://www.propubl ica.org/article/machine-bias-risk-assessments-in-criminal-sentencing. A. Blum, J. Liguori, T. Mussomeli, and M. Hardt
2016
-
[2]
Multiaccuracy: Black-box post-processing for fairness in classification
“Multiaccuracy: Black-box post-processing for fairness in classification. ” In:Proceedings of the 35th International Conference on Machine Learning (ICML). https://arxiv.org/abs/1805.12317. S. Chiappa
-
[3]
A Causal Bayesian Networks Viewpoint on Fairness
“A Causal Bayesian Networks Viewpoint on Fairness. ” In:Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS) Workshop on Fair ML. https://arxiv.org/abs/1908.08619. S. Chiappa and T. P. S. Gillam
arXiv 1908
-
[4]
On Optimum Recognition Error and Reject Tradeoff
“On Optimum Recognition Error and Reject Tradeoff. ”IEEE Transactions on Information Theory, 16, 1, 41–46. doi:10.1109 /TIT.1970.1054406. P. Cunningham and S. J. Delany
arXiv 1970
-
[5]
Amazon scraps secret AI recruiting tool that showed bias against women
“Amazon scraps secret AI recruiting tool that showed bias against women. ”Reuters, (Oct. 10, 2018). Retrieved Oct. 13, 2022 from https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G. Z. Deng, C. Dwork, and L. Zhang
2018
-
[6]
Happymap: A generalized multi-calibration method
“Happymap: A generalized multi-calibration method. ”arXiv preprint arXiv:2303.04379. C. Dimitrakakis, Y. Liu, D. C. Parkes, and G. Radanovic
-
[7]
“Bayesian Fairness. ” In:Proceedings of the AAAI Conference on Artificial Intelligence01. Vol. 33, 5099–5106. doi:10.1609/aaai.v33i01.33015099. R. El-Yaniv and Y. Wiener
-
[8]
On the foundations of noise-free selective classification
“On the foundations of noise-free selective classification. ”Journal of Machine Learning Research, 11, 1605–1641. http://jmlr.org/papers/v11/el-yaniv10a.html. European Parliament and Council of the EU. 2024.Regulation (EU) 2024/1689 (Artificial Intelligence Act). OJ L, entered into force 1 August
2024
-
[9]
https://eur-lex.europa.eu/eli/reg/2024/1689/oj
(2024). https://eur-lex.europa.eu/eli/reg/2024/1689/oj. B. de Finetti
2024
-
[10]
Bayesian Modelling of Intersectional Fairness: The Variance of Bias
“Bayesian Modelling of Intersectional Fairness: The Variance of Bias. ” In:Proceedings of the 2020 SIAM International Conference on Data Mining (SDM). SIAM, 381–389. doi:10.1137/1.9781611976236.43. A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari, and D. B. Rubin. 2013.Bayesian Data Analysis. (Third ed.). Chapman and Hall/CRC. doi:10.1201/b1...
-
[11]
Multicalibration: Calibration for the (computationally-identifiable) masses
“Multicalibration: Calibration for the (computationally-identifiable) masses. ” In:International Conference on Machine Learning. PMLR, 1939–1948. R. Herbei and M. H. Wegkamp
1939
-
[12]
Canadian Journal of Statistics 34, 709–721
“Classification with reject option. ”Canadian Journal of Statistics, 34, 4, 709–721. doi:10.1002/cjs.5550340410. X. Ji, J. Zou, H. Nassar, A. D. Procaccia, and Y. Chen
-
[13]
Can I Trust My Fairness Metric? Assessing Fairness with Unlabeled Data and Bayesian Inference
“Can I Trust My Fairness Metric? Assessing Fairness with Unlabeled Data and Bayesian Inference. ” In:Proceedings of the 40th International Conference on Machine Learning (ICML). https://arxiv.org/abs/2306.13898. R. E. Kass and A. E. Raftery
-
[14]
“Bayes Factors. ”Journal of the American Statistical Association, 90, 430, 773–795. doi:10.1080/01621459.1995 .10476572. M. Kearns, S. Neel, A. Roth, and Z. S. Wu
-
[15]
Interpretable and Fair Mechanisms for Abstaining Classifiers
“Interpretable and Fair Mechanisms for Abstaining Classifiers. ” In:European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD). https://arxiv.org/abs/2402.11392. N. Mehrabi, F. Morstatter, N. Saxena, K. Lerman, and A. Galstyan. July
-
[16]
D., Allo, P., Taddeo, M., Wachter, S., & Floridi, L
“A Survey on Bias and Fairness in Machine Learning. ”ACM Comput. Surv., 54, 6, Article 115, (July 2021). doi:10.1145/3457607. Z. Obermeyer, B. Powers, C. Vogeli, and S. Mullainathan
-
[17]
“Fair Bayesian Optimization. ” In: Proceedings of the 38th International Conference on Machine Learning (ICML), 8476–8487. https://arxiv.org/abs/2102.06959. N. Schreuder and E. Chzhen
-
[18]
Classification with abstention but without disparities
“Classification with abstention but without disparities. ” In:Proceedings of the 37th Conference on Uncertainty in Artificial Intelligence (UAI). https://arxiv.org/abs/2106.08057. Y. Wiener and R. El-Yaniv
-
[19]
Agnostic Pointwise-Competitive Selective Classification
“Agnostic Pointwise-Competitive Selective Classification. ”Journal of Artificial Intelligence Research, 52, 171–201. doi:10.1613/jair.4439. T. Yin, J.-F. Ton, R. Guo, B. Shi, A. Gretton, and A. Weller
-
[20]
Fair Classifiers that Abstain without Harm
“Fair Classifiers that Abstain without Harm. ” In:Proceedings of the Twelfth International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=R0PxctbcD2. S. Zabell. 1989.The Rule of Succession. (31st ed.). Erkenntnis, 283–321. M. B. Zafar, I. Valera, M. Gomez Rodriguez, and K. P. Gummadi
1989
-
[22]
https://arxiv.org/abs/2207.08801. A Pseudocode A.0.1 Data Preparation (Steps 1–5).The first step is to set the parameters of the algorithm: •𝛼 : Significance level. Larger values make the requirements for statistical consistency more stringent. We use10 −5 as the starting point of the binary search over 𝛼 described in §6.4; the reported value of 𝛼 ∗ is th...
-
[23]
This lets us pick between pool members using the richer 𝑣 node evidence, which cannot be expressed as a linear MIP objective
The final prediction is the pool member with the highest 𝐿 (Equation 22). This lets us pick between pool members using the richer 𝑣 node evidence, which cannot be expressed as a linear MIP objective. A final check confirms all boundaries hold for the chosen solution. B Baseline Hyperparameter Configurations This appendix reports the hyperparameter search ...
2011
-
[24]
Proportional Multi-Calibrator (PMC) The PMC post-processor is applied to a logistic regression base learner (LogisticRegression, 𝐶= 1.0,max_iter= 1000)
Neural Network: final selected configuration per dataset. Proportional Multi-Calibrator (PMC) The PMC post-processor is applied to a logistic regression base learner (LogisticRegression, 𝐶= 1.0,max_iter= 1000). TheMultiCalibrator auditor is initialised with the protected attributes for each dataset; 𝑛_bins= 5; all other parameters use the library defaults...
2023
-
[25]
cherry-picked
to check feasibility and predicted label ˆ𝑦1. (3)Decision rule. •If both extended problems are infeasible, abstain from predicting. •If exactly one is feasible, predict its label. •If both are feasible and ˆ𝑦0 = ˆ𝑦1, predict the common label. •If both are feasible and ˆ𝑦0 ≠ ˆ𝑦1, abstain from predicting. This procedure checks whether the existing evidence ...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.