Observable Patterns Are Not Explanations: A Causal-Geometric Analysis of Latent Reasoning Models
Pith reviewed 2026-06-27 09:34 UTC · model grok-4.3
The pith
Observable patterns in latent states of reasoning models appear in controls and do not establish causal mechanisms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
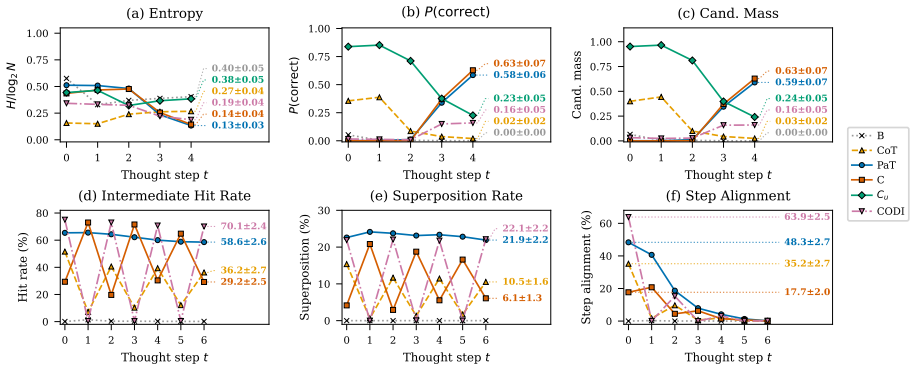
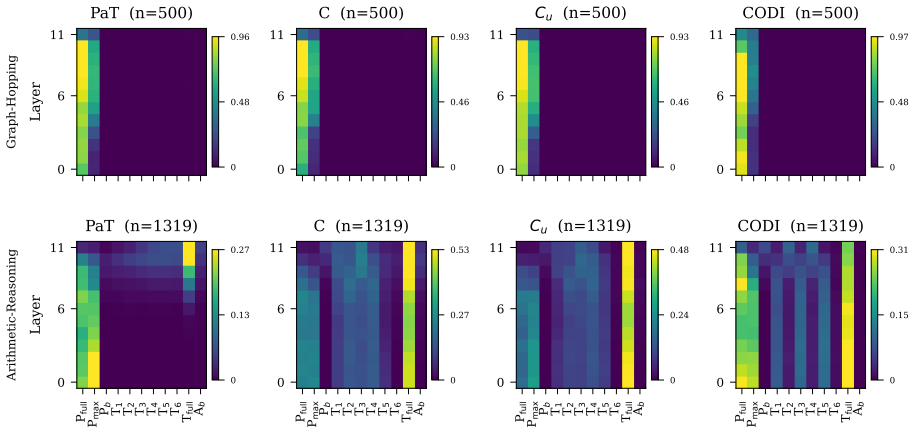
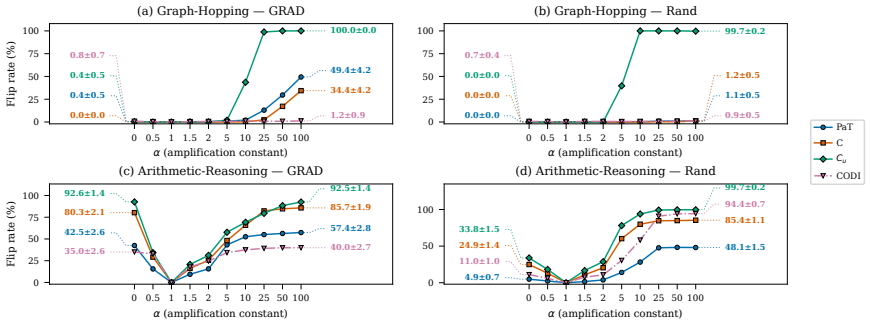
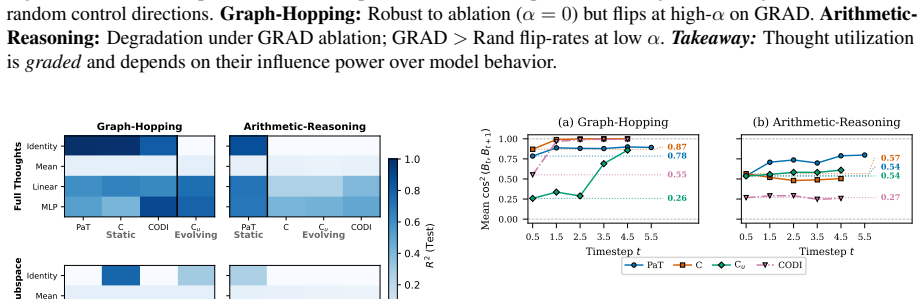
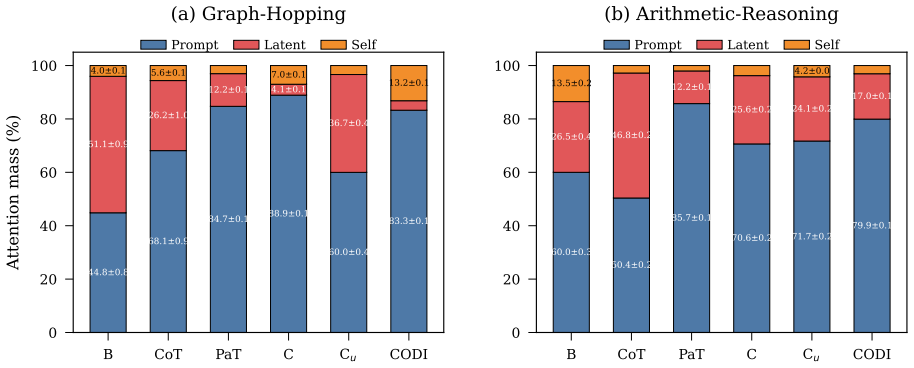
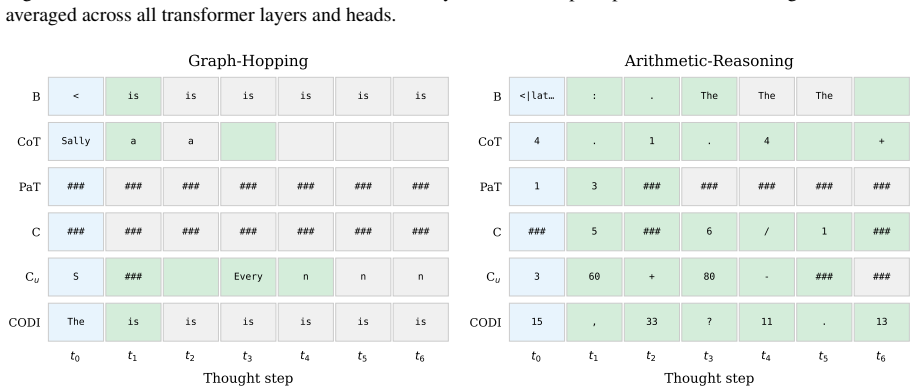
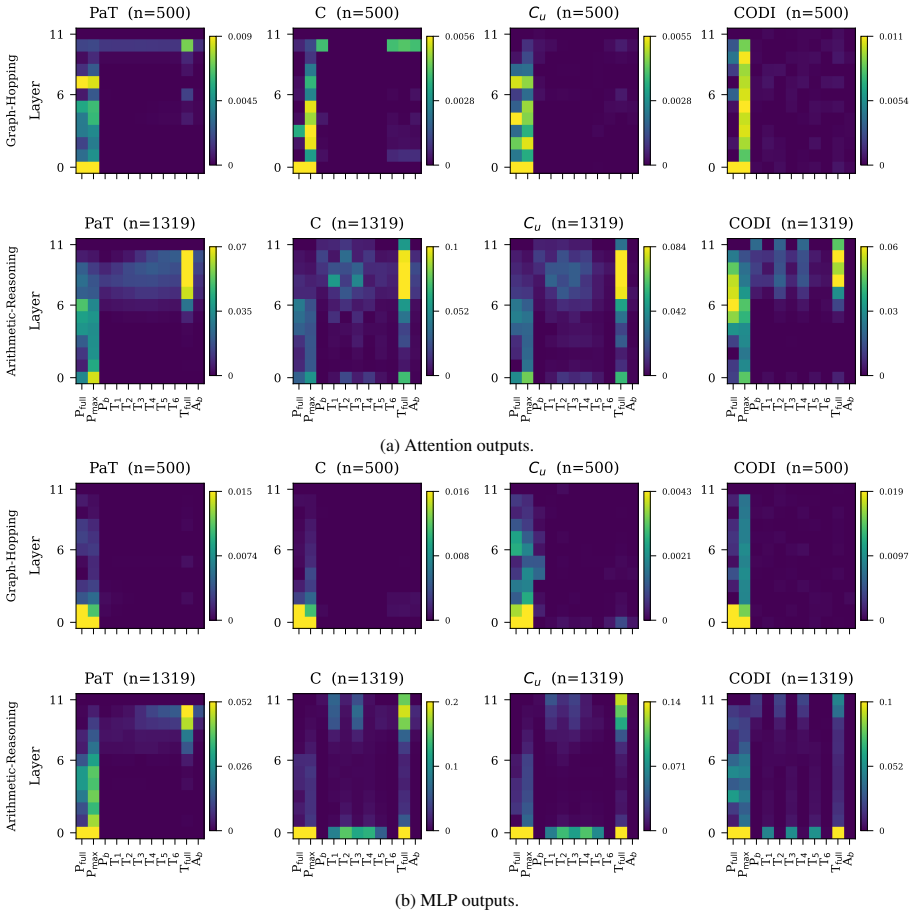
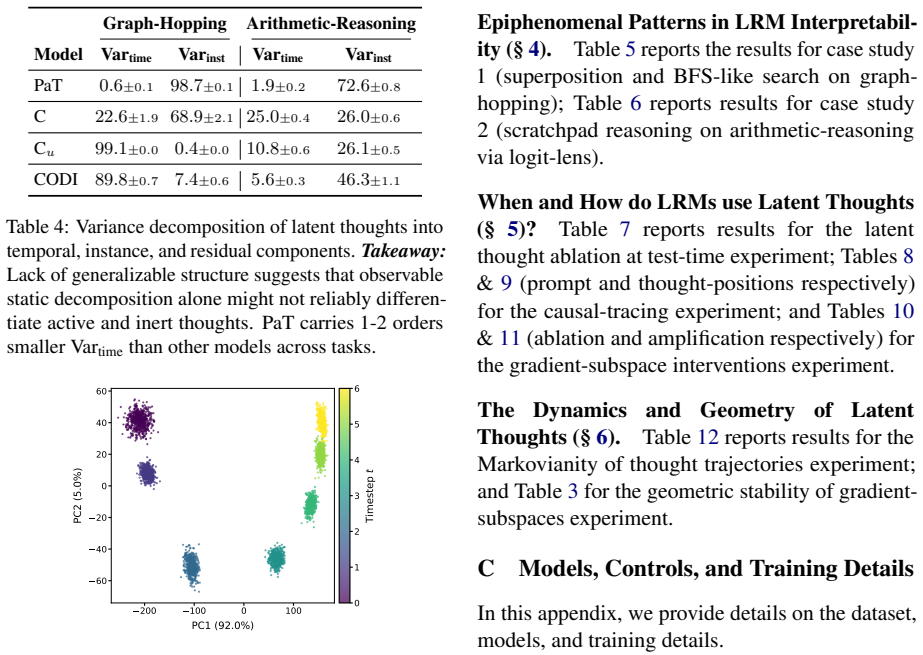
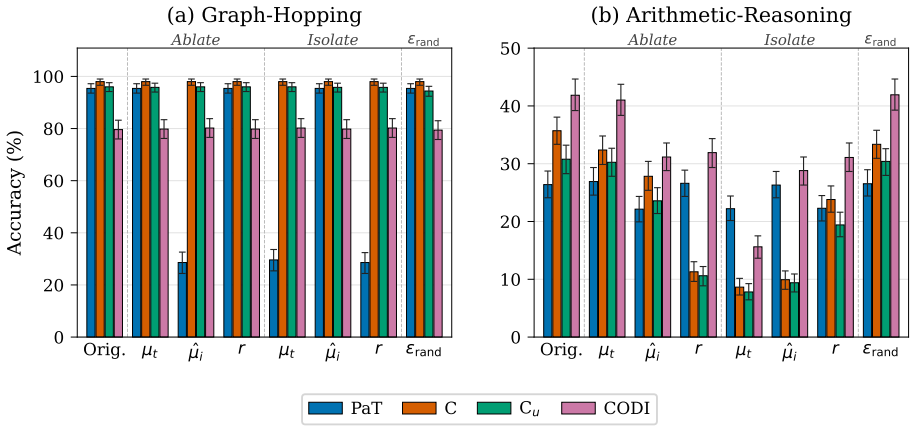
Evaluating two LRMs against controls lacking the proposed recurrence or curriculum, we find these patterns also appear in the controls and do not always causally affect behavior. Causal interventions reveal that latent-thought utilization is not binary but graded, scaling with a thought's causal effect on model behavior. Geometric analyses reveal this effect concentrates in low-rank directions whose step-to-step geometry grows more structured as their behavioral influence increases. Latent thoughts should therefore be treated as hidden computation, not hidden explanation: decodability, attention, or static structure alone cannot establish mechanism.
What carries the argument
Matched control models combined with causal interventions that measure the behavioral effect of individual latent thoughts, followed by geometric analysis of their step-to-step structure.
If this is right
- Decodability of latent states alone does not establish an internal reasoning mechanism.
- Static geometric structure in latent thoughts does not by itself explain model outputs.
- Interpretability claims for LRMs require explicit comparison to matched controls.
- Causal tests are needed to determine whether any given latent thought affects behavior.
Where Pith is reading between the lines
- The same logic may apply to interpretability claims based on attention patterns or activations in other transformer variants.
- Extending the graded-causality measurement to new tasks could test whether low-rank concentration is a general property of useful latent computation.
- Designing training regimes that explicitly control the rank and structure of latent directions could become a practical way to improve interpretability.
Load-bearing premise
The control models without recurrence or curriculum are otherwise comparable to the LRMs in capacity and training regime.
What would settle it
Demonstrating that the reported patterns are absent from controls or that every causal intervention on latent thoughts changes model behavior would falsify the central claim.
Figures
read the original abstract
Latent reasoning models (LRMs) replace explicit chain-of-thought with continuous thoughts. Recent work treats observable latent-state patterns, such as BFS-like frontiers and decodable arithmetic computation, as evidence for internal reasoning mechanisms. Evaluating two LRMs (Coconut and CODI) against controls lacking the proposed recurrence or curriculum, we find these patterns also appear in the controls and do not always causally affect behavior. Causal interventions reveal that latent-thought utilization is not binary but graded, scaling with a thought's causal effect on model behavior. Geometric analyses reveal this effect concentrates in low-rank directions whose step-to-step geometry grows more structured as their behavioral influence increases. Latent thoughts should therefore be treated as hidden computation, not hidden explanation: decodability, attention, or static structure alone cannot establish mechanism. LRM interpretability thus requires matched controls and causal tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that observable patterns in latent reasoning models (LRMs) such as Coconut and CODI—including BFS-like frontiers and decodable arithmetic computation—are not evidence of internal reasoning mechanisms. These patterns also appear in control models lacking recurrence or curriculum and do not consistently exert causal effects on behavior. Causal interventions demonstrate graded rather than binary utilization of latent thoughts, with behavioral influence scaling continuously; geometric analysis shows this influence concentrates in low-rank directions whose step-to-step structure increases with causal strength. The paper concludes that decodability, attention, or static structure alone cannot establish mechanism and that LRM interpretability requires matched controls plus causal tests, treating latent thoughts as hidden computation rather than hidden explanations.
Significance. If the results hold, the work is significant for shifting LRM interpretability away from purely observational analyses toward causal and geometric methods. The explicit use of matched controls, causal interventions, and low-rank geometric quantification supplies a concrete, falsifiable framework that could raise standards across neural interpretability research. Credit is due for grounding claims in intervention outcomes rather than fitted patterns and for the graded-effect finding, which directly challenges binary mechanism assumptions.
major comments (1)
- [Abstract] Abstract: the central claim—that patterns in controls undermine their mechanistic status inside LRMs—requires that controls match LRMs on capacity, depth, parameter count, training data, and optimization. The abstract states only that controls 'lack the proposed recurrence or curriculum'; without explicit confirmation of these other axes, the presence of identical patterns in controls does not falsify mechanism inside the LRMs. This matching premise is load-bearing for the graded-effect and geometry conclusions.
Simulated Author's Rebuttal
We thank the referee for the constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim—that patterns in controls undermine their mechanistic status inside LRMs—requires that controls match LRMs on capacity, depth, parameter count, training data, and optimization. The abstract states only that controls 'lack the proposed recurrence or curriculum'; without explicit confirmation of these other axes, the presence of identical patterns in controls does not falsify mechanism inside the LRMs. This matching premise is load-bearing for the graded-effect and geometry conclusions.
Authors: We agree the abstract is concise and does not enumerate every matching axis. The full manuscript (Methods and experimental setup) details that controls were constructed to match LRMs on capacity, depth, parameter count, training data, and optimization procedure; the sole controlled differences are the absence of recurrence and curriculum. This design isolates the contribution of the proposed mechanisms. To eliminate ambiguity we will revise the abstract to state explicitly that controls are matched on the listed axes in addition to lacking recurrence or curriculum. The graded-effect and geometry results rest on these matched controls as already described in the body of the paper. revision: yes
Circularity Check
No significant circularity; derivation relies on external controls and interventions
full rationale
The paper's argument proceeds by comparing observable patterns in LRMs against independently constructed control models (lacking recurrence/curriculum) and measuring causal effects via interventions on behavior. These steps are not self-definitional, as the controls are described as external baselines rather than derived from the LRMs' own definitions, and no equations or claims reduce a prediction to a fitted input by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the abstract provides no evidence of ansatz smuggling or renaming. The control-comparability premise is a methodological assumption open to empirical challenge, not a definitional loop internal to the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , url=
Shibo Hao and Sainbayar Sukhbaatar and DiJia Su and Xian Li and Zhiting Hu and Jason E Weston and Yuandong Tian , booktitle=. 2025 , url=
2025
-
[2]
Probing the Probing Paradigm: Does Probing Accuracy Entail Task Relevance?
Ravichander, Abhilasha and Belinkov, Yonatan and Hovy, Eduard , editor =. Probing the Probing Paradigm: Does Probing Accuracy Entail Task Relevance?. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.295
-
[3]
Hewitt, John and Liang, Percy. Designing and Interpreting Probes with Control Tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1275
-
[4]
Forty-second International Conference on Machine Learning , year=
Are Sparse Autoencoders Useful? A Case Study in Sparse Probing , author=. Forty-second International Conference on Machine Learning , year=
-
[5]
Teney, Damien and Peyrard, Maxime and Abbasnejad, Ehsan , title =. Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXIII , pages =. 2022 , isbn =. doi:10.1007/978-3-031-20050-2_27 , abstract =
-
[7]
Probing for the Usage of Grammatical Number
Lasri, Karim and Pimentel, Tiago and Lenci, Alessandro and Poibeau, Thierry and Cotterell, Ryan. Probing for the Usage of Grammatical Number. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.603
-
[8]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[9]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Codi: Compressing chain-of-thought into continuous space via self-distillation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[10]
The Twelfth International Conference on Learning Representations , year=
Think before you speak: Training Language Models With Pause Tokens , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
2019 , url=
Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , journal=. 2019 , url=
2019
-
[12]
Elazar, Yanai and Ravfogel, Shauli and Jacovi, Alon and Goldberg, Yoav. Transactions of the Association for Computational Linguistics. 2021. doi:10.1162/tacl_a_00359
-
[13]
Neuroimage , volume=
Neural correlates of interspecies perspective taking in the post-mortem Atlantic Salmon: an argument for multiple comparisons correction , author=. Neuroimage , volume=. 2009 , publisher=
2009
-
[14]
arXiv preprint arXiv:2512.18792 , year=
The Dead Salmons of AI Interpretability , author=. arXiv preprint arXiv:2512.18792 , year=
-
[15]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[16]
2023 , eprint=
Implicit Chain of Thought Reasoning via Knowledge Distillation , author=. 2023 , eprint=
2023
-
[17]
2024 , eprint=
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step , author=. 2024 , eprint=
2024
-
[18]
Proceedings of the 40th International Conference on Machine Learning , pages =
Looped Transformers as Programmable Computers , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[19]
International Conference on Learning Representations , year=
Universal Transformers , author=. International Conference on Learning Representations , year=
-
[20]
2025 , url=
Cywinski, Bartosz and Bussmann, Bart and Conmy, Arthur and Engels, Joshua and Nanda, Neel and Rajamanoharan, Senthooran , journal=. 2025 , url=
2025
-
[21]
Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
Brad Peters and Sayam Goyal and Mar. Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
2025
-
[22]
2026 , url=
Yingqian Cui and Zhenwei Dai and Bing He and Zhan Shi and Hui Liu and Rui Sun and Zhiji Liu and Yue Xing and Jiliang Tang and Benoit Dumoulin , booktitle=. 2026 , url=
2026
-
[23]
Yuyi Zhang and Boyu Tang and Tianjie Ju and Sufeng Duan and Gongshen Liu , year=. 2512.21711 , archivePrefix=
-
[24]
2026 , eprint=
The Illusion of Superposition? A Principled Analysis of Latent Thinking in Language Models , author=. 2026 , eprint=
2026
-
[25]
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought , url =
Zhu, Hanlin and Hao, Shibo and Hu, Zhiting and Jiao, Jiantao and Russell, Stuart J and Tian, Yuandong , booktitle =. Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought , url =
-
[26]
2026 , eprint=
Do Latent-CoT Models Think Step-by-Step? A Mechanistic Study on Sequential Reasoning Tasks , author=. 2026 , eprint=
2026
-
[27]
arXiv preprint arXiv:2504.19678 , year=
From llm reasoning to autonomous ai agents: A comprehensive review , author=. arXiv preprint arXiv:2504.19678 , year=
-
[28]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[29]
arXiv preprint arXiv:2505.15778 , year=
Soft thinking: Unlocking the reasoning potential of llms in continuous concept space , author=. arXiv preprint arXiv:2505.15778 , year=
-
[30]
arXiv preprint arXiv:2505.05410 , year=
Reasoning models don't always say what they think , author=. arXiv preprint arXiv:2505.05410 , year=
-
[31]
Proceedings of the 2023 ACM conference on fairness, accountability, and transparency , pages=
Harms from increasingly agentic algorithmic systems , author=. Proceedings of the 2023 ACM conference on fairness, accountability, and transparency , pages=
2023
-
[32]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
arXiv preprint arXiv:2404.14082 , year=
Mechanistic interpretability for AI safety--a review , author=. arXiv preprint arXiv:2404.14082 , year=
-
[34]
arXiv preprint arXiv:2602.22441 , year=
How Do Latent Reasoning Methods Perform Under Weak and Strong Supervision? , author=. arXiv preprint arXiv:2602.22441 , year=
-
[35]
2026 , url=
Xilin Wei and Xiaoran Liu and Yuhang Zang and Xiaoyi Dong and Yuhang Cao and Jiaqi Wang and Xipeng Qiu and Dahua Lin , booktitle=. 2026 , url=
2026
-
[36]
2026 , url=
Connor Dilgren and Sarah Wiegreffe , booktitle=. 2026 , url=
2026
-
[37]
2026 , url=
Zihan Wang and Yijun Dong and Qi Lei , booktitle=. 2026 , url=
2026
-
[38]
arXiv preprint arXiv:2209.10652 , year=
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
-
[39]
arXiv preprint arXiv:2604.08764 , year=
Revisiting Anisotropy in Language Transformers: The Geometry of Learning Dynamics , author=. arXiv preprint arXiv:2604.08764 , year=
-
[40]
arXiv preprint arXiv:1812.04754 , year=
Gradient descent happens in a tiny subspace , author=. arXiv preprint arXiv:1812.04754 , year=
-
[41]
arXiv preprint arXiv:2311.03658 , year=
The linear representation hypothesis and the geometry of large language models , author=. arXiv preprint arXiv:2311.03658 , year=
-
[42]
arXiv preprint arXiv:2310.02207 , year=
Language models represent space and time , author=. arXiv preprint arXiv:2310.02207 , year=
-
[43]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Dissecting recall of factual associations in auto-regressive language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[44]
arXiv preprint arXiv:2505.11423 , year=
When thinking fails: The pitfalls of reasoning for instruction-following in llms , author=. arXiv preprint arXiv:2505.11423 , year=
-
[45]
Faithful chain-of-thought reasoning , author=. Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
Tomek Korbak and Mikita Balesni and Elizabeth Barnes and Yoshua Bengio and Joe Benton and Joseph Bloom and Mark Chen and Alan Cooney and Allan Dafoe and Anca Dragan and Scott Emmons and Owain Evans and David Farhi and Ryan Greenblatt and Dan Hendrycks and Marius Hobbhahn and Evan Hubinger and Geoffrey Irving and Erik Jenner and Daniel Kokotajlo and Victor...
-
[47]
Journal of Machine Learning Research , year =
Atticus Geiger and Duligur Ibeling and Amir Zur and Maheep Chaudhary and Sonakshi Chauhan and Jing Huang and Aryaman Arora and Zhengxuan Wu and Noah Goodman and Christopher Potts and Thomas Icard , title =. Journal of Machine Learning Research , year =
-
[48]
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics. 2022. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[49]
2023 , eprint=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. 2023 , eprint=
2023
-
[50]
A ttention is not E xplanation
Jain, Sarthak and Wallace, Byron C. A ttention is not E xplanation. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1357
-
[51]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
2023
-
[52]
2022 , journal=
Causal scrubbing, a method for rigorously testing interpretability hypotheses , author=. 2022 , journal=
2022
-
[53]
2024 , eprint=
How to use and interpret activation patching , author=. 2024 , eprint=
2024
-
[54]
The Thirteenth International Conference on Learning Representations , year=
Everything, Everywhere, All at Once: Is Mechanistic Interpretability Identifiable? , author=. The Thirteenth International Conference on Learning Representations , year=
-
[55]
arXiv preprint arXiv:2503.08679 , year=
Chain-of-thought reasoning in the wild is not always faithful , author=. arXiv preprint arXiv:2503.08679 , year=
-
[56]
arXiv preprint arXiv:2603.05488 , year=
Reasoning theater: Disentangling model beliefs from chain-of-thought , author=. arXiv preprint arXiv:2603.05488 , year=
-
[57]
arXiv preprint arXiv:2510.24941 , year=
Can Aha Moments Be Fake? Identifying True and Decorative Thinking Steps in Chain-of-Thought , author=. arXiv preprint arXiv:2510.24941 , year=
-
[58]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[59]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Towards interpretable sequence continuation: Analyzing shared circuits in large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[60]
2023 , eprint=
The Hydra Effect: Emergent Self-repair in Language Model Computations , author=. 2023 , eprint=
2023
-
[61]
2026 , eprint=
What Really Controls Temporal Reasoning in Large Language Models: Tokenisation or Representation of Time? , author=. 2026 , eprint=
2026
-
[62]
Date Fragments: A Hidden Bottleneck of Tokenization for Temporal Reasoning
Bhatia, Gagan and Peyrard, Maxime and Zhao, Wei. Date Fragments: A Hidden Bottleneck of Tokenization for Temporal Reasoning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.159
-
[63]
A Glitch in the Matrix? Locating and Detecting Language Model Grounding with Fakepedia
Monea, Giovanni and Peyrard, Maxime and Josifoski, Martin and Chaudhary, Vishrav and Eisner, Jason and Kiciman, Emre and Palangi, Hamid and Patra, Barun and West, Robert. A Glitch in the Matrix? Locating and Detecting Language Model Grounding with Fakepedia. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1:...
-
[64]
Bogdan and Uzay Macar and Neel Nanda and Arthur Conmy , booktitle=
Paul C. Bogdan and Uzay Macar and Neel Nanda and Arthur Conmy , booktitle=. 2025 , url=
2025
-
[65]
The Fourteenth International Conference on Learning Representations , year=
The Geometry of Reasoning: Flowing Logics in Representation Space , author=. The Fourteenth International Conference on Learning Representations , year=
-
[66]
2024 , month = sep, url =
2024
-
[67]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , year=. 2407.21783 , archivePrefix=
-
[68]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.