Rigel: Reverse-Engineering the Metal 4.1 Tensor Compute Path on the Apple M4 Max GPU
Pith reviewed 2026-06-27 07:13 UTC · model grok-4.3
The pith
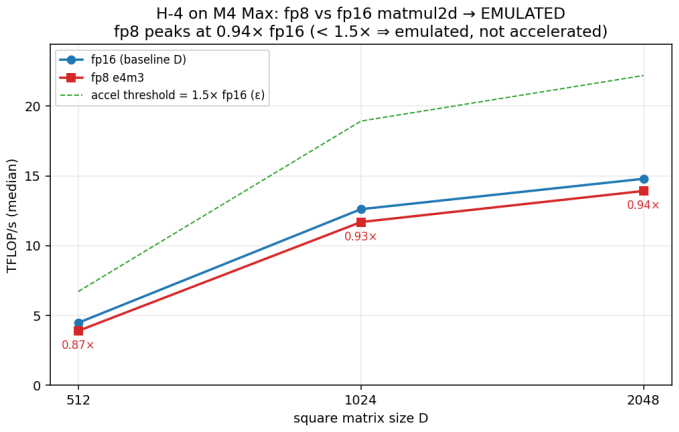
Apple's Metal 4.1 fp8 matmul2d on the M4 Max GPU runs at 0.94 times fp16 throughput despite using half the data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
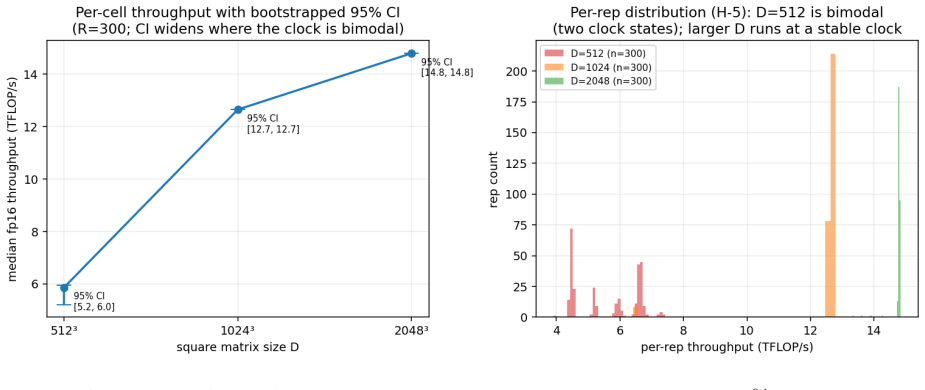
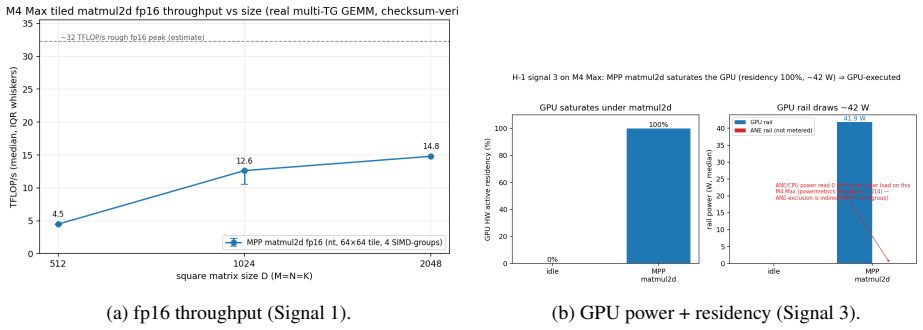
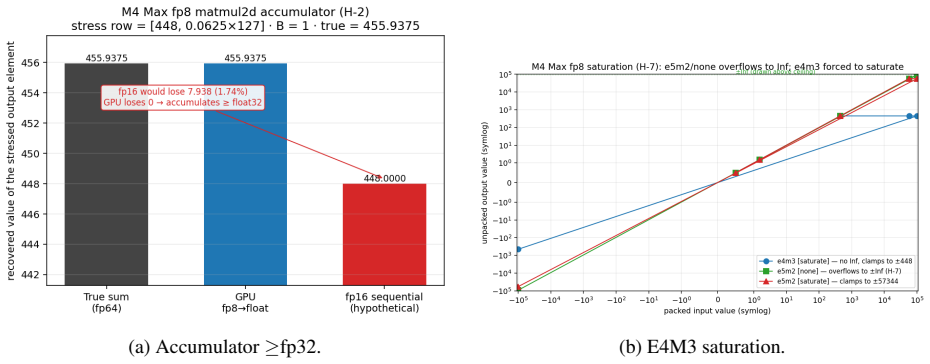
The Metal 4.1 fp8 (E4M3) matmul2d is emulated on the GPU shader cores rather than using dedicated hardware, sustaining 0.94x the throughput of fp16 while reading half the operand bytes, indicating it is a memory-footprint optimization rather than a performance one. It executes entirely on shader cores with no evidence of Neural Engine involvement, accumulates in fp32 or wider, and uses an 8x8 cooperative_tensor fragment layout.
What carries the argument
Checksum-gated, provenance-tracked microbenchmark harness combined with three-signal triangulation of throughput ceiling, simdgroup_matrix comparison, and per-rail power attribution.
If this is right
- matmul2d executes entirely on shader cores with no dedicated matrix datapath
- accumulation occurs in at least fp32 precision
- the cooperative_tensor fragment layout is an undocumented 8x8 structure
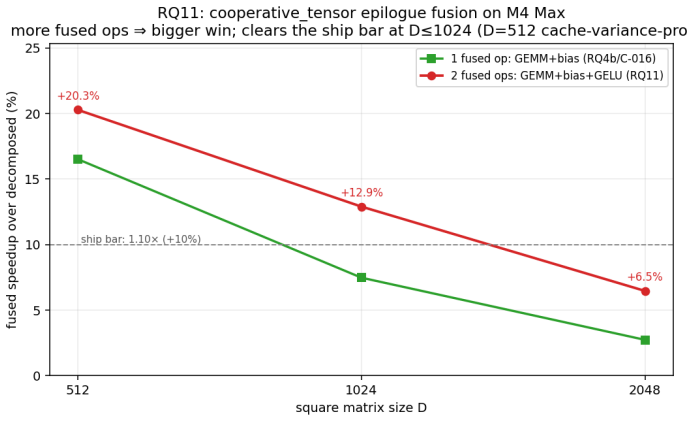
- hand-fused GEMM plus bias plus GELU kernels outperform the decomposed path by 6.5 to 12.9 percent in the cache-resident regime
- all findings are reproducible from the released MIT-licensed code and per-cell CSVs
Where Pith is reading between the lines
- Similar emulation behavior may hold on other current-generation Apple GPUs without dedicated neural accelerators.
- Memory-footprint benefits of fp8 remain usable even when speed gains are absent for large models.
- The microbenchmark method could be extended to other hidden paths in future Metal releases.
- Fused kernels could be tested on additional operations to quantify further gains in the same regime.
Load-bearing premise
The microbenchmark harness isolates the matmul2d execution path without measurable interference from concurrent workloads, software layers, or other GPU components.
What would settle it
A measurement showing fp8 matmul2d throughput substantially exceeding fp16 on the same hardware or power rails indicating a dedicated datapath would disprove the emulation claim.
Figures

read the original abstract
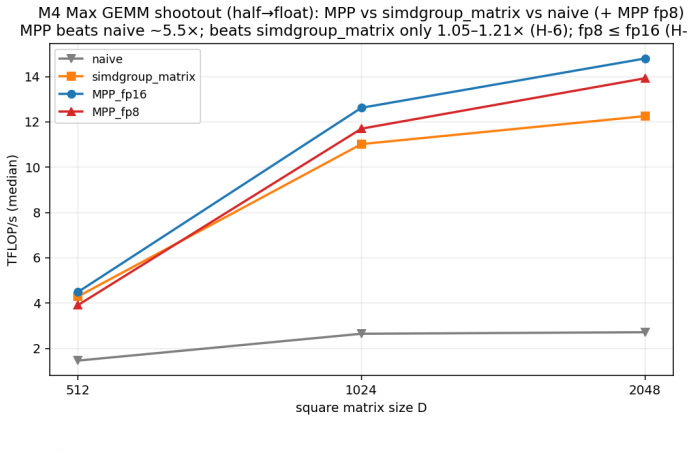
Apple's Metal 4.1 exposes a tensor compute path: the Metal Performance Primitives (MPP) matmul2d operation over cooperative_tensor fragments, whose interface is documented but whose hardware behavior is deliberately hidden. The specification states which data-type rows are supported, never whether they are hardware-accelerated, where the operation physically executes, what its accumulator width is, or how it partitions matrix fragments across threads. We present Rigel, an empirical characterization of this path on a single Apple M4 Max (a pre-neural-accelerator generation). Using a checksum-gated, provenance-tracked microbenchmark harness, Rigel recovers eleven facts the v4.1 specification hides or contradicts. The headline finding: the Metal 4.1 fp8 (E4M3) matmul2d is emulated, not accelerated: it sustains 0.94x the throughput of fp16 despite reading half the operand bytes, so on M4 it is a memory-footprint feature, not a performance feature. We further show, via a three-signal triangulation (throughput ceiling, comparison against simdgroup_matrix, and per-rail power attribution), that matmul2d executes entirely on the GPU shader cores with no dedicated matrix datapath and no evidence of Apple Neural Engine routing; that it accumulates in >=fp32; and we reconstruct the opaque 8x8 cooperative_tensor fragment layout Apple documents nowhere. Acting on the characterization, a hand-fused GEMM + bias + GELU kernel beats the decomposed path by +6.5-12.9% in the cache-resident regime. All findings are reproducible from committed MIT-licensed code and per-cell CSVs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Rigel, an empirical reverse-engineering effort using a checksum-gated, provenance-tracked microbenchmark harness on a single Apple M4 Max GPU. It claims to recover eleven hidden or contradicted facts about the Metal 4.1 MPP matmul2d operation over cooperative_tensor fragments, with the central finding that fp8 (E4M3) matmul2d is emulated on shader cores (0.94x fp16 throughput despite half the operand bytes) rather than hardware-accelerated. Additional claims include execution entirely on GPU shader cores (via throughput ceiling, simdgroup_matrix comparison, and per-rail power triangulation), accumulation in >=fp32, reconstruction of the undocumented 8x8 fragment layout, and a hand-fused GEMM kernel outperforming the decomposed path by 6.5-12.9% in cache-resident regimes. All results are supported by MIT-licensed code and per-cell CSVs.
Significance. If the measurements correctly isolate matmul2d execution, the work provides a concrete, falsifiable characterization of undocumented tensor compute behavior on a pre-neural-accelerator Apple GPU, showing fp8 as a memory-footprint feature rather than a performance one. The open release of code, CSVs, and the three-signal attribution method (throughput, simdgroup_matrix, power) enables direct reproducibility and extends the empirical toolkit for reverse-engineering proprietary GPU paths.
minor comments (2)
- [Abstract] The abstract states that Rigel recovers 'eleven facts' but the main text would benefit from an explicit enumerated list or table cross-referencing each fact to its supporting measurement (e.g., §4 or §5).
- [Figures] Figure captions for the throughput and power plots should include the exact matrix dimensions, threadgroup sizes, and number of repetitions used in the checksum-gated runs to aid direct replication from the released CSVs.
Simulated Author's Rebuttal
We thank the referee for their positive assessment and recommendation to accept. The report correctly captures the scope and methodology of the work.
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on direct empirical measurements obtained from a checksum-gated microbenchmark harness, throughput ceilings, simdgroup_matrix comparisons, and per-rail power attribution. No equations, fitted parameters, or self-referential definitions appear; the fp8 emulation inference follows from observed 0.94x fp16 throughput parity despite halved operand size, and the execution-location attribution follows from the three-signal triangulation. The reproducibility commitment (MIT code + CSVs) supplies an external verification path. No self-citation chains, ansatzes, or renamings of known results are load-bearing. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The microbenchmark environment experiences no significant interference from concurrent processes or other GPU workloads during throughput and power measurements.
- domain assumption The three-signal triangulation (throughput ceiling, simdgroup_matrix comparison, per-rail power) accurately attributes execution to shader cores without false attribution.
Reference graph
Works this paper leans on
-
[1]
Metal shading language specification, version 4.1, 2026
Apple Inc. Metal shading language specification, version 4.1, 2026. Apple Developer Documentation; archived copy dated 2026-06-04
2026
-
[2]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher R´e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. arXiv:2205.14135
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Profiling Apple Silicon performance for ML training.arXiv preprint arXiv:2501.14925, 2025
Dahua Feng, Zhiming Xu, Rongxiang Wang, and Felix Xiaozhu Lin. Profiling Apple Silicon performance for ML training.arXiv preprint arXiv:2501.14925, 2025
- [5]
-
[6]
Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
Zhe Jia, Marco Maggioni, Benjamin Staiger, and Daniele P. Scarpazza. Dissecting the NVIDIA V olta GPU architecture via microbenchmarking.arXiv preprint arXiv:1804.06826, 2018. 10 Figure 7:Epilogue fusion.Fusing bias +GELU via a cooperative tensor destination beats the decomposed path; two fused ops beat one and clear the1.10×ship bar atD≤1024
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Dissecting the NVidia Turing T4 GPU via Microbenchmarking
Zhe Jia, Marco Maggioni, Jeffrey Smith, and Daniele Paolo Scarpazza. Dissecting the NVidia Turing T4 GPU via microbenchmarking.arXiv preprint arXiv:1903.07486, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[8]
Stefano Markidis, Steven Wei Der Chien, Erwin Laure, Ivy Bo Peng, and Jeffrey S. Vetter. NVIDIA tensor core programmability, performance & precision. InIEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), 2018. arXiv:1803.04014
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisenthwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, Naveen Mellempudi, Stuart Oberman, Mohammad Shoeybi, Michael Siu, and Hao Wu. FP8 formats for deep learning.arXiv preprint arXiv:2209.05433, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
OCP microscaling formats (MX) specification, version 1.0
Open Compute Project. OCP microscaling formats (MX) specification, version 1.0. Technical report, Open Compute Project Foundation, 2023
2023
-
[11]
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2407.08608
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Wei Sun, Ang Li, Tong Geng, Sander Stuijk, and Henk Corporaal. Dissecting tensor cores via microbenchmarks: Latency, throughput and numeric behaviors.IEEE Transactions on Parallel and Distributed Systems, 34(1): 246–261, 2023. doi: 10.1109/TPDS.2022.3217824. arXiv:2206.02874
-
[13]
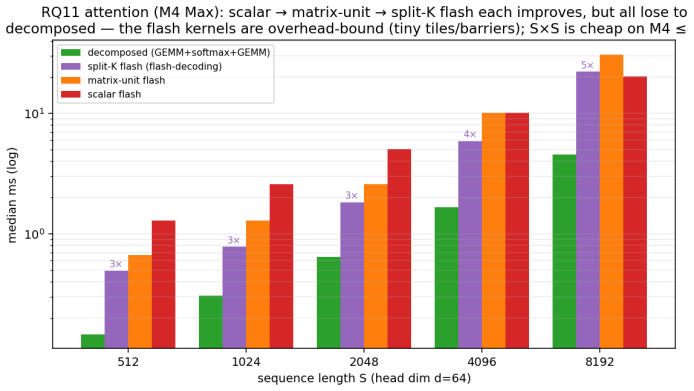
Philippe Tillet, H. T. Kung, and David Cox. Triton: An intermediate language and compiler for tiled neural network computations. InProc. 3rd ACM SIGPLAN Int. Workshop on Machine Learning and Programming Languages (MAPL), 2019. doi: 10.1145/3315508.3329973. 11 Figure 8:Attention: a negative result.Scalar, matrix-unit, and split-K flash each improve, but al...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.