Constructing Evaluation Datasets for Procedural Reasoning: Balancing Naturalness, Grounding, and Multi-Hop Coverage
Pith reviewed 2026-06-27 07:28 UTC · model grok-4.3
The pith
Strict generation from Task-Method-Knowledge models produces the most grounded datasets for procedural reasoning evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
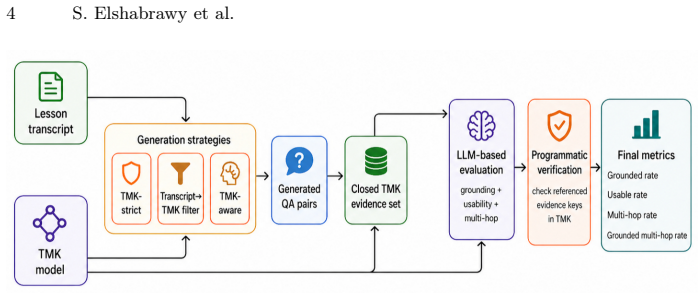
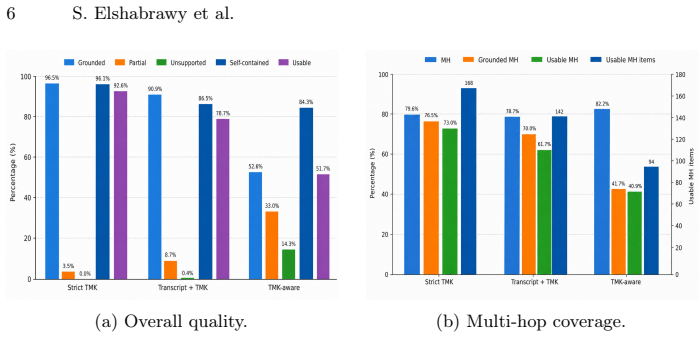
Strict generation from Task-Method-Knowledge (TMK) models achieves the strongest overall quality, with 96.5% grounded questions and 92.6% usable questions across 23 instructional topics and 690 generated pairs. Transcript-first generation produces more learner-like questions but yields more context-dependent or weakly grounded items. TMK-aware generation yields high raw multi-hop coverage but lower grounding. These outcomes demonstrate that procedural richness and natural phrasing do not guarantee representational grounding, motivating explicit representation-aware validation for evaluation datasets.
What carries the argument
The grounding validation framework, which extracts closed-set evidence units from TMK models to measure whether answers are supported by the underlying representation and whether questions are self-contained.
If this is right
- Procedural richness obtained from transcripts does not ensure that questions remain grounded in the instructional representation.
- Different generation strategies create explicit trade-offs among natural phrasing, grounding, and multi-hop coverage.
- Evaluation datasets for AI-supported learning require representation-aware validation rather than relying on surface features alone.
Where Pith is reading between the lines
- Datasets built this way could serve as benchmarks for testing whether new procedural reasoners actually operate over the same knowledge structures used in instruction.
- The validation framework might transfer to other structured representations such as hierarchical task networks or causal graphs used in planning systems.
Load-bearing premise
The grounding validation framework based on closed-set evidence units extracted from TMK models correctly determines whether answers are supported by the underlying representation and whether questions are self-contained.
What would settle it
Independent human raters assessing the same 690 pairs for grounding and usability and finding agreement with the framework below 80 percent would falsify the claim that the framework reliably measures representational support.
Figures
read the original abstract
Evaluating procedural reasoning in AI-supported learning systems requires question-answer datasets that are both learner-like and grounded in the instructional knowledge the system is expected to use. We study how TMK-based question generation strategies affect dataset quality for procedural and multi-hop reasoning. We compare three strategies: strict generation from Task-Method-Knowledge (TMK) models, transcript-first generation with post-hoc TMK filtering, and TMK-aware generation that combines transcripts with structured guidance. To evaluate generated items, we introduce a grounding validation framework based on closed-set evidence units extracted from TMK models. The framework measures whether answers are supported by the underlying representation, whether questions are self-contained, and whether they target multi-hop procedural reasoning. Across 23 instructional topics and 690 generated question-answer pairs, strict TMK generation achieves the strongest overall quality, with 96.5% grounded questions and 92.6% usable questions. Transcript-first generation produces more learner-like questions but more context-dependent or weakly grounded items, while TMK-aware generation yields high raw multi-hop coverage but lower grounding. These results show that procedural richness and natural phrasing do not guarantee representational grounding, motivating explicit representation-aware validation for evaluation datasets in AI-supported learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for constructing evaluation datasets for procedural reasoning, three TMK-based generation strategies were compared across 23 instructional topics yielding 690 question-answer pairs. Strict TMK generation from Task-Method-Knowledge models produces the highest quality with 96.5% grounded questions and 92.6% usable questions according to a new grounding validation framework that extracts closed-set evidence units from TMK models to assess support for answers, self-containment of questions, and multi-hop procedural targeting. Transcript-first generation yields more learner-like items but weaker grounding, while TMK-aware generation shows high multi-hop coverage but lower grounding scores. The work concludes that naturalness and procedural richness do not guarantee representational grounding, motivating explicit representation-aware validation.
Significance. If the central comparative result holds after addressing validation concerns, the work is significant for AI-supported learning systems because it supplies concrete empirical evidence that procedural dataset quality requires explicit grounding checks rather than relying on natural phrasing or multi-hop coverage alone. The study provides a reproducible empirical comparison using explicitly defined metrics on generated items and introduces a validation framework that could be extended to other structured representations.
major comments (2)
- [Grounding validation framework (abstract and methods)] The grounding validation framework (described in the abstract and the methods) extracts closed-set evidence units from TMK models to determine whether answers are supported and questions are self-contained. Strict TMK generation produces items directly from the same TMK representation, so the reported 96.5% grounded rate is expected by construction; transcript-first and TMK-aware strategies start from external transcripts and are scored against the same units, creating a risk that mismatches reflect divergence from the TMK model rather than true lack of grounding in the instructional material. This is load-bearing for the claim that strict TMK achieves the strongest overall quality.
- [Results reporting (abstract and results section)] The abstract reports concrete percentages (96.5% grounded, 92.6% usable) across 690 pairs but supplies no error bars, no explicit definition of 'usable', no description of how multi-hop coverage was counted, no details on the 23 topics, and no inter-rater reliability statistics for the validation. These omissions prevent assessment of the stability and replicability of the metrics that underpin the main comparative conclusion.
minor comments (1)
- [Abstract] The abstract states that the framework measures 'whether they target multi-hop procedural reasoning' but does not indicate the operational criteria or counting procedure used for this dimension.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Grounding validation framework (abstract and methods)] The grounding validation framework (described in the abstract and the methods) extracts closed-set evidence units from TMK models to determine whether answers are supported and questions are self-contained. Strict TMK generation produces items directly from the same TMK representation, so the reported 96.5% grounded rate is expected by construction; transcript-first and TMK-aware strategies start from external transcripts and are scored against the same units, creating a risk that mismatches reflect divergence from the TMK model rather than true lack of grounding in the instructional material. This is load-bearing for the claim that strict TMK achieves the strongest overall quality.
Authors: The framework is intentionally representation-aware and measures alignment to the TMK model as the target knowledge structure for the AI-supported learning system. While strict generation scores high by construction, the comparative results show that transcript-based methods yield lower alignment even when drawn from the same instructional topics. This supports the paper's conclusion that naturalness and multi-hop coverage do not ensure grounding. We will revise the methods section to explicitly discuss the framework's design and this interpretive point. revision: partial
-
Referee: [Results reporting (abstract and results section)] The abstract reports concrete percentages (96.5% grounded, 92.6% usable) across 690 pairs but supplies no error bars, no explicit definition of 'usable', no description of how multi-hop coverage was counted, no details on the 23 topics, and no inter-rater reliability statistics for the validation. These omissions prevent assessment of the stability and replicability of the metrics that underpin the main comparative conclusion.
Authors: We agree that these details are needed for replicability. In the revised manuscript we will add error bars to the reported percentages, an explicit definition of 'usable', a description of the multi-hop counting procedure, additional details on the 23 topics, and inter-rater reliability statistics, updating both the abstract and results section accordingly. revision: yes
Circularity Check
Grounding validation defined from TMK evidence units makes strict TMK scores tautological by construction
specific steps
-
self definitional
[Abstract]
"To evaluate generated items, we introduce a grounding validation framework based on closed-set evidence units extracted from TMK models. The framework measures whether answers are supported by the underlying representation, whether questions are self-contained, and whether they target multi-hop procedural reasoning. Across 23 instructional topics and 690 generated question-answer pairs, strict TMK generation achieves the strongest overall quality, with 96.5% grounded questions and 92.6% usable questions."
Groundedness is defined as support by evidence units extracted from TMK models. Strict TMK generation produces items directly from those same TMK models, so the reported 96.5% grounded rate follows by construction from the shared source rather than from an independent test of grounding.
full rationale
The paper's main empirical claim (strict TMK generation yields 96.5% grounded / 92.6% usable items) rests on a validation framework whose closed-set evidence units are extracted directly from the same TMK models used to generate the strict-TMK items. This produces an alignment score that is definitionally expected rather than independently tested. Other generation strategies are scored against the identical TMK-derived units, creating an asymmetric and self-referential metric. No external grounding oracle or human judgment independent of the TMK representation is described. The result therefore reduces to a comparison of fidelity to the TMK source rather than an external measure of representational grounding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption TMK models extracted from instructional materials provide a sufficient closed-set representation for validating answer support and question self-containment.
Reference graph
Works this paper leans on
-
[1]
Bohnet, B., Tran, V.Q., Verga, P., Aharoni, R., Andor, D., Soares, L.B., Ciaramita, M., Eisenstein, J., Ganchev, K., Herzig, J., Hui, K., Kwiatkowski, T., Ma, J., Ni, J., Saralegui, L.S., Schuster, T., Cohen, W.W., Collins, M., Das, D., Metzler, D., Petrov, S., Webster, K.: Attributed question answering: Evaluation and modeling for attributed large langua...
arXiv 2023
-
[2]
Chandrasekaran, B.: Generic tasks in knowledge-based reasoning: high-level building blocks for expert system design, p. 170–177. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (1993)
1993
-
[3]
Chandrasekaran, B., Johnson, T.R., Smith, J.W.: Task-structure analysis for knowl- edge modeling. Commun. ACM35(9), 124–137 (Sep 1992).https://doi.org/10 .1145/130994.131002,https://doi.org/10.1145/130994.131002 Evaluation Datasets for Procedural Reasoning 9
-
[4]
Dass, R.K., Madhusudhana, R.H., Deye, E.C., Verma, S., Bydlon, T.A., Brazil, G., Goel, A.K.: Ivy: A hybrid knowledge-based and generative ai coach for explain- ing procedural skills. In: Artificial Intelligence in Education: 26th International Conference, AIED 2025, Palermo, Italy, July 22–26, 2025, Proceedings, Part II. p. 233–246. Springer-Verlag, Berli...
-
[5]
Dass, R.K., Puri, S., Khandelwal, A., Jin, X., Goel, A.K.: Developing models of procedural skills using an ai-assisted text-to-model approach (2026),https: //arxiv.org/abs/2604.17624
Pith/arXiv arXiv 2026
-
[6]
Fujisawa, I., Nobe, S., Seto, H., Onda, R., Uchida, Y., Ikoma, H., Chien, P.C., Kanai, R.: Procbench: Benchmark for multi-step reasoning and following procedure (2024),https://arxiv.org/abs/2410.03117
arXiv 2024
-
[7]
Gao, M., Hu, X., Ruan, J., Pu, X., Wan, X.: Llm-based nlg evaluation: Current status and challenges (2025),https://arxiv.org/abs/2402.01383
arXiv 2025
-
[8]
IEEE Intelligent Systems32(3), 60–67 (2017).https://doi.org/10.1109/ MIS.2017.44
Goel, A.K., Rugaber, S.: Gaia: A cad-like environment for designing game-playing agents. IEEE Intelligent Systems32(3), 60–67 (2017).https://doi.org/10.1109/ MIS.2017.44
2017
-
[9]
ColBERTv2: Effective and efficient retrieval via lightweight late inter- action,
Honovich, O., Aharoni, R., Herzig, J., Taitelbaum, H., Kukliansy, D., Cohen, V., Scialom, T., Szpektor, I., Hassidim, A., Matias, Y.: TRUE: Re-evaluating factual consistency evaluation. In: Carpuat, M., de Marneffe, M.C., Meza Ruiz, I.V. (eds.) Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistic...
-
[10]
Hu, N., Chen, J., Wu, Y., Qi, G., Wang, H., Bi, S., Chen, Y., Wu, T., Pan, J.Z.: Can llms evaluate complex attribution in qa? automatic benchmarking using knowledge graphs (2025),https://arxiv.org/abs/2401.14640
arXiv 2025
-
[11]
Khot, T., Clark, P., Guerquin, M., Jansen, P., Sabharwal, A.: Qasc: A dataset for question answering via sentence composition (2020),https://arxiv.org/abs/19 10.11473
2020
-
[12]
In: Sawyer, R.K
Koedinger, K.R., Corbett, A.T.: Cognitive tutors: Technology bringing learning science to the classroom. In: Sawyer, R.K. (ed.) The Cambridge Handbook of the Learning Sciences, pp. 61–78. Cambridge University Press, New York, NY (2006)
2006
-
[13]
In: Graf, S., Markos, A
Lum, C., Deye, E., Brazil, G., Bydlon, T., Verma, S., Madhusudhana, R., Dass, R., Goel, A.: Designing an ai coaching system for interactive video-based skill learning. In: Graf, S., Markos, A. (eds.) Generative Systems and Intelligent Tutoring Systems. pp. 281–291. Springer Nature Switzerland, Cham (2026)
2026
-
[14]
doi: 10.18653/v1/2023.emnlp-main.741
Min, S., Krishna, K., Lyu, X., Lewis, M., Yih, W.t., Koh, P., Iyyer, M., Zettlemoyer, L., Hajishirzi, H.: FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. In: Bouamor, H., Pino, J., Bali, K. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 12076–12100. Associatio...
-
[15]
Murdock, J.W., Goel, A.K.: Meta-case-based reasoning: self-improvement through self-understanding. J. Exp. Theor. Artif. Intell.20(1), 1–36 (Mar 2008).https: //doi.org/10.1080/09528130701472416 , https://doi.org/10.1080/09528130 701472416 10 S. Elshabrawy et al
-
[16]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Nguyen, T.S., Yang, H., Neoh, T.Y., Zhang, H., Yeo Keat, E., Fernando, B.: PKR- QA: A benchmark for procedural knowledge reasoning with knowledge module learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 24549–24557 (2026).https://doi.org/10.1609/aaai.v40i29.39638, https: //doi.org/10.1609/aaai.v40i29.39638
-
[17]
Rashkin, H., Nikolaev, V., Lamm, M., Aroyo, L., Collins, M., Das, D., Petrov, S., Tomar, G.S., Turc, I., Reitter, D.: Measuring attribution in natural language generation models. Computational Linguistics49(4), 777–840 (Dec 2023).https: //doi.org/10.1162/coli_a_00486,https://aclanthology.org/2023.cl-4.2/
-
[18]
Lost in the Middle: How Language Models Use Long Contexts
Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A.: MuSiQue: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics10, 539–554 (2022).https://doi.org/10.1162/tacl _a_00475,https://aclanthology.org/2022.tacl-1.31/
work page internal anchor Pith review doi:10.1162/tacl 2022
-
[19]
Vanlehn, K.: The behavior of tutoring systems. Int. J. Artif. Intell. Ed.16(3), 227–265 (Aug 2006)
2006
-
[20]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W., Salakhutdinov, R., Manning, C.D.: HotpotQA: A dataset for diverse, explainable multi-hop question answering. In: Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J. (eds.) Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 2369–2380. Association for Computational ...
-
[21]
Computational Linguistics51(4), 1373–1418 (2025)
Zhang, Y., Li, Y., Cui, L., Cai, D., Liu, L., Fu, T., Huang, X., Zhao, E., Zhang, Y., Chen, Y., et al.: Siren’s song in the ai ocean: A survey on hallucination in large language models. Computational Linguistics51(4), 1373–1418 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.