Language-Guided Abstraction for Visual Reasoning
Pith reviewed 2026-06-27 07:45 UTC · model grok-4.3
The pith
A temporary language branch injects structured semantic embeddings into visual training to improve abstract rule learning on ARC tasks in a final 18-million-parameter model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
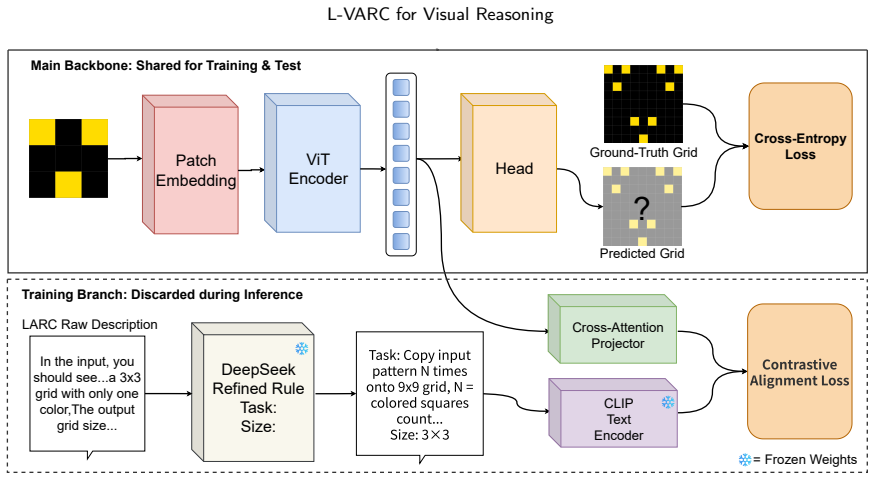
The central claim is that guiding a visual model with semantic embeddings derived from language descriptions of transformation rules, aligned through cross-attention, enables better learning of abstract concepts in few-shot settings on the ARC benchmark. The approach structures language annotations into embeddings and transfers their information during training only, producing improved generalization on new tasks while keeping the inference model lightweight at 18 million parameters.
What carries the argument
The language-guided Learning Using Privileged Information branch, consisting of a Semantic Compression Module that refines language descriptions into structured embeddings and a Cross-Attention Projector that aligns those embeddings with visual features during training.
If this is right
- The final model requires no language input at test time and stays at 18 million parameters.
- Visual reasoning avoids overfitting to low-level patterns by incorporating high-level semantic guidance from language.
- The framework connects language-based and vision-only approaches to abstraction tasks.
- Ablation experiments confirm separate contributions from the compression step and the alignment projector.
Where Pith is reading between the lines
- Similar privileged language information could be collected and applied to other few-shot visual reasoning problems beyond ARC.
- If the embeddings encode general rules, the training method might support transfer to abstract domains with novel transformations.
- Expanding the collection of structured language descriptions for such tasks could strengthen the guidance effect.
Load-bearing premise
The embeddings from compressed language descriptions must accurately represent abstract transformation rules in a form that transfers to the visual model without introducing distribution shifts or new overfitting.
What would settle it
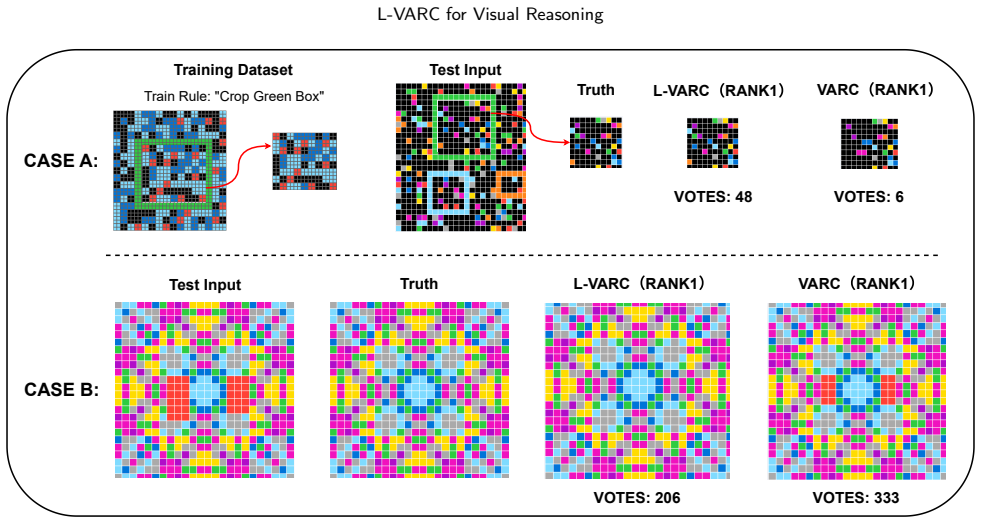
An experiment that replaces the semantic embeddings with unrelated vectors and finds no loss in the reported performance gains, or that shows the model fails to generalize on a fresh set of ARC tasks with distinct rule structures, would falsify the central claim.
Figures




read the original abstract
The Abstraction and Reasoning Corpus (ARC) is viewed as a critical avenue to Artificial General Intelligence (AGI), as it enables models to learn abstract transformation rules from few-shot examples and then generalize to new tasks. However, prevalent ARC methodology is either pure language or vision-only (i.e., VARC). The former depends heavily on LLMs, consuming billions of parameters. The latter often struggles to capture high-level semantics, leading to overfitting on pixel-level patterns. To bridge this gap, we propose L-VARC, a novel framework that enhances visual reasoning via a language-guided Learning Using Privileged Information (LUPI) branch. Specifically, we design a Semantic Compression Module by feeding a unified, task-agnostic prompt into DeepSeek-V3. In this way, the raw LARC (a crowd-sourced language description dataset) can be substantially refined and structured, fitting with the context length constraint of standard text encoders (e.g., CLIP). Moreover, we design a Cross-Attention Projector to align visual features with semantic embeddings, aiming to guide the training of the ARC model. Notably, the LUPI branch is taken in the training process and will be discarded during inference, thereby yielding a lightweight model with a mere 18 million parameters. Extensive experiments demonstrate that our L-VARC effectively leverages linguistic priors to boost visual reasoning and outperforms state-of-the-art. Ablation studies further confirm the contribution of the two new designs towards the L-VARC framework. The code is available at https://github.com/GZHU-DVL/L-VARC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes L-VARC, a language-guided LUPI framework for ARC visual reasoning. A Semantic Compression Module feeds a unified task-agnostic prompt to DeepSeek-V3 on LARC data to produce structured embeddings within CLIP-length limits; these are aligned to visual features via a Cross-Attention Projector during training only. The LUPI branch is discarded at inference, yielding an 18M-parameter model claimed to outperform prior SOTA, with ablations confirming the two modules.
Significance. If the quantitative claims hold with proper controls, the work would show a practical route to injecting linguistic priors into small visual backbones for few-shot abstraction tasks without inference overhead, addressing the parameter bloat of LLM-only ARC methods and the overfitting of pure vision approaches.
major comments (2)
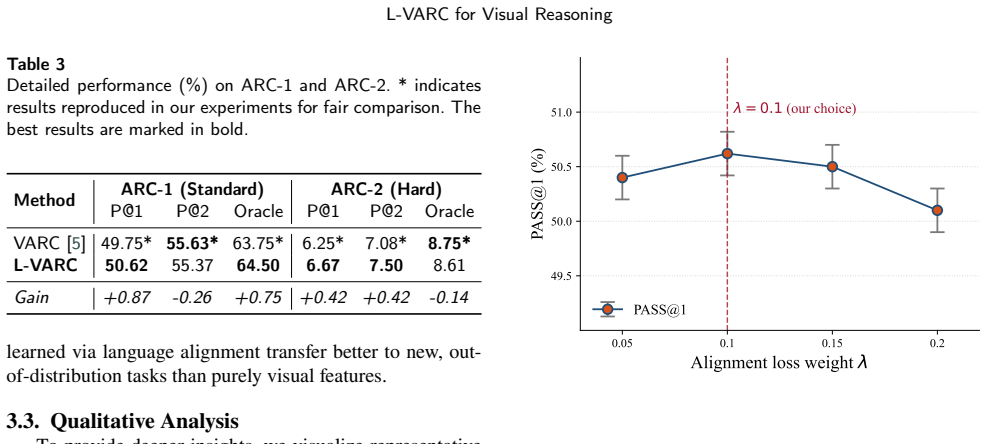
- [Abstract] Abstract and experimental section: the central claim of outperforming SOTA with an 18M model via LUPI requires quantitative support (accuracy deltas, baselines, error bars, statistical tests); none are supplied in the abstract and the skeptic note indicates the full experimental section lacks these details, rendering the outperformance assertion unverifiable.
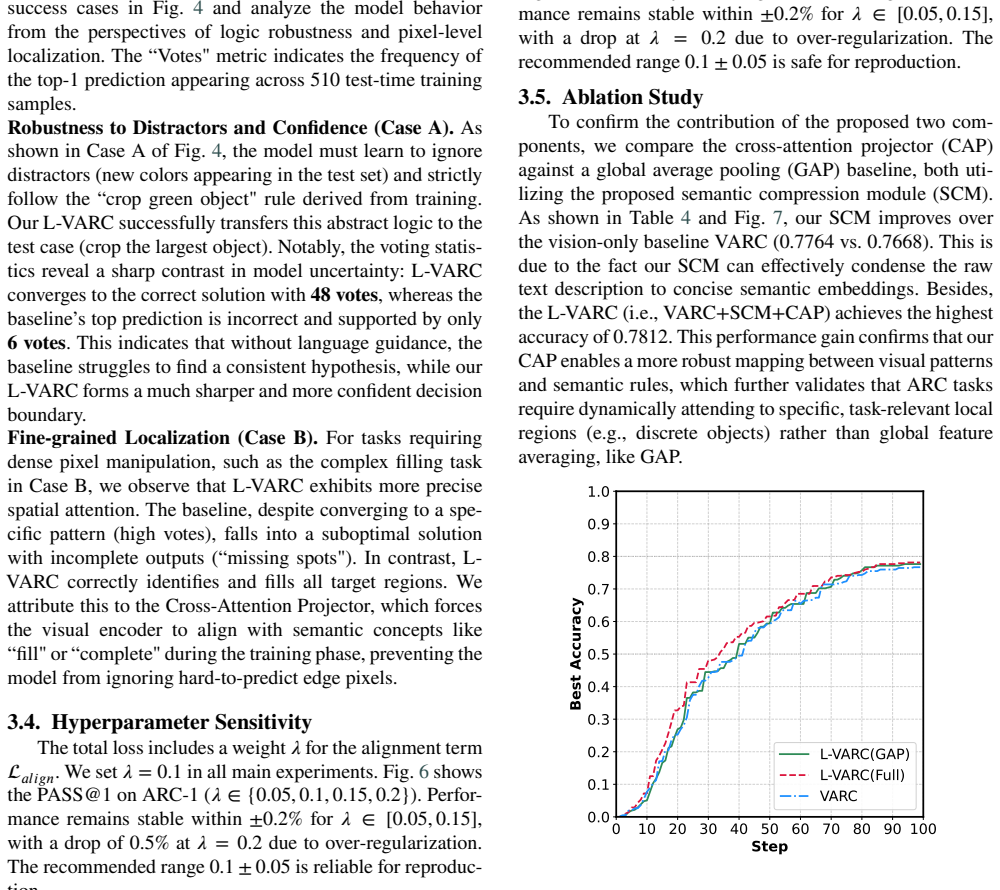
- [Method] Semantic Compression Module and Cross-Attention Projector sections: the claim that DeepSeek-V3 embeddings on the unified prompt capture abstract transformation rules (rotation, color mapping) in a task-agnostic manner, rather than surface descriptions, is load-bearing for the LUPI benefit; no embedding-quality validation, no ablation isolating the projector, and no train/test distribution alignment check are described, so the reported gains could arise from regularization alone.
minor comments (1)
- [Abstract] The GitHub link is a positive step for reproducibility; ensure the released code includes the exact prompt template and projector architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the quantitative claims require more explicit support and that additional validation for the modules would strengthen the paper. We address each major comment below and commit to revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental section: the central claim of outperforming SOTA with an 18M model via LUPI requires quantitative support (accuracy deltas, baselines, error bars, statistical tests); none are supplied in the abstract and the skeptic note indicates the full experimental section lacks these details, rendering the outperformance assertion unverifiable.
Authors: We agree the abstract should include specific quantitative support and that the experimental section needs accuracy deltas, baselines, error bars, and statistical tests for verifiability. In the revision we will update the abstract with key performance numbers (e.g., accuracy improvements over prior SOTA) and expand the experiments section accordingly, including any required controls to address the skeptic note. revision: yes
-
Referee: [Method] Semantic Compression Module and Cross-Attention Projector sections: the claim that DeepSeek-V3 embeddings on the unified prompt capture abstract transformation rules (rotation, color mapping) in a task-agnostic manner, rather than surface descriptions, is load-bearing for the LUPI benefit; no embedding-quality validation, no ablation isolating the projector, and no train/test distribution alignment check are described, so the reported gains could arise from regularization alone.
Authors: We acknowledge the need for explicit validation that the embeddings capture abstract rules rather than surface features. In the revision we will add embedding-quality validation (e.g., qualitative examples or similarity analyses), an ablation study isolating the Cross-Attention Projector, and train/test distribution alignment checks to demonstrate the source of the gains. revision: yes
Circularity Check
No significant circularity; derivation relies on external LLM processing and standard training.
full rationale
The paper introduces L-VARC using DeepSeek-V3 (external) for the Semantic Compression Module on LARC data and a Cross-Attention Projector in a LUPI setup discarded at inference. No equations, self-citations, or fitted inputs are presented as predictions or first-principles results. The method is self-contained against external benchmarks with no reduction of claims to author-defined inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Crowd-sourced language descriptions in LARC accurately encode the abstract visual transformation rules.
Reference graph
Works this paper leans on
-
[1]
F.Chollet, Onthemeasureofintelligence, arXiv:1911.01547(2019)
Pith/arXiv arXiv 1911
-
[2]
F. Chollet, M. Knoop, G. Kamradt, B. Landers, Arc prize 2024: Technical report, arXiv:2412.04604 (2024)
arXiv 2024
-
[3]
R. Wang, E. Zelikman, G. Poesia, Y. Pu, N. Haber, N. D. Goodman, Hypothesis search: Inductive reasoning with language models, in: InternationalConferenceonLearningRepresentations(ICLR),2024
2024
-
[4]
Ellis, C
K. Ellis, C. Wong, M. Nye, M. Sablé-Meyer, L. Morales, L. Hewitt, L.Cary,A.Solar-Lezama,J.B.Tenenbaum, Dreamcoder:Bootstrap- ping inductive program synthesis with wake-sleep library learning, in: ACM SIGPLAN International Conference on Programming Lan- guage Design and Implementation (PLDI), 2021, pp. 835–850
2021
-
[5]
K. Hu, A. Cy, L. Qiu, X. D. Ding, R. Wang, Y. E. Zhu, J. Andreas, K. He, Arc is a vision problem!, arXiv:2511.14761 (2025)
arXiv 2025
-
[6]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, N. Houlsby, An image is worth 16x16 words: Trans- formers for image recognition at scale, in: International Conference on Learning Representations (ICLR), 2021
2021
-
[7]
L.Bottou,V.Vapnik, Locallearningalgorithms, NeuralComputation 4 (1992) 888–900
1992
-
[8]
Y. Sun, X. Wang, Z. Liu, J. Miller, A. Efros, M. Hardt, Test-time training with self-supervision for generalization under distribution shifts, in: International Conference on Machine Learning (ICML), 2020, pp. 9229–9248
2020
-
[9]
W. Li, Y. Xu, S. Sanner, E. B. Khalil, Tackling the abstraction and reasoning corpus with vision transformers: the importance of 2d representation, positions, and objects, Transactions on Machine Learning Research (TMLR) (2025)
2025
- [10]
-
[11]
Z.Jia,J.Wang,K.Song,Z.Wang,X.Ma,R.Jin, Aduetofperception andreasoning:Clipandllmbrainstormingforscenetextrecognition, Neurocomputing (2025) 132236
2025
-
[12]
Vapnik, A
V. Vapnik, A. Vashist, A new learning paradigm: Learning using privileged information, Neural Networks 22 (2009) 544–557
2009
-
[13]
Acquaviva, Y
S. Acquaviva, Y. Pu, M. Kryven, T. Sechopoulos, C. Wong, G. Ecanow, M. Nye, M. Tessler, J. Tenenbaum, Communicating natural programs to humans and machines, in: Advances in Neural Information Processing Systems (NeurIPS), volume 35, 2022, pp. 3731–3743
2022
-
[14]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al., Deepseek-v3 technical report, arXiv:2412.19437 (2024)
Pith/arXiv arXiv 2024
-
[15]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G.Sastry,A.Askell,P.Mishkin,J.Clark,etal., Learningtransferable visual models from natural language supervision, in: International Conference on Machine Learning (ICML), 2021, pp. 8748–8763
2021
-
[16]
W.Zhang,Q.Tan,P.Li,Q.Zhang,R.Wang,Cross-modaltransformer withlanguagequeryforreferringimagesegmentation, Neurocomput- ing 536 (2023) 191–205
2023
-
[17]
Pechyony, V
D. Pechyony, V. Vapnik, On the theory of learnining with privileged information, Advances in neural information processing systems (NeurIPS) 23 (2010)
2010
-
[18]
24824–24837
J.Wei,X.Wang,D.Schuurmans,M.Bosma,F.Xia,E.Chi,Q.V.Le, D.Zhou,etal., Chain-of-thoughtpromptingelicitsreasoninginlarge language models, in: Advances in Neural Information Processing Systems (NeurIPS), volume 35, 2022, pp. 24824–24837
2022
-
[19]
J. Li, D. Li, C. Xiong, S. Hoi, Blip: Bootstrapping language-image pre-training for unified vision-language understanding and genera- tion, in: International Conference on Machine Learning (ICML), 2022, pp. 12888–12900
2022
-
[20]
A. v. d. Oord, Y. Li, O. Vinyals, Representation learning with contrastive predictive coding, arXiv:1807.03748 (2018)
Pith/arXiv arXiv 2018
-
[21]
Yadkori, Hierarchical reasoning model, arXiv:2506.21734 (2025)
G.Wang,J.Li,Y.Sun,X.Chen,C.Liu,Y.Wu,M.Lu,S.Song,Y.A. Yadkori, Hierarchical reasoning model, arXiv:2506.21734 (2025)
Pith/arXiv arXiv 2025
-
[22]
Jolicoeur-Martineau, Less is more: Recursive reasoning with tiny networks, arXiv:2510.04871 (2025)
A. Jolicoeur-Martineau, Less is more: Recursive reasoning with tiny networks, arXiv:2510.04871 (2025)
Pith/arXiv arXiv 2025
-
[23]
X.Wang,Z.Ji,Y.Pang,Y.Yu,Acognition-drivenframeworkforfew- shotclass-incrementallearning,Neurocomputing600(2024)128118
2024
-
[24]
S. Vahdati, A. Aioanei, H. Suresh, J. Lehmann, The arc of progress towards agi: A living survey of abstraction and reasoning, arXiv:2603.13372 (2026)
arXiv 2026
-
[25]
Bratus, D
S. Bratus, D. F. Jenny, A. Plesner, R. Wattenhofer, A survey on the abstraction and reasoning corpus, TechRxiv (2026)
2026
-
[26]
W. L. de Oliveira, M. Bobokhonov, M. Caorsi, A. Podestà, G. Bel- tramo, L. Crosato, M. Bonotto, F. Cecchetto, H. Espic, D. T. Salajan, et al., Arc-agi-2 technical report, arXiv:2603.06590 (2026)
arXiv 2026
-
[27]
Bratus, D
S. Bratus, D. F. Jenny, A. Plesner, R. Wattenhofer, A survey on the abstraction and reasoning corpus, TechRxiv 2026 (2026)
2026
-
[28]
W.-J. Shu, X. Qiu, R.-J. Zhu, H. H. Chen, Y. Liu, H. Yang, Loopvit: Scaling visual arc with looped transformers, arXiv:2602.02156 (2026)
arXiv 2026
-
[29]
X. Yan, C. Li, Y. Shao, Y. Meng, Learning using statistical invari- ants with privileged information, Information Sciences 709 (2025) 122069
2025
-
[30]
Q. Song, H. Li, Y. Yu, H. Zhou, L. Yang, S. Bai, Q. She, Z. Huang, Y. Zhao, Codedance: A dynamic tool-integrated mllm for executable visual reasoning, arXiv:2512.17312 (2025)
arXiv 2025
-
[31]
Zhang, M
Z. Zhang, M. Jiang, J. Kong, J. Li, Llm guided counterfactual reasoning for zero-shot knowledge based visual question answering, Neurocomputing (2025) 131828
2025
-
[32]
H. Jiang, J. Fu, J. Fang, C. Gao, X. Wang, X. He, Y. Li, Univlr: Unifying text and vision in visual latent reasoning for multimodal llms, arXiv:2605.11856 (2026)
Pith/arXiv arXiv 2026
-
[33]
M. Vaishnav, T. Tammet, Symbolic grounding reveals representa- tional bottlenecks in abstract visual reasoning, arXiv:2604.21346 (2026)
Pith/arXiv arXiv 2026
-
[34]
Zhang, Z
W. Zhang, Z. Cheng, Y. He, Multimodal self-instruct: Synthetic abstractimageandvisualreasoninginstructionusinglanguagemodel, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024, pp. 19228–19252. Ye et al.:Preprint submitted to ElsevierPage 10 of 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.