The Hidden Power of Scaling Factor in LoRA Optimization
Pith reviewed 2026-06-27 07:11 UTC · model grok-4.3
The pith
The scaling factor alpha in LoRA drives optimization more effectively than the learning rate, with gains that cannot be replicated by learning rate scaling alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
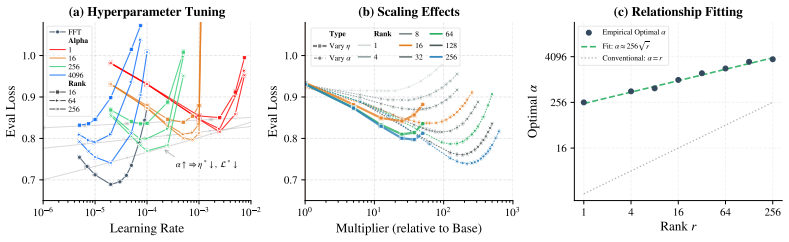
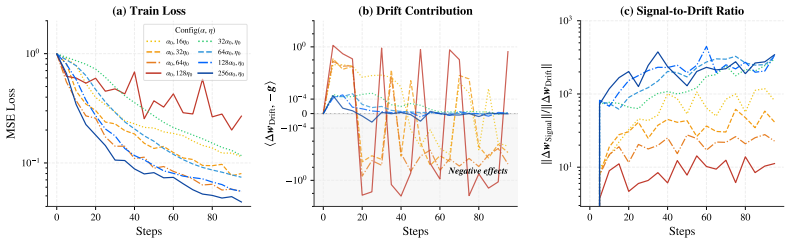
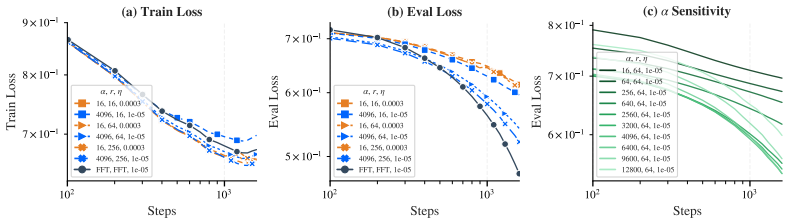
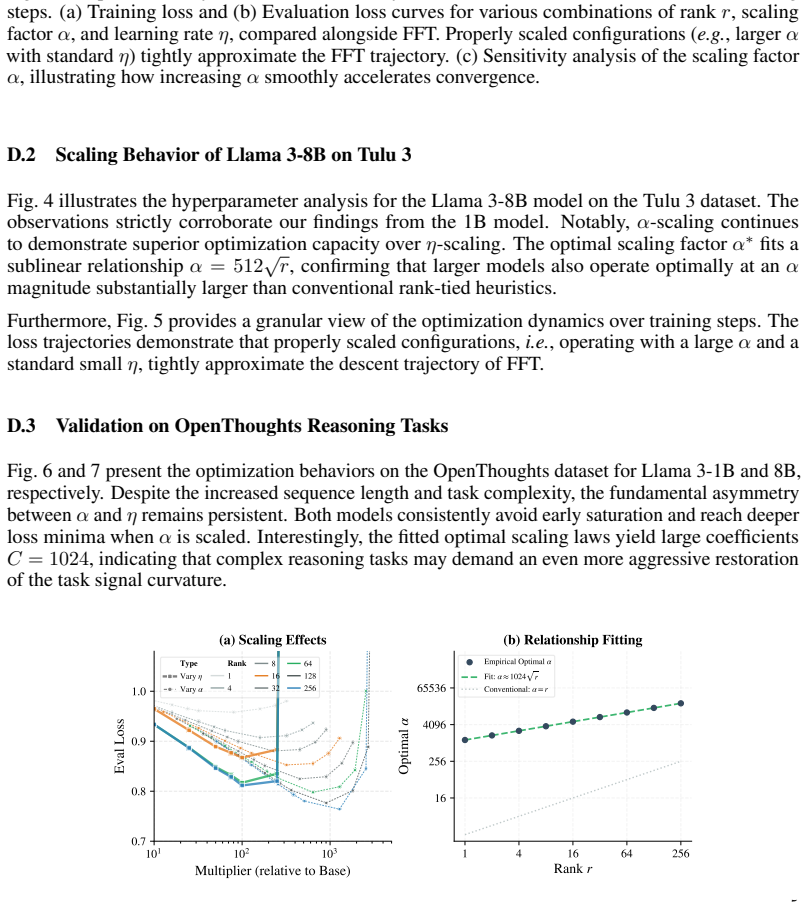
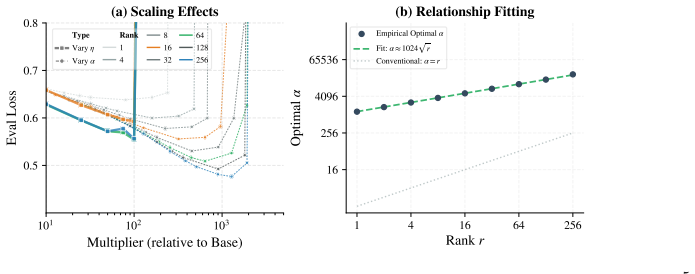
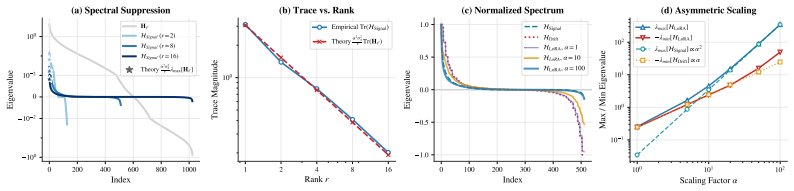
The scaling factor alpha emerges as the dominant driver of effective optimization in LoRA, delivering gains that cannot be replicated by learning rate scaling alone. Through the Signal-Drift framework, alpha amplifies the task signal without increasing the drift ratio. LoRA's spectral suppression smooths the landscape, rendering standard hyperparameters overly conservative. The optimal scaling factor follows a sublinear square-root law with rank and an unexpectedly large coefficient.
What carries the argument
The Signal-Drift framework, which shows how the scaling factor alpha amplifies the task signal without increasing the drift ratio.
If this is right
- LoRA's spectral suppression creates a smoother optimization landscape that makes standard hyperparameters overly conservative.
- Alpha accelerates convergence by amplifying the task signal without raising the drift ratio, outperforming learning rate adjustments.
- The optimal alpha follows a square-root law with rank and a large coefficient, exceeding the scaling in existing heuristics.
- LoRA-alpha sets alpha in its proper regime, making LoRA compatible with standard small learning rates.
- The approach yields consistent performance gains and reduces the need for extensive hyperparameter search across tasks.
Where Pith is reading between the lines
- The separation between alpha and learning rate effects may extend to other parameter-efficient fine-tuning methods that use scaling factors.
- Direct tests of the square-root law at much higher ranks could confirm the coefficient size or reveal adjustments.
- Relying on proper alpha values could simplify learning rate selection in LoRA practice.
- The Signal-Drift view might help analyze scaling choices in related adaptation techniques.
Load-bearing premise
The Signal-Drift framework and the empirical tasks represent general LoRA optimization dynamics rather than being limited to the specific models or datasets tested.
What would settle it
An experiment in which scaling the learning rate alone produces the same performance gains as adjusting alpha across multiple tasks and models would falsify the claim that alpha is the dominant driver.
Figures


read the original abstract
In Low-Rank Adaptation (LoRA), the scaling factor $\alpha$ is often treated as a mere complement to the learning rate, yet its role in optimization remains poorly understood. In this paper, we reveal that the scaling factor $\alpha$ and the learning rate function differently, with $\alpha$ emerging as the dominant driver of effective optimization, delivering gains that cannot be replicated by learning rate scaling alone. Through the synergy of extensive empirical analysis and a theoretical Signal-Drift framework, we uncover three findings into LoRA's scaling mechanism: First, LoRA's spectral suppression smooths the optimization landscape, rendering standard hyperparameters overly conservative and creating an optimization gap. Second, when leveraging this smoothness to accelerate convergence, $\alpha$ outperforms the learning rate by amplifying the task signal without increasing the drift ratio. Third, the optimal scaling factor follows a sublinear relationship with the rank, well characterized by a square-root law with an unexpectedly large coefficient, revealing the insufficient scaling of existing rank-tied heuristics. Based on these insights, we propose LoRA-$\alpha$, a minimalist framework that restores $\alpha$ to its principled regime, making LoRA compatible with standard small learning rates. Extensive evaluations across diverse tasks demonstrate that LoRA-$\alpha$ consistently improves performance while streamlining hyperparameter search, unleashing the learning potential of LoRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in LoRA the scaling factor α functions differently from the learning rate and emerges as the dominant driver of effective optimization, delivering performance gains that cannot be replicated by learning-rate scaling alone. It introduces a Signal-Drift framework to explain how spectral suppression in LoRA creates an optimization gap, shows that α amplifies task signal without increasing drift ratio, derives that optimal α follows a square-root law in rank with an unexpectedly large coefficient, and proposes the minimalist LoRA-α framework that restores α to its principled regime while making LoRA compatible with standard small learning rates. Extensive evaluations across diverse tasks are reported to confirm consistent improvements and streamlined hyperparameter search.
Significance. If the Signal-Drift framework holds and the empirical results generalize, the work would be significant for parameter-efficient fine-tuning: it reframes α as a first-class hyperparameter rather than a complement to the learning rate, offers a concrete square-root scaling rule, and provides a practical method to close the optimization gap without additional search cost. The combination of theoretical framing and broad empirical validation is a strength.
major comments (3)
- [section presenting the square-root law and its coefficient] The section deriving the square-root law for optimal α (the characterization with an unexpectedly large coefficient) appears post-hoc fitted to the reported experiments rather than derived from the Signal-Drift framework; this creates circularity between the claimed law and the data used to discover it. A pre-specified functional form or explicit derivation from the signal/drift definitions would be required to support the claim that existing rank-tied heuristics are insufficiently scaled.
- [Signal-Drift framework section (theoretical analysis)] The central claim that α produces gains irreducible to learning-rate scaling rests on the Signal-Drift framework correctly separating signal amplification from drift increase. The definitions of signal and drift, and the quantitative argument that α outperforms LR adjustments, must be shown explicitly; without these, the non-replicability result cannot be verified.
- [experimental ablations on learning rate vs. α] Table or figure reporting the ablation on learning-rate scaling versus α scaling: the controls used to demonstrate that LR adjustments alone cannot replicate the gains must be detailed, including whether equivalent effective step sizes were matched and whether the same rank settings were held fixed.
minor comments (2)
- [abstract] The abstract states the square-root law has an 'unexpectedly large coefficient' but does not report the numerical value or confidence interval; this should be added for reproducibility.
- [theoretical framework] Notation for the Signal-Drift quantities (signal, drift ratio) should be introduced with explicit equations before being used in the three findings.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to clarify the theoretical and empirical contributions of our work. We address each major point below.
read point-by-point responses
-
Referee: [section presenting the square-root law and its coefficient] The section deriving the square-root law for optimal α (the characterization with an unexpectedly large coefficient) appears post-hoc fitted to the reported experiments rather than derived from the Signal-Drift framework; this creates circularity between the claimed law and the data used to discover it. A pre-specified functional form or explicit derivation from the signal/drift definitions would be required to support the claim that existing rank-tied heuristics are insufficiently scaled.
Authors: The square-root functional form is derived directly from the Signal-Drift framework by balancing the signal amplification term (linear in α) against the bounded drift ratio (independent of α due to spectral suppression), yielding α* ∝ √r with the coefficient determined by the explicit constants in the drift bound. The large coefficient is a prediction of the framework rather than a fit. To remove any ambiguity, we will insert a dedicated derivation subsection that starts from the signal and drift definitions, states the functional form a priori, and then reports the empirical coefficient as validation. revision: partial
-
Referee: [Signal-Drift framework section (theoretical analysis)] The central claim that α produces gains irreducible to learning-rate scaling rests on the Signal-Drift framework correctly separating signal amplification from drift increase. The definitions of signal and drift, and the quantitative argument that α outperforms LR adjustments, must be shown explicitly; without these, the non-replicability result cannot be verified.
Authors: We will expand the Signal-Drift section with explicit definitions: signal as the component of the update aligned with task-relevant singular vectors, and drift as the norm of the update in the orthogonal complement. We will add the step-by-step argument showing that α scales only the signal term while the drift ratio remains invariant, together with the direct comparison proving that equivalent learning-rate increases cannot replicate the same signal-to-drift improvement. revision: yes
-
Referee: [experimental ablations on learning rate vs. α] Table or figure reporting the ablation on learning-rate scaling versus α scaling: the controls used to demonstrate that LR adjustments alone cannot replicate the gains must be detailed, including whether equivalent effective step sizes were matched and whether the same rank settings were held fixed.
Authors: We will add a dedicated ablation table that fixes rank across all runs, matches effective step size by scaling the learning rate inversely with α, and reports both final performance and convergence curves. The table will explicitly document these controls and demonstrate that LR scaling alone fails to close the optimization gap. revision: yes
Circularity Check
Square-root law for optimal α is fitted to the reported experiments and presented as a discovery
specific steps
-
fitted input called prediction
[abstract (third finding)]
"Third, the optimal scaling factor follows a sublinear relationship with the rank, well characterized by a square-root law with an unexpectedly large coefficient, revealing the insufficient scaling of existing rank-tied heuristics."
The square-root law is obtained by fitting to the observed optimal α values across ranks in the experiments; presenting the fitted functional form as an independent 'finding' or 'uncover[ed]' mechanism makes the characterization equivalent to the input data by construction.
full rationale
The paper's central empirical claim (optimal scaling factor follows a square-root law with large coefficient) reduces to a post-hoc fit on the same experimental data used to identify the optimum. This matches the fitted_input_called_prediction pattern. The Signal-Drift framework and dominance claim rest on the same empirical tasks without external validation or parameter-free derivation, but the derivation chain is otherwise self-contained against the stated assumptions. No self-citation load-bearing or self-definitional steps are evident from the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- coefficient in square-root law for optimal alpha
axioms (1)
- domain assumption Signal-Drift framework accurately captures LoRA optimization dynamics
Reference graph
Works this paper leans on
-
[1]
Improving language understanding by generative pre-training , author=
-
[2]
ICCV , year=
Unsupervised multi-task feature learning on point clouds , author=. ICCV , year=
-
[3]
NeurIPS , year=
Language models are few-shot learners , author=. NeurIPS , year=
-
[4]
arXiv preprint arXiv:2303.08774 , year=
GPT-4 Technical Report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[5]
arXiv preprint arXiv:2309.16609 , year=
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
-
[6]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[7]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[8]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[9]
ACL , year=
Parameter-Efficient Transfer Learning with Diff Pruning , author=. ACL , year=
-
[10]
ICLR , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. ICLR , year=
-
[11]
EMNLP , year=
The Power of Scale for Parameter-Efficient Prompt Tuning , author=. EMNLP , year=
-
[12]
ICLR , year=
Towards a Unified View of Parameter-Efficient Transfer Learning , author=. ICLR , year=
-
[13]
NeurIPS Workshop , year=
KronA: Parameter Efficient Tuning with Kronecker Adapter , author=. NeurIPS Workshop , year=
-
[14]
arXiv preprint arXiv:2501.13787 , year=
Parameter-Efficient Fine-Tuning for Foundation Models , author=. arXiv preprint arXiv:2501.13787 , year=
-
[15]
NeurIPS Workshop , year=
SLoRA: Federated parameter efficient fine-tuning of language models , author=. NeurIPS Workshop , year=
-
[16]
arXiv preprint arXiv:2404.18848 , year =
Yuxuan Yan and Shunpu Tang and Zhiguo Shi and Qianqian Yang , title =. arXiv preprint arXiv:2404.18848 , year =
-
[17]
TMLR , year=
Lora learns less and forgets less , author=. TMLR , year=
-
[18]
NeurIPS , year=
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning , author=. NeurIPS , year=
-
[19]
Nature Machine Intelligence , year=
Parameter-efficient fine-tuning of large-scale pre-trained language models , author=. Nature Machine Intelligence , year=
-
[20]
AISTATS , year=
Understanding the learning dynamics of lora: A gradient flow perspective on low-rank adaptation in matrix factorization , author=. AISTATS , year=
-
[21]
arXiv preprint arXiv:2304.08109 , year=
A comparative study between full-parameter and lora-based fine-tuning on chinese instruction data for instruction following large language model , author=. arXiv preprint arXiv:2304.08109 , year=
-
[22]
arXiv preprint arXiv:2405.00732 , year=
Lora land: 310 fine-tuned llms that rival gpt-4, a technical report , author=. arXiv preprint arXiv:2405.00732 , year=
-
[23]
arXiv preprint arXiv:2304.14178 , year=
mplug-owl: Modularization empowers large language models with multimodality , author=. arXiv preprint arXiv:2304.14178 , year=
-
[24]
ICLR , year=
Animatediff: Animate your personalized text-to-image diffusion models without specific tuning , author=. ICLR , year=
-
[25]
arXiv preprint arXiv:2311.15127 , year=
Stable video diffusion: Scaling latent video diffusion models to large datasets , author=. arXiv preprint arXiv:2311.15127 , year=
-
[26]
CVPR , year=
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation , author=. CVPR , year=
-
[27]
ICLR , year=
Fedpara: Low-rank hadamard product for communication-efficient federated learning , author=. ICLR , year=
-
[28]
arXiv preprint arXiv:2309.02411 , year=
Delta-LoRA: Fine-Tuning High-Rank Parameters with the Delta of Low-Rank Matrices , author=. arXiv preprint arXiv:2309.02411 , year=
-
[29]
ICML , year=
Parameter-Efficient Fine-Tuning with Discrete Fourier Transform , author=. ICML , year=
-
[30]
arXiv preprint arXiv:2405.12130 , year=
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning , author=. arXiv preprint arXiv:2405.12130 , year=
-
[31]
ICLR , year=
ReLoRA: High-Rank Training Through Low-Rank Updates , author=. ICLR , year=
-
[32]
ICML , year=
Wenhan Xia and Chengwei Qin and Elad Hazan , title =. ICML , year=
-
[33]
arXiv preprint arXiv.2402.16141 , year =
Xiangdi Meng and Damai Dai and Weiyao Luo and Zhe Yang and Shaoxiang Wu and Xiaochen Wang and Peiyi Wang and Qingxiu Dong and Liang Chen and Zhifang Sui , title =. arXiv preprint arXiv.2402.16141 , year =
-
[34]
ICLR , year=
On the Crucial Role of Initialization for Matrix Factorization , author=. ICLR , year=
-
[35]
ICLR , year=
The expressive power of low-rank adaptation , author=. ICLR , year=
-
[36]
ICLR , year=
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning , author=. ICLR , year=
-
[37]
EMNLP , year=
Sparse Low-rank Adaptation of Pre-trained Language Models , author=. EMNLP , year=
-
[38]
arXiv preprint arXiv:2312.03732 , year=
A rank stabilization scaling factor for fine-tuning with lora , author=. arXiv preprint arXiv:2312.03732 , year=
-
[39]
ICML , year=
LoRA+: Efficient Low Rank Adaptation of Large Models , author=. ICML , year=
-
[40]
ICML , year=
Asymmetry in low-rank adapters of foundation models , author=. ICML , year=
-
[41]
arXiv preprint arXiv:2406.08447 , booktitle=
The Impact of Initialization on LoRA Finetuning Dynamics , author=. arXiv preprint arXiv:2406.08447 , booktitle=
-
[42]
ICML , year=
Riemannian Preconditioned LoRA for Fine-Tuning Foundation Models , author=. ICML , year=
-
[43]
NeurIPS , year=
Pissa: Principal singular values and singular vectors adaptation of large language models , author=. NeurIPS , year=
-
[44]
NAACL , year=
MiLoRA: Harnessing Minor Singular Components for Parameter-Efficient LLM Finetuning , author=. NAACL , year=
-
[45]
arXiv preprint arXiv:2406.01775 , year=
OLoRA: Orthonormal Low-Rank Adaptation of Large Language Models , author=. arXiv preprint arXiv:2406.01775 , year=
-
[46]
NeurIPS , year=
CorDA: Context-Oriented Decomposition Adaptation of Large Language Models , author=. NeurIPS , year=
-
[47]
NeurIPS , year=
Lora-ga: Low-rank adaptation with gradient approximation , author=. NeurIPS , year=
-
[48]
ICLR , year=
Vera: Vector-based random matrix adaptation , author=. ICLR , year=
-
[49]
NeurIPS , year=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. NeurIPS , year=
-
[50]
PEFT: state-of-the-art parameter-efficient fine-tuning methods , author=
-
[51]
EMNLP , year=
Transformers: State-of-the-Art Natural Language Processing. EMNLP , year=
-
[52]
Frontiers of Computer Science , year=
A survey on lora of large language models , author=. Frontiers of Computer Science , year=
-
[53]
ICCV , year=
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification , author=. ICCV , year=
-
[54]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[55]
CVPR , year=
Improved baselines with visual instruction tuning , author=. CVPR , year=
-
[56]
KDD , year=
Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x , author=. KDD , year=
-
[57]
2024 , url=
Black Forest Labs , title=. 2024 , url=
2024
-
[58]
ICLR , year=
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing , author=. ICLR , year=
-
[59]
ICLR , year=
LoRA-Pro: Are Low-Rank Adapters Properly Optimized? , author=. ICLR , year=
-
[60]
ICLR , year=
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models , author=. ICLR , year=
-
[61]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[62]
ACL Findings , year=
OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement , author=. ACL Findings , year=
-
[63]
arXiv preprint arXiv:2108.07732 , year=
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[64]
LLM -Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
Hu, Zhiqiang and Wang, Lei and Lan, Yihuai and Xu, Wanyu and Lim, Ee-Peng and Bing, Lidong and Xu, Xing and Poria, Soujanya and Lee, Roy. LLM -Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models. EMNLP. 2023
2023
-
[65]
EMNLP Workshop , year=
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding , author=. EMNLP Workshop , year=
-
[66]
ICML , year=
Learning transferable visual models from natural language supervision , author=. ICML , year=
-
[67]
NeurIPS , year=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. NeurIPS , year=
-
[68]
ECCV , year=
Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images , author=. ECCV , year=
-
[69]
arXiv preprint arXiv:2501.00365 , year=
Low-Rank Adaptation for Foundation Models: A Comprehensive Review , author=. arXiv preprint arXiv:2501.00365 , year=
-
[70]
ACL , year =
Pengjie Ren and Chengshun Shi and Shiguang Wu and Mengqi Zhang and Zhaochun Ren and Maarten de Rijke and Zhumin Chen and Jiahuan Pei , title =. ACL , year =
-
[71]
EMNLP Findings , year=
LoRAN: Improved Low-Rank Adaptation by a Non-Linear Transformation , author=. EMNLP Findings , year=
-
[72]
arXiv preprint arXiv:2410.01870 , year=
NEAT: Nonlinear Parameter-efficient Adaptation of Pre-trained Models , author=. arXiv preprint arXiv:2410.01870 , year=
-
[73]
ICLR , year =
Yeming Wen and Swarat Chaudhuri , title =. ICLR , year =
-
[74]
arXiv preprint arXiv:2308.03303 , year=
Lora-fa: Memory-efficient low-rank adaptation for large language models fine-tuning , author=. arXiv preprint arXiv:2308.03303 , year=
-
[75]
arXiv preprint arXiv:2405.17604 , year=
LoRA-XS: Low-Rank Adaptation with Extremely Small Number of Parameters , author=. arXiv preprint arXiv:2405.17604 , year=
-
[76]
ICLR , year =
Loftq: Lora-fine-tuning-aware quantization for large language models , author=. ICLR , year =
-
[77]
ICML , year=
Dora: Weight-decomposed low-rank adaptation , author=. ICML , year=
-
[78]
AISTATS , year=
Understanding the difficulty of training deep feedforward neural networks , author=. AISTATS , year=
-
[79]
arXiv preprint arXiv:2410.07170 , year=
One initialization to rule them all: Fine-tuning via explained variance adaptation , author=. arXiv preprint arXiv:2410.07170 , year=
-
[80]
arXiv preprint arXiv:2502.01235 , year=
One-step full gradient suffices for low-rank fine-tuning, provably and efficiently , author=. arXiv preprint arXiv:2502.01235 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.