MAMVI: 3D Test-Time Adaptation via Masked Multi-View Point Clouds
Pith reviewed 2026-06-27 07:34 UTC · model grok-4.3
The pith
MAMVI replaces sequential multi-view optimization with a single backward pass on aggregated masked point cloud losses for test-time adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
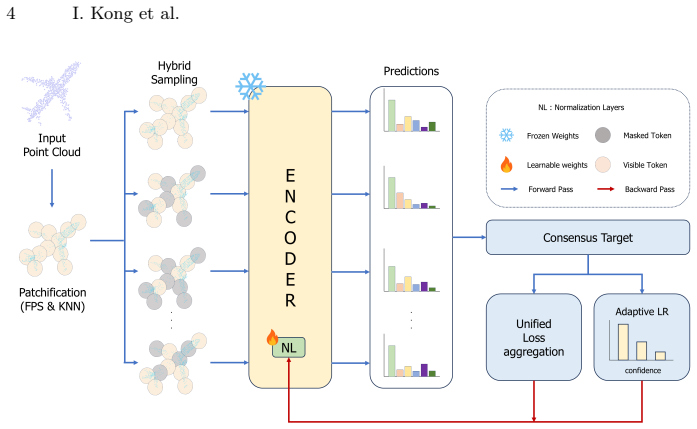
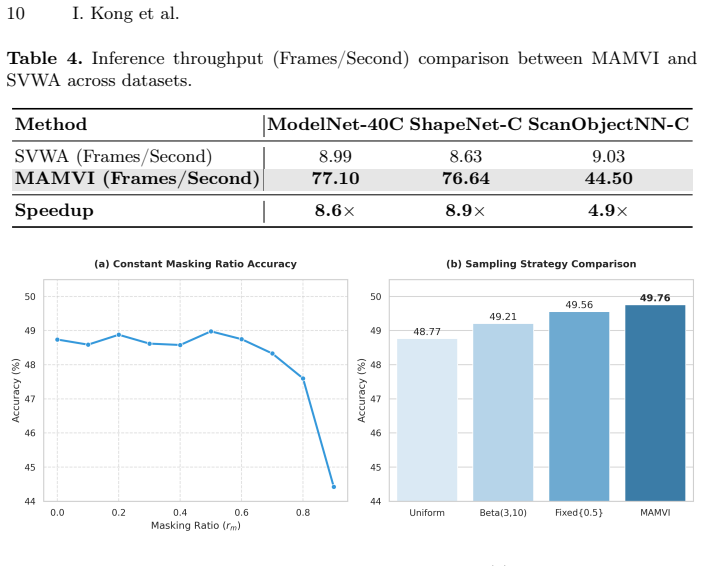
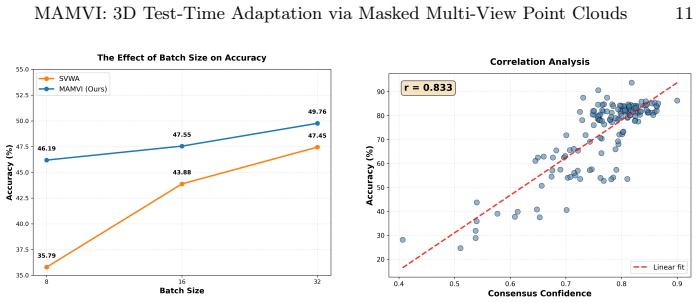
MAMVI performs test-time adaptation by generating a hybrid-masked multi-view set of point clouds, summing the losses across those views, and executing one backward pass to update the model, augmented by a per-sample adaptive learning rate based on prediction confidence. This single-step process replaces the sequential optimization used in prior multi-view TTA, yielding state-of-the-art accuracy on ShapeNet-C and ScanObjectNN-C, competitive results on ModelNet-40C, and 4.9-8.9 times faster inference.
What carries the argument
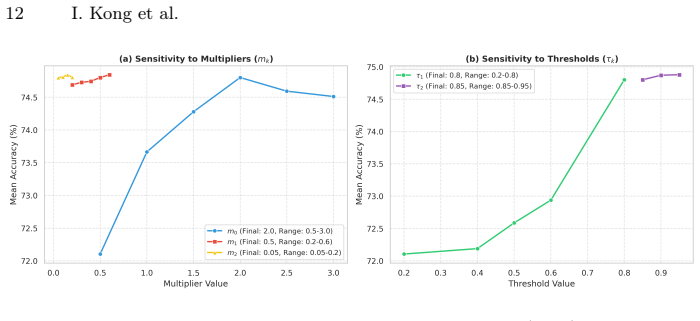
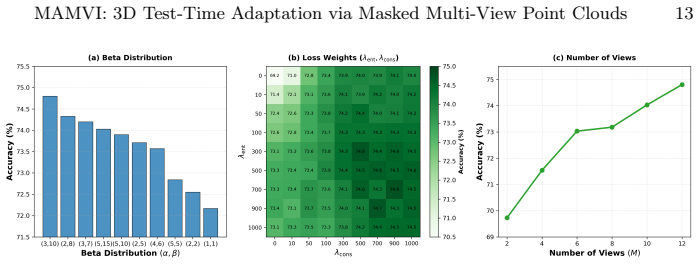
hybrid masking strategy that combines fixed ratios for stability with Beta-distributed sampling for diversity, enabling loss aggregation across views for a single backward pass
If this is right
- Delivers state-of-the-art accuracy on ShapeNet-C and ScanObjectNN-C corruption benchmarks.
- Remains competitive with prior methods on ModelNet-40C while using far less computation per sample.
- Enables real-time test-time adaptation because inference speed improves by a factor of 4.9 to 8.9.
- The confidence-based learning rate dynamically scales adaptation strength per input.
Where Pith is reading between the lines
- The single-pass design could be combined with streaming sensor data to support continuous adaptation in robotics without buffering multiple sequential steps.
- Hybrid masking might transfer to other modalities such as multi-view images or video frames where sequential optimization is currently a bottleneck.
- If the Beta sampling component is removed, accuracy might drop on high-variability corruptions, providing a direct ablation test of the diversity term.
Load-bearing premise
Aggregating losses from a hybrid-masked multi-view set and running one backward pass produces adaptation performance comparable to or better than sequential per-view optimization without causing instability or under-adaptation.
What would settle it
Measure classification accuracy and per-sample wall-clock time when running MAMVI versus a sequential multi-view TTA baseline on the same set of corrupted point clouds from ShapeNet-C.
Figures
read the original abstract
3D point cloud models suffer significant performance degradation under distribution shifts caused by sensor noise, occlusions, and environmental changes. Test-time adaptation (TTA) has emerged as a practical paradigm for mitigating this issue during inference. Recently, leveraging multi-view augmentation has shown promise in improving 3D TTA performance. However, existing multi-view approaches are often constrained by sequential optimization that treats each view independently. This sequential optimization leads to substantial inference latency due to repetitive optimization steps, making real-time adaptation impractical. To address this, we propose Masked Multi-View Test-Time Adaptation (MAMVI), which replaces sequential optimization with a unified single-step adaptation. Specifically, MAMVI utilizes a hybrid masking strategy that combines fixed ratios for stability with Beta-distributed sampling for diversity. By aggregating losses across multiple views, MAMVI performs adaptation through a single backward pass based on multi-view consensus. Additionally, a confidence-based adaptive learning rate is used to dynamically adjust the adaptation intensity for each sample. Extensive experiments on ModelNet-40C, ShapeNet-C, and ScanObjectNN-C demonstrate that MAMVI achieves state-of-the-art accuracy on ShapeNet-C and ScanObjectNN-C. Moreover, it remains competitive on ModelNet-40C while delivering 4.9-8.9 times faster inference, making it highly suitable for real-time applications. Our code is available at https://github.com/Inseok-kong/MAMVI
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MAMVI for 3D point cloud test-time adaptation under distribution shifts. It replaces sequential per-view optimization with a hybrid masking strategy (fixed ratios plus Beta-distributed sampling) on multi-view point clouds, aggregates losses for a single backward pass, and uses a confidence-based adaptive learning rate. The method claims state-of-the-art accuracy on ShapeNet-C and ScanObjectNN-C, competitiveness on ModelNet-40C, and 4.9-8.9x faster inference than prior multi-view TTA approaches, with code released.
Significance. If the single-pass aggregation claim holds with supporting evidence, the work could enable practical real-time 3D TTA by addressing latency bottlenecks in multi-view methods. The public code release is a clear strength for reproducibility and further validation.
major comments (2)
- [Method (hybrid masking and single-step adaptation)] The central claim rests on loss aggregation across the hybrid-masked multi-view set enabling a single backward pass to match or exceed sequential per-view optimization. However, no equation is supplied for the aggregated loss (mean, sum, or weighted), no gradient-norm analysis across views is provided, and the interaction with the confidence-based adaptive LR is unspecified, leaving the risk of diluted gradients or instability unaddressed.
- [Experiments] No ablation isolating the single-pass aggregation effect from the masking strategy itself is reported. This is load-bearing because the speedup and performance claims require demonstrating that aggregation does not cause under-adaptation on harder shifts, yet the experiments section supplies only overall benchmark wins without such controls or error analysis.
minor comments (2)
- [Abstract] The abstract states benchmark wins and speedups but contains no quantitative values, table references, or baseline details, which reduces immediate assessability even though the full paper presumably contains them.
- [Method] Notation for the Beta distribution parameters and fixed masking ratios should be introduced with explicit symbols and ranges in the method description for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will incorporate clarifications and additional analysis in a revised manuscript.
read point-by-point responses
-
Referee: [Method (hybrid masking and single-step adaptation)] The central claim rests on loss aggregation across the hybrid-masked multi-view set enabling a single backward pass to match or exceed sequential per-view optimization. However, no equation is supplied for the aggregated loss (mean, sum, or weighted), no gradient-norm analysis across views is provided, and the interaction with the confidence-based adaptive LR is unspecified, leaving the risk of diluted gradients or instability unaddressed.
Authors: We agree that an explicit equation and supporting analysis would strengthen the presentation. In the revision we will add the precise formulation of the aggregated loss (the mean of per-view losses after hybrid masking), include a short gradient-norm comparison across views demonstrating that multi-view consensus does not dilute gradients relative to sequential optimization, and clarify the interaction with the confidence-adaptive learning rate by showing how per-sample modulates the effective step size on the aggregated gradient. These additions will directly address concerns about potential instability. revision: yes
-
Referee: [Experiments] No ablation isolating the single-pass aggregation effect from the masking strategy itself is reported. This is load-bearing because the speedup and performance claims require demonstrating that aggregation does not cause under-adaptation on harder shifts, yet the experiments section supplies only overall benchmark wins without such controls or error analysis.
Authors: We acknowledge that an ablation isolating the single-pass aggregation is necessary to substantiate the claims. We will add this controlled experiment in the revised version, comparing (i) sequential per-view optimization, (ii) hybrid masking without aggregation, and (iii) full MAMVI, evaluated on the harder shifts in ShapeNet-C and ScanObjectNN-C, with error bars across multiple runs. This will show that aggregation preserves or improves accuracy without under-adaptation while delivering the reported speed-up. revision: yes
Circularity Check
No circularity: empirical method with independent experimental validation
full rationale
The paper introduces MAMVI as a practical TTA algorithm that aggregates hybrid-masked multi-view losses for single-pass adaptation plus a confidence-based LR schedule. All reported gains (SOTA on ShapeNet-C/ScanObjectNN-C, speedups) are presented as outcomes of experiments on fixed benchmarks rather than any first-principles derivation, fitted parameter renamed as prediction, or self-citation chain. No equations appear that define a quantity in terms of itself or that reduce the adaptation result to the input data by construction; the central design choices (mask ratios, Beta sampling, loss aggregation) are motivated by engineering considerations and validated externally. The derivation chain is therefore self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
free parameters (3)
- fixed masking ratios
- Beta distribution parameters
- confidence scaling factor for learning rate
axioms (2)
- domain assumption Loss aggregation across hybrid-masked views yields a reliable adaptation gradient
- domain assumption Beta sampling adds beneficial diversity without destabilizing single-step updates
Reference graph
Works this paper leans on
- [1]
-
[2]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Bahri, A., Yazdanpanah, M., Noori, M., Dastani, S., Cheraghalikhani, M., Os- owiechi, D., Beizaee, F., Hakim, G.A.V., Ayed, I.B., Desrosiers, C.: Test-time adap- tation in point clouds: Leveraging sampling variation with weight averaging. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 266–275. IEEE (2025)
2025
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition
Boudiaf, M., Mueller, R., Ben Ayed, I., Bertinetto, L.: Parameter-free online test- time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition. pp. 8344–8353 (2022)
2022
-
[4]
ShapeNet: An Information-Rich 3D Model Repository
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., et al.: Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Dastmalchi, H., An, A., Cheraghian, A., Rahman, S., Ramasinghe, S.: Test-time adaptation of 3d point clouds via denoising diffusion models. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 1566–1576. IEEE (2025)
2025
-
[6]
In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidi- rectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). pp. 4171–4186 (2019)
2019
-
[7]
In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K
Gandelsman, Y., Sun, Y., Chen, X., Efros, A.A.: Test-time training with masked autoencoders. In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neural Information Processing Systems (2022)
2022
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gao, J., Zhang, J., Liu, X., Darrell, T., Shelhamer, E., Wang, D.: Back to the source: Diffusion-driven adaptation to test-time corruption. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11786– 11796 (2023)
2023
-
[9]
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalablevisionlearners.In:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition (CVPR). pp. 16000–16009 (2022)
2022
-
[10]
Advances in Neural Information Processing Systems34, 2427–2440 (2021)
Iwasawa,Y.,Matsuo,Y.:Test-timeclassifieradjustmentmoduleformodel-agnostic domain generalization. Advances in Neural Information Processing Systems34, 2427–2440 (2021)
2021
-
[11]
In: Workshop on challenges in representation learning, ICML (2013)
Lee, D.H., et al.: Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In: Workshop on challenges in representation learning, ICML (2013)
2013
-
[12]
In: International conference on machine learning
Liang, J., Hu, D., Feng, J.: Do we really need to access the source data? source hy- pothesis transfer for unsupervised domain adaptation. In: International conference on machine learning. pp. 6028–6039. PMLR (2020)
2020
-
[13]
Liu, Y., Kothari, P., Van Delft, B., Bellot-Gurlet, B., Mordan, T., Alahi, A.: Ttt++: When does self-supervised test-time training fail or thrive? Advances in Neural Information Processing Systems34, 21808–21820 (2021)
2021
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Mirza, M.J., Micorek, J., Possegger, H., Bischof, H.: The norm must go on: Dy- namic unsupervised domain adaptation by normalization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14765– 14775 (2022) MAMVI: 3D Test-Time Adaptation via Masked Multi-View Point Clouds 15
2022
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Mirza, M.J., Shin, I., Lin, W., Schriebl, A., Sun, K., Choe, J., Kozinski, M., Pos- segger, H., Kweon, I.S., Yoon, K.J., et al.: Mate: Masked autoencoders are online 3d test-time learners. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 16709–16718 (2023)
2023
-
[16]
arXiv preprint arXiv:2302.12400 (2023)
Niu, S., Wu, J., Zhang, Y., Wen, Z., Chen, Y., Zhao, P., Tan, M.: Towards sta- ble test-time adaptation in dynamic wild world. arXiv preprint arXiv:2302.12400 (2023)
-
[17]
World Scientific Annual Review of Artificial Intelligence 1, 2440001 (2023)
Pang, Y., Tay, E.H.F., Yuan, L., Chen, Z.: Masked autoencoders for 3d point cloud self-supervised learning. World Scientific Annual Review of Artificial Intelligence 1, 2440001 (2023)
2023
-
[18]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 652–660 (2017)
2017
-
[19]
Advances in neural information processing systems30(2017)
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learn- ing on point sets in a metric space. Advances in neural information processing systems30(2017)
2017
-
[20]
In: European Conference on Com- puter Vision
Shim, H., Kim, C., Yang, E.: Cloudfixer: Test-time adaptation for 3d point clouds via diffusion-guided geometric transformation. In: European Conference on Com- puter Vision. pp. 454–471. Springer (2024)
2024
-
[21]
arXiv preprint arXiv:2201.12296 (2022)
Sun, J., Zhang, Q., Kailkhura, B., Yu, Z., Xiao, C., Mao, Z.M.: Benchmarking ro- bustness of 3d point cloud recognition against common corruptions. arXiv preprint arXiv:2201.12296 (2022)
-
[22]
In: International conference on machine learning
Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A., Hardt, M.: Test-time training with self-supervision for generalization under distribution shifts. In: International conference on machine learning. pp. 9229–9248. PMLR (2020)
2020
-
[23]
In: Proceedings of the IEEE/CVF international conference on computer vi- sion
Uy, M.A., Pham, Q.H., Hua, B.S., Nguyen, T., Yeung, S.K.: Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In: Proceedings of the IEEE/CVF international conference on computer vi- sion. pp. 1588–1597 (2019)
2019
-
[24]
Tent: Fully Test-time Adaptation by Entropy Minimization
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., Darrell, T.: Tent: Fully test-time adaptation by entropy minimization. arXiv preprint arXiv:2006.10726 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, Y., Cheraghian, A., Hayder, Z., Hong, J., Ramasinghe, S., Rahman, S., Ahmedt-Aristizabal, D., Li, X., Petersson, L., Harandi, M.: Backpropagation-free network for 3d test-time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23231–23241 (2024)
2024
-
[26]
ACM Transactions on Graphics (tog)38(5), 1–12 (2019)
Wang, Y., Sun, Y., Liu, Z., Sarma, S.E., Bronstein, M.M., Solomon, J.M.: Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics (tog)38(5), 1–12 (2019)
2019
-
[27]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yazdanpanah, M., Bahri, A., Noori, M., Dastani, S., Hakim, G.A.V., Osowiechi, D., Ben Ayed, I., Desrosiers, C.: Purge-gate: Backpropagation-free test-time adap- tation for point clouds classification via token purging. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27640–27649 (2025)
2025
-
[28]
Advances in neural information processing systems35, 38629–38642 (2022)
Zhang, M., Levine, S., Finn, C.: Memo: Test time robustness via adaptation and augmentation. Advances in neural information processing systems35, 38629–38642 (2022)
2022
-
[29]
Advances in neural information processing systems35, 27061–27074 (2022)
Zhang, R., Guo, Z., Gao, P., Fang, R., Zhao, B., Wang, D., Qiao, Y., Li, H.: Point- m2ae: multi-scale masked autoencoders for hierarchical point cloud pre-training. Advances in neural information processing systems35, 27061–27074 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.