Camera and LiDAR BEV Fusion for Cooperative 3D Object Detection on TUMTraf V2X
Pith reviewed 2026-06-27 07:27 UTC · model grok-4.3
The pith
Camera and LiDAR BEV fusion for cooperative 3D detection reaches 0.85 mAP on TUMTraf V2X test split.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A BEV fusion model combining roadside cameras and infrastructure-plus-vehicle LiDAR achieves 0.85 3D mAP on the public test split; oversampling the 44 overlapping frames raises the score to 0.89 while replacing predictions on those frames with ground truth raises it to 0.99.
What carries the argument
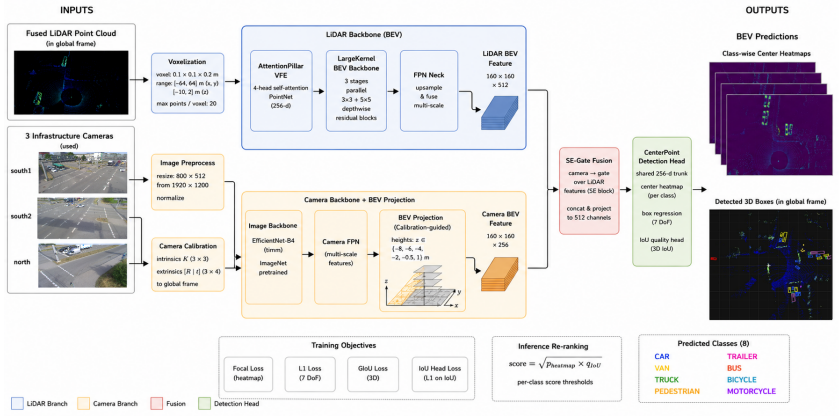
Bird's-eye-view fusion of multi-view camera features and a merged point cloud, followed by a CenterPoint detection head with generalized IoU regression and IoU-based re-ranking.
If this is right
- The fusion approach can be applied to roadside cooperative perception tasks.
- Higher scores are obtained by including more overlapping frames in training.
- Near-perfect scores result from using ground truth on overlapping test frames.
Where Pith is reading between the lines
- The 0.85 mAP likely overestimates generalization performance due to data leakage.
- V2X benchmarks require stricter train-test separation to avoid such overlaps.
- Methods should be evaluated on non-overlapping test subsets for fair comparison.
Load-bearing premise
The public test split contains frames that do not appear in the train or validation splits.
What would settle it
Running the model on a test set consisting only of the 6 non-overlapping frames would reveal the performance without leakage.
Figures


read the original abstract
We describe a Camera and LiDAR fusion detector developed for the TUMTraf V2X cooperative 3D object detection track of the DriveX 2026 challenge. The detector fuses three roadside cameras with a fused infrastructure-plus-vehicle point cloud in a shared bird's-eye-view space and predicts boxes through a CenterPoint-style head with a generalized IoU regression loss and an IoU quality re-ranking head. Trained on the provided train and validation splits, the model reaches a 3D mAP of 0.85 on the public Codabench test split. While iterating on the system, we observed that 44 of the 50 test frames are also present in the released train (40) and validation (4) splits with their labels. We therefore conducted two additional studies to quantify how this overlap affects the final score: (1) a finetuning run that oversamples the 44 overlapping frames, reaching 0.89 mAP, and (2) a post-processing run that replaces predictions on those frames with the released ground truth, reaching 0.99 mAP (uploaded to our Codabench account for testing but not published on the leaderboard). All three configurations and their per-class results are reported.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a Camera and LiDAR BEV fusion detector for the TUMTraf V2X cooperative 3D object detection track. It fuses three roadside cameras with a combined infrastructure-plus-vehicle point cloud in shared BEV space and predicts boxes via a CenterPoint-style head using generalized IoU regression loss and an IoU quality re-ranking head. Trained on the released train and validation splits, the model reports 0.85 3D mAP on the public Codabench test split. The authors disclose that 44 of 50 test frames overlap with the train (40) and validation (4) splits and quantify the effect via an oversampling experiment (0.89 mAP) and a ground-truth substitution experiment (0.99 mAP).
Significance. If the empirical results hold, the work supplies a practical baseline for multi-modal cooperative perception and, more importantly, provides transparent quantification of test-set overlap effects through controlled experiments. This disclosure and the accompanying ablation-style runs strengthen the credibility of the reported numbers and offer useful guidance for interpreting leaderboard scores in V2X challenges.
minor comments (2)
- [Abstract] Abstract: the description of the architecture, loss, and head is high-level only; no equations, network dimensions, training hyperparameters, or implementation details are supplied, which prevents independent verification or reproduction of the 0.85 mAP figure.
- The manuscript does not indicate whether the per-class mAP breakdowns or the two controlled experiments are presented in tables or figures; adding such structured results would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of our contributions including the test-set overlap disclosure, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The manuscript reports empirical 3D mAP results obtained by training a BEV fusion detector on the provided train/validation splits and evaluating on the public Codabench test split. It explicitly discloses the 44-frame overlap between test and train/validation data, then quantifies the effect through two controlled experiments (oversampling overlap and GT substitution). No derivation chain, fitted parameter presented as a prediction, self-citation load-bearing premise, or ansatz is present; the reported numbers are direct experimental outcomes rather than quantities defined in terms of the model's own outputs or prior self-referential results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zimmer, G
W. Zimmer, G. A. Wardana, S. Sritharan, X. Zhou, R. Song, and A. C. Knoll,TUMTraf V2X Cooperative Perception Dataset, CVPR 2024
2024
-
[2]
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. Rus, and S. Han,BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation, ICRA 2023
2023
-
[3]
Philion and S
J. Philion and S. Fidler,Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D, ECCV 2020
2020
-
[4]
T. Yin, X. Zhou, and P. Kr¨ ahenb¨ uhl,Center-based 3D Object Detection and Tracking, CVPR 2021
2021
-
[5]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei,ImageNet: A Large-Scale Hierarchical Image Database, CVPR 2009
2009
-
[6]
Wightman,PyTorch Image Models (timm), GitHub repository, 2019
R. Wightman,PyTorch Image Models (timm), GitHub repository, 2019. https://github.com/huggingface/ pytorch-image-models
2019
-
[7]
Zhou and O
Y. Zhou and O. Tuzel,VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection, CVPR 2018
2018
-
[8]
A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom,PointPillars: Fast Encoders for Object Detection from Point Clouds, CVPR 2019
2019
-
[9]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas,PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation, CVPR 2017
2017
-
[10]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin,Attention Is All You Need, NeurIPS 2017
2017
-
[11]
Y. Chen, J. Liu, X. Zhang, X. Qi, and J. Jia,LargeKernel3D: Scaling Up Kernels in 3D Sparse CNNs, CVPR 2023
2023
-
[12]
T.-Y. Lin, P. Doll´ ar, R. Girshick, K. He, B. Hariharan, and S. Belongie,Feature Pyramid Networks for Object Detection, CVPR 2017
2017
-
[13]
Tan and Q
M. Tan and Q. V. Le,EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, ICML 2019
2019
-
[14]
J. Hu, L. Shen, and G. Sun,Squeeze-and-Excitation Networks, CVPR 2018
2018
-
[15]
T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ ar,Focal Loss for Dense Object Detection, ICCV 2017
2017
-
[16]
X. Zhou, D. Wang, and P. Kr¨ ahenb¨ uhl,Objects as Points, arXiv:1904.07850, 2019
Pith/arXiv arXiv 1904
-
[17]
Rezatofighi, N
H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese,Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression, CVPR 2019
2019
-
[18]
Zheng, W
W. Zheng, W. Tang, S. Chen, L. Jiang, and C.-W. Fu,CIA-SSD: Confident IoU-Aware Single-Stage Object Detector from Point Cloud, AAAI 2021
2021
-
[19]
Loshchilov and F
I. Loshchilov and F. Hutter,Decoupled Weight Decay Regularization, ICLR 2019
2019
-
[20]
L. N. Smith and N. Topin,Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates, arXiv:1708.07120, 2017
Pith/arXiv arXiv 2017
-
[21]
Micikevicius, S
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, and H. Wu,Mixed Precision Training, ICLR 2018
2018
-
[22]
B. Zhu, Z. Jiang, X. Zhou, Z. Li, and G. Yu,Class-Balanced Grouping and Sampling for Point Cloud 3D Object Detection, arXiv:1908.09492, 2019
arXiv 1908
-
[23]
Y. Yan, Y. Mao, and B. Li,SECOND: Sparsely Embedded Convolutional Detection, Sensors, 18(10):3337, 2018. 8
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.