Reliability of Probabilistic Emulation of Physical Systems
Pith reviewed 2026-06-27 07:43 UTC · model grok-4.3
The pith
CRPS-trained ensembles of deterministic models deliver more reliable uncertainty estimates than generative models trained in latent space when emulating 2D physical systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
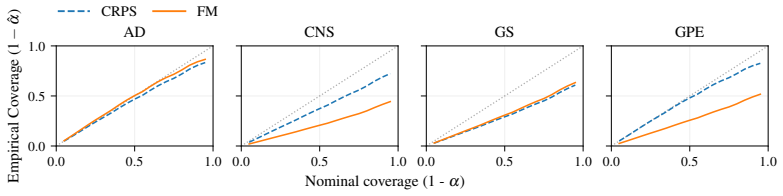
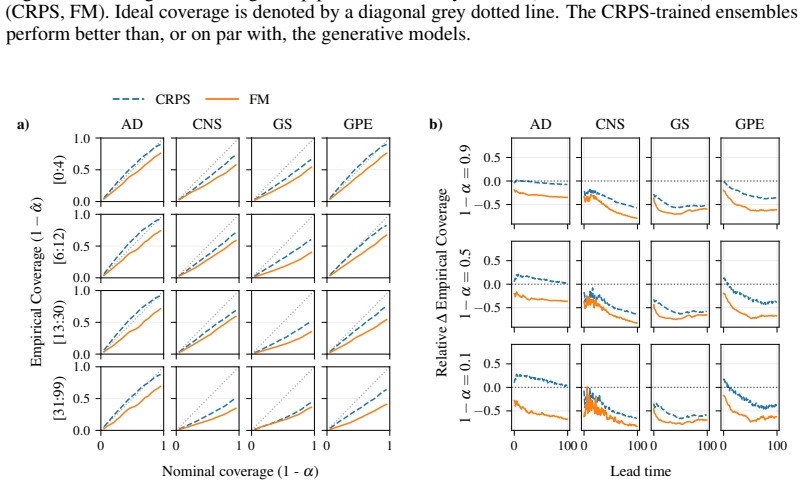
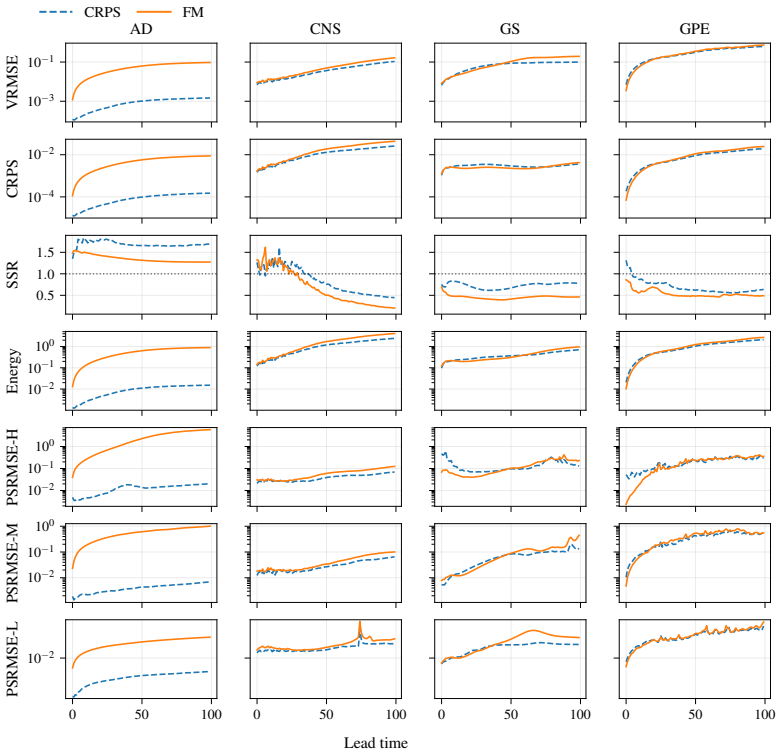
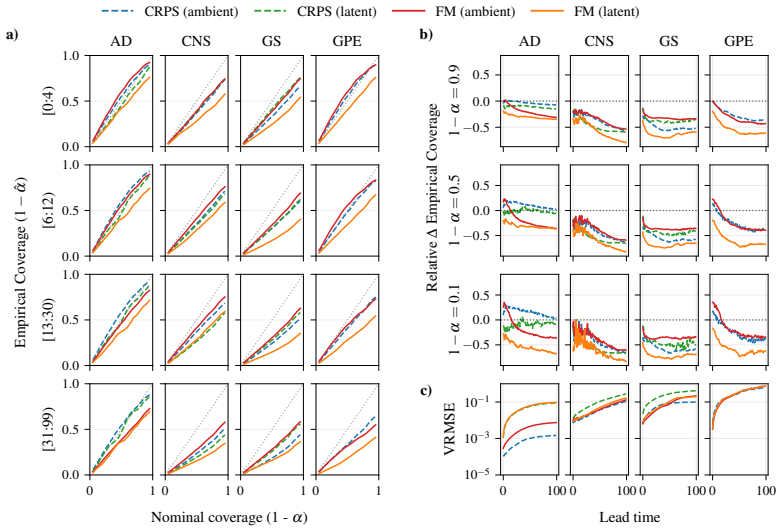
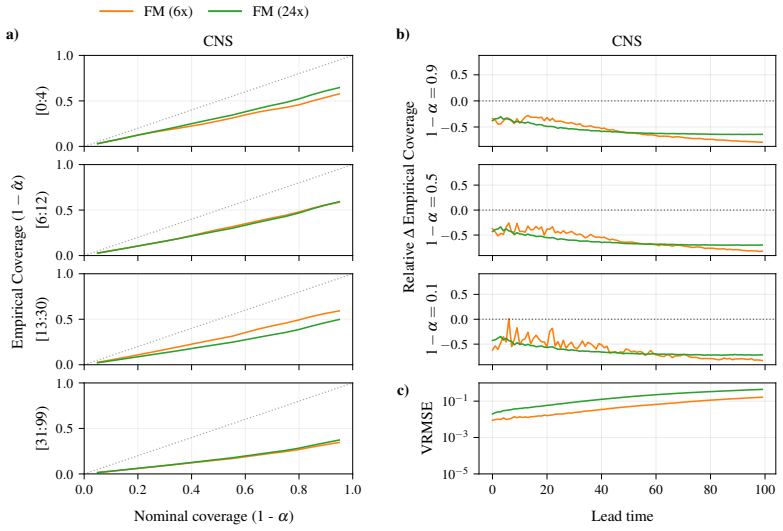
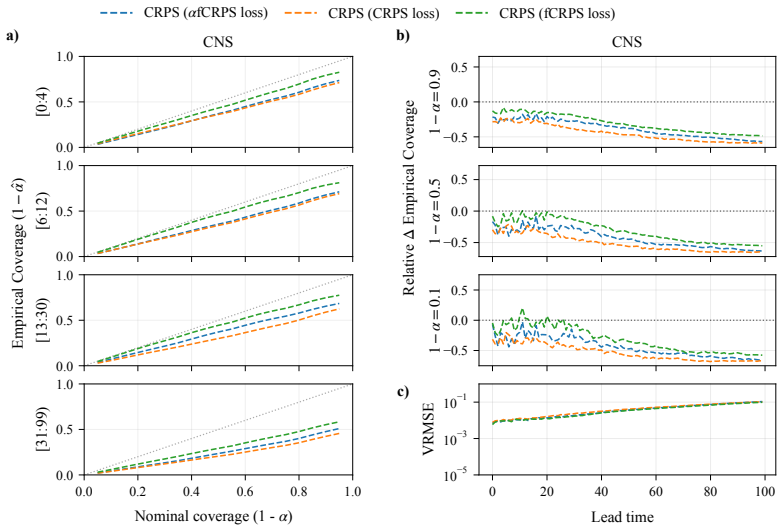
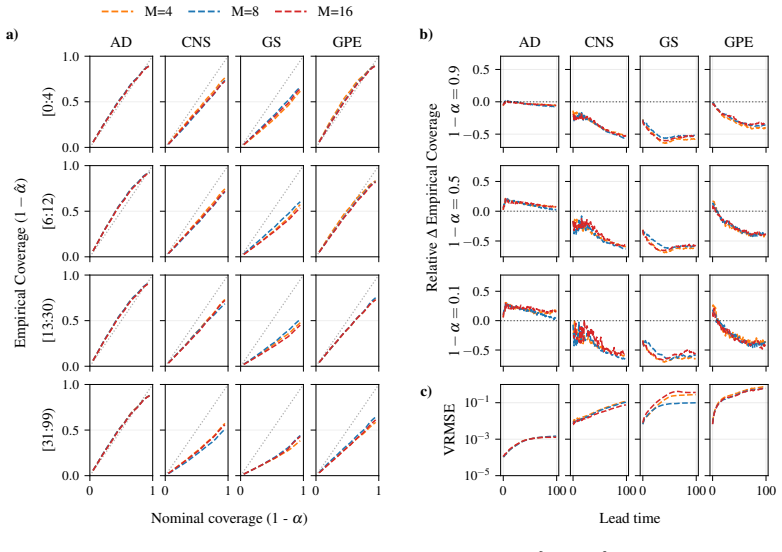
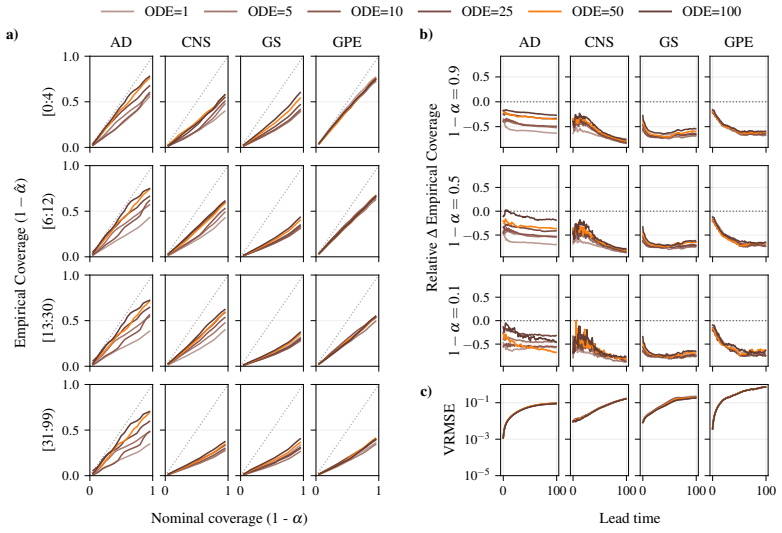
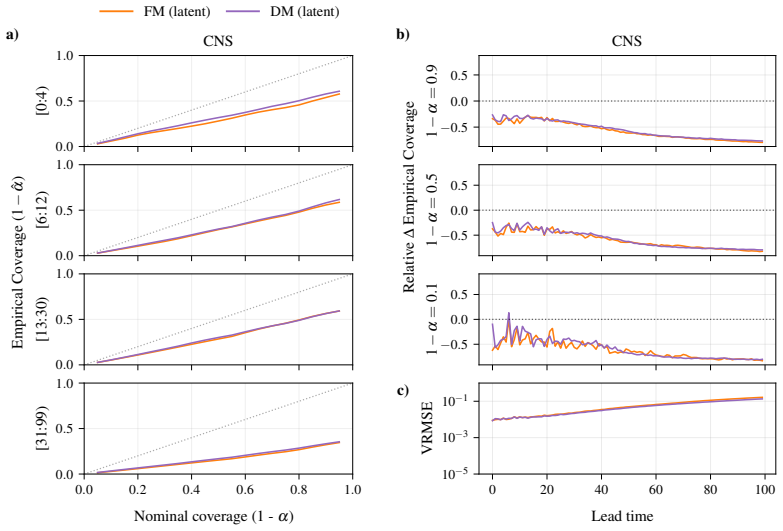
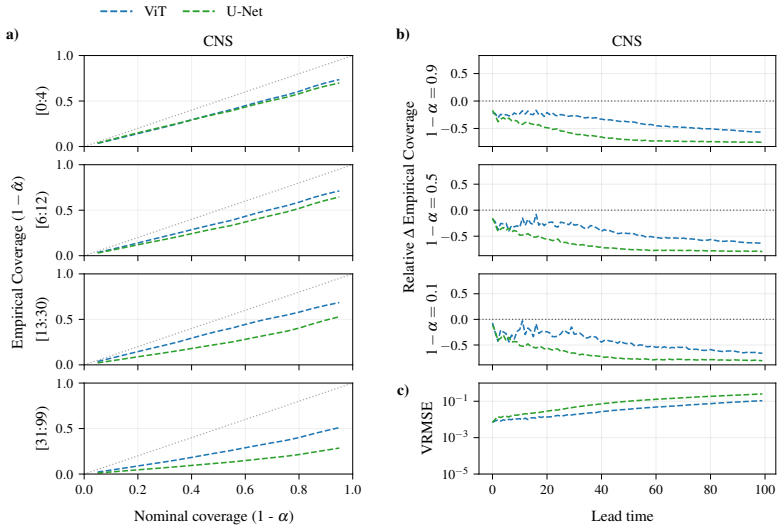
CRPS-trained ensembles typically achieve more reliable uncertainties on both single-step prediction and autoregressive rollouts, demonstrating better coverage than the standard alternative of training generative models in a latent space. Moreover, the CRPS approach offers significantly faster inference. When generative models are trained in ambient rather than a compressed latent space, which is often infeasible for high-dimensional problems, they exhibit comparable coverage to CRPS-trained ensembles, though with substantially larger inference latency. In contrast, when CRPS-trained ensembles are trained in latent space they do not show a marked degradation in coverage with respect to ambien
What carries the argument
Empirical coverage of predictive intervals, measured across matched model sizes and computational budgets on 2D spatiotemporal physical systems, used to compare CRPS-trained ensembles against generative models trained in latent versus ambient space.
If this is right
- CRPS-trained ensembles are the more practical choice when both reliable uncertainty and fast inference are required.
- Training CRPS ensembles in a latent space preserves coverage without the large speed penalty seen in generative models.
- Generative models require ambient-space training to match CRPS coverage, which limits their use on high-dimensional problems.
- Both families of models reach comparable point-prediction accuracy, so the difference lies mainly in uncertainty calibration and speed.
- The released AutoCast and AutoSim packages enable direct replication and extension of the coverage comparisons.
Where Pith is reading between the lines
- The result suggests that explicit scoring-rule training may be more robust to dimensionality reduction than implicit generative training.
- Similar coverage advantages might appear in 3D or time-varying systems if the same matched-budget protocol is followed.
- Practitioners needing real-time probabilistic forecasts could adopt CRPS ensembles first and add generative models only when ambient-space compute is available.
- The finding raises the question of whether other proper scoring rules would produce ensembles with coverage profiles similar to CRPS.
Load-bearing premise
The selected set of 2D spatiotemporal physical systems together with the matched model sizes and computational budgets produces a fair comparison that generalizes beyond the tested cases.
What would settle it
On a held-out physical system or with a different model architecture, generative models trained in latent space achieve equal or better coverage of predictive intervals than CRPS-trained ensembles while using the same compute budget.
Figures

read the original abstract
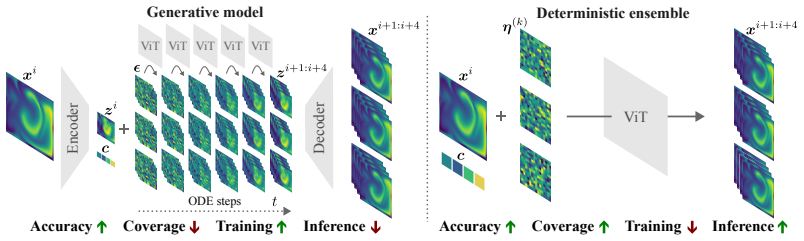
Two dominant approaches have emerged for generating probabilistic forecasts of physical systems: generative models, such as diffusion or flow matching; and ensembles of deterministic models with stochasticity injected, trained using the continuous ranked probability score (CRPS) loss. While both approaches have demonstrated strong predictive accuracy, the reliability of their uncertainties has not been systematically assessed. We address this gap by developing a framework to evaluate both approaches across diverse 2D spatiotemporal physical systems, under matched model size and computational budget. We assess the reliability of probabilistic emulation by inspecting the empirical coverage of predictive intervals, while also considering accuracy and computational efficiency metrics. CRPS-trained ensembles typically achieve more reliable uncertainties on both single-step prediction and autoregressive rollouts, demonstrating better coverage than the standard alternative of training generative models in a latent space. Moreover, the CRPS approach offers significantly faster inference. When generative models are trained in ambient rather than a compressed latent space, which is often infeasible for high-dimensional problems, they exhibit comparable coverage to CRPS-trained ensembles, though with substantially larger inference latency. In contrast, when CRPS-trained ensembles are trained in latent space they do not show a marked degradation in coverage with respect to ambient space. Both generative models and CRPS-trained ensembles demonstrate good predictive accuracy. To facilitate future research and application, we release AutoCast, a modular framework implementing both generative models and CRPS-trained ensembles, alongside AutoSim, a flexible dataset generation package for rapid prototyping.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares two approaches to probabilistic emulation of 2D spatiotemporal physical systems under matched model size and compute budget: (i) generative models (diffusion or flow matching) trained in a compressed latent space and (ii) ensembles of deterministic models trained with the CRPS loss. Using empirical coverage of predictive intervals as the primary reliability metric, together with accuracy and latency, the authors report that CRPS-trained ensembles achieve better coverage on both single-step and autoregressive rollouts and substantially lower inference latency. Ambient-space generative models reach comparable coverage but at much higher cost; CRPS ensembles trained in latent space show little degradation relative to ambient training. Both families attain good predictive accuracy. The work releases the AutoCast framework and AutoSim dataset generator to support reproducibility.
Significance. If the coverage and latency results prove robust, the paper supplies actionable guidance for choosing between generative and CRPS-ensemble methods when reliable uncertainty quantification is required. The explicit release of modular code and a dataset generator is a concrete strength that directly addresses the reproducibility concerns typical of empirical benchmark studies in this area.
minor comments (3)
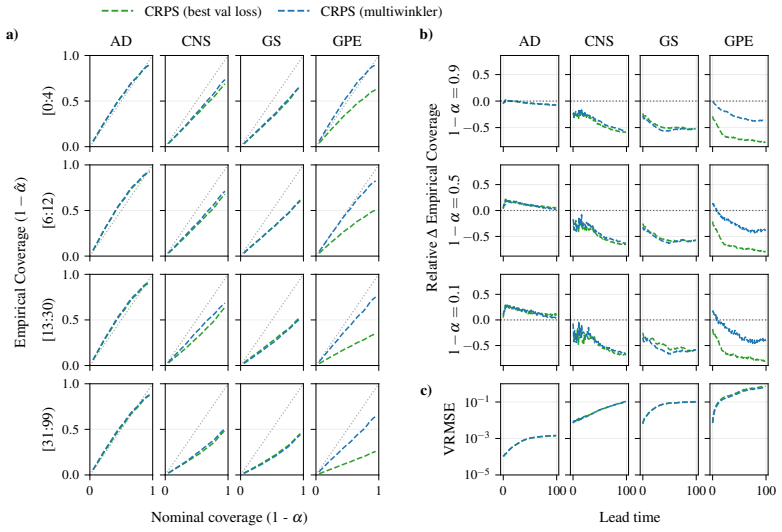
- [§3.2] §3.2: the precise construction of the predictive intervals (quantiles or ensemble spread) used for the coverage calculation should be stated explicitly so that the comparison between generative and CRPS methods is fully reproducible from the text alone.
- [Table 2] Table 2 and Figure 4: the reported coverage percentages would benefit from per-system standard deviations or bootstrap intervals to indicate variability across random seeds and initial conditions.
- [§5.1] §5.1: the statement that CRPS ensembles 'typically' outperform is not accompanied by a count or fraction of systems on which the advantage holds; adding this summary statistic would make the claim more precise.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, accurate summary of our contributions, and recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark study comparing CRPS-trained ensembles against generative models on 2D physical systems. No derivations, uniqueness theorems, or fitted inputs are presented that reduce by construction to author-defined quantities or self-citations. Claims rest on coverage, accuracy, and latency metrics evaluated under matched budgets, with code and datasets released for independent verification. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anastasios N Angelopoulos and Stephen Bates
URL https://arxiv.org/ abs/2506.10772. Anastasios N Angelopoulos and Stephen Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification
-
[2]
URL https://arxiv.org/abs/2107.07511. Anastasios N. Angelopoulos, Rina Foygel Barber, and Stephen Bates. Theoretical foundations of conformal prediction,
-
[3]
Weizhu Bao, Qiang Du, and Yanzhi Zhang
URLhttps://arxiv.org/abs/2411.11824. Weizhu Bao, Qiang Du, and Yanzhi Zhang. Dynamics of rotating Bose–Einstein condensates and its efficient and accurate numerical computation.SIAM Journal on Applied Mathematics, 66(3): 758–786, January
-
[4]
ISSN 1095-712X. doi: 10.1137/050629392. URL http://dx.doi. org/10.1137/050629392. Boris Bonev, Thorsten Kurth, Ankur Mahesh, Mauro Bisson, Jean Kossaifi, Karthik Kashinath, Anima Anandkumar, William D. Collins, Michael S. Pritchard, and Alexander Keller. FourCastNet 3: A geometric approach to probabilistic machine-learning weather forecasting at scale,
-
[5]
Cristiana Diaconu, Miles Cranmer, Richard E
URLhttps://arxiv.org/abs/2507.12144. Cristiana Diaconu, Miles Cranmer, Richard E. Turner, Tanya Marwah, and Payel Mukhopadhyay. Probabilistic retrofitting of learned simulators. InAI&PDE: ICLR 2026 Workshop on AI and Partial Differential Equations,
arXiv 2026
-
[6]
URLhttps://doi.org/10.1198/016214506000001437
doi: 10.1198/016214506000001437. URLhttps://doi.org/10.1198/016214506000001437. Vignesh Gopakumar, Ander Gray, Joel Oskarsson, Lorenzo Zanisi, Daniel Giles, Matt J Kusner, Stanislas Pamela, and Marc Peter Deisenroth. Uncertainty quantification of surrogate models using conformal prediction.Machine Learning: Science and Technology, 7(1):015025, feb
-
[7]
URLhttps://doi.org/10.1088/2632-2153/ae2e7b
doi: 10.1088/2632-2153/ae2e7b. URLhttps://doi.org/10.1088/2632-2153/ae2e7b. Jayesh K Gupta and Johannes Brandstetter. Towards multi-spatiotemporal-scale generalized PDE modeling.Transactions on Machine Learning Research,
-
[8]
Woo Jin Kwon, Joon Hyun Kim, Sang Won Seo, and Y
URL https://proceedings.neurips.cc/paper_files/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf. Woo Jin Kwon, Joon Hyun Kim, Sang Won Seo, and Y . Shin. Observation of von Kármán vortex street in an atomic superfluid gas.Physical Review Letters, 117(24), December
2020
-
[9]
doi: 10.1103/physrevlett.117.245301
ISSN 1079-7114. doi: 10.1103/physrevlett.117.245301. URL http://dx.doi.org/10.1103/ PhysRevLett.117.245301. Simon Lang, Mihai Alexe, Mariana C. A. Clare, Christopher Roberts, Rilwan Adewoyin, Zied Ben Bouallègue, Matthew Chantry, Jesper Dramsch, Peter D. Dueben, Sara Hahner, Pedro Maciel, Ana Prieto-Nemesio, Cathal O’Brien, Florian Pinault, Jan Polster, B...
-
[10]
URL https: //arxiv.org/abs/2412.15832. 10 Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations,
-
[11]
URLhttps://arxiv.org/abs/2010.08895. Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Repre- sentations,
Pith/arXiv arXiv 2010
-
[12]
URLhttps://arxiv.org/ abs/2410.11199. Ruben Ohana, Michael McCabe, Lucas Thibaut Meyer, Rudy Morel, Fruzsina Julia Agocs, Miguel Beneitez, Marsha Berger, Blakesley Burkhart, Stuart B. Dalziel, Drummond Buschman Fielding, Daniel Fortunato, Jared A. Goldberg, Keiya Hirashima, Yan-Fei Jiang, Rich Kerswell, Surya- narayana Maddu, Jonah M. Miller, Payel Mukhop...
-
[13]
doi: 10.1109/ ICCV51070.2023.00387. R. Pic, C. Dombry, P. Naveau, and M. Taillardat. Proper scoring rules for multivariate proba- bilistic forecasts based on aggregation and transformation.Advances in Statistical Climatology, Meteorology and Oceanography, 11(1):23–58,
arXiv 2023
-
[14]
URL https://ascmo.copernicus.org/articles/11/23/2025/
doi: 10.5194/ascmo-11-23-2025. URL https://ascmo.copernicus.org/articles/11/23/2025/. C. Raman, M. Köhl, R. Onofrio, D. S. Durfee, C. E. Kuklewicz, Z. Hadzibabic, and W. Ketterle. Evidence for a critical velocity in a Bose-Einstein condensed gas.Physical Review Letters, 83 (13):2502–2505, September
-
[15]
doi: 10.1103/physrevlett.83.2502
ISSN 1079-7114. doi: 10.1103/physrevlett.83.2502. URL http://dx.doi.org/10.1103/PhysRevLett.83.2502. M. T. Reeves, T. P. Billam, B. P. Anderson, and A. S. Bradley. Identifying a superfluid Reynolds number via dynamical similarity.Physical Review Letters, 114(15), April
-
[16]
doi: 10.1103/physrevlett.114.155302
ISSN 1079-7114. doi: 10.1103/physrevlett.114.155302. URL http://dx.doi.org/10.1103/PhysRevLett. 114.155302. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695,
-
[17]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241. Springer,
2015
-
[18]
François Rozet, Ruben Ohana, Michael McCabe, Gilles Louppe, Francois Lanusse, and Shirley Ho
doi: 10.1007/978-3-319-24574-4_28. François Rozet, Ruben Ohana, Michael McCabe, Gilles Louppe, Francois Lanusse, and Shirley Ho. Lost in latent space: An empirical study of latent diffusion models for physics emulation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. URL https://openreview.net/forum?id=xoNrbfbekM. Fr...
-
[19]
doi: 10.1103/ physrevlett.104.150404
ISSN 1079-7114. doi: 10.1103/ physrevlett.104.150404. URLhttp://dx.doi.org/10.1103/PhysRevLett.104.150404. Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Dan MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. PDEBench: An extensive benchmark for scientific machine learning. InThirty-sixth Conference on Neural Information Processing S...
-
[20]
smoke-flow
The vorticity equation is integrated with a finite-difference discretisation of the Laplacian and advection terms, while the Poisson equation (1b) for the stream function is solved spectrally via fast Fourier transform (FFT); time stepping is performed with an adaptive RK45 solver and a snapshot stride∆t= 0.25. Table 2: Parameter ranges used to sample AD ...
2023
-
[21]
to periodic vortex–antivortex pair shedding (a quantum von Kármán street; Sasaki et al., 2010; Kwon et al.,
2010
-
[22]
The parameter ranges below are chosen so that vmax straddles vc
and on to increasingly disordered wakes that follow a superfluid-Reynolds-number scaling (Reeves et al., 2015). The parameter ranges below are chosen so that vmax straddles vc. Because the obstacle motion is sinusoidal, a single sweep can pass through slower and faster phases of the forcing. The simulation is performed on a uniform 64×64 periodic Fourier ...
2015
-
[23]
Processors Our main comparison is between two model classes with matched ViT backbones
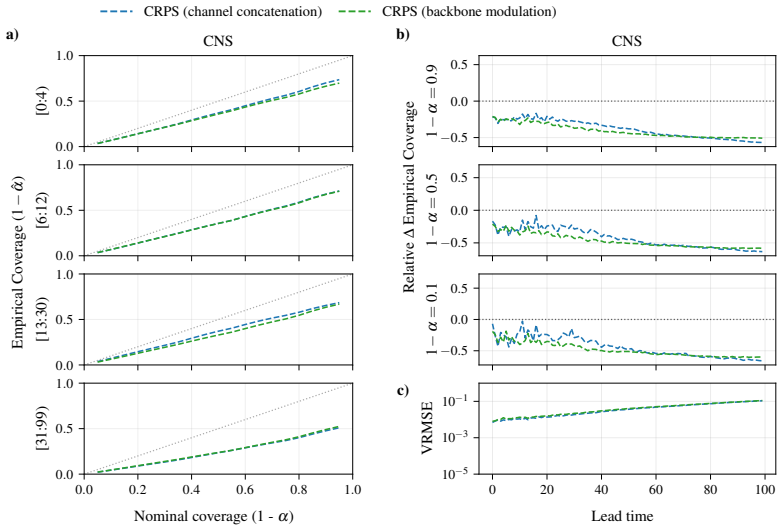
This corresponds to a relatively mild compression rate compared with some recent latent-emulation settings, but is appropriate for our 64×64 resolution regime and allows us to isolate the effect of latent space forecasting without introducing an aggressively lossy bottleneck. Processors Our main comparison is between two model classes with matched ViT bac...
2023
-
[24]
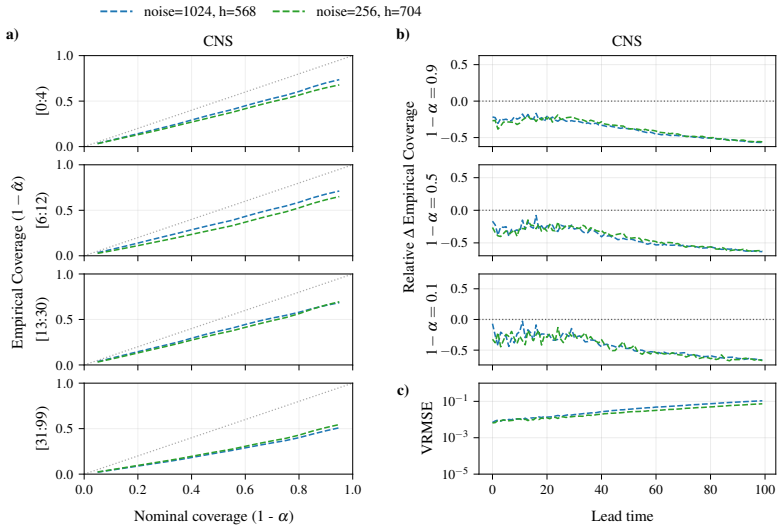
and are identical across datasets. Main Ablations FM CRPS FM CRPS Diffusion CRPS (latent) (ambient) (ambient) (latent) (latent) (ambient) Backbone ViT ViT ViT ViT ViT U-Net Width / channels704 568 704 568 70462, 124, 248, 496 Blocks12 12 12 12 123, 3, 3, 3 Heads8 8 8 8 8— Patch size1 4 4 1 1— MLP expansion4 4 4 4 4 1 Noise channels —1024—1024—1024 Ensembl...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.