Nous: An Attempt to Extract and Inject the Cognition Behind Prediction-Market Behavior
Pith reviewed 2026-06-27 06:36 UTC · model grok-4.3
The pith
Behavioral profiles from prediction-market traders can be partially recovered but resist transfer to LLM agents via prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across 100 wallets, eight of fourteen parameters are temporally stable (split-half ICC >= 0.5), wallets are retrievable from profiles at 17-22 percent top-1 accuracy versus 1 percent chance, and two pre-specified dimensions correlate with future realized profit. On multiple models, however, structured injection shows no significant embedding-distance advantage over controls, the resulting diversity leaves ensemble error correlation and Brier score unchanged, and the prompt translator emits near-uniform outputs whose spread does not track input-profile spread.
What carries the argument
The eight-dimension behavioral profile extracted from trading activity together with the structure-to-narrative translator used for prompt injection.
If this is right
- Stable parameters allow reliable longitudinal profiling of individual traders.
- Above-chance identifiability indicates that the profiles capture distinctive behavioral signatures.
- Profit correlations for two dimensions suggest those traits may carry economic value.
- Null injection results hold across variations in sampling temperature, profile diversity, and question difficulty.
- Compression occurs inside the prompt generator before any model processes the text.
Where Pith is reading between the lines
- Deeper methods such as fine-tuning or activation steering on profile-matched data may succeed where prompts fail.
- The same extraction pipeline could be applied to other collective-decision domains to test whether prompt compression is domain-specific.
- Refining the eight dimensions to remove behavioral confounds might increase the chance that any injection method transmits usable traits.
- If prompt-level transfer remains impossible, collective forecasting systems may need model-level diversity mechanisms rather than prompt engineering.
Load-bearing premise
The eight dimensions capture transferable cognitive traits rather than surface trading patterns, and semantic embedding distance plus Brier score are sufficient to detect whether those traits have been injected.
What would settle it
An experiment in which any injection method produces a statistically significant drop in ensemble error correlation below the observed r approximately 0.77 baseline while also increasing embedding distance between profile-matched and control agents.
Figures
read the original abstract
As LLM agents proliferate in prediction markets and collective decision-making, they risk a cognitive monoculture: agents built on shared foundation models produce correlated forecasts, and recent measurement finds frontier-model errors correlated at r ~ 0.77. We ask whether human cognitive diversity can be recovered from behavior and transferred to LLM agents. Nous extracts a structured eight-dimension behavioral profile from real Polymarket trading activity and injects it into agents through prompts. Our central finding is a dissociation between the two halves of that pipeline. Extraction works, partially: across 100 wallets, 8 of 14 parameters are temporally stable (split-half ICC >= 0.5, bootstrap CI lower bound > 0.3; contrarian score reaches ICC ~ 0.9); wallets are identifiable from their profiles well above chance (top-1 retrieval 17-22% vs. 1% chance); and two of four pre-specified dimensions rank-correlate with future realized profit out-of-sample, though the correlations do not survive behavioral-confound controls. Prompt-level injection does not measurably transmit it: on a semantic embedding metric, structured injection shows no significant advantage over a length-matched control on any model, and the diversity it induces neither reduces ensemble error correlation nor improves Brier score -- a null that persists across exploratory checks on sampling temperature, profile diversity, and question difficulty. Measuring the prompts themselves locates the compression before the model: the structure-to-narrative translator emits near-uniform prompts whose spread does not track profile spread. We position Nous as measuring the cognitive-monoculture problem and the limits of a prompt-level remedy, motivating deeper, below-the-prompt injection (fine-tuning, activation steering). Code, frozen profiles, prompts, and model outputs: https://github.com/WillChienT/nous-paper
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Nous, which extracts an eight-dimension behavioral profile from real Polymarket trading activity across 100 wallets and attempts to inject these profiles into LLM agents via structured prompts. The central claim is a dissociation: extraction is partially successful, with 8 of 14 parameters showing split-half ICC >=0.5 (bootstrap CI lower bound >0.3), above-chance wallet retrieval (17-22% top-1), and two dimensions correlating with out-of-sample profit (though not surviving confound controls); prompt-level injection fails to transmit the profiles, showing no advantage over length-matched controls on semantic embedding distance, no reduction in ensemble error correlation, and no Brier score improvement, with the null persisting across temperature, diversity, and difficulty checks and traced to the structure-to-narrative translator emitting near-uniform prompts.
Significance. If the dissociation holds, the work supplies a reproducible empirical measurement of the cognitive-monoculture problem in LLM agents for prediction markets and collective decisions, while documenting the limits of prompt-based transfer and motivating deeper methods such as fine-tuning or activation steering. Public release of code, frozen profiles, prompts, and model outputs is a clear strength that enables direct replication and extension.
major comments (2)
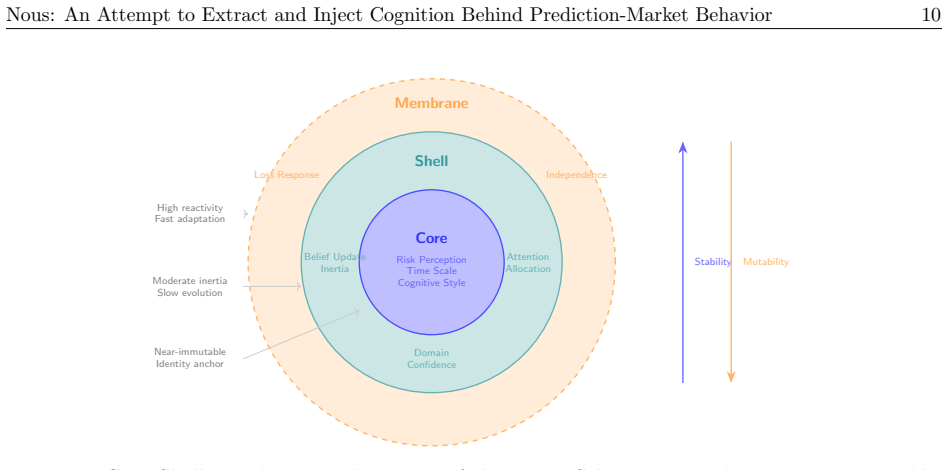
- [§3] §3 (Extraction): The exact definitions of the 14 parameters, the contrarian score, and the criteria for selecting/reducing to the eight dimensions are not fully specified in the text (though referenced in the code); this is load-bearing for assessing whether the stable parameters capture transferable cognitive traits versus surface trading patterns, and for interpreting the ICC and retrieval results.
- [§4.3] §4.3 (Injection results): The structure-to-narrative translator's production of near-uniform prompts (spread uncorrelated with profile spread) is presented as the source of the null; however, no quantitative metric or table quantifies this uniformity (e.g., variance of embedding distances across profiles), which is central to scoping the claim that prompt-level injection 'does not measurably transmit' the profiles.
minor comments (3)
- [Abstract] Abstract: the frontier-model error correlation r ~ 0.77 is stated without a citation or reference to the source measurement.
- [§4.2] The semantic embedding metric and Brier score are used to detect injection success, but their sensitivity (e.g., via positive controls with known profile differences) is not reported.
- [Results] Table or figure showing the 14 parameters, their ICC values, and which eight are retained would improve clarity of the extraction results.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and positive assessment of the work's contribution to measuring cognitive monoculture in LLM agents. We address the two major comments below and will make the requested clarifications in a revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Extraction): The exact definitions of the 14 parameters, the contrarian score, and the criteria for selecting/reducing to the eight dimensions are not fully specified in the text (though referenced in the code); this is load-bearing for assessing whether the stable parameters capture transferable cognitive traits versus surface trading patterns, and for interpreting the ICC and retrieval results.
Authors: We agree that the manuscript would benefit from self-contained definitions. The 14 parameters and contrarian score are defined in the linked code, but to address this we will add explicit mathematical and operational definitions of all parameters, the contrarian score formula, and the pre-specified criteria used to retain the eight dimensions (split-half ICC threshold, bootstrap CI, and domain relevance) into a new subsection of §3. This will allow readers to evaluate the constructs without consulting external code. revision: yes
-
Referee: [§4.3] §4.3 (Injection results): The structure-to-narrative translator's production of near-uniform prompts (spread uncorrelated with profile spread) is presented as the source of the null; however, no quantitative metric or table quantifies this uniformity (e.g., variance of embedding distances across profiles), which is central to scoping the claim that prompt-level injection 'does not measurably transmit' the profiles.
Authors: We concur that an explicit quantitative metric would strengthen the presentation. In the revision we will add a table (or supplementary figure) reporting the variance and range of semantic embedding distances among the generated prompts, together with the correlation between prompt spread and profile spread, directly quantifying the uniformity observed in the structure-to-narrative translator. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's claims rest entirely on direct empirical measurements against external trading data and model outputs: split-half ICC values, retrieval accuracies, out-of-sample profit correlations, semantic embedding distances, ensemble error correlations, and Brier scores. No quantity is defined in terms of a fitted parameter that is then treated as a prediction, and the manuscript contains no self-citations, uniqueness theorems, or ansatzes that reduce the central dissociation result to its own inputs by construction. The structure-to-narrative translator's uniformity is reported as an observed measurement rather than a definitional step.
Axiom & Free-Parameter Ledger
free parameters (3)
- ICC stability threshold
- Contrarian score definition
- Profile-to-prompt translator parameters
axioms (2)
- domain assumption Trading activity on Polymarket reflects stable, transferable cognitive traits rather than transient market conditions or liquidity effects.
- domain assumption Semantic embedding distance and Brier score are adequate proxies for whether a cognitive profile has been successfully injected into an LLM.
invented entities (1)
-
Eight-dimension behavioral profile (Nous)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qiming Bao, Xiaoxuan Fu, and Michael Witbrock. Conflict-aware fusion: Mitigating logic inertia in large language models via structured cognitive priors.arXiv preprint arXiv:2512.06393, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Rajat M. Barot and Arjun S. Borkhatariya. PolySwarm: A multi-agent large language model framework for prediction market trading and latency arbitrage.arXiv preprint arXiv:2604.03888, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
PolyBench: Benchmarking LLM Forecasting and Trading Capabilities on Live Prediction Market Data
Pu Cheng, Juncheng Liu, and Yunshen Long. PolyBench: Benchmarking LLM forecasting and trading capabilities on live prediction market data.arXiv preprint arXiv:2604.14199, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Putnam, 1994
Antonio Damasio.Descartes’ Error: Emotion, Reason, and the Human Brain. Putnam, 1994
1994
-
[5]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InInternational Conference on Machine Learning, pages 8560–8581. PMLR, 2023
2023
-
[6]
Portfolio/Penguin, 2021
Julia Galef.The Scout Mindset: Why Some People See Things Clearly and Others Don’t. Portfolio/Penguin, 2021. Nous: An Attempt to Extract and Inject Cognition Behind Prediction-Market Behavior 33
2021
-
[7]
Griffiths, Charles Kemp, and Joshua B
Thomas L. Griffiths, Charles Kemp, and Joshua B. Tenenbaum. Bayesian models of cognition. Cambridge Handbook of Computational Psychology, pages 59–100, 2008
2008
-
[8]
Approaching human-level forecasting with language models
Danny Halawi, Fred Zhang, Yueh-Han Chen, and Jacob Steinhardt. Approaching human-level forecasting with language models. InAdvances in Neural Information Processing Systems, volume 37, 2024. NeurIPS 2024 poster; arXiv:2402.18563. OpenReview FlcdW7NPRY
-
[9]
Ojha, Ross Spoon, Jiatong Han, and Colin F
Thomas Henning, Siddhartha M. Ojha, Ross Spoon, Jiatong Han, and Colin F. Camerer. LLM agents do not replicate human market traders: Evidence from experimental finance.arXiv preprint arXiv:2502.15800, 2025
-
[10]
Lu Hong and Scott E. Page. Groups of diverse problem solvers can outperform groups of high- ability problem solvers.Proceedings of the National Academy of Sciences, 101(46):16385–16389, 2004
2004
-
[11]
Designing AI- agents with personalities: A psychometric approach.Personality Science, 2026
Muhua Huang, Xijuan Zhang, Christopher Soto, and James Evans. Designing AI- agents with personalities: A psychometric approach.Personality Science, 2026. DOI 10.1177/27000710251406471
-
[12]
Giulia Iadisernia and Carolina Camassa. Prompting for policy: Forecasting macroeconomic scenarios with synthetic LLM personas.arXiv preprint arXiv:2511.02458, 2025. 6th ACM International Conference on AI in Finance (ICAIF ’25)
-
[13]
Training LLMs to predict world events
Scott Jeen and Matthew Aitchison. Training LLMs to predict world events. https:// thinkingmachines.ai/news/training-llms-to-predict-world-events/ , Mar 2026. Man- tic system blog post (in collaboration with Thinking Machines), 19 March 2026. Reports GRPO-style RL fine-tuning of gpt-oss-120b on ∼10k binary questions with Brier-score reward, lifting Metacul...
2026
-
[14]
Farrar, Straus and Giroux, 2011
Daniel Kahneman.Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011
2011
-
[15]
Conditions for intuitive expertise: A failure to disagree
Daniel Kahneman and Gary Klein. Conditions for intuitive expertise: A failure to disagree. American Psychologist, 64(6):515–526, 2009
2009
-
[16]
Prospect theory: An analysis of decision under risk
Daniel Kahneman and Amos Tversky. Prospect theory: An analysis of decision under risk. Econometrica, 47(2):263–291, 1979
1979
-
[17]
Ayato Kitadai, Yusuke Fukasawa, and Nariaki Nishino. Bias-adjusted LLM agents for human- like decision-making via behavioral economics.arXiv preprint arXiv:2508.18600, 2025
-
[18]
MIT Press, 1998
Gary Klein.Sources of Power: How People Make Decisions. MIT Press, 1998
1998
-
[19]
Coordination as an Architectural Layer for LLM-Based Multi-Agent Systems
Maksym Nechepurenko and Pavel Shuvalov. Coordination as an architectural layer for LLM- based multi-agent systems.arXiv preprint arXiv:2605.03310, 2026. Nous: An Attempt to Extract and Inject Cognition Behind Prediction-Market Behavior 34
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, volume 35, pages 27730–27744, 2022
2022
-
[21]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22. ACM, 2023
2023
-
[22]
LLM-as-a-Prophet: Understanding Predictive Intelligence with Prophet Arena
Prophet Arena. Prophet Arena: A live benchmark for predictive intelligence. https:// prophetarena.co/, 2026. Live forecasting benchmark for LLMs; default scoring is Brier score with an averaged-return metric. A companion academic paper, “LLM-as-a-Prophet: Understanding Predictive Intelligence with Prophet Arena” (arXiv:2510.17638, ICLR 2026), documents th...
-
[23]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[24]
In-context impersonation reveals large language models’ strengths and biases
Leonard Salewski, Stephan Alaniz, Isabel Rio-Torto, Eric Schulz, and Zeynep Akata. In-context impersonation reveals large language models’ strengths and biases. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[25]
Park, Rafael Valdece Sousa Bastos, and Philip E
Philipp Schoenegger, Indre Tuminauskaite, Peter S. Park, Rafael Valdece Sousa Bastos, and Philip E. Tetlock. Wisdom of the silicon crowd: LLM ensemble prediction capabilities rival human crowd accuracy.Science Advances, 10(45), 2024. doi: 10.1126/sciadv.adp1528. arXiv preprint 2402.19379 (Feb 2024); journal version published in Science Advances Nov 2024
-
[26]
Role-play with large language models
Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role-play with large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[27]
The Oracle's Fingerprint: Correlated AI Forecasting Errors and the Limits of Bias Transmission
Theodor Spiro. The oracle’s fingerprint: Correlated AI forecasting errors and the limits of bias transmission.arXiv preprint arXiv:2605.00844, 2026. Reports mean pairwise forecasting-error correlation r = 0.77 (r = 0.78 excluding likely-leaked questions) across GPT-4o, Claude, and Gemini on 568 resolved binary questions
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Doubleday, 2004
James Surowiecki.The Wisdom of Crowds. Doubleday, 2004
2004
-
[29]
Tetlock.Expert Political Judgment: How Good Is It? How Can We Know?Princeton University Press, 2005
Philip E. Tetlock.Expert Political Judgment: How Good Is It? How Can We Know?Princeton University Press, 2005
2005
-
[30]
Tetlock and Dan Gardner.Superforecasting: The Art and Science of Prediction
Philip E. Tetlock and Dan Gardner.Superforecasting: The Art and Science of Prediction. Crown, 2015. Nous: An Attempt to Extract and Inject Cognition Behind Prediction-Market Behavior 35
2015
-
[31]
Advances in prospect theory: Cumulative representation of uncertainty.Journal of Risk and Uncertainty, 5(4):297–323, 1992
Amos Tversky and Daniel Kahneman. Advances in prospect theory: Cumulative representation of uncertainty.Journal of Risk and Uncertainty, 5(4):297–323, 1992
1992
-
[32]
Multiperspectivity as a resource for narrative similarity prediction
Max Upravitelev, Veronika Solopova, Jing Yang, Charlott Jakob, Premtim Sahitaj, Ariana Sahitaj, and Vera Schmitt. Multiperspectivity as a resource for narrative similarity prediction. arXiv preprint arXiv:2603.22103, 2026
-
[33]
Beyond inherent cognition biases in LLM-based event forecasting: A multi-cognition agentic framework
Zhen Wang, Xi Zhou, Yating Yang, Bo Ma, Lei Wang, Rui Dong, and Azmat Anwar. Beyond inherent cognition biases in LLM-based event forecasting: A multi-cognition agentic framework. Findings of EMNLP, 2025
2025
-
[34]
Ruihan Yang, Fanghua Ye, Xiang We, Ruoqing Zhao, Kang Luo, Xinbo Xu, Bo Zhao, Ruotian Ma, Shanyi Wang, Zhaopeng Tu, Xiaolong Li, Deqing Yang, and Linus. Think fast and slow: Step-level cognitive depth adaptation for LLM agents.arXiv preprint arXiv:2602.12662, 2026
-
[35]
Yuzhe Yang, Yifei Zhang, Minghao Wu, Kaidi Zhang, Yunmiao Zhang, Honghai Yu, Yan Hu, and Benyou Wang. TwinMarket: A scalable behavioral and social simulation for financial markets.arXiv preprint arXiv:2502.01506, 2025
-
[36]
Ben Yellin, Ehud Ezra, Mark Foreman, and Shula Grinapol. Decoding the human factor: High fidelity behavioral prediction for strategic foresight.arXiv preprint arXiv:2602.17222, 2026
-
[37]
Prediction Arena: Benchmarking AI Models on Real-World Prediction Markets
Jaden Zhang, Gardenia Liu, Oliver Johansson, Hileamlak Yitayew, Kamryn Ohly, and Grace Li. Prediction arena: Benchmarking AI models on real-world prediction markets.arXiv preprint arXiv:2604.07355, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Jian-Qiao Zhu and Thomas L. Griffiths. Eliciting the priors of large language models using iterated in-context learning.arXiv preprint arXiv:2406.01860, 2024. A Local-Model Forecasting Baseline This appendix gives the full detail behind the summary in Section 6.1: the setup, the information- leakage audit, the top-volume stratified result, the mid-volume ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.