Disparate Impact in Synthetic Data Generation
Pith reviewed 2026-06-27 07:21 UTC · model grok-4.3
The pith
Non-disparate impact in synthetic data generation is achieved by matching the real distribution exactly, but methods often fail due to group-different approximation and estimation errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Non-disparate impact is notably achieved when the synthetic and real distributions are the same. SDG may fail to reach that solution because approximation and estimation errors occur and can be disparate across groups. The authors examine the expressive power of methods relative to distribution complexity, sampling errors due to group proportions, and estimation errors induced by differential privacy. They illustrate the resulting disparate impact on artificial and real-world data with probabilistic graphical models and show that learning group-wise SDG models improves both overall utility and its parity in many settings.
What carries the argument
The analysis of how model approximation limits, group-proportion sampling variance, and differential-privacy noise each produce unequal record utility across sensitive groups, together with the group-wise learning strategy that trains separate generators per group to reduce those differences.
If this is right
- Methods whose expressive power is insufficient for the true distribution will generate larger errors on complex subgroups, creating measurable utility gaps.
- Smaller groups experience higher sampling variance, raising the probability that their synthetic records have lower utility than those of larger groups.
- Privacy mechanisms that add noise produce estimation errors whose size can depend on group statistics, leading to disparate impact even when the underlying model is unbiased.
- Training one generator per sensitive group reduces the impact of both sampling and approximation errors on parity while preserving or improving aggregate utility.
Where Pith is reading between the lines
- The same error-parity lens could be applied to generative models outside probabilistic graphical models, such as GANs or diffusion models.
- If the observed data already embed historical biases, faithful matching would propagate them, so practitioners must separately decide whether matching or correction is the appropriate fairness goal.
- Group-wise training adds a tunable hyperparameter (number of groups or clustering) whose effect on the utility-parity trade-off can be measured directly on validation sets.
Load-bearing premise
That the correct target for non-disparate impact is exact distributional match to the observed data rather than correction of biases already present in that data.
What would settle it
An experiment in which an SDG method is given infinite samples, perfect expressivity, and no privacy noise yet still shows unequal utility across groups, or in which group-wise models produce no parity improvement on the same data.
Figures
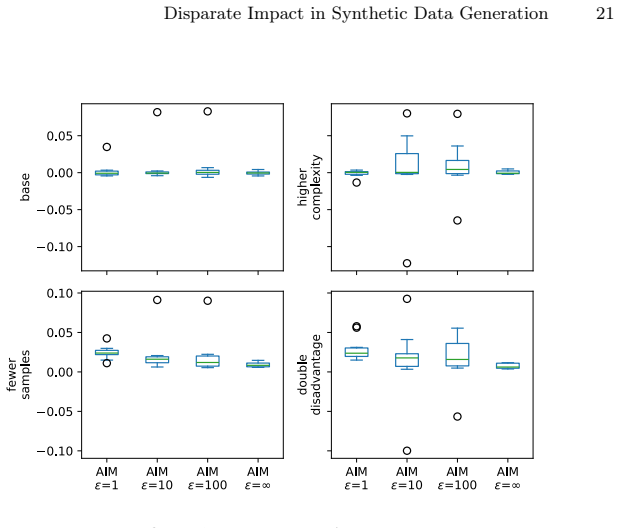
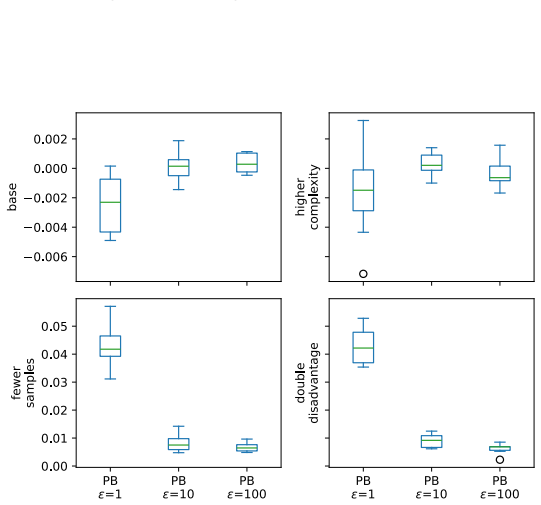
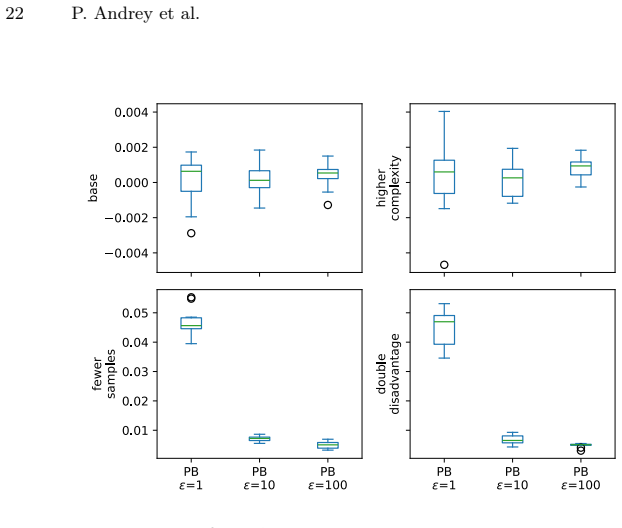
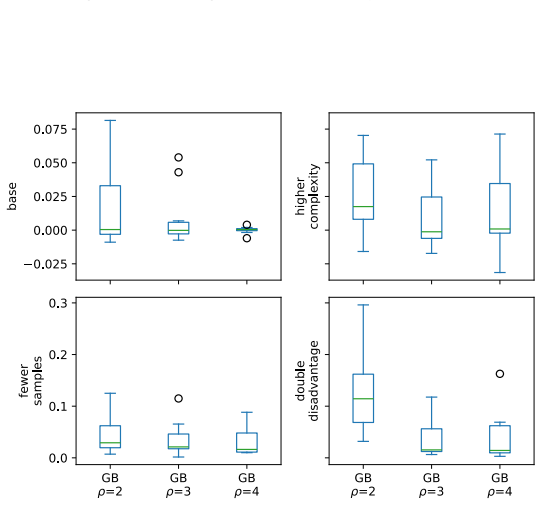
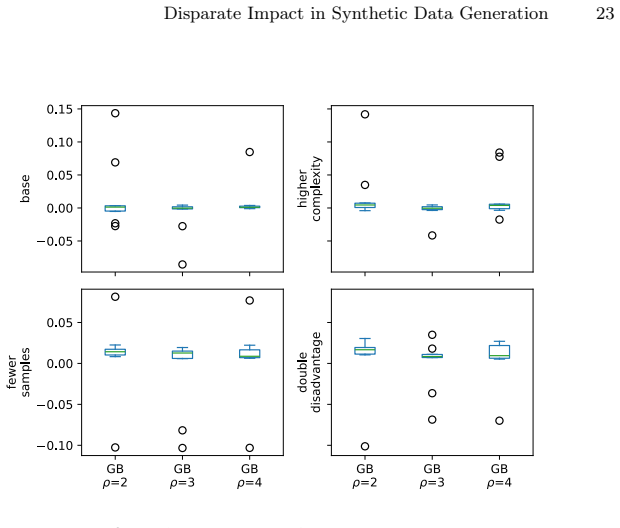
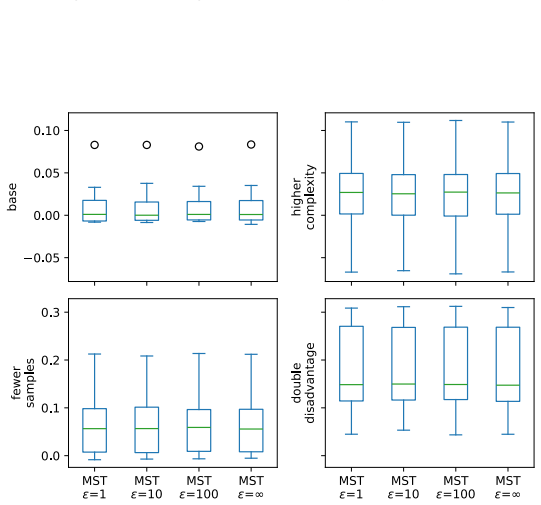
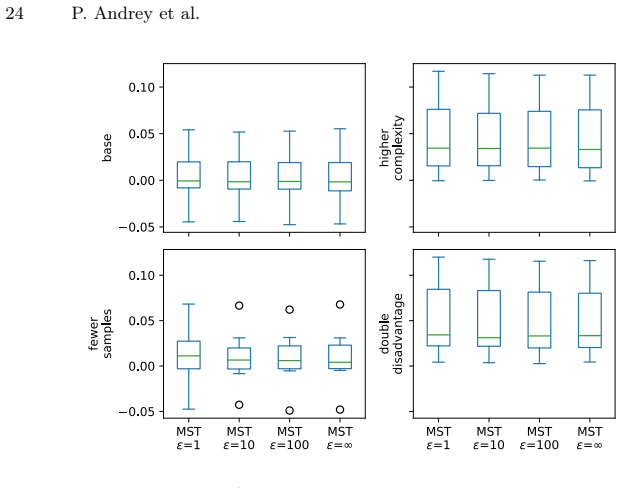
read the original abstract
We revisit the fairness notion of disparate impact for synthetic data generation (SDG), that assesses whether the utility of generated records is the same across sensitive groups. Our approach departs from existing work on fair SDG, that address the problem of correcting for undue biases in the observed distribution, hence redefining SDG as learning a distribution that is not that of the real data. By contrast, non-disparate impact is notably achieved when the synthetic and real distributions are the same. We expose reasons why SDG may fail to reach that solution and discuss why approximation and estimation errors occur and can be disparate across groups. We notably look into the expressive power of SDG methods relative to distribution complexity, sampling errors due to group proportions, and estimation errors induced by differential privacy mechanisms. We illustrate cases of disparate impact on both artificial and real-world data, focusing on SDG methods that rely on probabilistic graphical models. We also introduce a strategy of learning group-wise SDG models and illustrate how it can improve both the overall utility and its parity in many settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript revisits disparate impact for synthetic data generation (SDG), defining it as equal utility of generated records across sensitive groups. It departs from prior fair-SDG work that corrects biases in the observed data; instead, it claims non-disparate impact is achieved when the synthetic distribution exactly matches the real one. The authors analyze why standard SDG methods (focusing on probabilistic graphical models) fail to reach this match due to limited expressive power relative to distribution complexity, sampling errors from group proportions, and estimation errors from differential privacy. They illustrate failure cases on artificial and real-world data and introduce a group-wise SDG modeling strategy claimed to improve both overall utility and parity.
Significance. If the error analysis and group-wise mitigation hold under quantitative scrutiny, the work could usefully reorient fair SDG toward faithful replication rather than bias correction, while highlighting concrete practical failure modes (expressive power, sampling imbalance, DP noise) in common generative methods. The proposed group-wise approach offers a lightweight, implementable intervention that could be adopted in privacy-preserving data synthesis pipelines.
major comments (2)
- [Abstract] Abstract: The load-bearing claim that 'non-disparate impact is notably achieved when the synthetic and real distributions are the same' is not accompanied by a formal statement showing that distributional equality implies |U_synth(A) - U_synth(B)| = 0. When the real data already exhibits |U_real(A) - U_real(B)| > 0, exact matching replicates that disparity, which appears to contradict the stated definition of non-disparate impact unless an unstated premise (real data is unbiased) or redefinition of the metric (to introduced disparity only) is intended. This choice underpins the paper's explicit departure from bias-correcting fair-SDG literature.
- [Abstract] Abstract (illustrations paragraph): The manuscript describes illustrations on artificial and real data but supplies no quantitative results, error bars, baseline comparisons, or statistical controls. Without these, it is impossible to assess whether the reported improvements in utility and parity from the group-wise strategy are robust or merely visual.
minor comments (1)
- [Abstract] The abstract would benefit from an explicit mathematical definition of the utility function U and the disparate-impact metric before stating the central claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the positioning of our work relative to the fair-SDG literature. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that 'non-disparate impact is notably achieved when the synthetic and real distributions are the same' is not accompanied by a formal statement showing that distributional equality implies |U_synth(A) - U_synth(B)| = 0. When the real data already exhibits |U_real(A) - U_real(B)| > 0, exact matching replicates that disparity, which appears to contradict the stated definition of non-disparate impact unless an unstated premise (real data is unbiased) or redefinition of the metric (to introduced disparity only) is intended. This choice underpins the paper's explicit departure from bias-correcting fair-SDG literature.
Authors: We agree that the abstract phrasing requires clarification. Our intended definition is that non-disparate impact means the SDG process introduces no additional disparity beyond any that already exists in the real data: exact distributional match ensures U_synth matches U_real (including any group disparity present in the real data). This is distinct from absolute parity and explains our departure from bias-correction methods. We will revise the abstract and add a formal statement in Section 2 to make this explicit, including the implication that |U_synth(A) - U_synth(B)| = |U_real(A) - U_real(B)| under exact match. revision: yes
-
Referee: [Abstract] Abstract (illustrations paragraph): The manuscript describes illustrations on artificial and real data but supplies no quantitative results, error bars, baseline comparisons, or statistical controls. Without these, it is impossible to assess whether the reported improvements in utility and parity from the group-wise strategy are robust or merely visual.
Authors: The main manuscript body contains quantitative evaluations (utility and parity metrics, baseline comparisons, and multiple runs) on both artificial and real-world data, with the group-wise approach showing improvements in the reported settings. However, the abstract's summary of the illustrations is indeed high-level and lacks these details. We will revise the abstract to briefly reference the quantitative gains and ensure the main text explicitly includes error bars and statistical controls for the group-wise results. revision: yes
Circularity Check
No significant circularity; central claim is definitional implication, not reduction to input
full rationale
The paper defines disparate impact as equal utility of generated records across sensitive groups and states that this is achieved when synthetic and real distributions match. This follows directly as a logical consequence if utility is a function of the distribution, without any derivation that reduces a result to a fitted parameter or self-citation by construction. The analysis of approximation/estimation errors and the group-wise modeling strategy are independent contributions with no evident self-definitional loops, fitted-input predictions, or load-bearing self-citations. The paper is self-contained against its stated assumptions and does not invoke uniqueness theorems or rename known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Dasgupta, S., Mandt, S., Li, Y
Abroshan, M., Elliott, A., Mahdi Khalili, M.: Imposing fairness constraints in syn- thetic data generation. In: Dasgupta, S., Mandt, S., Li, Y. (eds.) Proceedings of The 27th International Conference on Artificial Intelligence and Statistics. Pro- ceedings of Machine Learning Research, vol. 238, pp. 2269–2277. PMLR (02–04 May 2024),https://proceedings.mlr...
2024
-
[2]
(eds.) Machine Learning and Knowledge Discovery in Databases
Andrey, P., Le Bars, B., Tommasi, M.: Tamis: Tailored membership inference at- tacksonsyntheticdata.In:Ribeiro,R.P.,Pfahringer,B.,Japkowicz,N.,Larrañaga, P., Jorge, A.M., Soares, C., Abreu, P.H., Gama, J. (eds.) Machine Learning and Knowledge Discovery in Databases. Research Track. pp. 203–220. Springer Nature Switzerland, Cham (2026)
2026
-
[3]
MIT Press (2023)
Barocas,S.,Hardt,M.,Narayanan,A.:FairnessandMachineLearning:Limitations and Opportunities. MIT Press (2023)
2023
-
[4]
In: Proceedings of the 35th International Conference on Neural Information Processing Systems
Breugel, B.v., Kyono, T., Berrevoets, J., van der Schaar, M.: Decaf: generating fair synthetic data using causally-aware generative networks. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. NIPS ’21, Curran Associates Inc., Red Hook, NY, USA (2021)
2021
-
[5]
Bullwinkel, B., Grabarz, K., Ke, L., Gong, S., Tanner, C., Allen, J.: Evaluating the fairness impact of differentially private synthetic data (2022),https://arxiv. org/abs/2205.04321
arXiv 2022
-
[6]
In: Will Synthetic Data Finally Solve the Data Access Problem? (2025),https://openreview.net/forum?id=0bvWk1HuJC
Chen, K., Li, X., GONG, C., McKenna, R., Wang, T.: Benchmarking differentially private tabular data synthesis algorithms. In: Will Synthetic Data Finally Solve the Data Access Problem? (2025),https://openreview.net/forum?id=0bvWk1HuJC
2025
-
[7]
In: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency
Cheng, V., Suriyakumar, V.M., Dullerud, N., Joshi, S., Ghassemi, M.: Can you fake it until you make it? impacts of differentially private synthetic data on downstream classification fairness. In: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. p. 149–160. FAccT ’21, Association for Comput- ing Machinery, New York, NY,...
-
[8]
In: Proceedings of the 37th International Conference on Machine Learning
Choi, K., Grover, A., Singh, T., Shu, R., Ermon, S.: Fair generative modeling via weak supervision. In: Proceedings of the 37th International Conference on Machine Learning. ICML’20, JMLR.org (2020) 16 P. Andrey et al
2020
-
[9]
Advances in Neural Information Processing Systems34(2021)
Ding, F., Hardt, M., Miller, J., Schmidt, L.: Retiring adult: New datasets for fair machine learning. Advances in Neural Information Processing Systems34(2021)
2021
-
[10]
The algorithmic foundations of differential privacy.Found
Dwork, C., Roth, A.: The algorithmic foundations of differential privacy. Foun- dations and Trends®in Theoretical Computer Science9(3–4), 211–407 (2014). https://doi.org/10.1561/0400000042
-
[11]
Feldman, M., Friedler, S.A., Moeller, J., Scheidegger, C., Venkatasubramanian, S.: Certifying and removing disparate impact. In: Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. p. 259–268. KDD ’15, Association for Computing Machinery, New York, NY, USA (2015).https://doi.org/10.1145/2783258.2783311
-
[12]
In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S
Ganev, G., Oprisanu, B., De Cristofaro, E.: Robin hood and matthew effects: Differential privacy has disparate impact on synthetic data. In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S. (eds.) Proceedings of the 39th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 162, pp. 6944–6959...
2022
-
[13]
Ganev, G., Xu, K., De Cristofaro, E.: Graphical vs. deep generative models: Mea- suring the impact of differentially private mechanisms and budgets on utility. In: Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Commu- nications Security. p. 1596–1610. CCS ’24, Association for Computing Machinery, New York, NY, USA (2024).https://doi.org/...
-
[14]
Houssiau, F., Jordon, J., Cohen, S.N., Elliott, A., Geddes, J., Mole, C., Rangel- Smith, C., Szpruch, L.: Prive: Empirical privacy evaluation of synthetic data gener- ators.In:NeurIPS2022WorkshoponSyntheticDataforEmpoweringMLResearch (2022),https://openreview.net/forum?id=9hXskf1K7zQ
2022
-
[15]
Journal of Privacy and Confidentiality11(3) (2021).https://doi.org/10.29012/jpc.778
McKenna, R., Miklau, G., Sheldon, D.: Winning the NIST contest: A scalable and general approach to differentially private synthetic data. Journal of Privacy and Confidentiality11(3) (2021).https://doi.org/10.29012/jpc.778
-
[16]
McKenna, R., Mullins, B., Sheldon, D., Miklau, G.: Aim: an adaptive and iterative mechanism for differentially private synthetic data. Proc. VLDB Endow.15(11), 2599–2612 (Jul 2022).https://doi.org/10.14778/3551793.3551817
-
[17]
PLOS ONE19(2), 1–24 (02 2024).https://doi.org/10.1371/journal.pone.0297271
Pereira,M.,Kshirsagar,M.,Mukherjee,S.,Dodhia,R.,LavistaFerres,J.,deSousa, R.:Assessmentofdifferentiallyprivatesyntheticdataforutilityandfairnessinend- to-end machine learning pipelines for tabular data. PLOS ONE19(2), 1–24 (02 2024).https://doi.org/10.1371/journal.pone.0297271
-
[18]
Pujol, D., Gilad, A., Machanavajjhala, A.: Prefair: Privately generating justifiably fair synthetic data. Proc. VLDB Endow.16(6), 1573–1586 (Feb 2023).https: //doi.org/10.14778/3583140.3583168
-
[19]
In: 31st USENIX Security Symposium (USENIX Security 22)
Stadler, T., Oprisanu, B., Troncoso, C.: Synthetic data – anonymisation groundhog day. In: 31st USENIX Security Symposium (USENIX Security 22). pp. 1451–1468. USENIXAssociation,Boston,MA(2022),https://www.usenix.org/conference/ usenixsecurity22/presentation/stadler
2022
-
[20]
Tao, Y., McKenna, R., Hay, M., Machanavajjhala, A., Miklau, G.: Benchmarking differentially private synthetic data generation algorithms (2022),https://arxiv. org/abs/2112.09238
arXiv 2022
-
[21]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Teo, C.T.H., Abdollahzadeh, M., Cheung, N.M.: On measuring fairness in gen- erative models. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. NIPS ’23, Curran Associates Inc., Red Hook, NY, USA (2023) Disparate Impact in Synthetic Data Generation 17
2023
-
[22]
Foundations and Trends® in Machine Learning , author =
Wainwright, M.J., Jordan, M.I.: Graphical models, exponential families, and vari- ational inference. Foundations and Trends®in Machine Learning1(1–2), 1–305 (2008).https://doi.org/10.1561/2200000001
-
[23]
Walonoski, J., Kramer, M., Nichols, J., Quina, A., Moesel, C., Hall, D., Duffett, C., Dube, K., Gallagher, T., McLachlan, S.: Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record. Journal of the American Medical Informatics Association25(3), 230–238 (08 2017).https://doi.org...
-
[24]
In: Proceedings of the 2024 ACM Conference on Fair- ness, Accountability, and Transparency
Wyllie, S., Shumailov, I., Papernot, N.: Fairness feedback loops: Training on syn- thetic data amplifies bias. In: Proceedings of the 2024 ACM Conference on Fair- ness, Accountability, and Transparency. p. 2113–2147. FAccT ’24, Association for Computing Machinery, New York, NY, USA (2024).https://doi.org/10.1145/ 3630106.3659029
arXiv 2024
-
[25]
Xu, D., Wu, Y., Yuan, S., Zhang, L., Wu, X.: Achieving causal fairness through generative adversarial networks. In: Proceedings of the Twenty-Eighth Interna- tional Joint Conference on Artificial Intelligence, IJCAI-19. pp. 1452–1458. In- ternational Joint Conferences on Artificial Intelligence Organization (7 2019). https://doi.org/10.24963/ijcai.2019/201
-
[26]
In: 2018 IEEE International Conference on Big Data (Big Data)
Xu, D., Yuan, S., Zhang, L., Wu, X.: Fairgan: Fairness-aware generative adversarial networks. In: 2018 IEEE International Conference on Big Data (Big Data). pp. 570–575 (2018).https://doi.org/10.1109/BigData.2018.8622525
-
[27]
In: Dasgupta, S., McAllester, D
Zemel, R., Wu, Y., Swersky, K., Pitassi, T., Dwork, C.: Learning fair represen- tations. In: Dasgupta, S., McAllester, D. (eds.) Proceedings of the 30th Inter- national Conference on Machine Learning. Proceedings of Machine Learning Re- search, vol. 28, pp. 325–333. PMLR, Atlanta, Georgia, USA (17–19 Jun 2013), https://proceedings.mlr.press/v28/zemel13.html
2013
-
[28]
and Srivastava, Divesh and Xiao, Xiaokui , title =
Zhang, J., Cormode, G., Procopiuc, C.M., Srivastava, D., Xiao, X.: PrivBayes: Private data release via bayesian networks. ACM Trans. Database Syst.42(4) (2017).https://doi.org/10.1145/3134428
-
[29]
NIPS ’24, Curran Associates Inc., Red Hook, NY, USA (2025) 18 P
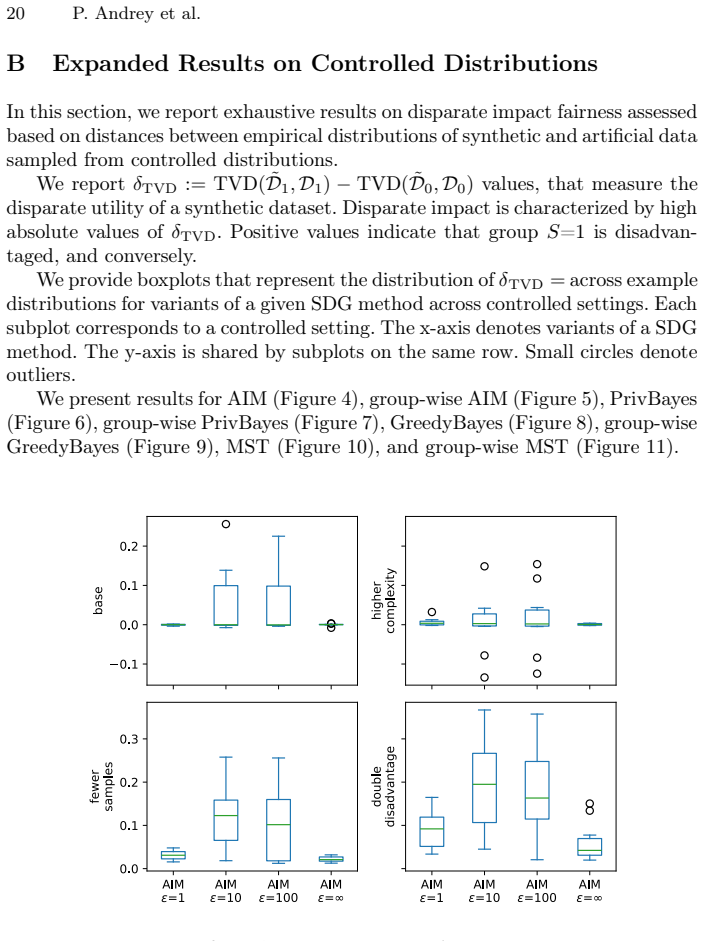
Zhou, Z., Tarzanagh, D.A., Hou, B., Long, Q., Shen, L.: Fairness-aware estimation ofgraphicalmodels.In:Proceedingsofthe38thInternationalConferenceonNeural Information Processing Systems. NIPS ’24, Curran Associates Inc., Red Hook, NY, USA (2025) 18 P. Andrey et al. A Experimental Setup Details In this section, we provide some specific methodological detai...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.