TerraBench: Can Agents Reason Over Heterogeneous Earth-System Data?
Pith reviewed 2026-07-02 22:28 UTC · model grok-4.3
The pith
Reliable Earth-science agents must coordinate heterogeneous workflows, precisely parameterize tools, and preserve artifact provenance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TerraBench shows that agents for Earth science must advance beyond basic tool access by coordinating workflows across heterogeneous data modalities, setting tool parameters accurately, and maintaining provenance of all artifacts generated during reasoning and computation.
What carries the argument
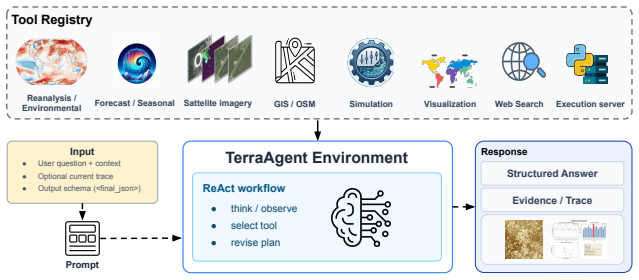
TerraAgent, a ReAct-style executable framework that interleaves LLM reasoning, tool calls, and observations to couple planning with scientific tools for environmental retrieval, geospatial processing, simulation, and artifact-backed computation.
If this is right
- Unifying imagery analysis, gridded data, GIS reasoning, and simulation inside one executable interface reveals gaps that isolated benchmarks miss.
- Pairing process-level tool-use metrics with tolerance-aware numeric scoring gives a more complete picture of agent reliability than accuracy alone.
- Coverage across three tracks and eight domains shows that coordination failures appear consistently rather than in narrow task types.
- The scale of 24,500 verified execution steps demonstrates that realistic Earth-science tasks involve many interdependent steps that must be tracked.
- Success requires agents to treat tool outputs as persistent, provenance-linked artifacts rather than ephemeral results.
Where Pith is reading between the lines
- Improved provenance tracking could raise the auditability of AI-generated environmental reports used in policy decisions.
- The same coordination demands may appear in other scientific domains that combine observational data with simulations, such as materials science or ecology.
- Architectural additions for workflow state management may prove more effective than simply scaling model size.
- Future benchmarks could add explicit tests for error recovery when a tool call produces inconsistent intermediate artifacts.
Load-bearing premise
The 403 tasks and TerraAgent framework accurately capture the requirements and challenges of real-world Earth-science reasoning workflows across heterogeneous data types.
What would settle it
An agent scoring high on the benchmark but producing incorrect or non-reproducible results on an unseen real-world environmental workflow involving mixed satellite imagery and gridded simulation data would falsify the central claim.
Figures
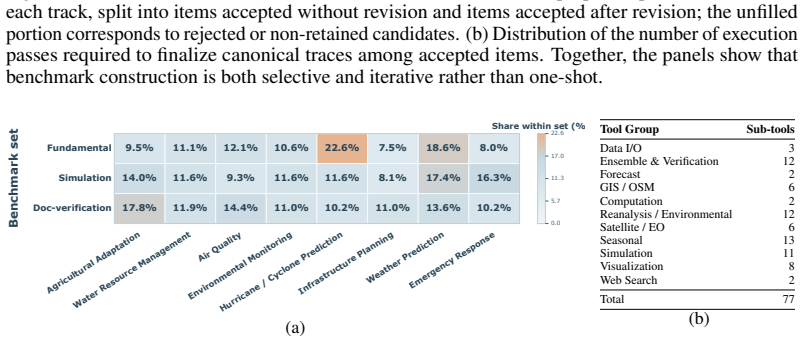
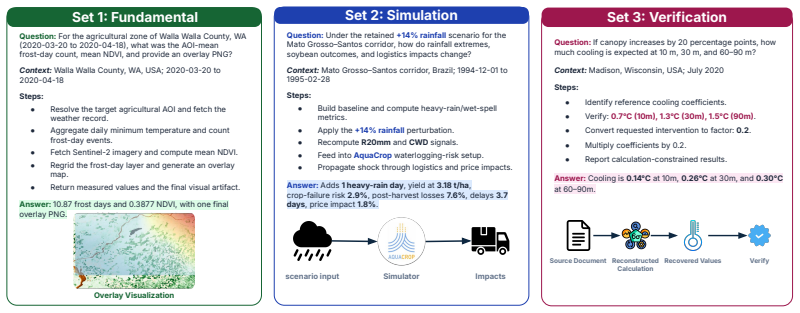
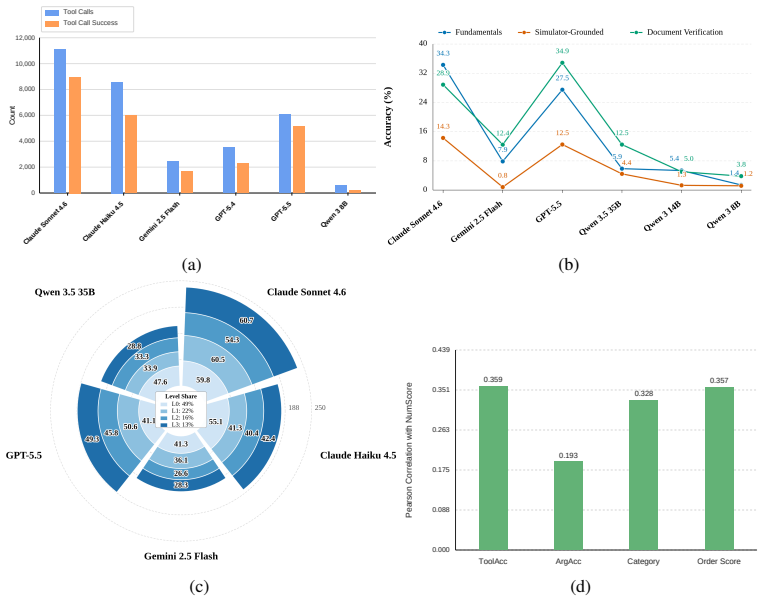
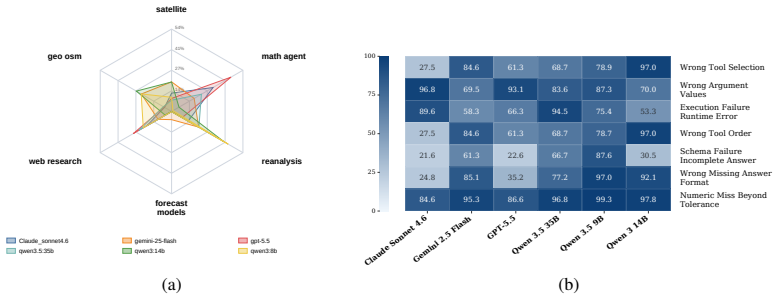
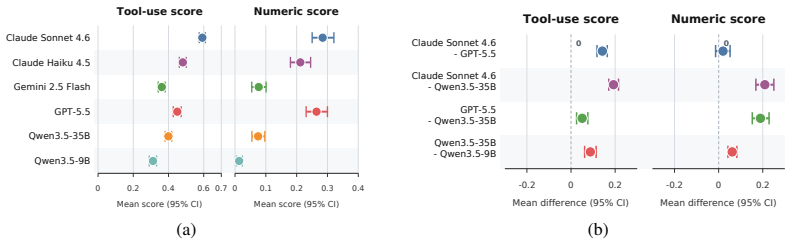
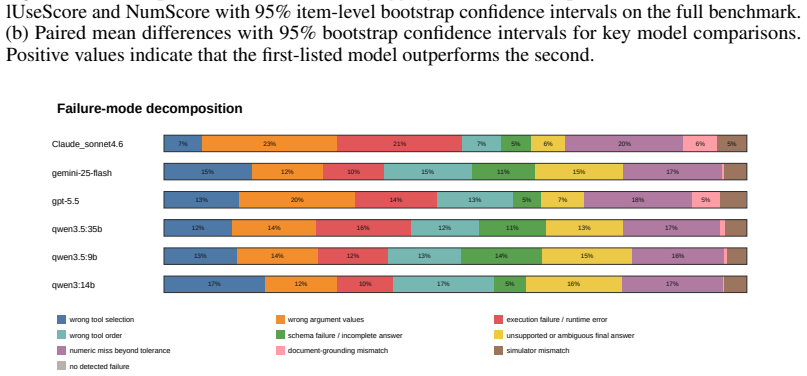
read the original abstract
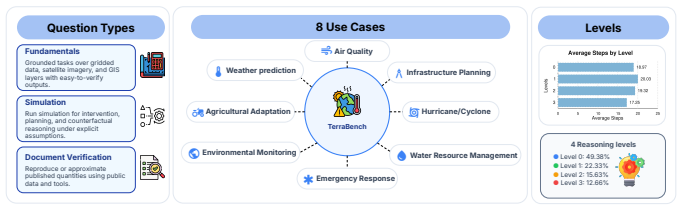
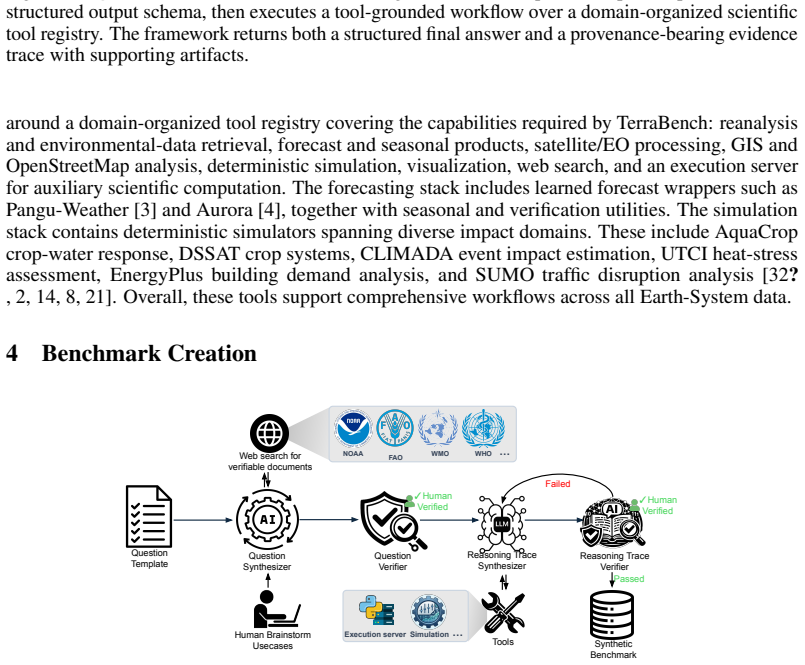
Climate and environmental decision-making increasingly requires reasoning across heterogeneous inputs, including gridded physical data, satellite imagery, geospatial context, and simulator outputs. Weather and climate foundation models can forecast well, but do not reason interactively in language, while large language models (LLMs) reason in language but cannot operate directly on high-dimensional Earth-system data. As a result, real scientific workflows in Earth-science remain underserved. We introduce TerraBench, a benchmark for grounded Earth-science reasoning, built on TerraAgent, a ReAct-style executable framework that interleaves reasoning, tool calls, and observations to couple LLM planning with scientific tools for environmental retrieval, geospatial processing, simulation, and artifact-backed computation. TerraBench unifies analysis of Earth observation imagery, gridded data, GIS reasoning and simulation in a single executable interface, whereas prior benchmarks isolate these capabilities into narrow individual tasks. It is also the first in this space to pair process-level tool-use metrics with tolerance-aware numeric scoring. The benchmark comprises 403 extensive agentic tasks across three tracks (Fundamentals, Simulator-Grounded, and Document-Grounded Verification) and eight application domains with 24,500 verified execution steps. These results indicate that reliable Earth-science agents must go beyond tool access to coordinate heterogeneous workflows, parameterize tools precisely, and preserve artifact provenance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TerraBench, a benchmark of 403 agentic tasks across three tracks (Fundamentals, Simulator-Grounded, Document-Grounded Verification) and eight domains, built on the TerraAgent ReAct-style executable framework that interleaves LLM reasoning with tools for Earth observation imagery, gridded data, GIS, and simulation. It claims to be the first to unify these capabilities in one interface and to pair process-level tool-use metrics with tolerance-aware numeric scoring, with 24,500 verified execution steps; the central claim is that reliable Earth-science agents must coordinate heterogeneous workflows, parameterize tools precisely, and preserve artifact provenance.
Significance. If the tasks are representative, the benchmark would usefully identify coordination, parameterization, and provenance as key gaps beyond simple tool access for scientific agents. The work is credited for creating a unified executable interface across heterogeneous Earth-system data types and for being the first to combine process-level tool-use metrics with tolerance-aware numeric scoring.
major comments (2)
- [Abstract] Abstract: the claim that 'these results indicate' that agents must coordinate heterogeneous workflows, parameterize tools precisely, and preserve provenance is unsupported because the abstract provides no quantitative performance metrics, task-level outcomes, or error analysis.
- [Abstract] Abstract: the inference from observed failure modes on the 403 tasks to general requirements for Earth-science agents is load-bearing on task representativeness, yet the abstract supplies no details on task construction, expert validation, or mapping to documented scientific use-cases.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We address the two major comments below and will revise the abstract accordingly to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'these results indicate' that agents must coordinate heterogeneous workflows, parameterize tools precisely, and preserve provenance is unsupported because the abstract provides no quantitative performance metrics, task-level outcomes, or error analysis.
Authors: We agree that the abstract, due to its brevity, does not include the supporting quantitative metrics or error analysis from the full experiments. We will revise the abstract to incorporate key aggregate results (e.g., overall task success rates and the distribution of failure modes across the 24,500 execution steps) to directly support the stated inference. revision: yes
-
Referee: [Abstract] Abstract: the inference from observed failure modes on the 403 tasks to general requirements for Earth-science agents is load-bearing on task representativeness, yet the abstract supplies no details on task construction, expert validation, or mapping to documented scientific use-cases.
Authors: We acknowledge that the abstract does not mention task construction details. While the manuscript body contains dedicated sections on expert validation, domain mapping, and use-case grounding, we will add a concise clause to the abstract noting that tasks were constructed with domain-expert input and aligned to documented Earth-science workflows to better contextualize the representativeness of the observed failure modes. revision: yes
Circularity Check
No circularity: new benchmark and empirical results are self-contained
full rationale
The paper introduces TerraBench and TerraAgent as novel constructs, then reports agent performance across 403 tasks to support the claim that reliable agents require workflow coordination, precise parameterization, and provenance preservation. No equations, fitted parameters, or self-citations are invoked to force this conclusion by construction; the derivation rests on direct execution traces from the newly defined tasks rather than reducing to prior inputs or definitions. The representativeness concern raised by the skeptic is an external-validity issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ReAct-style frameworks can effectively couple LLM planning with scientific tools for heterogeneous Earth-system data processing
invented entities (2)
-
TerraAgent
no independent evidence
-
TerraBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks
Tajamul Ashraf, Amal Saqib, Hanan Ghani, Muhra AlMahri, Yuhao Li, Noor Ahsan, Umair Nawaz, Jean Lahoud, Hisham Cholakkal, Mubarak Shah, et al. Agent-x: Evaluating deep multimodal reasoning in vision-centric agentic tasks.arXiv preprint arXiv:2505.24876, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Climada v1: a global weather and climate risk assessment platform.Geoscientific Model Development, 12(7):3085–3097, 2019
Gabriela Aznar-Siguan and David N Bresch. Climada v1: a global weather and climate risk assessment platform.Geoscientific Model Development, 12(7):3085–3097, 2019
2019
-
[3]
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Pangu-weather: A 3d high-resolution model for fast and accurate global weather forecast.CoRR, abs/2211.02556, 2022
-
[4]
Bruinsma, Ana Lucic, Megan Stanley, Anna Allen, Johannes Brandstetter, Patrick Garvan, Maik Riechert, Jonathan A
Cristian Bodnar, Wessel P. Bruinsma, Ana Lucic, Megan Stanley, Anna Allen, Johannes Brandstetter, Patrick Garvan, Maik Riechert, Jonathan A. Weyn, Haiyu Dong, Jayesh K. Gupta, Kit Thambiratnam, Alexander T. Archibald, Chun-Chieh Wu, Elizabeth Heider, Max Welling, Richard E. Turner, and Paris Perdikaris. A foundation model for the earth system.Nat., 641(80...
2025
-
[5]
Climateiqa: A new dataset and benchmark to advance vision-language models in meteorology anomalies analysis
Jian Chen, Peilin Zhou, Yining Hua, Dading Chong, Meng Cao, Yaowei Li, Wei Chen, Bing Zhu, Junwei Liang, and Zixuan Yuan. Climateiqa: A new dataset and benchmark to advance vision-language models in meteorology anomalies analysis. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, KDD ’25, page 5322–5333, New York...
2025
-
[6]
Terra: A multimodal spatio-temporal dataset spanning the earth.Advances in Neural Information Processing Systems, 37:66329– 66356, 2024
Wei Chen, Xixuan Hao, Yuankai Wu, and Yuxuan Liang. Terra: A multimodal spatio-temporal dataset spanning the earth.Advances in Neural Information Processing Systems, 37:66329– 66356, 2024
2024
-
[7]
A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
Jacob Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
1960
-
[8]
Energyplus: creating a new-generation building energy simulation program.Energy and buildings, 33(4):319–331, 2001
Drury B Crawley, Linda K Lawrie, Frederick C Winkelmann, Walter F Buhl, Y Joe Huang, Curtis O Pedersen, Richard K Strand, Richard J Liesen, Daniel E Fisher, Michael J Witte, et al. Energyplus: creating a new-generation building energy simulation program.Energy and buildings, 33(4):319–331, 2001
2001
-
[9]
Ellen H Davenport, J Varan Madan, Rebecca Gjini, Jared Brzenski, Nick Ho, Tien-Yiao Hsu, Yueshan Liang, Zhixing Liu, Veeramakali Manivannan, Eric Pham, et al. Jcm v1. 0: A differentiable, intermediate-complexity atmospheric model.EGUsphere, 2026:1–20, 2026
2026
-
[10]
Peilin Feng, Zhutao Lv, Junyan Ye, Xiaolei Wang, Xinjie Huo, Jinhua Yu, Wanghan Xu, Wenlong Zhang, Lei Bai, Conghui He, and Weijia Li. Earth-agent: Unlocking the full landscape of earth observation with agents.CoRR, abs/2509.23141, 2025
-
[11]
Agentscope: A flexible yet robust multi-agent platform.arXiv preprint arXiv:2402.14034, 2024
Dawei Gao, Zitao Li, Xuchen Pan, Weirui Kuang, Zhijian Ma, Bingchen Qian, Fei Wei, Wenhao Zhang, Yuexiang Xie, Daoyuan Chen, et al. Agentscope: A flexible yet robust multi-agent platform.arXiv preprint arXiv:2402.14034, 2024
-
[12]
Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11143–11156, 2024. 10
2024
-
[13]
Ahmed Jaber, Wangshu Zhu, Ayon Roy, Karthick Jayavelu, Justin Downes, Sameer Mohamed, Candace Agonafir, Linnia Hawkins, and Tian Zheng. Autoclimds: Climate data science agentic ai–a knowledge graph is all you need.arXiv preprint arXiv:2509.21553, 2025
-
[14]
Utci—why another thermal index? International journal of biometeorology, 56(3):421–428, 2012
Gerd Jendritzky, Richard De Dear, and George Havenith. Utci—why another thermal index? International journal of biometeorology, 56(3):421–428, 2012
2012
-
[15]
Towards llm agents for earth observation.arXiv preprint arXiv:2504.12110, 2025
Chia Hsiang Kao, Wenting Zhao, Shreelekha Revankar, Samuel Speas, Snehal Bhagat, Rajeev Datta, Cheng Perng Phoo, Utkarsh Mall, Carl V ondrick, Kavita Bala, et al. Towards llm agents for earth observation.arXiv preprint arXiv:2504.12110, 2025
-
[16]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 881–905, 2024
2024
-
[17]
Geobenchx: Benchmarking llms in agent solving multistep geospatial tasks
Varvara Krechetova and Denis Kochedykov. Geobenchx: Benchmarking llms in agent solving multistep geospatial tasks. InProceedings of the 1st ACM SIGSPATIAL International Workshop on Generative and Agentic AI for Multi-Modality Space-Time Intelligence, pages 27–35, 2025
2025
-
[18]
CLLMate: A multimodal benchmark for weather and climate events forecasting
Haobo Li, Zhaowei Wang, Jiachen Wang, Yueya Wang, Alexis Kai Hon Lau, and Huamin Qu. CLLMate: A multimodal benchmark for weather and climate events forecasting. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17536– 1756...
2025
-
[19]
Api-bank: A comprehensive benchmark for tool-augmented llms
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. Api-bank: A comprehensive benchmark for tool-augmented llms. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 3102–3116, 2023
2023
-
[20]
ollamar: An r package for running large language models.Journal of Open Source Software, 10(105):7211, jan 2025
Hause Lin and Tawab Safi. ollamar: An r package for running large language models.Journal of Open Source Software, 10(105):7211, jan 2025
2025
-
[21]
Microscopic traffic simulation using sumo
Pablo Alvarez Lopez, Michael Behrisch, Laura Bieker-Walz, Jakob Erdmann, Yun-Pang Flöt- teröd, Robert Hilbrich, Leonhard Lücken, Johannes Rummel, Peter Wagner, and Evamarie Wiessner. Microscopic traffic simulation using sumo. In2018 21st International Conference on Intelligent Transportation Systems (ITSC), pages 2575–2582, 2018
2018
-
[22]
Chengqian Ma, Zhanxiang Hua, Alexandra Anderson-Frey, Vikram Iyer, Xin Liu, and Lianhui Qin. Weatherqa: Can multimodal language models reason about severe weather?arXiv preprint arXiv:2406.11217, 2024
-
[23]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[24]
Deepak Nathani, Lovish Madaan, Nicholas Roberts, Nikolay Bashlykov, Ajay Menon, Vin- cent Moens, Amar Budhiraja, Despoina Magka, Vladislav V orotilov, Gaurav Chaurasia, et al. Mlgym: A new framework and benchmark for advancing ai research agents.arXiv preprint arXiv:2502.14499, 2025
-
[25]
Scaling transformer neural networks for skillful and reliable medium-range weather forecasting.Advances in Neural Information Processing Systems, 37:68740–68771, 2024
Tung Nguyen, Rohan Shah, Hritik Bansal, Troy Arcomano, Romit Maulik, Rao Kotamarthi, Ian Foster, Sandeep Madireddy, and Aditya Grover. Scaling transformer neural networks for skillful and reliable medium-range weather forecasting.Advances in Neural Information Processing Systems, 37:68740–68771, 2024
2024
-
[26]
Cambridge University Press, 2 edition, 2009
Judea Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2 edition, 2009
2009
-
[27]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Akashah Shabbir, Muhammad Akhtar Munir, Akshay Dudhane, Muhammad Umer Sheikh, Muhammad Haris Khan, Paolo Fraccaro, Juan Bernabe Moreno, Fahad Shahbaz Khan, and Salman Khan. Thinkgeo: Evaluating tool-augmented agents for remote sensing tasks.arXiv preprint arXiv:2505.23752, 2025
-
[29]
Akashah Shabbir, Muhammad Umer Sheikh, Muhammad Akhtar Munir, Hiyam Debary, Mus- tansar Fiaz, Muhammad Zaigham Zaheer, Paolo Fraccaro, Fahad Shahbaz Khan, Muham- mad Haris Khan, Xiao Xiang Zhu, et al. Openearthagent: A unified framework for tool- augmented geospatial agents.arXiv preprint arXiv:2602.17665, 2026
-
[30]
GCA Framework: A GCC Countries-Grounded Dataset and Agentic Pipeline for Climate Decision Support
Muhammad Umer Sheikh, Khawar Shehzad, Salman Khan, Fahad Shahbaz Khan, and Muham- mad Haris Khan. Gca framework: A gcc countries-grounded dataset and agentic pipeline for climate decision support.arXiv preprint arXiv:2604.12306, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
2023
-
[32]
Aquacrop—the fao crop model to simulate yield response to water: I
Pasquale Steduto, Theodore C Hsiao, Dirk Raes, and Elias Fereres. Aquacrop—the fao crop model to simulate yield response to water: I. concepts and underlying principles.Agronomy journal, 101(3):426–437, 2009
2009
-
[33]
Shuo Tang, Jiadong Zhang, Jian Xu, Gengxian Zhou, Qizhao Jin, Qinxuan Wang, Yi Hu, Ning Hu, Hongchang Ren, Lingli He, et al. Hvr-met: A hypothesis-verification-replaning agentic system for extreme weather diagnosis.arXiv preprint arXiv:2603.01121, 2026
-
[34]
Zephyrus: An agentic framework for weather science.arXiv preprint arXiv:2510.04017, 2025
Sumanth Varambally, Marshall Fisher, Jas Thakker, Yiwei Chen, Zhirui Xia, Yasaman Jafari, Ruijia Niu, Manas Jain, Veeramakali Vignesh Manivannan, Zachary Novack, et al. Zephyrus: An agentic framework for weather science.arXiv preprint arXiv:2510.04017, 2025
-
[35]
Gta: a benchmark for general tool agents.Advances in Neural Information Processing Systems, 37:75749–75790, 2024
Jize Wang, Zerun Ma, Yining Li, Songyang Zhang, Cailian Chen, Kai Chen, and Xinyi Le. Gta: a benchmark for general tool agents.Advances in Neural Information Processing Systems, 37:75749–75790, 2024
2024
-
[36]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models.arXiv preprint arXiv:2303.04671, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Aoran Xiao, Shihao Cheng, Yonghao Xu, Yexian Ren, Hongruixuan Chen, and Naoto Yokoya. Geommbench and geommagent: Toward expert-level multimodal intelligence in geoscience and remote sensing.arXiv preprint arXiv:2604.08896, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action.arXiv preprint arXiv:2303.11381, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[40]
TerraBench: Can Agents Reason Over Heterogeneous Earth-System Data?
YuhangYan, Lichao Mou, bokang yang, and QINGYU LI. Hierarchies over pixels: A benchmark for cognitive geospatial reasoning for agents, 2026. 12 Supplementary Material “TerraBench: Can Agents Reason Over Heterogeneous Earth-System Data?” This supplement provides additional details on the TerraAgent framework (Appendix A), benchmark construction (Appendix B...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.