WHAR Arena: Benchmarking the State of the Art in Efficient Wearable Human Activity Recognition
Pith reviewed 2026-06-27 07:07 UTC · model grok-4.3
The pith
Standardized benchmark of 17 models on 30 datasets shows wearable activity recognition performance has plateaued while efficiency trade-offs stay open.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
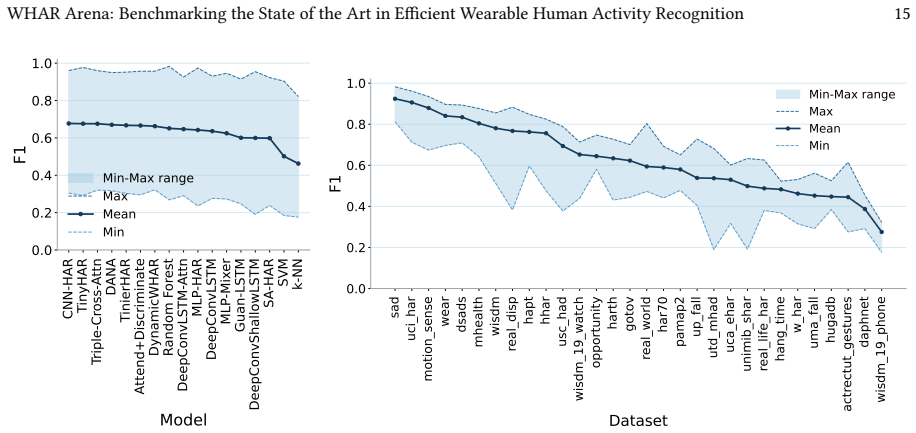
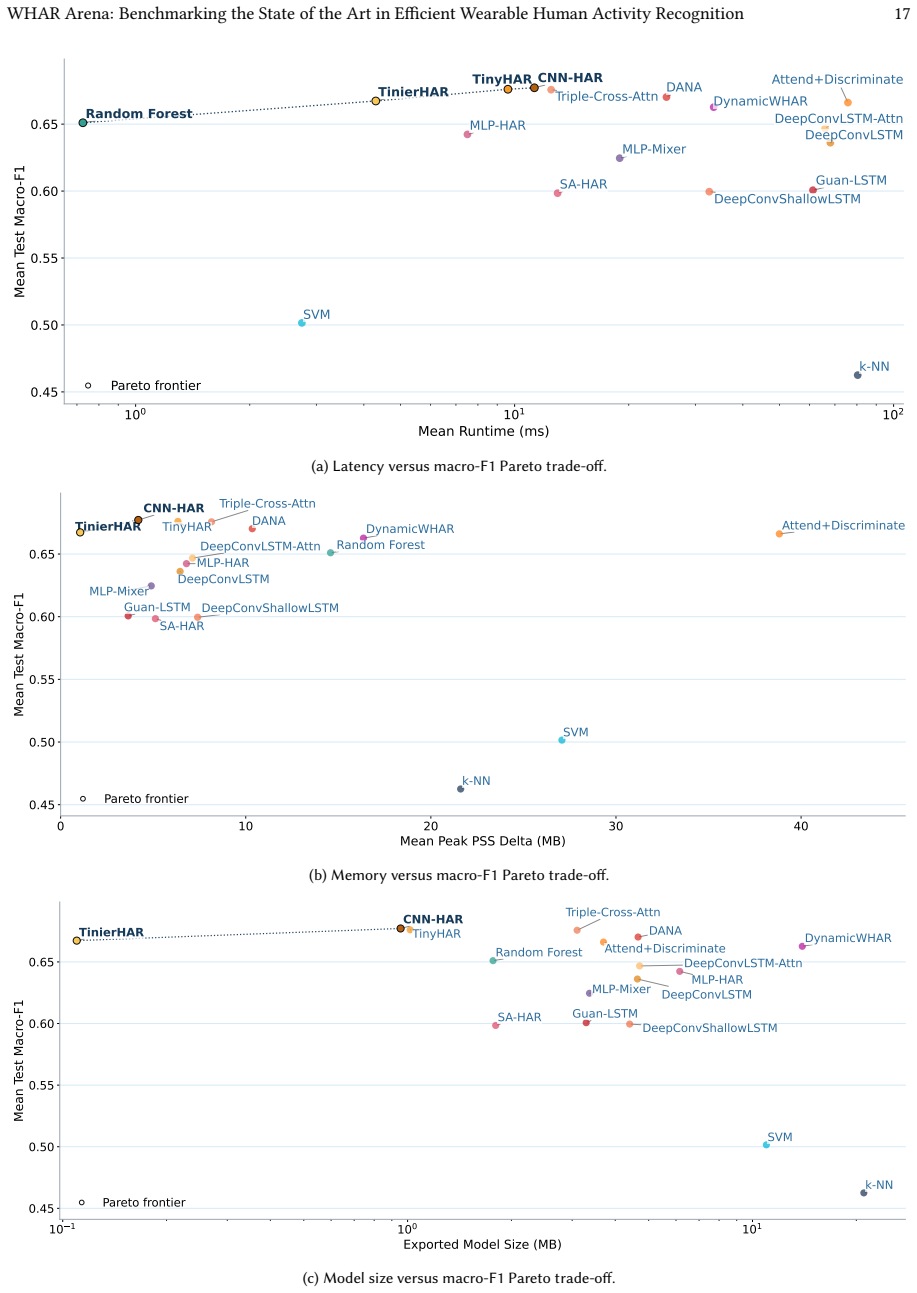
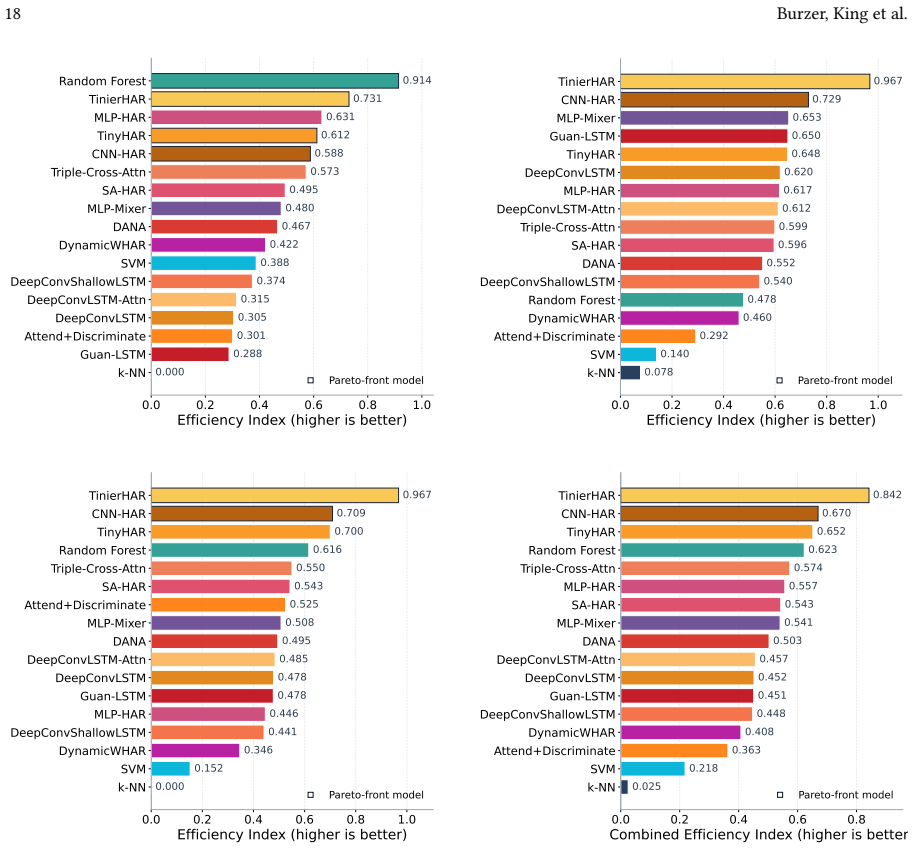
The state of the art in wearable human activity recognition is distributed rather than dominated by a single architecture. CNN-HAR records the highest mean macro-F1, yet top models cluster tightly near a performance ceiling. When deployment costs are considered, compact neural models such as TinierHAR and classical random forests mark the practical Pareto frontier, while larger recurrent and hybrid models incur high hardware costs without matching gains. Consequently, predictive performance has plateaued, but substantial potential remains in optimizing deployment efficiency and improving adaptation to domain shifts.
What carries the argument
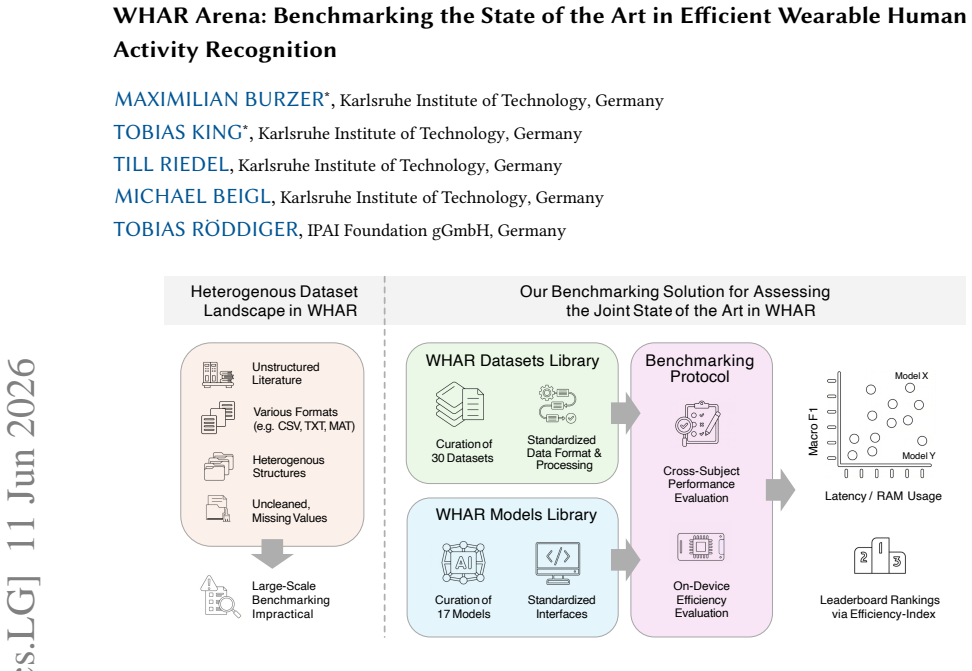
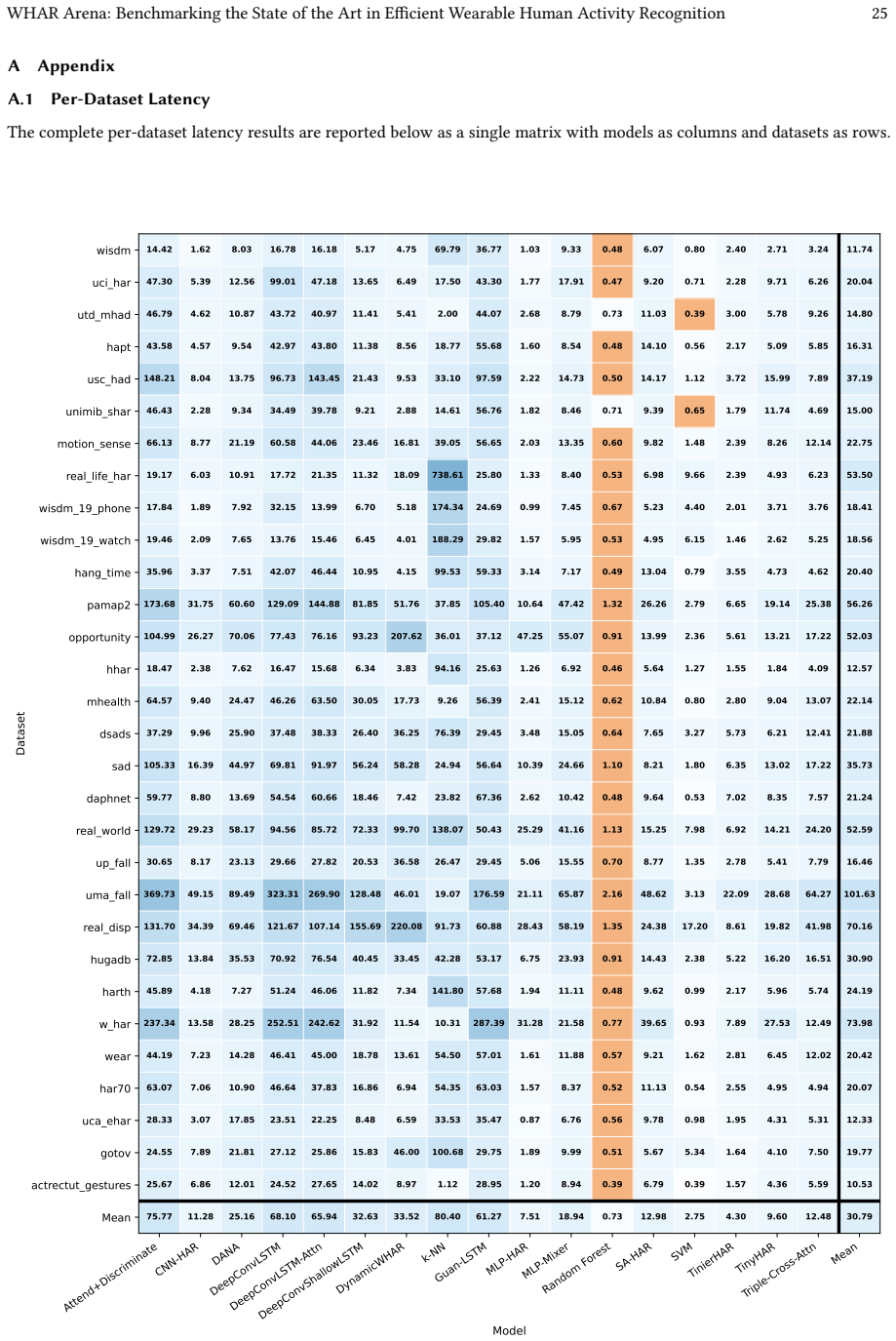
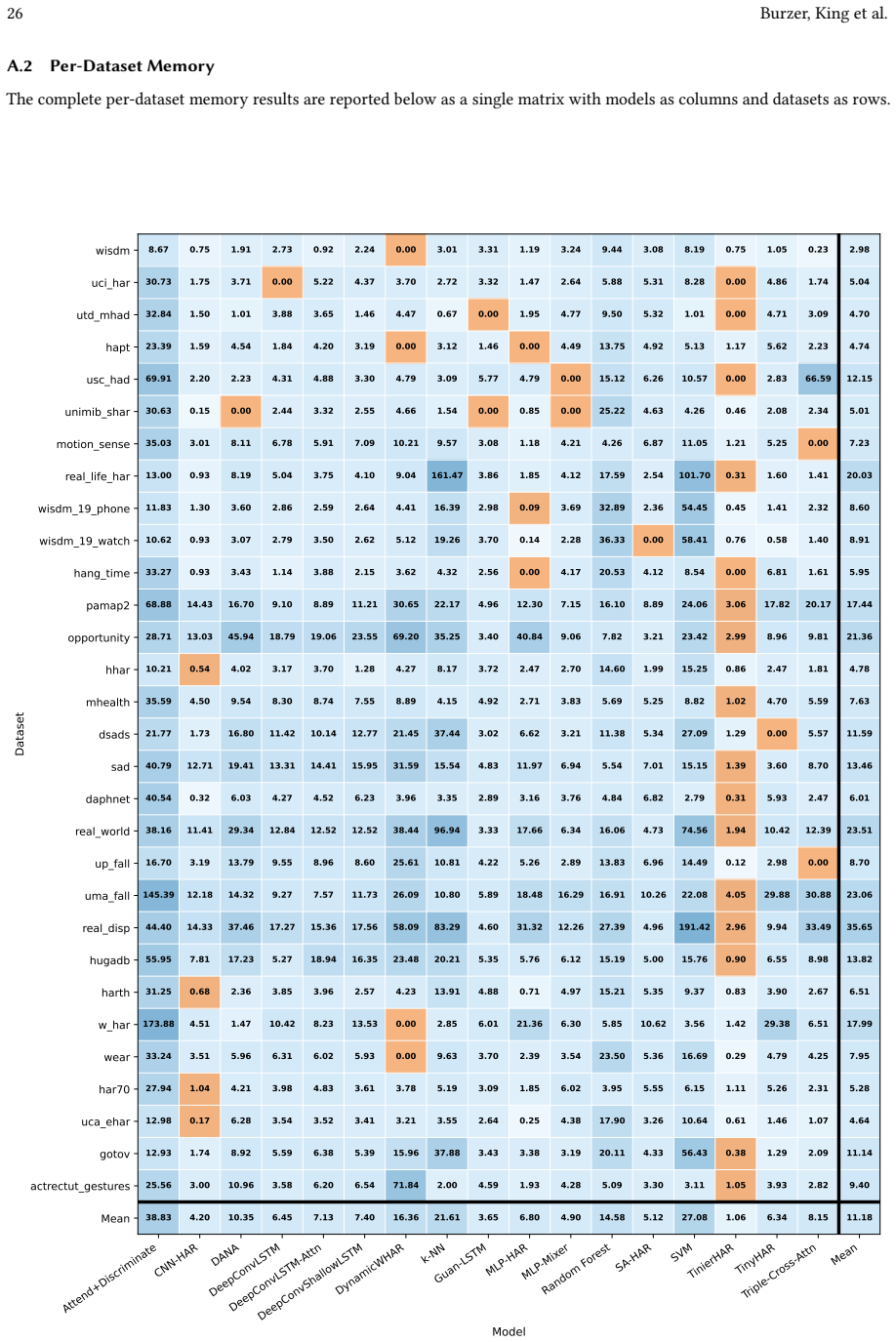
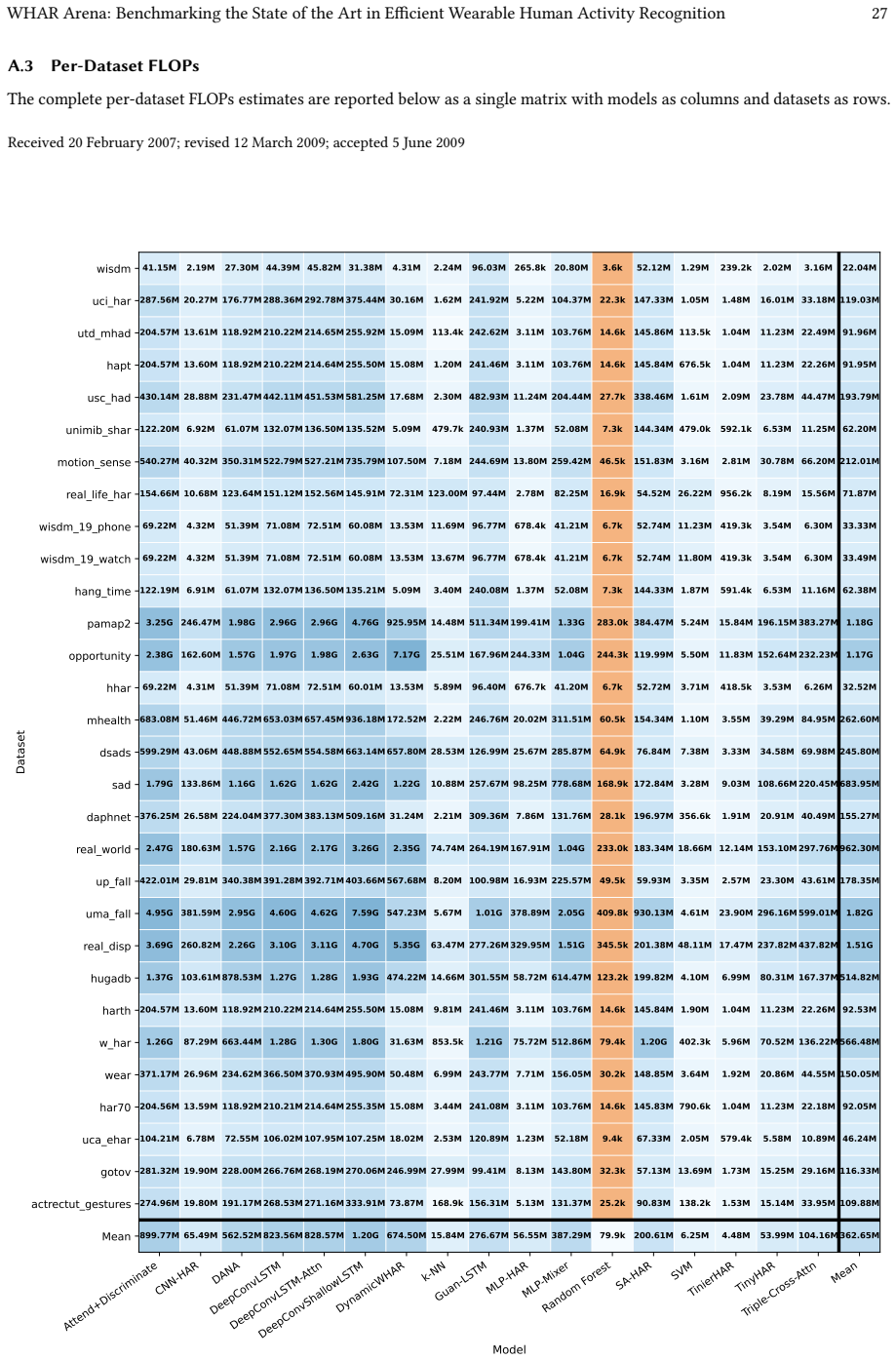
The WHAR Arena benchmark that combines 30 datasets under standardized processing, unified model interfaces, and a shared cross-subject evaluation protocol while jointly measuring predictive performance with on-device latency, peak memory, and model size.
If this is right
- No single architecture dominates predictive performance across the tested datasets.
- Contemporary models have converged near a predictive performance ceiling.
- Compact models such as TinierHAR and random forests define the relevant efficiency-accuracy trade-off.
- Larger recurrent and hybrid models add hardware costs without corresponding accuracy improvements.
- Future gains are more likely from deployment efficiency improvements and domain-shift adaptation than from further accuracy increases.
Where Pith is reading between the lines
- Standardized multi-metric benchmarks could reduce wasted effort on incomparable claims in other sensor-based recognition tasks.
- Hardware measurements taken on a single Android device may understate variation across different wearable processors.
- Releasing the full evaluation framework allows direct addition of new datasets or metrics by other researchers.
- Domain-shift robustness could be tested more explicitly by holding out entire user groups or sensor placements not covered in the current protocol.
Load-bearing premise
The 30 datasets together with the single cross-subject protocol and standardized processing give a representative and unbiased picture of real-world performance.
What would settle it
A new architecture that exceeds the current tight performance cluster by a clear margin in macro-F1 while keeping latency and memory below the compact-model frontier on the same Android reference device would disprove the plateau claim.
Figures

read the original abstract
Deep learning has become the dominant paradigm in Wearable Human Activity Recognition (WHAR), yet progress is obscured by a comparability crisis. Results are often reported using inconsistent datasets, custom data processing, and varying evaluation protocols, making state-of-the-art claims fragile. We address this with a large-scale, open-source benchmark that integrates 30 diverse datasets under standardized processing, unified model interfaces, and a shared cross-subject evaluation protocol. Evaluating 17 representative architectures across 4760 training runs, we jointly measure predictive performance alongside on-device latency, peak memory, and model size on an Android reference device. Our results reveal that the WHAR state of the art is distributed rather than dominated by a single architecture. While CNN-HAR achieves the highest mean macro-F1, top-performing models cluster tightly, indicating contemporary architectures have converged near a predictive performance ceiling. When accounting for deployment efficiency, compact neural models, such as TinierHAR, and classical Random Forests define the practically relevant Pareto frontier, whereas larger recurrent and hybrid models incur high hardware costs without corresponding performance gains. Consequently, while predictive performance has plateaued, substantial potential for future progress remains in optimizing deployment efficiency and improving adaptation to domain shifts. We release our full framework to support transparent reuse and extension.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WHAR Arena, a large-scale benchmark integrating 30 diverse datasets under standardized processing and a unified cross-subject evaluation protocol. It evaluates 17 representative architectures across 4760 training runs, jointly measuring predictive performance (macro-F1) alongside on-device latency, peak memory, and model size on an Android reference device. Results show that top models (e.g., CNN-HAR) cluster tightly with no single dominant architecture, compact models like TinierHAR and Random Forests define the Pareto frontier for efficiency, and larger recurrent/hybrid models incur high hardware costs without proportional gains. The central claim is that predictive performance has plateaued while substantial progress remains possible in deployment efficiency and domain-shift adaptation; the full framework is released open-source.
Significance. If the benchmark protocol and results hold, this addresses the comparability crisis in WHAR by establishing a reusable, standardized evaluation framework at a scale (4760 runs) that enables direct comparison of accuracy and hardware metrics. The open-source release and focus on practical Pareto trade-offs are strengths that could guide future work away from accuracy-only optimization. The empirical nature with direct measurements (no circular derivations) adds to its utility as a reference.
major comments (2)
- [Abstract and §4 (Results)] Abstract and §4 (Results): the claim that top-performing models 'cluster tightly' and have 'converged near a predictive performance ceiling' is load-bearing for the plateau conclusion, yet no variance measures, confidence intervals, or statistical tests (e.g., paired t-tests or ANOVA across the 4760 runs) are reported to confirm that differences between CNN-HAR and other top models are insignificant.
- [§3 (Methods/Datasets)] §3 (Methods/Datasets): the unified cross-subject protocol and selection of the 30 datasets are central to the generalizability of both the plateau and Pareto-frontier claims, but details on data exclusion rules, inclusion criteria, and verification that the protocol avoids bias across domains are insufficient to fully assess representativeness.
minor comments (2)
- [Abstract] Abstract: specify how macro-F1 is aggregated (per-dataset then averaged, or pooled) and whether class imbalance handling is uniform across all 30 datasets.
- [Figures/Tables] Figure/Table captions (throughout): ensure all hardware metrics explicitly reference the Android device model and measurement methodology for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the statistical support for our claims and the transparency of our dataset protocol. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] Abstract and §4 (Results): the claim that top-performing models 'cluster tightly' and have 'converged near a predictive performance ceiling' is load-bearing for the plateau conclusion, yet no variance measures, confidence intervals, or statistical tests (e.g., paired t-tests or ANOVA across the 4760 runs) are reported to confirm that differences between CNN-HAR and other top models are insignificant.
Authors: We agree that variance measures and statistical tests would strengthen the evidence for the tight clustering of top models and the plateau conclusion. In the revised manuscript, we will report standard deviations across the multiple training runs for macro-F1 scores of the top models, include confidence intervals where appropriate, and add results from paired statistical tests (e.g., paired t-tests or Wilcoxon signed-rank tests) comparing CNN-HAR against other leading models to assess whether differences are statistically insignificant. These additions will be placed in §4 and referenced in the abstract. revision: yes
-
Referee: [§3 (Methods/Datasets)] §3 (Methods/Datasets): the unified cross-subject protocol and selection of the 30 datasets are central to the generalizability of both the plateau and Pareto-frontier claims, but details on data exclusion rules, inclusion criteria, and verification that the protocol avoids bias across domains are insufficient to fully assess representativeness.
Authors: We acknowledge that expanded details on dataset curation and protocol safeguards would better allow readers to evaluate representativeness. In the revised §3, we will add explicit inclusion criteria (e.g., minimum subject count, sensor types, activity granularity), data exclusion rules applied during standardization (e.g., removal of incomplete recordings or incompatible label sets), and additional verification steps such as domain coverage analysis and checks for protocol-induced bias across sensor modalities and populations. A new table or subsection will summarize these criteria. revision: yes
Circularity Check
No significant circularity identified
full rationale
This paper is a purely empirical benchmark reporting direct measurements of accuracy, latency, memory, and model size across 17 architectures and 30 datasets under a fixed protocol. No derivations, equations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described methodology. The central claims (performance plateau, efficiency Pareto frontier) follow from observed experimental outcomes rather than reducing to inputs by construction. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected 30 datasets and unified cross-subject protocol fairly represent real-world WHAR variability
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Rajat Monga, Sherry Moore, Derek Murray, Chr...
2015
-
[2]
Reem Abdel-Salam, Rana Mostafa, and Mayada Hadhood. 2021. Human Activity Recognition using Wearable Sensors: Review, Challenges, Evaluation Benchmark. Vol. 1370. 1–15. doi:10.1007/978-981-16-0575-8_1 arXiv:2101.01665 [cs]
-
[3]
Alireza Abedin, Mahsa Ehsanpour, Qinfeng Shi, Hamid Rezatofighi, and Damith C. Ranasinghe. 2021. Attend and Discriminate: Beyond the State-of-the-Art for Human Activity Recognition Using Wearable Sensors. (2021). doi:10.1145/3448083 WHAR Arena: Benchmarking the State of the Art in Efficient Wearable Human Activity Recognition 21
-
[4]
Gulzar Alam, Ian McChesney, Peter Nicholl, and Joseph Rafferty. 2023. Open Datasets in Human Activity Recognition Research—Issues and Challenges: A Review.IEEE Sensors Journal23, 22 (Nov. 2023), 26952–26980. doi:10.1109/jsen.2023.3317645 Publisher: Institute of Electrical and Electronics Engineers (IEEE)
-
[5]
Kerem Altun, Billur Barshan, and Orkun Tunçel. 2010. Comparative study on classifying human activities with miniature inertial and magnetic sensors. Pattern Recognition43, 10 (Oct. 2010), 3605–3620. doi:10.1016/j.patcog.2010.04.019
-
[6]
Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra, and Jorge L Reyes-Ortiz. 2013. A Public Domain Dataset for Human Activity Recognition Using Smartphones.Computational Intelligence(2013)
2013
-
[7]
Kjærnli, Sverre Herland, Aleksej Logacjov, and Paul Jarle Mork
Kerstin Bach, Atle Kongsvold, Hilde Bårdstu, Ellen Marie Bardal, Håkon S. Kjærnli, Sverre Herland, Aleksej Logacjov, and Paul Jarle Mork. 2022. A Machine Learning Classifier for Detection of Physical Activity Types and Postures During Free-Living.Journal for the Measurement of Physical Behaviour5, 1 (March 2022), 24–31. doi:10.1123/jmpb.2021-0015
-
[8]
2014.mHealthDroid: A Novel Framework for Agile Development of Mobile Health Applications
Oresti Banos, Rafael García, Juan Holgado-Terriza, Miguel Damas, Hector Pomares, Ignacio Rojas, and Alejandro Saez. 2014.mHealthDroid: A Novel Framework for Agile Development of Mobile Health Applications. Vol. 8868. doi:10.1007/978-3-319-13105-4_14 Pages: 98
-
[9]
Oresti Banos, Mate Toth, Miguel Damas, Hector Pomares, and Ignacio Rojas. 2014. Dealing with the Effects of Sensor Displacement in Wearable Activity Recognition.Sensors14, 6 (June 2014), 9995–10023. doi:10.3390/s140609995
-
[10]
Ganapati Bhat, Nicholas Tran, Holly Shill, and Umit Y. Ogras. 2020. w-HAR: An Activity Recognition Dataset and Framework Using Low-Power Wearable Devices.Sensors20, 18 (Sept. 2020), 5356. doi:10.3390/s20185356
-
[11]
Sizhen Bian, Mengxi Liu, Vitor Fortes Rey, Daniel Geißler, and Paul Lukowicz. 2025. TinierHAR: Towards Ultra-Lightweight Deep Learning Models for Efficient Human Activity Recognition on Edge Devices. InProceedings of the 2025 ACM International Symposium on Wearable Computers (Iswc ’25). Association for Computing Machinery, New York, NY, USA, 163–169. doi:...
-
[12]
Vishwanath Bijalwan, Vijay Bhaskar Semwal, and Vishal Gupta. 2022. Wearable Sensor-Based Pattern Mining for Human Activity Recognition: Deep Learning Approach.Industrial Robot: the international journal of robotics research and application49, 1 (Jan. 2022), 21–33. doi:10.1108/IR-09-2020-0187
-
[13]
Marius Bock, Alexander Hölzemann, Michael Moeller, and Kristof Van Laerhoven. 2021. Improving deep learning for HAR with shallow LSTMs. In Proceedings of the 2021 ACM International Symposium on Wearable Computers. 7–12
2021
-
[14]
Marius Bock, Hilde Kuehne, Kristof Van Laerhoven, and Michael Moeller. 2024. WEAR: An Outdoor Sports Dataset for Wearable and Egocentric Activity Recognition.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.8, 4 (Nov. 2024), 175:1–175:21. doi:10.1145/3699776
-
[15]
Andreas Bulling, Ulf Blanke, and Bernt Schiele. 2014. A tutorial on human activity recognition using body-worn inertial sensors.ACM Computing Surveys (CSUR)46, 3 (2014), 1–33
2014
-
[16]
Maximilian Burzer, Tobias King, Till Riedel, Michael Beigl, and Tobias Röddiger. 2025. WHAR Datasets: An Open Source Library for Wearable Human Activity Recognition. InCompanion of the 2025 ACM International Joint Conference on Pervasive and Ubiquitous Computing. 1315–1322
2025
-
[17]
Eduardo Casilari, Jose A. Santoyo-Ramón, and Jose M. Cano-García. 2017. UMAFall: A Multisensor Dataset for the Research on Automatic Fall Detection. Procedia Computer Science110 (2017), 32–39. doi:10.1016/j.procs.2017.06.110
-
[18]
Shing Chan, Yuan Hang, Catherine Tong, Aidan Acquah, Abram Schonfeldt, Jonathan Gershuny, and Aiden Doherty. 2024. CAPTURE-24: A large dataset of wrist-worn activity tracker data collected in the wild for human activity recognition.Scientific Data11, 1 (Oct. 2024), 1135. doi:10.1038/s41597-024-03960-3
-
[19]
Chen Chen, Roozbeh Jafari, and Nasser Kehtarnavaz. 2015. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In2015 IEEE International Conference on Image Processing (ICIP). 168–172. doi:10.1109/ICIP.2015.7350781
-
[20]
Kaixuan Chen, Dalin Zhang, Lina Yao, Bin Guo, Zhiwen Yu, and Yunhao Liu. 2021. Deep Learning for Sensor-based Human Activity Recognition: Overview, Challenges, and Opportunities.ACM Comput. Surv.54, 4 (May 2021), 77:1–77:40. doi:10.1145/3447744
-
[21]
Roman Chereshnev and Attila Kertesz-Farkas. 2017. HuGaDB: Human Gait Database for Activity Recognition from Wearable Inertial Sensor Networks. doi:10.48550/arXiv.1705.08506 arXiv:1705.08506 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1705.08506 2017
-
[22]
Stefano Chessa and Stefan Knauth. 2012. Evaluating AAL systems through competitive benchmarking.Proc. Evaluating AAL Systems Through Competitive Benchmarking. Indoor Localization and Tracking309 (2012), 1–13
2012
-
[23]
Maximilian Christ, Nils Braun, Julius Neuffer, and Andreas W Kempa-Liehr. 2018. Time series feature extraction on basis of scalable hypothesis tests (tsfresh–a python package).Neurocomputing307 (2018), 72–77
2018
-
[24]
Mathias Ciliberto, Vitor Fortes Rey, Alberto Calatroni, Paul Lukowicz, and Daniel Roggen. 2021. Opportunity++: A Multimodal Dataset for Video- and Wearable, Object and Ambient Sensors-Based Human Activity Recognition.Frontiers in Computer Science3 (Dec. 2021), 792065. doi:10.3389/fcomp.2021. 792065
-
[25]
Dima Damen. 2014. Scaling Egocentric Vision: The EPIC-KITCHENS Dataset. (2014)
2014
-
[26]
Anindya Das Antar, Masud Ahmed, and Md Atiqur Rahman Ahad. 2019.Challenges in Sensor-based Human Activity Recognition and a Comparative Analysis of Benchmark Datasets: A Review. 139 pages. doi:10.1109/ICIEV.2019.8858508
-
[27]
Emiro De-La-Hoz-Franco, Paola Ariza-Colpas, Javier Medina Quero, and Macarena Espinilla. 2018. Sensor-Based Datasets for Human Activity Recognition – A Systematic Review of Literature.IEEE Access6 (2018), 59192–59210. doi:10.1109/ACCESS.2018.2873502
-
[28]
Joseph DelPreto, Chao Liu, Yiyue Luo, Michael Foshey, Yunzhu Li, Antonio Torralba, Wojciech Matusik, and Daniela Rus. [n. d.]. ActionSense: A Multimodal Dataset and Recording Framework for Human Activities Using Wearable Sensors in a Kitchen Environment. ([n. d.])
-
[29]
Angus Dempster, Navid Mohammadi Foumani, Chang Wei Tan, Lynn Miller, Amish Mishra, Mahsa Salehi, Charlotte Pelletier, Daniel F. Schmidt, and Geoffrey I. Webb. 2025. MONSTER: Monash Scalable Time Series Evaluation Repository. doi:10.48550/arXiv.2502.15122 arXiv:2502.15122 [cs]
-
[30]
Florenc Demrozi, Graziano Pravadelli, Azra Bihorac, and Parisa Rashidi. 2020. Human Activity Recognition Using Inertial, Physiological and Environmental Sensors: A Comprehensive Survey.IEEE Access8 (2020), 210816–210836. doi:10.1109/ACCESS.2020.3037715
-
[31]
Daniel Garcia-Gonzalez, Daniel Rivero, Enrique Fernandez-Blanco, and Miguel R. Luaces. 2020. A Public Domain Dataset for Real-Life Human Activity Recognition Using Smartphone Sensors.Sensors20, 8 (April 2020), 2200. doi:10.3390/s20082200
-
[32]
Daniel Geissler, Dominique Nshimyimana, Vitor Fortes Rey, Sungho Suh, Bo Zhou, and Paul Lukowicz. 2024. Beyond Confusion: A Fine-grained Dialectical Examination of Human Activity Recognition Benchmark Datasets. arXiv:2412.09037 [cs] doi:10.48550/arXiv.2412.09037
-
[33]
Hristijan Gjoreski, Mathias Ciliberto, Lin Wang, Francisco Javier Ordonez Morales, Sami Mekki, Stefan Valentin, and Daniel Roggen. 2018. The University of Sussex-Huawei Locomotion and Transportation Dataset for Multimodal Analytics With Mobile Devices.IEEE Access6 (2018), 42592–42604. doi:10.1109/ACCESS.2018.2858933
-
[34]
Xingyu Gong, Xinyang Zhang, and Na Li. 2024. Lightweight Human Activity Recognition Method Based on the MobileHARC Model.Systems Science & Control Engineering12, 1 (Dec. 2024), 2328549. doi:10.1080/21642583.2024.2328549
-
[35]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. 2022. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18995–19012. 22 Burzer, King et al
2022
-
[36]
Fuqiang Gu, Mu-Huan Chung, Mark Chignell, Shahrokh Valaee, Baoding Zhou, and Xue Liu. 2021. A Survey on Deep Learning for Human Activity Recognition.ACM Comput. Surv.54, 8 (Oct. 2021), 177:1–177:34. doi:10.1145/3472290
-
[37]
Yu Guan and Thomas Plötz. 2017. Ensembles of Deep LSTM Learners for Activity Recognition Using Wearables.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.1, 2 (June 2017), 11:1–11:28. doi:10.1145/3090076
-
[38]
Moritz Hardt. 2025. The Emerging Science of Machine Learning Benchmarks. Online at https://mlbenchmarks.org. Manuscript
2025
-
[39]
Alexander Hoelzemann, Julia Lee Romero, Marius Bock, Kristof Van Laerhoven, and Qin Lv. 2023. Hang-Time HAR: A Benchmark Dataset for Basketball Activity Recognition Using Wrist-Worn Inertial Sensors.Sensors23, 13 (June 2023), 5879. doi:10.3390/s23135879
-
[40]
Md Meem Hossain, The Anh Han, Safina Showkat Ara, and Zia Ush Shamszaman. 2025. Benchmarking Classical, Deep, and Generative Models for Human Activity Recognition. arXiv:2501.08471 [cs] doi:10.48550/arXiv.2501.08471
-
[41]
Black, Otmar Hilliges, and Gerard Pons-Moll
Yinghao Huang, Manuel Kaufmann, Emre Aksan, Michael J. Black, Otmar Hilliges, and Gerard Pons-Moll. 2018. Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time.ACM Trans. Graph.37, 6 (Dec. 2018), 185:1–185:15. doi:10.1145/3272127.3275108
-
[42]
Yiran Huang, Haibin Zhao, Yexu Zhou, Till Riedel, and Michael Beigl. 2024. Standardizing Your Training Process for Human Activity Recognition Models: A Comprehensive Review in the Tunable Factors. doi:10.48550/arXiv.2401.05477 arXiv:2401.05477 [cs]
-
[43]
Yiran Huang, Yexu Zhou, Haibin Zhao, Till Riedel, and Michael Beigl. 2024. A Survey on Wearable Human Activity Recognition: Innovative Pipeline Development for Enhanced Research and Practice. In2024 International Joint Conference on Neural Networks (IJCNN). 1–10. doi:10.1109/IJCNN60899.2024. 10650060
-
[44]
Jonas Hummel, Tobias Röddiger, Valeria Zitz, Philipp Lepold, Michael Küttner, Marius Prill, Christopher Clarke, Hans Gellersen, and Michael Beigl. 2025. EarXplore: An Open Research Database on Earable Interaction. arXiv:2507.20656 [cs.HC] https://arxiv.org/abs/2507.20656
arXiv 2025
-
[45]
Saurav Jha, Martin Schiemer, Franco Zambonelli, and Juan Ye. 2021. Continual Learning in Sensor-Based Human Activity Recognition: An Empirical Benchmark Analysis.Information Sciences575 (Oct. 2021), 1–21. doi:10.1016/j.ins.2021.04.062
-
[46]
Human Activity Recognition Based on Wearable Sensor Data: A Standardization of the State-of-the-Art
Artur Jordao, Antonio C. Nazare, Jessica Sena, and William Robson Schwartz. 2019. Human Activity Recognition Based on Wearable Sensor Data: A Standardization of the State-of-the-Art. doi:10.48550/arXiv.1806.05226 arXiv:1806.05226 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.05226 2019
-
[47]
Misha Karim, Shah Khalid, Aliya Aleryani, Jawad Khan, Irfan Ullah, and Zafar Ali. 2024. Human Action Recognition Systems: A Review of the Trends and State-of-the-Art.IEEE Access12 (2024), 36372–36390. doi:10.1109/ACCESS.2024.3373199
-
[48]
Nobuo Kawaguchi, Nobuhiro Ogawa, Yohei Iwasaki, Katsuhiko Kaji, Tsutomu Terada, Kazuya Murao, Sozo Inoue, Yoshihiro Kawahara, Yasuyuki Sumi, and Nobuhiko Nishio. 2011. Hasc challenge: gathering large scale human activity corpus for the real-world activity understandings. InProceedings of the 2nd augmented human international conference. 1–5
2011
-
[49]
Quan Kong, Ziming Wu, Ziwei Deng, Martin Klinkigt, Bin Tong, and Tomokazu Murakami. 2019. Mmact: A large-scale dataset for cross modal human action understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8658–8667
2019
-
[50]
Pranjal Kumar, Siddhartha Chauhan, and Lalit Kumar Awasthi. 2024. Human Activity Recognition (HAR) Using Deep Learning: Review, Methodologies, Progress and Future Research Directions.Archives of Computational Methods in Engineering31, 1 (Jan. 2024), 179–219. doi:10.1007/s11831-023-09986-x
-
[51]
Jennifer R. Kwapisz, Gary M. Weiss, and Samuel A. Moore. 2011. Activity recognition using cell phone accelerometers.SIGKDD Explor. Newsl.12, 2 (March 2011), 74–82. doi:10.1145/1964897.1964918
-
[52]
Tianzheng Liao, Jinjin Zhao, Yushi Liu, Kamen Ivanov, Jing Xiong, and Yan Yan. 2022. Deep Transfer Learning with Graph Neural Network for Sensor-Based Human Activity Recognition. In2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). 2445–2452. doi:10.1109/BIBM55620.2022. 9995660
-
[53]
Hui Liu, Yale Hartmann, and Tanja Schultz. 2021. CSL-SHARE: A Multimodal Wearable Sensor-Based Human Activity Dataset.Frontiers in Computer Science3 (Oct. 2021), 759136. doi:10.3389/fcomp.2021.759136
-
[54]
Aleksej Logacjov, Kerstin Bach, Atle Kongsvold, Hilde Bremseth Bårdstu, and Paul Jarle Mork. 2021. HARTH: A Human Activity Recognition Dataset for Machine Learning.Sensors21, 23 (Nov. 2021), 7853. doi:10.3390/s21237853
-
[55]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101(2017)
Pith/arXiv arXiv 2017
-
[56]
Wang Lu, Yao Zhu, and Jindong Wang. 2025. HAROOD: A Benchmark for Out-of-distribution Generalization in Sensor-based Human Activity Recognition. arXiv:2512.10807 [cs] doi:10.48550/arXiv.2512.10807
-
[57]
Tanjid Hasan Tonmoy, Kishor Kumar Bhaumik, A
Saif Mahmud, M. Tanjid Hasan Tonmoy, Kishor Kumar Bhaumik, A. K. M. Mahbubur Rahman, M. Ashraful Amin, Mohammad Shoyaib, Muhammad Asif Hossain Khan, and Amin Ahsan Ali. 2020. Human Activity Recognition from Wearable Sensor Data Using Self-Attention. arXiv:2003.09018 [cs] doi:10.48550/arXiv.2003.09018
-
[58]
Mohammad Malekzadeh, Richard Clegg, Andrea Cavallaro, and Hamed Haddadi. 2021. Dana: Dimension-adaptive neural architecture for multivariate sensor data.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies5, 3 (2021), 1–27
2021
-
[59]
Clegg, Andrea Cavallaro, and Hamed Haddadi
Mohammad Malekzadeh, Richard G. Clegg, Andrea Cavallaro, and Hamed Haddadi. 2019. Mobile sensor data anonymization. InProceedings of the International Conference on Internet of Things Design and Implementation. ACM, Montreal Quebec Canada, 49–58. doi:10.1145/3302505.3310068
-
[60]
Lourdes Martínez-Villaseñor, Hiram Ponce, Jorge Brieva, Ernesto Moya-Albor, José Núñez-Martínez, and Carlos Peñafort-Asturiano. 2019. UP-Fall Detection Dataset: A Multimodal Approach.Sensors19, 9 (April 2019), 1988. doi:10.3390/s19091988
-
[61]
Sakorn Mekruksavanich and Anuchit Jitpattanakul. 2020. Smartwatch-based Human Activity Recognition Using Hybrid LSTM Network. In2020 IEEE SENSORS. 1–4. doi:10.1109/SENSORS47125.2020.9278630
-
[62]
Shenghuan Miao, Ling Chen, Rong Hu, and Yingsong Luo. 2022. Towards a Dynamic Inter-Sensor Correlations Learning Framework for Multi-Sensor-Based Wearable Human Activity Recognition. (2022). doi:10.1145/3550331
-
[63]
Daniela Micucci, Marco Mobilio, and Paolo Napoletano. 2017. UniMiB SHAR: A Dataset for Human Activity Recognition Using Acceleration Data from Smartphones.Applied Sciences7, 10 (Oct. 2017), 1101. doi:10.3390/app7101101
-
[64]
Steven T. Moore, Hamish G. MacDougall, and William G. Ondo. 2008. Ambulatory monitoring of freezing of gait in Parkinson’s disease.Journal of Neuroscience Methods167, 2 (Jan. 2008), 340–348. doi:10.1016/j.jneumeth.2007.08.023
-
[65]
Seyed Ahmadreza Mousavi and Rastko Selmic. 2023. Wearable Smart Rings for Multifinger Gesture Recognition Using Supervised Learning.IEEE Transactions on Instrumentation and Measurement72 (2023), 1–12. doi:10.1109/TIM.2023.3304703
-
[66]
Vishvak S. Murahari and Thomas Plötz. 2018. On Attention Models for Human Activity Recognition. InProceedings of the 2018 ACM International Symposium on Wearable Computers (ISWC ’18). Association for Computing Machinery, New York, NY, USA, 100–103. doi:10.1145/3267242.3267287
-
[67]
Katsuyuki Nakamura, Serena Yeung, Alexandre Alahi, and Li Fei-Fei. 2017. Jointly Learning Energy Expenditures and Activities Using Egocentric Multimodal Signals. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Honolulu, HI, 6817–6826. doi:10.1109/CVPR.2017.721
-
[68]
Otávio Napoli, Dami Duarte, Patrick Alves, Darlinne Hubert Palo Soto, Henrique Evangelista De Oliveira, Anderson Rocha, Levy Boccato, and Edson Borin
-
[69]
A benchmark for domain adaptation and generalization in smartphone-based human activity recognition.Scientific Data11, 1 (Nov. 2024), 1192. doi:10.1038/s41597-024-03951-4 WHAR Arena: Benchmarking the State of the Art in Efficient Wearable Human Activity Recognition 23
-
[70]
Duc-Anh Nguyen and Nhien-An Le-Khac. 2024. SoK: Behind the Accuracy of Complex Human Activity Recognition Using Deep Learning. In2024 International Joint Conference on Neural Networks (IJCNN). 1–8. doi:10.1109/IJCNN60899.2024.10650322
-
[71]
Friedrich Niemann, Fernando Moya Rueda, Moh’d Khier Al Kfari, Nilah Ravi Nair, Stefan Ludtke, and Alice Kirchheim. [n. d.]. Towards Standardized Dataset Creation for Human Activity Recognition: Framework, Taxonomy, Checklist, and Best Practices. ([n. d.])
-
[72]
Pierre-Emmanuel Novac, Alain Pegatoquet, Benoît Miramond, and Christophe Caquineau. 2022. UCA-EHAR: A Dataset for Human Activity Recognition with Embedded AI on Smart Glasses.Applied Sciences12, 8 (April 2022), 3849. doi:10.3390/app12083849
-
[73]
Ferda Ofli, Rizwan Chaudhry, Gregorij Kurillo, René Vidal, and Ruzena Bajcsy. 2013. Berkeley MHAD: A Comprehensive Multimodal Human Action Database. In2013 IEEE Workshop on Applications of Computer Vision (W ACV). 53–60. doi:10.1109/WACV.2013.6474999
-
[74]
Godwin Ogbuabor, Juan Augusto Wrede, Ralph Moseley, and Alechia Van Wyk. 2021. Context-Aware Support for Cardiac Health Monitoring Using Federated Machine Learning. 267–281. doi:10.1007/978-3-030-91100-3_22
-
[75]
Kamsiriochukwu Ojiako and Katayoun Farrahi. 2023. MLPs Are All You Need for Human Activity Recognition.Applied Sciences13, 20 (Oct. 2023). doi:10.3390/app132011154
-
[76]
Francisco Javier Ordóñez and Daniel Roggen. 2016. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition.Sensors16, 1 (2016). doi:10.3390/s16010115
-
[77]
Eline Slagboom, Marian Beekman, and Arno Knobbe
Stylianos Paraschiakos, Cláudio Rebelo De Sá, Jeremiah Okai, P. Eline Slagboom, Marian Beekman, and Arno Knobbe. 2022. A recurrent neural network architecture to model physical activity energy expenditure in older people.Data Mining and Knowledge Discovery36, 1 (Jan. 2022), 477–512. doi:10.1007/s10618-021-00817-w
-
[78]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, High...
2019
-
[79]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-Learn: Machine Learning in Python.Journal of Machine Learning Research12 (2011), 2825–2830
2011
-
[80]
PyTorch. [n. d.]. ExecuTorch. https://github.com/pytorch/executorch. Accessed 2026-05-01
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.