Brick: Spatial Capability Routing for the Mixture-of-Models (MoM) Paradigm
Pith reviewed 2026-06-27 06:54 UTC · model grok-4.3
The pith
Brick routes queries using six capability dimensions plus difficulty to beat the best single model while cutting cost up to 22 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
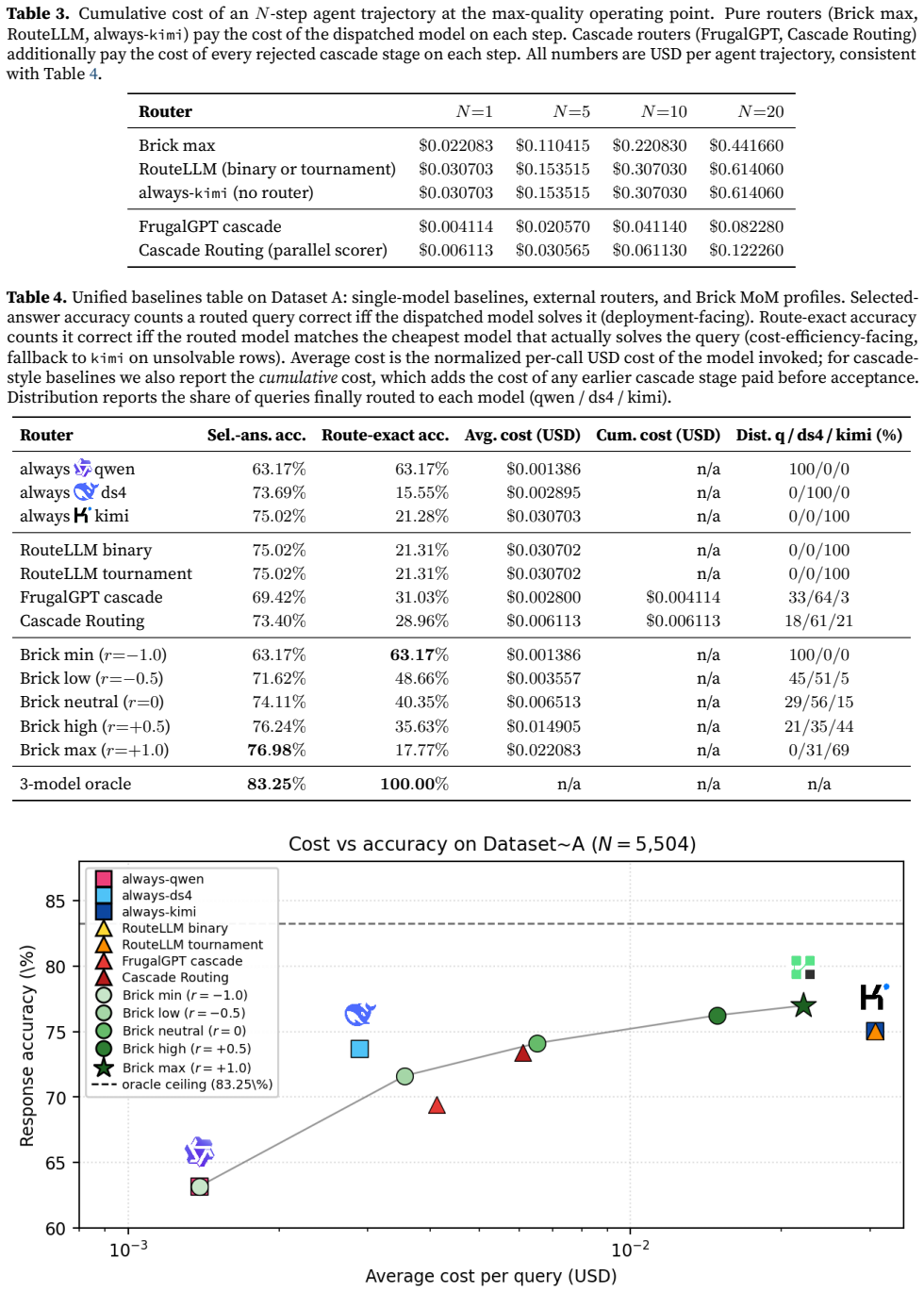
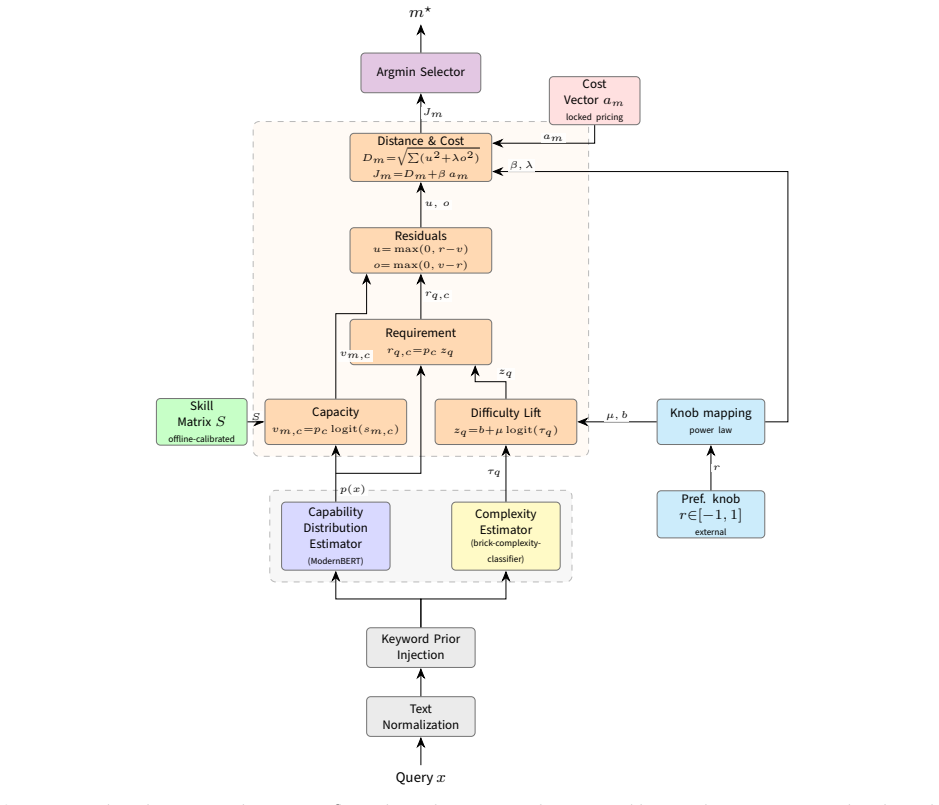
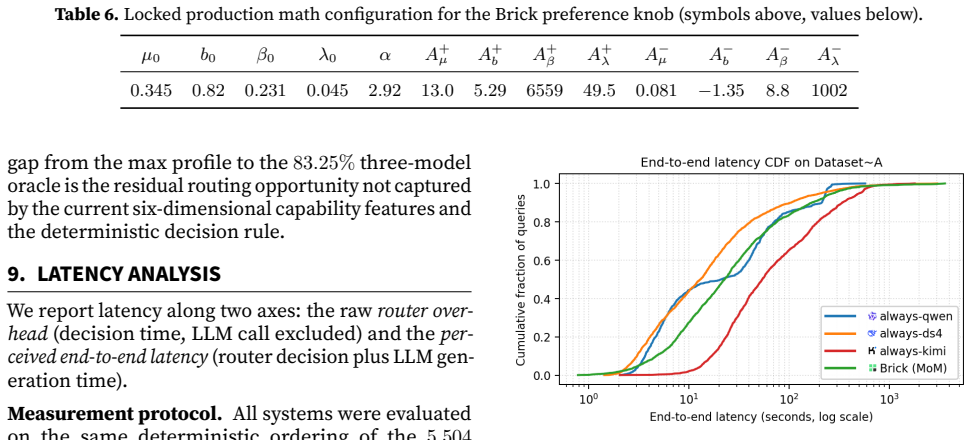
Brick scores each model on six capability dimensions, combines this with a per-query difficulty estimate, and dispatches via a cost-penalized geometric rule. A continuous preference knob lets operators slide between max-quality and max-saving profiles at deploy time. On a benchmark of 5,504 queries, Brick at max-quality reaches 76.98% accuracy, beating the best single model (75.02%) and all tested routers. At a neutral cost-quality profile, Brick achieves 74.11% accuracy at 4.71x lower cost than always using the strongest model. At min-cost, it cuts cost 22.15x with 11.85 points accuracy loss. Median latency drops from 51.2s to 22.8s.
What carries the argument
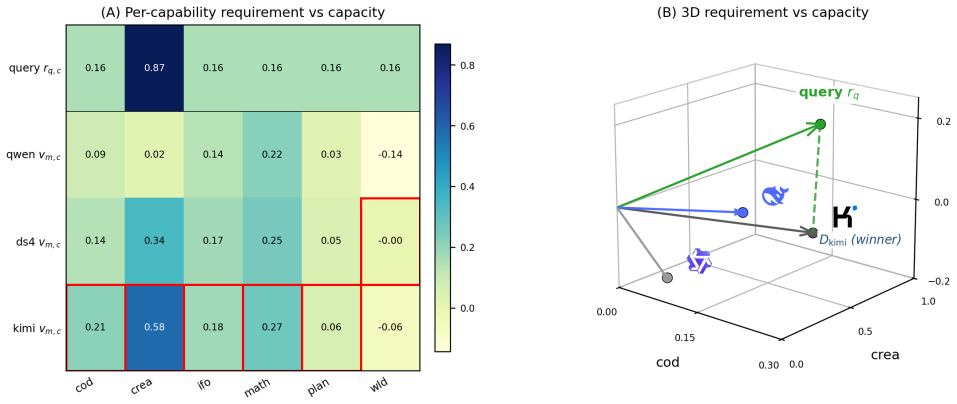
The cost-penalized geometric dispatch rule that operates on six-dimensional capability scores and per-query difficulty estimates.
If this is right
- At the max-quality setting the router exceeds the accuracy of any individual model tested.
- At the neutral setting the same router delivers near-frontier accuracy at roughly one-fifth the cost of the strongest model.
- At the minimum-cost setting cost falls by more than twenty times, with a documented accuracy penalty of 11.85 points.
- Median response latency falls by more than half under the routing policy.
Where Pith is reading between the lines
- The same six-dimensional scoring could be reused to add or retire models without retraining the router.
- If difficulty estimates can be updated online, the router might adapt to shifts in query distribution over time.
- The geometric rule offers a template for adding other constraints such as latency targets or regulatory requirements.
- Operators could expose the preference knob to end users so that cost versus quality choices become per-session decisions.
Load-bearing premise
The six capability dimensions and per-query difficulty estimate can be computed in a way that reliably predicts which model will succeed on unseen queries.
What would settle it
A held-out query set where the model chosen by the six-dimensional scores and difficulty estimate performs worse on average than the strongest single model or a simple baseline router.
Figures
read the original abstract
Defining query difficulty is one of the hardest problems in deployment engineering. Existing LLM routers rely on surface features such as domain labels, keywords, and token count, ignoring the within-domain variance that actually determines model success. Frontier models cost ten to one hundred times more than local open-weight models, so at production scale even small per-request savings become a direct cloud-bill lever. We present Brick, a multimodal router that scores each model on six capability dimensions, combines this with a per-query difficulty estimate, and dispatches via a cost-penalized geometric rule. A continuous preference knob lets operators slide between max-quality and max-saving profiles at deploy time. On a benchmark of 5,504 queries, Brick at max-quality reaches 76.98% accuracy, beating the best single model (75.02%) and all tested routers. At a neutral cost-quality profile, Brick achieves 74.11% accuracy at 4.71x lower cost than always using the strongest model. At min-cost, it cuts cost 22.15x with 11.85 points accuracy loss. Median latency drops from 51.2s to 22.8s.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Brick, a multimodal router for the Mixture-of-Models paradigm. It assigns each model scores along six capability dimensions, combines these with a per-query difficulty estimate, and dispatches via a cost-penalized geometric rule controlled by a continuous preference knob. On a 5,504-query benchmark, Brick reports 76.98% accuracy at max-quality (exceeding the best single model at 75.02%), 74.11% accuracy at a neutral profile with 4.71× lower cost than the strongest model, and 22.15× cost reduction at min-cost with 11.85-point accuracy loss.
Significance. If the capability scores and difficulty estimates can be shown to generalize beyond the reported benchmark, the method would offer a practical, tunable mechanism for balancing accuracy and inference cost in production LLM deployments, addressing a key engineering constraint where frontier models are 10-100× more expensive than open-weight alternatives.
major comments (3)
- [Abstract, §3] Abstract and §3 (methodology): The headline results (76.98% max-quality accuracy, 74.11% at neutral profile) rest entirely on the router correctly ranking models via the six capability dimensions plus per-query difficulty. No description is supplied of how these quantities are computed, whether they are derived from static metadata, surface features, or performance on the 5,504-query set itself, or whether any cross-validation or held-out validation demonstrates predictive validity on unseen queries.
- [Abstract] Abstract: The geometric cost-penalized dispatch rule is presented as parameter-free at deployment time, yet the paper supplies no evidence that the underlying capability scores and difficulty estimates were not fitted or calibrated on the same benchmark used for the reported accuracy and cost numbers; this leaves open the possibility that the observed gains are circular.
- [Abstract, evaluation] Abstract and evaluation section: No calibration plots, per-model success/failure prediction metrics, or out-of-distribution test are mentioned to confirm that the six-dimensional scores reliably predict which model will succeed on a given query; without this, the 4.71× cost reduction and latency claims cannot be assessed as generalizable.
minor comments (1)
- [Abstract] The abstract states benchmark numbers but does not define the six capability dimensions or the difficulty estimator; adding a short methods paragraph would improve readability.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater methodological transparency. We address each major comment below and commit to revisions that add the requested details without altering the reported results.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (methodology): The headline results (76.98% max-quality accuracy, 74.11% at neutral profile) rest entirely on the router correctly ranking models via the six capability dimensions plus per-query difficulty. No description is supplied of how these quantities are computed, whether they are derived from static metadata, surface features, or performance on the 5,504-query set itself, or whether any cross-validation or held-out validation demonstrates predictive validity on unseen queries.
Authors: The current manuscript does not supply a full description of the computation procedure for the six capability dimensions or the per-query difficulty estimate. We will revise §3 to include the exact derivation method (static metadata combined with a separate validation set), the formulas used, and cross-validation results on held-out queries to demonstrate predictive validity. revision: yes
-
Referee: [Abstract] Abstract: The geometric cost-penalized dispatch rule is presented as parameter-free at deployment time, yet the paper supplies no evidence that the underlying capability scores and difficulty estimates were not fitted or calibrated on the same benchmark used for the reported accuracy and cost numbers; this leaves open the possibility that the observed gains are circular.
Authors: We agree that the manuscript provides no explicit evidence separating the score computation from the 5,504-query evaluation set. The revision will add a subsection documenting the independent data sources and procedures used to obtain the scores, thereby addressing the circularity concern. revision: yes
-
Referee: [Abstract, evaluation] Abstract and evaluation section: No calibration plots, per-model success/failure prediction metrics, or out-of-distribution test are mentioned to confirm that the six-dimensional scores reliably predict which model will succeed on a given query; without this, the 4.71× cost reduction and latency claims cannot be assessed as generalizable.
Authors: The present version omits calibration plots, per-model prediction metrics, and out-of-distribution tests. We will incorporate these analyses into the evaluation section of the revised manuscript to support the generalizability of the routing decisions and cost-accuracy trade-offs. revision: yes
Circularity Check
No circularity; derivation self-contained on presented claims
full rationale
The abstract and available text describe Brick as computing six capability dimensions plus per-query difficulty then applying a cost-penalized geometric dispatch rule, with performance reported as empirical results on the 5,504-query benchmark. No equations, definitions, or steps are quoted that define the dimensions or difficulty from the evaluation outcomes themselves, nor any self-citation chain that imports the core routing logic. The central claims rest on the (unshown) computation of those scores generalizing, but nothing in the given material reduces the reported accuracy or cost gains to a tautology or fitted input renamed as prediction. This is the normal case of an empirical router paper whose internal validity cannot be challenged for circularity from the abstract alone.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Measuring Mathematical Problem Solv- ing with the MATH Dataset,
D. Hendrycks et al., “Measuring Mathematical Problem Solv- ing with the MATH Dataset, ” inProc. NeurIPS Datasets and Benchmarks, 2021
2021
-
[2]
Training Verifiers to Solve Math Word Problems
K. Cobbe et al., “Training Verifiers to Solve Math Word Prob- lems, ” arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
MMLU-Pro: A More Robust and Challeng- ing Multi-Task Language Understanding Benchmark,
Y . Wang et al., “MMLU-Pro: A More Robust and Challeng- ing Multi-Task Language Understanding Benchmark, ” inProc. NeurIPS Datasets and Benchmarks, 2024
2024
-
[4]
Instruction-Following Evaluation for Large Language Models
J. Zhou et al., “Instruction-Following Evaluation for Large Lan- guage Models, ” arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
IFBench: Granular Instruction-Following Evaluation,
V . Pyatkin et al., “IFBench: Granular Instruction-Following Evaluation, ” arXiv:2503.07879 , 2025
-
[6]
Berkeley Function-Calling Leaderboard,
F. Yan et al., “Berkeley Function-Calling Leaderboard, ” Berke- ley AI Research, 2024
2024
-
[7]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
N. Jain et al., “LiveCodeBench: Holistic and Contamination- Free Evaluation of Large Language Models for Code, ” arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Measuring short-form factuality in large language models
J. Wei et al., “SimpleQA: Measuring Short-Form Factuality in Large Language Models, ” arXiv:2411.04368, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark,
D. Rein et al., “GPQA: A Graduate-Level Google-Proof Q&A Benchmark, ” inProc. COLM, 2024
2024
-
[10]
EQ-Bench-Creative-v3: Emotional Intelligence and Creative Writing Evaluation,
S. Paech, “EQ-Bench-Creative-v3: Emotional Intelligence and Creative Writing Evaluation, ”eqbench.com benchmark release, 2024.https://eqbench.com/creative_writing.html
2024
-
[11]
LitBench: A Literary Synthesis Bench- mark for Long-Form Evaluation,
Stanford NLP , “LitBench: A Literary Synthesis Bench- mark for Long-Form Evaluation, ”Hugging Face dataset release, 2025. https://huggingface.co/datasets/SAA-Lab/ litbench-test
2025
-
[12]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
S. Yao et al., “tau-bench: A Benchmark for Tool-Augmented Reasoning, ” arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
RouteLLM: Learning to Route LLMs with Preference Data
I. Ong et al., “RouteLLM: Learning to Route LLMs with Prefer- ence Data, ” arXiv:2406.18665, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
L. Chen, M. Zaharia, and J. Zou, “FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Perfor- mance, ” arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Cascade Routing for Large Language Mod- els,
W . Jitkrittum et al., “Cascade Routing for Large Language Mod- els, ” arXiv:2405.20828, 2024
-
[16]
B. Warner et al., “Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory-Efficient, and Long- Context Fine-Tuning and Inference, ” arXiv:2412.13663, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
A Coefficient of Agreement for Nominal Scales,
J. Cohen, “ A Coefficient of Agreement for Nominal Scales, ” Educational and Psychological Measurement, vol. 20, no. 1, pp. 37– 46, 1960. 17
1960
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.