Dual-Constrained Diffusion Image Compression for Operational Rate-Distortion-Perception Optimization
Pith reviewed 2026-06-27 07:22 UTC · model grok-4.3
The pith
Dual constraints on a diffusion decoder let one bitstream navigate the full rate-distortion-perception surface.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
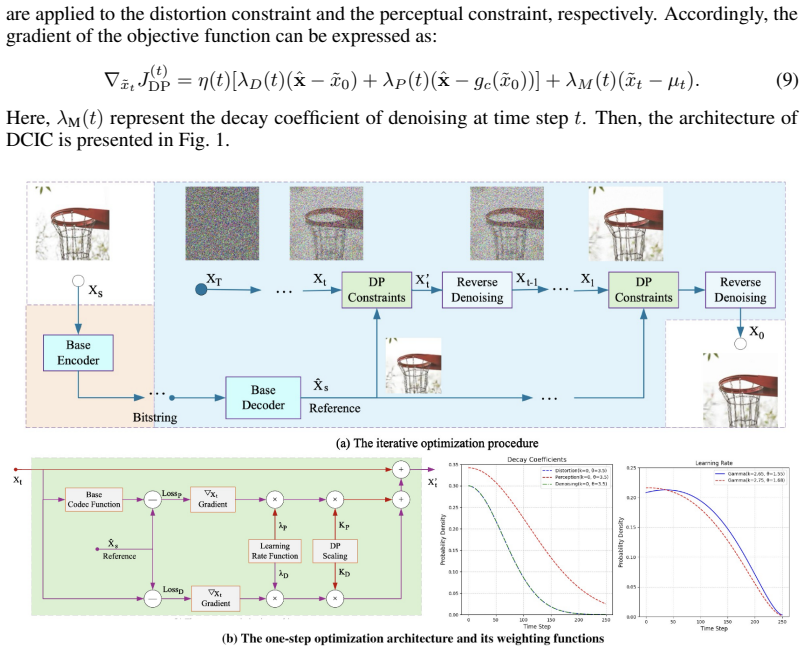
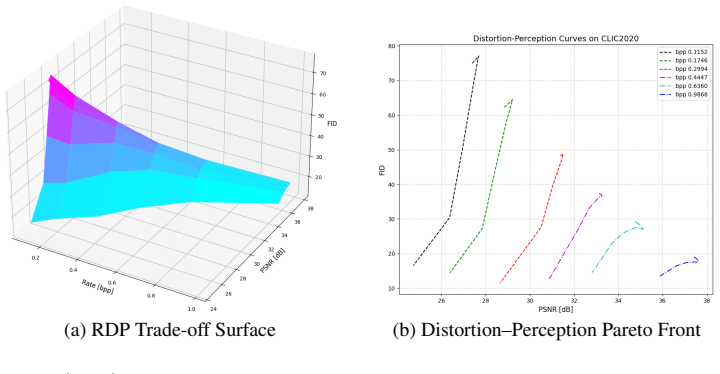
DCIC integrates a learned codec with a diffusion-based decoder governed by joint distortion and idempotence constraints. The distortion constraint bounds reconstruction fidelity relative to the base codec output; the idempotence constraint requires that re-encoding the restored image recovers the base codec reconstruction. Together they steer the reverse denoising process via iterative optimization with consistent noise injection, realizing common randomness without additional rate overhead. At fixed rate, dual attenuation factors (K_D, K_P) jointly navigate the Pareto frontier of the distortion-perception plane, enabling continuously adjustable fidelity-realism trade-offs from a single bits
What carries the argument
Dual-constrained diffusion decoder steered by a distortion bound and an idempotence condition that together inject consistent noise for common randomness.
If this is right
- DCIC_RDP achieves superior BD-PSNR over all perceptual codecs.
- DCIC_RP matches dedicated perception-oriented methods in BD-FID.
- At fixed rate, dual attenuation factors (K_D, K_P) jointly navigate the Pareto frontier of the distortion-perception plane.
- DCIC_RD (K_P=0) and DCIC_RP (K_D=0) arise as boundary curves from the same model.
- The approach works across CNN, Transformer, and hybrid architectures on CelebA-HQ, CLIC2020, and ImageNet-1K.
Where Pith is reading between the lines
- Idempotence-style constraints may let other generative decoders approximate distributional matching without explicit density estimation.
- The single-bitstream navigation implies that separate perceptual-rate allocations are unnecessary once the decoder can be steered this way.
- Similar dual-constraint steering could be tested on video or 3D data where both fidelity and realism must be traded at constant rate.
Load-bearing premise
The assumption that the idempotence constraint serves as a tractable surrogate for the distributional perception requirement.
What would settle it
Check whether images produced under the idempotence constraint, when re-encoded by the base codec, consistently recover the base reconstruction while perceptual scores exceed those of the base codec on held-out test sets.
Figures
read the original abstract
The rate-distortion-perception (RDP) trade-off extends classical rate--distortion theory by imposing a distributional constraint on reconstructions, providing a unified framework for neural image compression that jointly governs fidelity and perceptual realism. While prior work achieves near-optimal rate--perception trade-offs, practical frameworks explicitly realizing the full RDP surface remain scarce, primarily due to the difficulty of introducing common randomness at the decoder. We propose DCIC (Dual-Constrained Diffusion Image Compression), which integrates a learned codec with a diffusion-based decoder governed by joint distortion and idempotence constraints. The distortion constraint bounds reconstruction fidelity relative to the base codec output; the idempotence constraint -- requiring that re-encoding the restored image recovers the base codec reconstruction -- serves as a tractable surrogate for the distributional perception requirement. Together, they steer the reverse denoising process via iterative optimization with consistent noise injection, realizing common randomness without additional rate overhead. At fixed rate, dual attenuation factors $(K_D, K_P)$ jointly navigate the Pareto frontier of the distortion-perception plane, enabling continuously adjustable fidelity-realism trade-offs from a single bitstream. DCIC$_{RD}$ ($K_P{=}0$) and DCIC$_{RP}$ ($K_D{=}0$) arise as boundary curves, with DCIC$_{RDP}$ ($K_D = K_P=1$) realizing the optimal interior operating point. Experiments on CelebA-HQ, CLIC2020, and ImageNet-1K across CNN, Transformer, and hybrid architectures confirm that DCIC$_{RDP}$ achieves superior BD-PSNR over all perceptual codecs, while DCIC$_{RP}$ matches dedicated perception-oriented methods in BD-FID, validating the practical value of full RDP surface navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dual-Constrained Diffusion Image Compression (DCIC), integrating a learned base codec with a diffusion decoder steered by joint distortion and idempotence constraints. The idempotence constraint (re-encoding the diffusion output recovers the base reconstruction) is introduced as a surrogate for the distributional perception requirement, enabling consistent noise injection for common randomness without rate overhead. Dual attenuation factors (K_D, K_P) are claimed to navigate the full RDP surface from a single bitstream, with DCIC_RD (K_P=0), DCIC_RP (K_D=0), and DCIC_RDP (K_D=K_P=1) as special cases. Experiments across CelebA-HQ, CLIC2020, and ImageNet-1K using CNN, Transformer, and hybrid architectures report that DCIC_RDP achieves superior BD-PSNR over perceptual codecs while DCIC_RP matches dedicated perception methods in BD-FID.
Significance. If the central construction holds, the framework would supply a practical, single-bitstream mechanism for continuous RDP trade-off navigation in neural image compression, addressing the common-randomness obstacle at the decoder. The multi-dataset, multi-architecture experimental design supplies broad empirical coverage of the claimed BD-PSNR and BD-FID gains.
major comments (1)
- [Abstract / method description] Abstract and method description: the claim that the idempotence constraint serves as a tractable surrogate for the distributional perception requirement lacks any derivation or bound. Idempotence is a deterministic fixed-point condition on the decoder-re-encoder composition, whereas RDP perception requires closeness of the conditional measure P_{X̂|Y} to the source measure; no analysis is supplied showing that satisfying the fixed point implies the required measure closeness or that iterative optimization with shared noise realizes the necessary common randomness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for clearer justification of the idempotence constraint. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract / method description] Abstract and method description: the claim that the idempotence constraint serves as a tractable surrogate for the distributional perception requirement lacks any derivation or bound. Idempotence is a deterministic fixed-point condition on the decoder-re-encoder composition, whereas RDP perception requires closeness of the conditional measure P_{X̂|Y} to the source measure; no analysis is supplied showing that satisfying the fixed point implies the required measure closeness or that iterative optimization with shared noise realizes the necessary common randomness.
Authors: We acknowledge that the current manuscript provides no formal derivation or bound connecting the idempotence constraint to distributional closeness under the perception metric. The idempotence condition is introduced as a deterministic mechanism to enforce consistency between the diffusion output and the base codec reconstruction, thereby enabling shared noise injection for common randomness without additional rate cost. This is presented as a practical surrogate rather than a theoretically proven equivalence. In revision we will expand the method section with a new subsection that (i) explicitly distinguishes the fixed-point property from the required measure closeness, (ii) provides the heuristic motivation based on consistency under re-encoding, and (iii) reports additional ablation results quantifying how well the resulting reconstructions satisfy empirical distributional metrics. We will also tone down the abstract claim from “serves as a tractable surrogate” to “is employed as an empirical surrogate.” revision: yes
Circularity Check
No significant circularity detected.
full rationale
The provided abstract and description introduce the idempotence constraint explicitly as a modeling choice serving as a surrogate for the distributional perception requirement, with dual attenuation factors (K_D, K_P) presented as design parameters to navigate the RDP surface. No equations, derivations, or claims are exhibited that reduce the perception metric to the idempotence condition by construction, nor is any prediction shown to be statistically forced from fitted inputs. No self-citation load-bearing, uniqueness theorems, or ansatz smuggling via prior work appear in the text. The central construction is a proposed method with boundary cases and empirical results, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- K_D and K_P
axioms (1)
- domain assumption Idempotence constraint serves as a tractable surrogate for the distributional perception requirement
Reference graph
Works this paper leans on
-
[1]
Sullivan, Jens-Rainer Ohm, Woojin Han, and Thomas Wiegand
Gary J. Sullivan, Jens-Rainer Ohm, Woojin Han, and Thomas Wiegand. Overview of the high efficiency video coding (hevc) standard. IEEE Transactions on Circuits and Systems for Video Technology, 22: 0 1649--1668, 2012. URL https://api.semanticscholar.org/CorpusID:64404
2012
-
[2]
Zhengxue Cheng, Heming Sun, Masaru Takeuchi, and J. Katto. Learned image compression with discretized gaussian mixture likelihoods and attention modules. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7936--7945, 2020. URL https://api.semanticscholar.org/CorpusID:209862064
2020
-
[3]
Jinming Liu, Heming Sun, and J. Katto. Learned image compression with mixed transformer-cnn architectures. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14388--14397, 2023. URL https://api.semanticscholar.org/CorpusID:257766648
2023
-
[4]
Elic: Efficient learned image compression with unevenly grouped space-channel contextual adaptive coding
Dailan He, Zi Yang, Weikun Peng, Rui Ma, Hongwei Qin, and Yan Wang. Elic: Efficient learned image compression with unevenly grouped space-channel contextual adaptive coding. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5708--5717, 2022. URL https://api.semanticscholar.org/CorpusID:247594672
2022
-
[5]
Variable bitrate models for learned image compression with multi-gain units and weighted probability assignment
Ran Wang, Wen Jiang, Heming Sun, and Jiro Katto. Variable bitrate models for learned image compression with multi-gain units and weighted probability assignment. In 2024 IEEE International Conference on Visual Communications and Image Processing (VCIP), pages 1--5. IEEE, 2024 a
2024
-
[6]
L. Yu H. Sun and J. Katto. Q-lic: Quantizing learned image compression with channel splitting. IEEE Transactions on Circuits and Systems for Video Technology, pages 3798--3811, 2025. URL https://api.semanticscholar.org/CorpusID:238243504
2025
-
[7]
Vvc official test model vtm
Joint Video Experts Team. Vvc official test model vtm. ITU, 2021
2021
-
[8]
Rethinking lossy compression: The rate-distortion-perception tradeoff
Yochai Blau and Tomer Michaeli. Rethinking lossy compression: The rate-distortion-perception tradeoff. In International Conference on Machine Learning, 2019. URL https://api.semanticscholar.org/CorpusID:59158898
2019
-
[9]
Information compression in the ai era: Recent advances and future challenges
Jun Chen, Yong Fang, Ashish Khisti, Ayfer Özgür, and Nir Shlezinger. Information compression in the ai era: Recent advances and future challenges. IEEE Journal on Selected Areas in Communications, 43 0 (7): 0 2333--2348, 2025. doi:10.1109/JSAC.2025.3560359
-
[10]
The rate-distortion-perception tradeoff: The role of common randomness
Aaron B Wagner. The rate-distortion-perception tradeoff: The role of common randomness. arXiv preprint arXiv:2202.04147, 2022
arXiv 2022
-
[11]
On the rate-distortion-perception function
Jun Chen, Lei Yu, Jia Wang, Wuxian Shi, Yiqun Ge, and Wen Tong. On the rate-distortion-perception function. IEEE Journal on Selected Areas in Information Theory, 3 0 (4): 0 664--673, 2022. doi:10.1109/JSAIT.2022.3231820
-
[12]
Rate-distortion-perception tradeoff for gaussian vector sources
Jingjing Qian, Sadaf Salehkalaibar, Jun Chen, Ashish Khisti, Wei Yu, Wuxian Shi, Yiqun Ge, and Wen Tong. Rate-distortion-perception tradeoff for gaussian vector sources. IEEE Journal on Selected Areas in Information Theory, 6: 0 1--17, 2025. doi:10.1109/JSAIT.2024.3509420
-
[13]
Rate-distortion-cognition controllable versatile neural image compression
Jinming Liu, Ruoyu Feng, Yunpeng Qi, Qiuyu Chen, Zhibo Chen, Wenjun Zeng, and Xin Jin. Rate-distortion-cognition controllable versatile neural image compression. In European Conference on Computer Vision, pages 329--348. Springer, 2024
2024
-
[14]
Zhibo Chen, Heming Sun, Li Zhang, and Fan Zhang. Survey on visual signal coding and processing with generative models: Technologies, standards, and optimization. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 14 0 (2): 0 149--171, 2024. doi:10.1109/JETCAS.2024.3403524
-
[15]
Task-oriented lossy compression with data, perception, and classification constraints
Yuhan Wang, Youlong Wu, Shuai Ma, and Ying-Jun Angela Zhang. Task-oriented lossy compression with data, perception, and classification constraints. IEEE Journal on Selected Areas in Communications, 43 0 (7): 0 2635--2650, 2025. doi:10.1109/JSAC.2025.3559164
-
[16]
High-fidelity generative image compression
Fabian Mentzer, George D Toderici, Michael Tschannen, and Eirikur Agustsson. High-fidelity generative image compression. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 11913--11924. Curran Associates, Inc., 2020 a . URL https://proceedings.neurips.cc/paper_fil...
2020
-
[17]
Minnen, George Toderici, and Fabian Mentzer
Eirikur Agustsson, David C. Minnen, George Toderici, and Fabian Mentzer. Multi-realism image compression with a conditional generator. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22324--22333, 2022. URL https://api.semanticscholar.org/CorpusID:255186005
2023
-
[18]
Lossy image compression with conditional diffusion models
Ruihan Yang and Stephan Mandt. Lossy image compression with conditional diffusion models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 64971--64995. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ccf6d8b4a1...
2023
-
[19]
Idempotence and perceptual image compression
Tongda Xu, Ziran Zhu, Dailan He, Yanghao Li, Lina Guo, Yuanyuan Wang, Zhe Wang, Hongwei Qin, Yan Wang, Jingjing Liu, and Ya-Qin Zhang. Idempotence and perceptual image compression. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Cy5v64DqEF
2024
-
[20]
Rddm: A rate-distortion guided diffusion model for learned image compression enhancement
Sanxin Jiang, Jiro Katto, and Heming Sun. Rddm: A rate-distortion guided diffusion model for learned image compression enhancement. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 15 0 (2): 0 186--199, 2025. doi:10.1109/JETCAS.2025.3563228
-
[21]
Picd: Versatile perceptual image compression with diffusion rendering
Tongda Xu, Jiahao Li, Bin Li, Yan Wang, Ya-Qin Zhang, and Yan Lu. Picd: Versatile perceptual image compression with diffusion rendering. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 28436--28445, 2025
2025
-
[22]
Rate-distortion-perception tradeoff for lossy compression using conditional perception measure
Sadaf Salehkalaibar, Jun Chen, Ashish Khisti, and Wei Yu. Rate-distortion-perception tradeoff for lossy compression using conditional perception measure. In 2024 IEEE International Symposium on Information Theory (ISIT), pages 1071--1076, 2024. doi:10.1109/ISIT57864.2024.10619096
-
[23]
Conditional rate-distortion-perception trade-off
Xueyan Niu, Deniz Gündüz, Bo Bai, and Wei Han. Conditional rate-distortion-perception trade-off. In 2023 IEEE International Symposium on Information Theory (ISIT), pages 1068--1073, 2023. doi:10.1109/ISIT54713.2023.10206459
-
[24]
Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston
Johannes Ball \'e , David C. Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. Variational image compression with a scale hyperprior. ArXiv, abs/1802.01436, 2018. URL https://api.semanticscholar.org/CorpusID:3611540
Pith/arXiv arXiv 2018
-
[25]
Entroformer: A transformer-based entropy model for learned image compression
Yichen Qian, Ming Lin, Xiuyu Sun, Zhiyu Tan, and Rong Jin. Entroformer: A transformer-based entropy model for learned image compression. ArXiv, abs/2202.05492, 2022
arXiv 2022
-
[26]
Learned block-based hybrid image compression
Yaojun Wu, Xin Li, Zhizheng Zhang, Xin Jin, and Zhibo Chen. Learned block-based hybrid image compression. IEEE Transactions on Circuits and Systems for Video Technology, 32: 0 3978--3990, 2020. URL https://api.semanticscholar.org/CorpusID:229297751
2020
-
[27]
Improving statistical fidelity for neural image compression with implicit local likelihood models
Matthew Muckley, Alaaeldin El-Nouby, Karen Ullrich, Herv'e J'egou, and Jakob Verbeek. Improving statistical fidelity for neural image compression with implicit local likelihood models. ArXiv, abs/2301.11189, 2023. URL https://api.semanticscholar.org/CorpusID:256274723
arXiv 2023
-
[29]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. ArXiv, abs/2010.02502, 2020. URL https://api.semanticscholar.org/CorpusID:222140788
Pith/arXiv arXiv 2010
-
[30]
Jaakkola, and Shiyu Chang
Guanhua Zhang, Jiabao Ji, Yang Zhang, Mo Yu, T. Jaakkola, and Shiyu Chang. Towards coherent image inpainting using denoising diffusion implicit models. In International Conference on Machine Learning, 2023. URL https://api.semanticscholar.org/CorpusID:258041305
2023
-
[31]
Denoising diffusion restoration models
Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song. Denoising diffusion restoration models. ArXiv, abs/2201.11793, 2022. URL https://api.semanticscholar.org/CorpusID:246411364
arXiv 2022
-
[32]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), December 2015
2015
-
[33]
Lempitsky
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor S. Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3172--3182, 2021. URL https://ap...
2022
-
[34]
Bernstein, Alexander C
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115: 0 211 -- 252, 2014. URL https://api.semanticscholar.org/CorpusID:2930547
2014
-
[35]
Clic 2020: Challenge on learned image compression
George Toderici, Lucas Theis, Nick Johnston, Eirikur Agustsson, Fabian Mentzer, Johannes Ball \'e , Wenzhe Shi, and Radu Timofte. Clic 2020: Challenge on learned image compression. Retrieved March, 29: 0 2021, 2020
2020
-
[36]
Transformer-based transform coding
Yinhao Zhu, Yang Yang, and Taco Cohen. Transformer-based transform coding. In International Conference on Learning Representations, 2022. URL https://api.semanticscholar.org/CorpusID:251647190
2022
-
[37]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andr \'e s Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11451--11461, 2022. URL https://api.semanticscholar.org/CorpusID:246240274
2022
-
[38]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. ArXiv, abs/2105.05233, 2021 b . URL https://api.semanticscholar.org/CorpusID:234357997
Pith/arXiv arXiv 2021
-
[39]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 586--595, 2018. URL https://api.semanticscholar.org/CorpusID:4766599
2018
-
[40]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Neural Information Processing Systems, 2017. URL https://api.semanticscholar.org/CorpusID:326772
2017
-
[41]
Calculation of average psnr differences between rd-curves
Gisle Bjontegaard. Calculation of average psnr differences between rd-curves. ITU-T SG16, Doc. VCEG-M33, 2001
2001
-
[42]
Web picture format
Google. Web picture format. 2010
2010
-
[43]
High-fidelity generative image compression
Fabian Mentzer, George Toderici, Michael Tschannen, and Eirikur Agustsson. High-fidelity generative image compression. ArXiv, abs/2006.09965, 2020 b . URL https://api.semanticscholar.org/CorpusID:219721015
arXiv 2006
-
[44]
Lossy image compression with conditional diffusion models
Ruihan Yang and Stephan Mandt. Lossy image compression with conditional diffusion models. ArXiv, abs/2209.06950, 2022. URL https://api.semanticscholar.org/CorpusID:252280611
arXiv 2022
-
[45]
On the rate–distortion–perception–semantics tradeoff in low-rate regime for lossy compression
Weida Wang, Xinyi Tong, Xinchun Yu, and Shao-Lun Huang. On the rate–distortion–perception–semantics tradeoff in low-rate regime for lossy compression. Journal of the Franklin Institute, 361 0 (11): 0 106873, 2024 b . ISSN 0016-0032. doi:https://doi.org/10.1016/j.jfranklin.2024.106873. URL https://www.sciencedirect.com/science/article/pii/S0016003224002941
-
[46]
Generative modeling via drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting. arXiv preprint arXiv:2602.04770, 2026
Pith/arXiv arXiv 2026
-
[47]
Fast sampling of diffusion models with exponential integrator
Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator. ArXiv, abs/2204.13902, 2022. URL https://api.semanticscholar.org/CorpusID:248476097
arXiv 2022
-
[48]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in neural information processing systems, 35: 0 5775--5787, 2022
2022
-
[49]
Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. Machine Intelligence Research, 22 0 (4): 0 730--751, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.