SPARC: Reliable Spatial Annotations from Robot Demonstrations at Scale
Pith reviewed 2026-06-27 06:26 UTC · model grok-4.3
The pith
SPARC automatically annotates robot demonstrations with spatial labels and reliability scores derived from task structure, outperforming detector baselines in accuracy and sample retention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
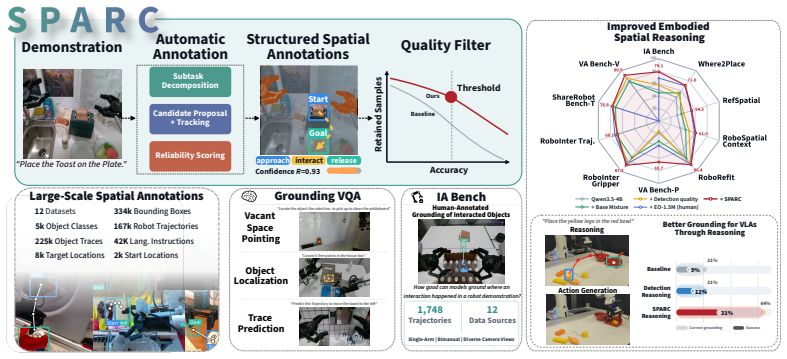
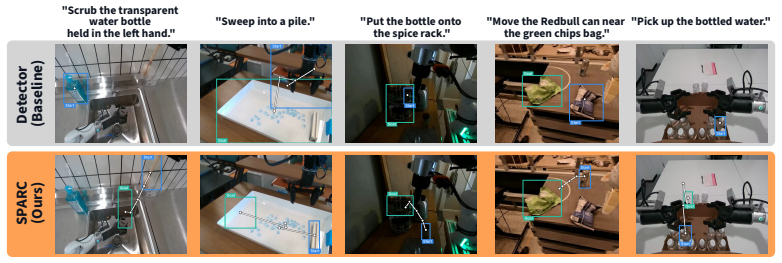
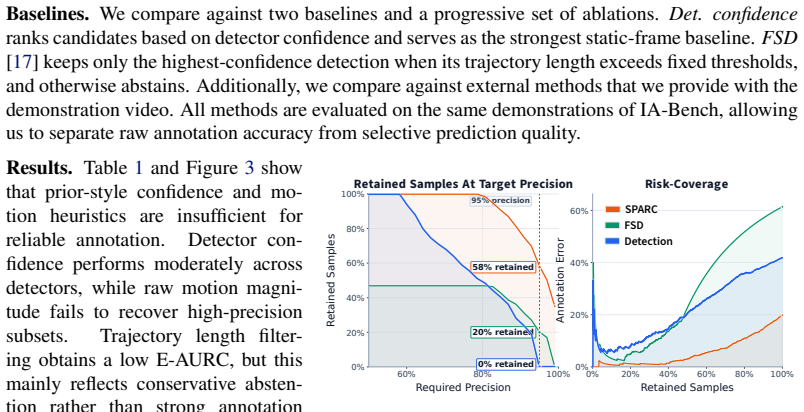
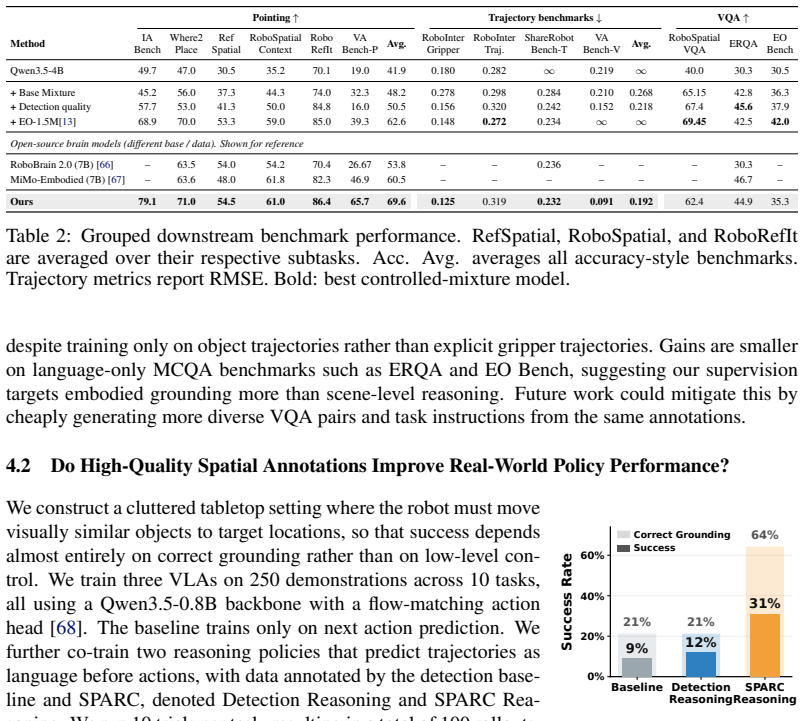
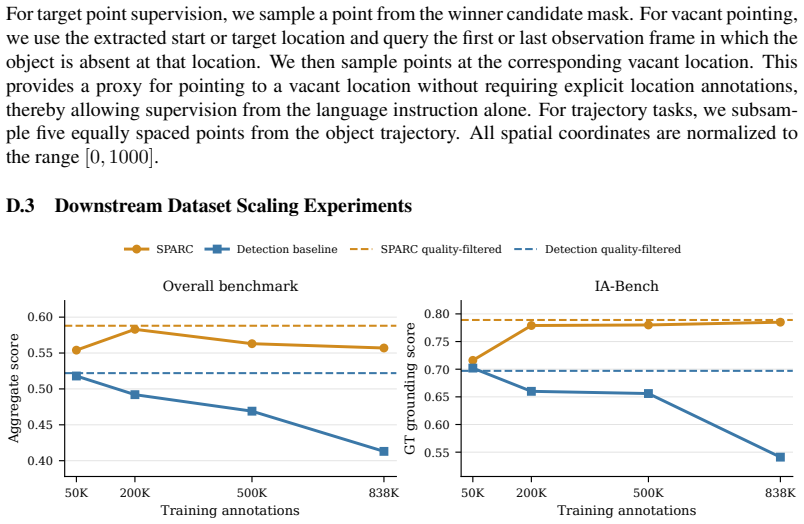
SPARC is a risk-aware framework that automatically labels robot demonstrations with structured spatial annotations and assigns each annotation a reliability score by leveraging the spatio-temporal structure inherent to robot tasks. On 1.7k human-annotated demonstrations spanning diverse embodiments and scenarios, SPARC significantly outperforms detection-only baselines in localization accuracy while retaining three times more samples at high-precision operating points. Models finetuned on the resulting annotations achieve state-of-the-art results on object-grounding and pointing benchmarks among similarly sized models and produce policies that outperform baselines in cluttered real-world sce
What carries the argument
The reliability calibration step that converts spatio-temporal consistency signals from robot task demonstrations into per-annotation correctness scores.
If this is right
- Policies trained on SPARC-generated annotations outperform baselines in cluttered, visually ambiguous real-world scenes.
- Models reach state-of-the-art performance on object-grounding and pointing benchmarks among similarly sized models without manually verified training data.
- Structured spatial annotations become available at larger scale for training grounded robot policies and embodied foundation models.
- Spatial-reasoning performance on broader suites remains competitive while removing the requirement for manual annotation of training data.
Where Pith is reading between the lines
- The same consistency-based scoring idea could be tested on other sequential sensor streams where task structure is available.
- Combining SPARC scores with existing active-learning loops might further reduce the total number of human reviews needed.
- The approach suggests a route to larger training corpora for vision-language-action models that currently face annotation bottlenecks.
Load-bearing premise
The spatio-temporal structure present in robot task demonstrations supplies a reliability signal that is better calibrated for annotation correctness than detector confidence scores alone.
What would settle it
A held-out test set of robot demonstrations in which human judges of annotation correctness show equal or lower correlation with SPARC reliability scores than with raw detector confidence scores.
Figures


read the original abstract
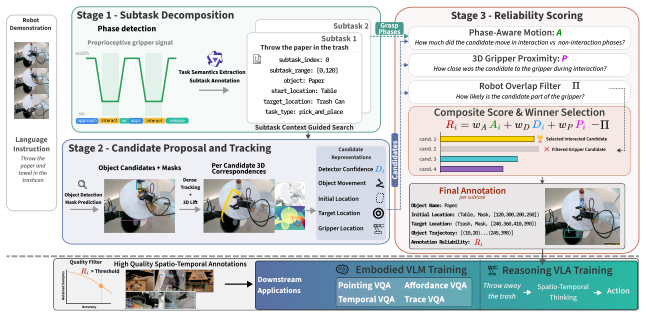
This work introduces Spatial Annotations from Robot Demonstrations with Reliability Calibration (SPARC), a risk-aware framework that automatically labels robot demonstrations with structured spatial annotations and assigns each annotation a reliability score. Structured spatial annotations, such as bounding boxes, object trajectories, and manipulation phase labels, benefit a broad range of robotics applications from training grounded robot policies and embodied foundation models to motion planning and hierarchical task composition. Existing automated pipelines generate such annotations at scale but provide no reliable quality signal: detector confidence is poorly calibrated for annotation correctness, forcing a choice between accepting noisy labels or discarding useful samples. In contrast to existing automated pipelines, SPARC leverages the spatio-temporal structure inherent to robot tasks to generate a reliability signal, reducing noisy labels and retaining more useful samples. We further introduce Interaction-Aware Bench (IA-Bench), a benchmark that measures model accuracy in grounding the locations of interacted objects in robot demonstrations. On 1.7k human-annotated demonstrations spanning diverse embodiments and scenarios, SPARC significantly outperforms detection-only baselines in localization accuracy while retaining three times more samples at high-precision operating points. Our experiments demonstrate that models finetuned on our annotations achieve state-of-the-art results on object-grounding and pointing benchmarks among similarly sized models, while remaining competitive on broader spatial-reasoning suites without manually verified or annotated training data. Furthermore, policies trained on SPARC-generated annotations outperform baselines in cluttered, visually ambiguous real-world scenes. Code, data, and models are available at intuitive-robots.github.io/sparc-labeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SPARC, a risk-aware framework that automatically generates structured spatial annotations (bounding boxes, trajectories, manipulation phases) from robot demonstrations and assigns reliability scores by exploiting inherent spatio-temporal task structure rather than detector confidence alone. It also presents IA-Bench for measuring grounding accuracy on interacted objects. On a set of 1.7k human-annotated demonstrations across embodiments, SPARC is reported to outperform detection-only baselines in localization accuracy while retaining three times more samples at high-precision thresholds; models fine-tuned on the resulting annotations reach SOTA on object-grounding and pointing benchmarks among similarly sized models and yield stronger real-world policies in cluttered scenes.
Significance. If the empirical claims hold after verification of methods and statistics, the work would be a meaningful contribution to scalable, high-quality annotation pipelines for robotics and embodied AI. The core idea of using task structure for calibration addresses a known weakness of detector scores, and the public release of code, data, and models strengthens reproducibility. IA-Bench is a useful addition for the community.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central performance claims rest on an evaluation over 1.7k human-annotated demonstrations, yet the provided text gives no visible details on exclusion criteria, how the human ground truth was collected, or statistical tests (error bars, p-values). This information is load-bearing for assessing whether the reported gains in localization accuracy and 3x sample retention are robust.
- [Methods] Methods section: the reliability signal is derived from spatio-temporal task structure, which is the key modeling choice highlighted in the weakest assumption. The exact formulation, any hyperparameters, and how it is computed from trajectories or phases must be stated explicitly (including pseudocode or equations) to allow independent verification that it is not circular with the target annotations.
minor comments (2)
- [Abstract] Abstract: the phrase 'state-of-the-art results ... among similarly sized models' should name the model sizes, the exact benchmarks, and the competing methods for immediate clarity.
- The link to code/data/models is given but should be accompanied by a permanent archive (e.g., Zenodo DOI) to ensure long-term accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental transparency and methodological clarity. We will revise the manuscript to incorporate the requested details while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central performance claims rest on an evaluation over 1.7k human-annotated demonstrations, yet the provided text gives no visible details on exclusion criteria, how the human ground truth was collected, or statistical tests (error bars, p-values). This information is load-bearing for assessing whether the reported gains in localization accuracy and 3x sample retention are robust.
Authors: We agree that these details are essential for reproducibility and robustness assessment. In the revised manuscript, we will add a dedicated subsection in the Experiments section describing the human annotation protocol (including the interface, guidelines, and number of annotators), explicit exclusion criteria (e.g., incomplete demonstrations or low inter-annotator agreement), and inter-annotator agreement statistics. We will also report error bars on all metrics and include statistical significance tests (paired t-tests with p-values) comparing SPARC against baselines. revision: yes
-
Referee: [Methods] Methods section: the reliability signal is derived from spatio-temporal task structure, which is the key modeling choice highlighted in the weakest assumption. The exact formulation, any hyperparameters, and how it is computed from trajectories or phases must be stated explicitly (including pseudocode or equations) to allow independent verification that it is not circular with the target annotations.
Authors: The reliability signal uses task priors (phase transition consistency and trajectory smoothness) that are independent of the detector-derived annotations. We will expand the Methods section with explicit equations defining the reliability score, a table of all hyperparameters and their selected values, and pseudocode for the full computation pipeline. This formulation relies solely on spatio-temporal task structure and does not reference the target bounding boxes or phases, ensuring it is non-circular. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces SPARC as an empirical framework that computes reliability scores from the spatio-temporal structure of robot tasks and evaluates them directly against 1.7k human-annotated demonstrations. No equations, fitting procedures, or self-citations are described that would reduce the reliability signal or any claimed prediction to a quantity defined by the target annotations themselves. The central claims rest on comparative localization accuracy, sample retention, and downstream benchmark results, all of which are externally falsifiable and independent of the method's internal definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zawalski, W
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine. Robotic control via embodied chain-of-thought reasoning. InConference on Robot Learning, pages 3157–3181. PMLR, 2025
2025
-
[2]
Zhao et al
Q. Zhao et al. CoT-VLA: Visual chain-of-thought reasoning for vision-language-action mod- els. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[3]
S. Bai, J. Lyu, W. Zhou, Z. Li, D. Wang, L. Xing, X. Zhao, P. Wang, Z. Wang, C. Chi, et al. Latent reasoning vla: Latent thinking and prediction for vision-language-action models.arXiv preprint arXiv:2602.01166, 2026
Pith/arXiv arXiv 2026
- [4]
-
[5]
Zhang, X
J. Zhang, X. Chen, Y . Guo, Y . Hu, and J. Chen. VLM4VLA: Revisiting vision-language- models in vision-language-action models. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=tc2UsBeODW
2026
-
[6]
Y . Du, Z. Guo, X. Ye, L. Ren, and C. Xiong. Embodiedmidtrain: Bridging the gap between vision-language models and vision-language-action models via mid-training, 2026. URL https://arxiv.org/abs/2604.20012
Pith/arXiv arXiv 2026
-
[7]
Ji et al
Y . Ji et al. RoboBrain: A unified brain model for robotic manipulation from abstract to con- crete. 2025
2025
-
[8]
H. Fang, J. Duan, D. Clay, S. Wang, S. Liu, W. Huang, X. Fan, W.-C. Tsai, S. Chen, Y . R. Wang, S. Xing, J. Cho, J. S. Park, A. Eftekhar, P. Sushko, K. Farley, A. Wadhwa, C. Harrison, W. Han, Y .-C. Lee, E. VanderBilt, R. Hendrix, S. Ellawela, L. Ngoo, J. Chai, Z. Ren, A. Farhadi, D. Fox, and R. Krishna. Molmoact2: Action reasoning models for real-world d...
Pith/arXiv arXiv 2026
-
[9]
R. Dang, J. Guo, B. Hou, S. Leng, K. Li, X. Li, J. Liu, Y . Mao, Z. Wang, Y . Yuan, et al. Rynnbrain: Open embodied foundation models.arXiv preprint arXiv:2602.14979, 2026
arXiv 2026
-
[10]
Q. Shou, F. Zhu, S. Chen, P. Yan, Z. Yan, Y . Miao, X. Pang, Z. Hong, R. Shi, H. Huang, J. Zhang, and S. Guo. Halo: A unified vision-language-action model for embodied mul- timodal chain-of-thought reasoning.ArXiv, abs/2602.21157, 2026. URLhttps://api. semanticscholar.org/CorpusID:286001130
arXiv 2026
-
[11]
A. Rocky and Q. M. J. Wu. Sam2auto: Auto annotation using flash, 2025. URLhttps: //arxiv.org/abs/2506.07850. 9
arXiv 2025
-
[12]
H. Li, Z. Wang, Z.-h. Ding, S. Yang, Y . Chen, Y . Tian, X. Hu, T. Wang, D. Lin, F. Zhao, et al. Robointer: A holistic intermediate representation suite towards robotic manipulation. InThe Fourteenth International Conference on Learning Representations
-
[13]
D. Qu, H. Song, Q. Chen, Z. Chen, X. Gao, X. Ye, Q. Lv, M. Shi, G. Ren, C. Ruan, et al. Eo-1: Interleaved vision-text-action pretraining for general robot control.arXiv preprint arXiv:2508.21112, 2025
arXiv 2025
-
[14]
Y . Li, Y . Deng, J. Zhang, J. Jang, M. Memmel, C. Garrett, F. Ramos, D. Fox, A. Li, A. Gupta, et al. Hamster: Hierarchical action models for open-world robot manipulation. InInternational Conference on Learning Representations, volume 2025, pages 24040–24068, 2025
2025
-
[15]
W. Yuan, J. Duan, V . Blukis, W. Pumacay, R. Krishna, A. Murali, A. Mousavian, and D. Fox. Robopoint: A vision-language model for spatial affordance prediction in robotics. In8th Annual Conference on Robot Learning
-
[16]
E. Zhou, J. An, C. Chi, Y . Han, S. Rong, C. Zhang, P. Wang, Z. Wang, T. Huang, L. Sheng, et al. Roborefer: Towards spatial referring with reasoning in vision-language models for robotics. Advances in Neural Information Processing Systems, 38:28404–28481, 2026
2026
-
[17]
Y . Yuan, H. Cui, Y . Chen, Z. Dong, F. Ni, L. Kou, J. Liu, P. Li, Y . Zheng, and J. Hao. From seeing to doing: Bridging reasoning and decision for robotic manipulation, 2026. URLhttps: //arxiv.org/abs/2505.08548
Pith/arXiv arXiv 2026
-
[18]
Y . Lu, Y . Fan, B. Deng, F. Liu, Y . Li, and S. Wang. Vl-grasp: a 6-dof interactive grasp pol- icy for language-oriented objects in cluttered indoor scenes. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 976–983. IEEE, 2023
2023
-
[19]
W. Chen, S. Belkhale, S. Mirchandani, K. Pertsch, D. Driess, O. Mees, and S. Levine. Training strategies for efficient embodied reasoning. InConference on Robot Learning, pages 365–391. PMLR, 2025
2025
- [20]
-
[21]
Huang, Y .-H
C.-P. Huang, Y .-H. Wu, M.-H. Chen, F. Wang, and F.-E. Yang. Thinkact: Vision-language- action reasoning via reinforced visual latent planning.Advances in Neural Information Pro- cessing Systems, 38:82782–82802, 2026
2026
-
[22]
J. Lee, J. Duan, H. Fang, Y . Deng, B. Li, S. Liu, B. Fang, J. Zhang, Y . R. Wang, S. Lee, et al. Molmoact: Action reasoning models that can reason in space. InWorkshop on Making Sense of Data in Robotics: Composition, Curation, and Interpretability at Scale at CoRL 2025
2025
-
[23]
Y . Gan, L. Zhu, D. Shan, B. Shi, H. Yin, B. Ivanovic, S. Han, T. Darrell, J. Malik, M. Pavone, et al. Foundationmotion: Auto-labeling and reasoning about spatial movement in videos.arXiv preprint arXiv:2512.10927, 2025
arXiv 2025
-
[24]
S. Liu, X. Ren, T. Shen, H. Ling, S. Gupta, S. Wang, S. Fidler, and J. Gao. Moright: Motion control done right.arXiv preprint arXiv:2604.07348, 2026
Pith/arXiv arXiv 2026
-
[25]
K. Chen, S. Xie, Z. Ma, P. R. Sanketi, and K. Goldberg. Robo2VLM: Improving visual ques- tion answering using large-scale robot manipulation data. InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track, 2026. URL https://openreview.net/forum?id=OChorZcZnY
2026
-
[26]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025. 10
Pith/arXiv arXiv 2025
-
[27]
X. Chen, Y . Chen, Y . Fu, N. Gao, J. Jia, W. Jin, H. Li, Y . Mu, J. Pang, Y . Qiao, et al. Internvla- m1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778, 2025
Pith/arXiv arXiv 2025
-
[28]
S. Deng, M. Yan, S. Wei, H. Ma, Y . Yang, J. Chen, Z. Zhang, T. Yang, X. Zhang, H. Cui, et al. Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data. In 9th Annual Conference on Robot Learning
-
[29]
M. X. Li, P. Mattes, N. Blank, K. F. Rudolf, P. W. Lödige, and R. Lioutikov. Multi-objective photoreal simulation (MOPS) dataset for computer vision in robotic manipulation. InStruc- tured World Models for Robotic Manipulation, 2025. URLhttps://openreview.net/forum? id=OHqgPaznoG
2025
-
[30]
Mattes, J
P. Mattes, J. Schwab, J. Bosch, M. Li, N. Blank, M.-T. Tang, M. Haberland, and R. Lioutikov. Sir: Structured image representations for explainable robot learning. InProceedings of the Computer Vision and Pattern Recognition Conference, 2026
2026
-
[31]
Y . Liu, Y . Liu, C. Jiang, K. Lyu, W. Wan, H. Shen, B. Liang, Z. Fu, H. Wang, and L. Yi. Hoi4d: A 4d egocentric dataset for category-level human-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21013–21022, 2022
2022
-
[32]
Darkhalil, D
A. Darkhalil, D. Shan, B. Zhu, J. Ma, A. Kar, R. Higgins, S. Fidler, D. Fouhey, and D. Damen. Epic-kitchens visor benchmark: Video segmentations and object relations.Advances in Neural Information Processing Systems, 35:13745–13758, 2022
2022
-
[33]
Perrett, A
T. Perrett, A. Darkhalil, S. Sinha, O. Emara, S. Pollard, K. K. Parida, K. Liu, P. Gatti, S. Bansal, K. Flanagan, et al. Hd-epic: A highly-detailed egocentric video dataset. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23901–23913, 2025
2025
-
[34]
A. Guo, B. Wen, J. Yuan, J. Tremblay, S. Tyree, J. Smith, and S. Birchfield. Handal: A dataset of real-world manipulable object categories with pose annotations, affordances, and reconstructions. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11428–11435. IEEE, 2023
2023
-
[35]
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
Pith/arXiv arXiv 2025
-
[36]
Lazarow, D
J. Lazarow, D. Griffiths, G. Kohavi, F. Crespo, and A. Dehghan. Cubify anything: Scaling indoor 3d object detection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22225–22233, 2025
2025
-
[37]
K. Sohn, D. Berthelot, N. Carlini, Z. Zhang, H. Zhang, C. A. Raffel, E. D. Cubuk, A. Ku- rakin, and C.-L. Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence.Advances in neural information processing systems, 33:596–608, 2020
2020
-
[38]
M. Xu, Z. Zhang, H. Hu, J. Wang, L. Wang, F. Wei, X. Bai, and Z. Liu. End-to-end semi- supervised object detection with soft teacher. InProceedings of the IEEE/CVF international conference on computer vision, pages 3060–3069, 2021
2021
-
[39]
Huang, L
Z. Huang, L. Huang, Y . Gong, C. Huang, and X. Wang. Mask scoring r-cnn. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6409–6418, 2019
2019
-
[40]
Northcutt, L
C. Northcutt, L. Jiang, and I. Chuang. Confident learning: Estimating uncertainty in dataset labels.Journal of Artificial Intelligence Research, 70:1373–1411, 2021
2021
-
[41]
Kirillov, E
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023. 11
2023
-
[42]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos. InInternational Confer- ence on Learning Representations, volume 2025, pages 28085–28128, 2025
2025
-
[43]
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[44]
S. Y . Gadre, G. Ilharco, A. Fang, J. Hayase, G. Smyrnis, T. Nguyen, R. Marten, M. Worts- man, D. Ghosh, J. Zhang, E. Orgad, R. Entezari, G. Daras, S. Pratt, V . Ramanujan, Y . Bitton, K. Marathe, S. Mussmann, R. Vencu, M. Cherti, R. Krishna, P. W. Koh, O. Saukh, A. J. Ratner, S. Song, H. Hajishirzi, A. Farhadi, R. Beaumont, S. Oh, A. Dimakis, J. Jitsev, ...
2023
-
[45]
A. Fang, A. Madappally Jose, A. Jain, L. Schmidt, A. Toshev, and V . Shankar. Data filter- ing networks. InInternational Conference on Learning Representations, volume 2024, pages 36221–36237, 2024
2024
-
[46]
L. Chen, S. Li, J. Yan, H. Wang, K. Gunaratna, V . Yadav, Z. Tang, V . Srinivasan, T. Zhou, H. Huang, et al. Alpagasus: Training a better alpaca with fewer data. InInternational Confer- ence on Learning Representations, volume 2024, pages 34767–34797, 2024
2024
-
[47]
C. Zhou, P. Liu, P. Xu, S. Iyer, J. Sun, Y . Mao, X. Ma, A. Efrat, P. Yu, L. Yu, et al. Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36:55006–55021, 2023
2023
-
[48]
Karaev, Y
N. Karaev, Y . Makarov, J. Wang, N. Neverova, A. Vedaldi, and C. Rupprecht. Cotracker3: Sim- pler and better point tracking by pseudo-labelling real videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6013–6022, 2025
2025
-
[49]
Blank, M
N. Blank, M. Reuss, M. Rühle, Ö. E. Ya˘gmurlu, F. Wenzel, O. Mees, and R. Lioutikov. Scaling robot policy learning via zero-shot labeling with foundation models. In8th Annual Conference on Robot Learning
-
[50]
Zhang, Y
Y . Zhang, Y . Xie, H. Liu, R. Shah, M. Wan, L. Fan, and Y . Zhu. Scizor: A self-supervised approach to data curation for large-scale imitation learning. InWorkshop on Making Sense of Data in Robotics: Composition, Curation, and Interpretability at Scale at CoRL 2025
2025
-
[51]
A. S. Chen, A. M. Lessing, Y . Liu, and C. Finn. Curating demonstrations using online experi- ence.arXiv preprint arXiv:2503.03707, 2025
arXiv 2025
-
[52]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models. In 9th Annual Conference on Robot Learning
-
[53]
Q. Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026. URLhttps://qwen.ai/blog?id=qwen3.5
2026
-
[54]
S. Fu, Q. Yang, Q. Mo, J. Yan, X. Wei, J. Meng, X. Xie, and W.-S. Zheng. Llmdet: Learning strong open-vocabulary object detectors under the supervision of large language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14987–14997, 2025. 12
2025
-
[55]
A. W. Harley, Y . You, X. Sun, Y . Zheng, N. Raghuraman, Y . Gu, S. Liang, W.-H. Chu, A. Dave, S. You, et al. Alltracker: Efficient dense point tracking at high resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5253–5262, 2025
2025
-
[56]
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang. Moge- 2: Accurate monocular geometry with metric scale and sharp details.Advances in Neural Information Processing Systems, 38:35928–35959, 2026
2026
-
[57]
H. Mei, Q. Huang, H. Ci, and M. Z. Shou. Robotseg: A model and dataset for segmenting robots in image and video.arXiv preprint arXiv:2511.22950, 2025
arXiv 2025
-
[58]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[59]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. DROID: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems (RSS), 2024
2024
-
[60]
Walke, K
H. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. He, V . Myers, M. J. Kim, M. Du, A. Lee, K. Fang, C. Finn, and S. Levine. BridgeData V2: A dataset for robot learning at scale. InConference on Robot Learning (CoRL), 2023
2023
-
[61]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[62]
Geifman and R
Y . Geifman and R. El-Yaniv. Selective classification for deep neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[63]
D. Feng, L. Rosenbaum, and K. Dietmayer. Towards safe autonomous driving: Capture un- certainty in the deep neural network for lidar 3d vehicle detection. In2018 21st international conference on intelligent transportation systems (ITSC), pages 3266–3273. IEEE, 2018
2018
-
[64]
Y . Geifman, G. Uziel, and R. El-Yaniv. Bias-reduced uncertainty estimation for deep neural classifiers.arXiv preprint arXiv:1805.08206, 2018
Pith/arXiv arXiv 2018
-
[65]
X. An, Y . Xie, F. Tang, Y . Yan, H. Tan, D. Zhu, C. Chen, X. Zhao, B. Qin, K. Yang, Y . Shen, Y . Zhang, K. Zhang, W. Zhang, Z. Cheng, N. Zhang, C. Wu, C. Ge, Z. Ran, D. Song, C. Li, S. Feng, M. Hu, Z. Chen, J. Niu, B. Li, Z. Feng, Z. Liu, Z. Ge, and J. Deng. Llava-onevision-2: Towards next-generation perceptual intelligence, 2026. URLhttps://arxiv.org/a...
2026
-
[66]
B. R. Team, M. Cao, H. Tan, Y . Ji, X. Chen, M. Lin, Z. Li, Z. Cao, P. Wang, E. Zhou, et al. Robobrain 2.0 technical report.arXiv preprint arXiv:2507.02029, 2025
arXiv 2025
-
[67]
X. Hao, L. Zhou, Z. Huang, Z. Hou, Y . Tang, L. Zhang, G. Li, Z. Lu, S. Ren, X. Meng, Y . Zhang, J. Wu, J. Lu, C. Dang, J. Guan, J. Wu, Z. Hou, H. Li, S. Xia, M. Zhou, Y . Zheng, Z. Yue, S. Gu, H. Tian, Y . Shen, J. Cui, W. Zhang, S. Xu, B. Wang, H. Sun, Z. Zhu, Y . Jiang, Z. Guo, C. Gong, C. Zhang, W. Ding, K. Ma, G. Chen, R. Cai, D. Xiang, H. Qu, F. Luo...
Pith/arXiv arXiv 2026
-
[68]
J. Ye, N. Gao, S. Yang, J. Zheng, Z. Wang, Y . Chen, P. Chen, Y . Chen, S. Liu, and J. Jia. Starvla: Reducing complexity in vision-language-action systems.arXiv preprint arXiv:2604.11757, 2026. 13
Pith/arXiv arXiv 2026
-
[69]
G. Luo, G. Yang, Z. Gong, G. Chen, H. Duan, E. Cui, R. Tong, Z. Hou, T. Zhang, Z. Chen, et al. Visual embodied brain: Let multimodal large language models see, think, and control in spaces.arXiv preprint arXiv:2506.00123, 2025
arXiv 2025
-
[70]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu, et al. Ground- ing DINO: Marrying DINO with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023
Pith/arXiv arXiv 2023
-
[71]
Karaev, I
N. Karaev, I. Rocco, B. Graham, N. Neverova, A. Vedaldi, and C. Rupprecht. CoTracker: It is better to track together. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[72]
S. Chen, H. Guo, S. Zhu, F. Zhang, Z. Huang, J. Feng, and B. Kang. Video depth anything: Consistent depth estimation for super-long videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22831–22840, 2025. 14 A Additional Related Work Type Method / dataset Ann. Filtering signal Labels Det. Track Robot Human RoboInter [12] /...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.