Flex4DHuman: Flexible Multi-view Video Diffusion for 4D Human Reconstruction
Pith reviewed 2026-06-27 06:52 UTC · model grok-4.3
The pith
A diffusion model generates dense multi-view videos from monocular input using only relative camera-pose conditioning for 4D human reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
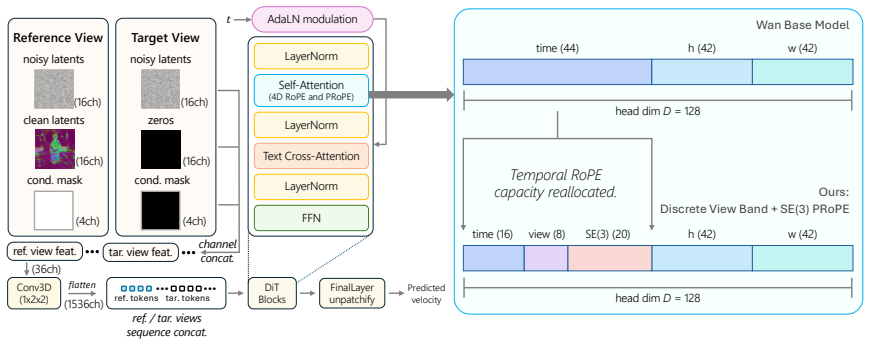
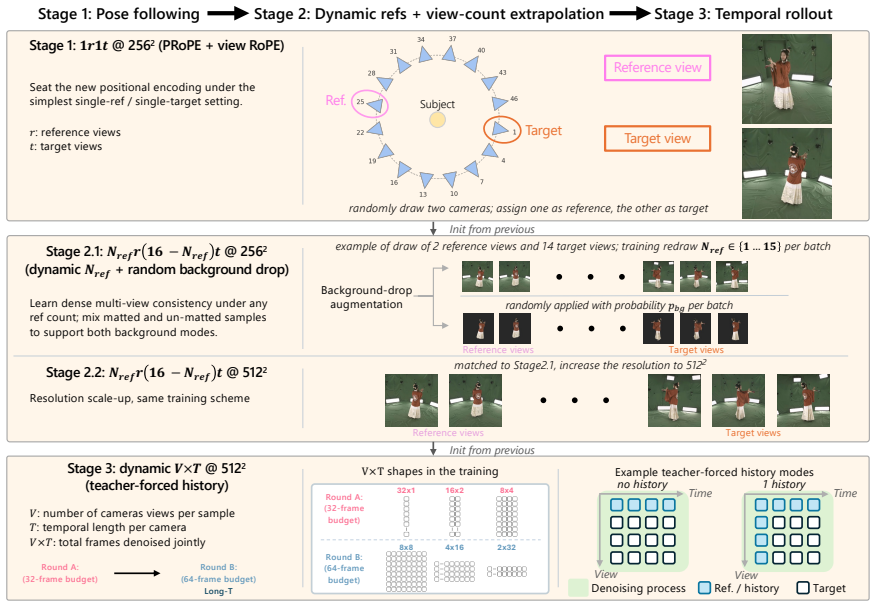
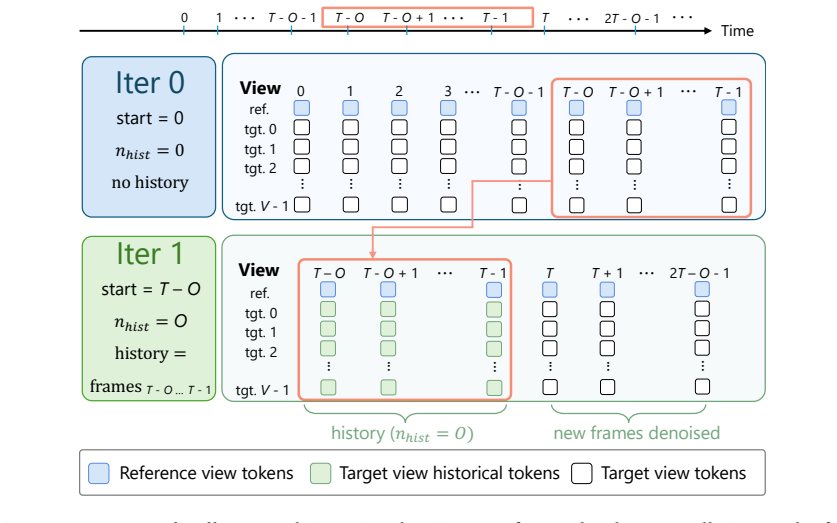
Flex4DHuman shows that relative camera-pose positional encoding, implemented as a five-axis extension of spatio-temporal RoPE that includes view indices and continuous SE(3) geometry, allows a frozen Wan 2.1 backbone to generate consistent multi-view video sequences. A three-stage curriculum first teaches basic pose following, then flexible reference-to-target generation, then temporal rollout using clean historical tokens, with added multi-view captions for text control at inference. The resulting videos integrate directly with off-the-shelf 4D Gaussian splatting to lift monocular videos into dynamic 4D models, outperforming prior human-centric methods on DNA-Rendering and ActorsHQ while ge
What carries the argument
Five-axis positional encoding that extends spatio-temporal RoPE with view indices and continuous SE(3) relative camera geometry, which supplies all conditioning information without explicit geometry priors.
If this is right
- Monocular static-camera videos can be lifted directly into dynamic 4D Gaussian splats without additional capture hardware.
- The same pose-conditioned formulation produces usable results on animal categories after mixed human-animal training.
- Multi-view captions enable text-guided control of the generated views at test time.
- Training with clean historical target-view tokens supports coherent temporal rollout across longer sequences.
- The generated dense views integrate with any downstream reconstruction pipeline that accepts synchronized multi-view video.
Where Pith is reading between the lines
- Single-camera casual videos could become a practical source for 4D assets in simulation and gaming once the pose-conditioning approach is validated at larger scale.
- The curriculum of pose following followed by view synthesis might transfer to other dynamic scene categories if similar relative-pose data is available.
- Text control over generated views opens a route to 4D video editing and re-shooting from existing footage.
- If the encoding generalizes, the method could lower the barrier for creating training data for downstream 4D tasks by removing the need for multi-camera rigs.
Load-bearing premise
Relative camera-pose positional encoding alone is sufficient to drive high-quality multi-view video generation without any explicit geometry priors such as skeletons, depth, or normals.
What would settle it
Generated videos that exhibit geometric inconsistencies or appearance drift when inspected from camera angles outside the conditioning set, or that produce visibly degraded 4D Gaussian reconstructions compared with methods using explicit priors, would falsify the central claim.
Figures

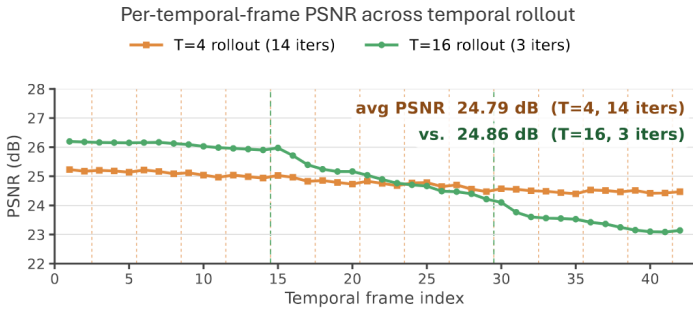

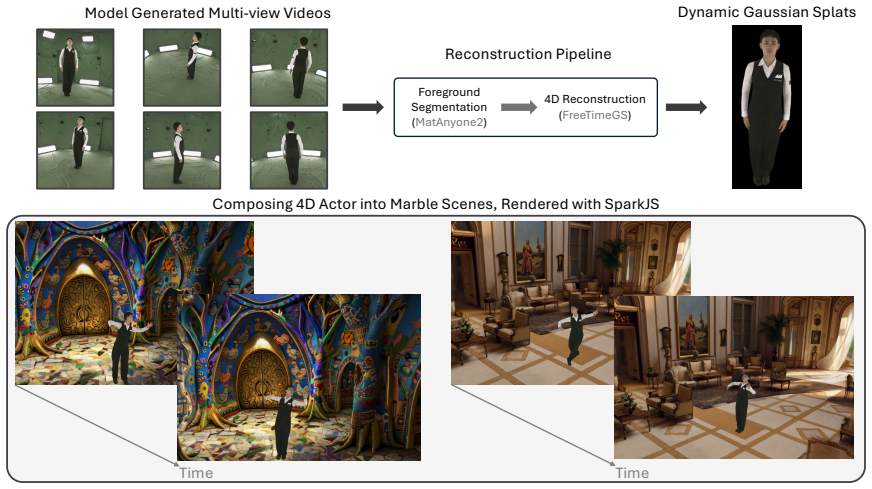
read the original abstract
We present Flex4DHuman, a multi-view video diffusion model that transforms a monocular or sparse multi-view video of a dynamic subject into synchronized dense multi-view videos using only relative camera-pose conditioning. Unlike prior human-centric methods that rely on skeletons, depth maps, normals, or rendered target-view geometry, Flex4DHuman requires no explicit geometry priors and instead conditions generation through relative camera-pose positional encoding. The generated videos can be directly ingested by downstream reconstruction pipelines to create dynamic 4D Gaussian splats. Built on the Wan 2.1 1.3B text-to-video model, Flex4DHuman preserves the backbone architecture and encodes camera and view information through a five-axis positional encoding that extends spatio-temporal RoPE with view indices and continuous SE(3) relative camera geometry. A three-stage curriculum progressively trains the model for pose following, flexible reference-to-target view generation, and temporal rollout. To support temporal rollout, we train with clean historical target-view tokens. We also add multi-view captions to enable test-time text control. Combined with an off-the-shelf 4D Gaussian Splatting stage, our framework lifts monocular static-camera videos into dynamic 4D Gaussian splats. Experiments on DNA-Rendering and ActorsHQ show that Flex4DHuman surpasses prior state-of-the-art methods, while the same formulation generalizes to animal categories after mixed human-animal training. These capabilities make Flex4DHuman a practical step toward scalable 4D content creation from casual monocular videos for simulation, gaming, AR/VR, and video re-shooting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Flex4DHuman, a multi-view video diffusion model built on the Wan 2.1 1.3B text-to-video backbone. It generates synchronized dense multi-view videos from monocular or sparse multi-view inputs of dynamic subjects using only relative camera-pose conditioning via a five-axis positional encoding that extends spatio-temporal RoPE with view indices and continuous SE(3) geometry. A three-stage curriculum trains for pose following, flexible reference-to-target generation, and temporal rollout with clean historical target-view tokens; multi-view captions enable test-time text control. The outputs feed directly into off-the-shelf 4D Gaussian Splatting for dynamic 4D reconstruction. Experiments on DNA-Rendering and ActorsHQ are claimed to surpass prior SOTA, with generalization to animals after mixed human-animal training.
Significance. If the reported experiments substantiate the claims, the work offers a practical advance toward scalable 4D content creation from casual videos by eliminating reliance on explicit geometry priors (skeletons, depth, normals). The formulation is falsifiable via the stated metrics on standard datasets and demonstrates cross-category generalization, which strengthens its potential utility for simulation, gaming, AR/VR, and video re-shooting. The reuse of an existing backbone with targeted conditioning is a pragmatic strength.
major comments (2)
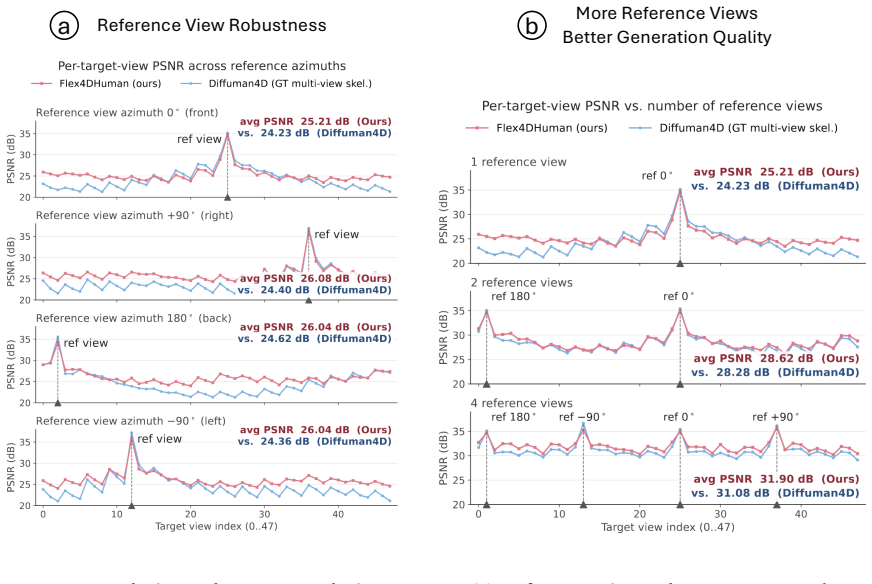
- [Abstract, §5] Abstract and §5 (Experiments): the central claim that Flex4DHuman surpasses prior SOTA on DNA-Rendering and ActorsHQ while generalizing to animals rests on quantitative results that are asserted but not summarized with specific metrics, baselines, or ablation tables in the provided abstract; without these numbers the performance advantage cannot be assessed.
- [§3] §3 (Architecture): the assertion that relative camera-pose positional encoding alone suffices for high-quality multi-view consistency without skeletons/depth/normals is load-bearing; the manuscript should explicitly state how the continuous SE(3) component is encoded and whether any implicit geometric signal is introduced through the backbone or training data.
minor comments (2)
- [§4] §4 (Training curriculum): provide the exact data proportions and loss weighting used in the three-stage schedule and the human-animal mixed training split.
- [Figures, §5] Figure captions and §5: ensure all qualitative results include the exact conditioning inputs (e.g., number of reference views, pose noise level) and direct side-by-side metric comparisons with cited baselines.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the minor revision recommendation. We address the two major comments point-by-point below, agreeing to strengthen the presentation with additional quantitative details and explicit architectural clarifications.
read point-by-point responses
-
Referee: [Abstract, §5] Abstract and §5 (Experiments): the central claim that Flex4DHuman surpasses prior SOTA on DNA-Rendering and ActorsHQ while generalizing to animals rests on quantitative results that are asserted but not summarized with specific metrics, baselines, or ablation tables in the provided abstract; without these numbers the performance advantage cannot be assessed.
Authors: We agree that the abstract would benefit from explicit metrics to allow immediate assessment of the claims. In the revised manuscript we will augment the abstract with concise quantitative highlights (e.g., PSNR/SSIM/LPIPS deltas versus the strongest baselines on DNA-Rendering and ActorsHQ) while preserving the existing word count. The full tables and ablations already appear in §5; the abstract change will simply reference them. revision: yes
-
Referee: [§3] §3 (Architecture): the assertion that relative camera-pose positional encoding alone suffices for high-quality multi-view consistency without skeletons/depth/normals is load-bearing; the manuscript should explicitly state how the continuous SE(3) component is encoded and whether any implicit geometric signal is introduced through the backbone or training data.
Authors: The manuscript already states that conditioning uses only relative camera poses via the five-axis RoPE extension and that no skeletons, depth, or normals are provided at inference or training time. To make the SE(3) encoding fully explicit we will insert a short paragraph in §3.2 detailing the continuous embedding: relative rotation is represented by the 6D continuous representation of Zhou et al. and translation by normalized xyz offsets, both projected into the RoPE frequency basis alongside the view-index axis. We will also add a sentence confirming that the training data contain only the provided camera poses and multi-view captions; any geometric knowledge therefore derives solely from the Wan 2.1 backbone weights, not from additional geometric supervision. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical extension of the external Wan 2.1 backbone via added five-axis positional encoding and a three-stage curriculum. No equations, derivations, or claims reduce any result to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The central claims rest on reported experiments on DNA-Rendering and ActorsHQ rather than internal reductions. The formulation is presented as falsifiable via metrics and generalizes to animals after mixed training, with no uniqueness theorems or ansatzes imported from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spatio-temporal RoPE can be extended with view indices and continuous SE(3) relative camera geometry while preserving the backbone architecture.
Reference graph
Works this paper leans on
-
[1]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, and Di Zhang. Recammaster: Camera-controlled generative rendering from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14834–14844, October 2025
2025
-
[2]
Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints
Jianhong Bai, Menghan Xia, Xintao Wang, Ziyang Yuan, Xiao Fu, Zuozhu Liu, Haoji Hu, Pengfei Wan, and Di Zhang. Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[3]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps: //openreview.net/forum?id=yDo1ynArjj
2024
-
[4]
Dna-rendering: A diverse neural actor repository for high-fidelity human-centric rendering
Wei Cheng, Ruixiang Chen, Wanqi Yin, Siming Fan, Keyu Chen, Honglin He, Huiwen Luo, Zhongang Cai, Jingbo Wang, Yang Gao, Zhengming Yu, Zhengyu Lin, Daxuan Ren, Lei Yang, Ziwei Liu, Chen Change Loy, Chen Qian, Wayne Wu, Dahua Lin, Bo Dai, and Kwan-Yee Lin. Dna-rendering: A diverse neural actor repository for high-fidelity human-centric rendering. In Procee...
2023
-
[5]
Cat3d: Create anything in 3d with multi-view diffusion models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pages 75468–75494, 2024
2024
-
[6]
Actorshq: A high-quality dataset of human perfor- mances for neural rendering
Xiangjun Gao, Chang Zhong, Shuwei Zhang, Jiaming Xiang, Yudong Hong, Yihong Guo, Hong- wen Zhang, Yating Zhang, and Yebin Guo. Actorshq: A high-quality dataset of human perfor- mances for neural rendering. InProceedings of the International Conference on 3D Vision (3DV), 2023
2023
-
[7]
Introducing gemini 3 flash: Benchmarks, global availability, dec 2025
Google. Introducing gemini 3 flash: Benchmarks, global availability, dec 2025. URLhttps: //blog.google/products/gemini/gemini-3-flash/
2025
-
[8]
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024
Pith/arXiv arXiv 2024
-
[9]
Cameractrl ii: Dynamic scene exploration via camera- controlled video diffusion models
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. Cameractrl ii: Dynamic scene exploration via camera- controlled video diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13416–13426, October 2025
2025
-
[10]
Viewdiff: 3d-consistent image generation with text-to-image models
Lukas Höllein, Alja vz Bo vzi vc, Norman Müller, David Novotny, Hung-Yu Tseng, Christian Richardt, Michael Zollhöfer, and Matthias Nie ssner. Viewdiff: 3d-consistent image generation with text-to-image models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[11]
Anyview: Synthesizing any novel view in dynamic scenes.https://arxiv.org/abs/2601.16982, 2026
Basile Van Hoorick, Dian Chen, Shun Iwase, Pavel Tokmakov, Muhammad Zubair Irshad, Igor Vasiljevic, Swati Gupta, Fangzhou Cheng, Sergey Zakharov, and Vitor Campagnolo Guizilini. Anyview: Synthesizing any novel view in dynamic scenes.https://arxiv.org/abs/2601.16982, 2026. 15
arXiv 2026
-
[12]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id= mSiN7i0BYH
2026
-
[13]
Mv-adapter: Multi-view consistent image generation made easy.arXiv preprint arXiv:2412.03632, 2024
Zehuan Huang, Yuan-Chen Guo, Haoran Wang, Ran Yi, Lizhuang Ma, Yan-Pei Cao, and Lu Sheng. Mv-adapter: Multi-view consistent image generation made easy.arXiv preprint arXiv:2412.03632, 2024
arXiv 2024
-
[14]
Instantavatar: Learning avatars from monocular video in 60 seconds
Tianjian Jiang, Xu Chen, Jie Song, and Otmar Hilliges. Instantavatar: Learning avatars from monocular video in 60 seconds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16922–16932, 2023
2023
-
[15]
Neuman: Neural human radiance field from a single video
Wei Jiang, Kwang Moo Yi, Golestaneh Sameh, Minhyuk Kim, ByungOk Ahn, Jaewoong Kim, Sunghyun Kim, and Hanbyul Joo. Neuman: Neural human radiance field from a single video. InProceedings of the European Conference on Computer Vision (ECCV), pages 402–418, 2022
2022
-
[16]
Diffhuman4d: 4d consistent human view synthesis from sparse-view videos with spatio-temporal diffusion models
Yudong Jin, Sida Peng, Xuan Wang, Tao Xie, Zhen Xu, Yifan Yang, Yujun Shen, Hujun Bao, and Xiaowei Zhou. Diffhuman4d: 4d consistent human view synthesis from sparse-view videos with spatio-temporal diffusion models. InInternational Conference on Computer Vision (ICCV), 2025
2025
-
[17]
Sapiens: Foundation for human vision models.arXiv preprint arXiv:2408.12569, 2024
Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, Su Zhaoen, Austin James, Peter Selednik, Stuart Anderson, and Shunsuke Saito. Sapiens: Foundation for human vision models.arXiv preprint arXiv:2408.12569, 2024
arXiv 2024
-
[18]
Cameras as relative positional encoding.Advances in Neural Information Processing Systems (NeurIPS), 2025
Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, and Angjoo Kanazawa. Cameras as relative positional encoding.Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[19]
Animatable gaussians: Learning pose- dependentgaussianmapsforhigh-fidelityhumanavatarmodeling
Zhe Li, Zerong Zheng, Lizhen Wang, and Yebin Liu. Animatable gaussians: Learning pose- dependentgaussianmapsforhigh-fidelityhumanavatarmodeling. InProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19711–19722, 2024
2024
-
[20]
Neural actor: Neural free-view synthesis of human actors with pose control.ACM Transactions on Graphics (ACM SIGGRAPH Asia), 40(6):219:1–219:16, 2021
Lingjie Liu, Marc Habermann, Viktor Rudnev, Kripasindhu Sarkar, Jiatao Gu, and Christian Theobalt. Neural actor: Neural free-view synthesis of human actors with pose control.ACM Transactions on Graphics (ACM SIGGRAPH Asia), 40(6):219:1–219:16, 2021
2021
-
[21]
SMPL: A skinned multi-person linear model.ACM Transactions on Graphics (Proc
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. SMPL: A skinned multi-person linear model.ACM Transactions on Graphics (Proc. SIGGRAPH Asia), 34(6):248:1–248:16, 2015
2015
-
[22]
Artemis: Articulated neural pets with appearance and motion synthesis
Haimin Luo, Teng Xu, Yuheng Jiang, Chenglin Zhou, Qiwei Qiu, Yingliang Zhang, Wei Yang, Lan Xu, and Jingyi Yu. Artemis: Articulated neural pets with appearance and motion synthesis. ACM Transactions on Graphics (TOG), 41(4):164:1–164:19, 2022
2022
-
[23]
Animatableneuralradiancefieldsformodelingdynamichumanbodies
Sida Peng, Junting Dong, Qianqian Wang, Shangzhan Zhang, Qing Shuai, Xiaowei Zhou, and HujunBao. Animatableneuralradiancefieldsformodelingdynamichumanbodies. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14314–14323, 2021
2021
-
[24]
Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans
Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9054–9063, 2021
2021
-
[25]
D-nerf: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10318–10327, 2021
2021
-
[26]
3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, and Siyu Tang. 3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5020–5030, 2024. 16
2024
-
[27]
Gen3c: 3d-informed world-consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[28]
Mvdream: Multi-view diffusion for 3d generation.arXiv preprint arXiv:2308.16512, 2023
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d generation.arXiv preprint arXiv:2308.16512, 2023
Pith/arXiv arXiv 2023
-
[29]
Spark: An advanced 3d gaussian splatting renderer for three.js.https: //github.com/sparkjsdev/spark, 2025
SparkJS Developers. Spark: An advanced 3d gaussian splatting renderer for three.js.https: //github.com/sparkjsdev/spark, 2025
2025
-
[30]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[31]
HunyuanWorld Team, Zhenwei Wang, Yuhao Liu, Junta Wu, Zixiao Gu, Haoyuan Wang, Xuhui Zuo, Tianyu Huang, Wenhuan Li, Sheng Zhang, Yihang Lian, Yulin Tsai, Lifu Wang, Sicong Liu, Puhua Jiang, Xianghui Yang, Dongyuan Guo, Yixuan Tang, Xinyue Mao, Jiaao Yu, Junlin Yu, Jihong Zhang, Meng Chen, Liang Dong, Yiwen Jia, Chao Zhang, Yonghao Tan, Hao Zhang, Zheng Ye...
arXiv 2025
-
[32]
Wan: Open and advanced large-scale video generative models
Wan Team, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
Pith/arXiv arXiv 2025
-
[33]
Chaoyang Wang, Ashkan Mirzaei, Vidit Goel, Willi Menapace, Aliaksandr Siarohin, Avalon Vinella, Michael Vasilkovsky, Ivan Skorokhodov, Vladislav Shakhrai, Sergey Korolev, Sergey Tulyakov, and Peter Wonka. 4real-video-v2: Fused view-time attention and feedforward recon- struction for 4d scene generation.arXiv preprint arXiv:2506.18839, 2025
arXiv 2025
-
[34]
Freetimegs: Free gaussian primitives at anytime and anywhere for dynamic scene reconstruction
Yifan Wang, Peishan Yang, Zhen Xu, Jiaming Sun, Zhanhua Zhang, Yong Chen, Hujun Bao, Sida Peng, and Xiaowei Zhou. Freetimegs: Free gaussian primitives at anytime and anywhere for dynamic scene reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[35]
Yiming Wang, Qihang Zhang, Shengqu Cai, Tong Wu, Jan Ackermann, Zhengfei Kuang, Yang Zheng, Frano Rajič, Siyu Tang, and Gordon Wetzstein. Bullettime: Decoupled control of time and camera pose for video generation.arXiv preprint arXiv:2512.05076, 2025
arXiv 2025
-
[36]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. In ACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[37]
Humannerf: Free-viewpoint rendering of moving people from monocular video
Chung-Yi Weng, Brian Curless, Pratul P Srinivasan, Jonathan T Barron, and Ira Kemelmacher- Shlizerman. Humannerf: Free-viewpoint rendering of moving people from monocular video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16210–16220, 2022. 17
2022
-
[38]
Marble: A multimodal world model, 2025
World Labs. Marble: A multimodal world model, 2025. URLhttps://www.worldlabs.ai/ blog/marble-world-model
2025
-
[39]
4d gaussian splatting for real-time dynamic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20310– 20320, June 2024
2024
-
[40]
Yiming Xie, Chun-Han Yao, Vikram Voleti, Huaizu Jiang, and Varun Jampani. Sv4d: Dynamic 3d contentgenerationwithmulti-frameandmulti-viewconsistency.arXivpreprintarXiv:2407.17470, 2024
arXiv 2024
-
[41]
Matanyone 2: Scaling video matting via a learned quality evaluator
Peiqing Yang, Shangchen Zhou, Kai Hao, and Qingyi Tao. Matanyone 2: Scaling video matting via a learned quality evaluator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[42]
Trajectorycrafter: Redirecting camera trajectory formonocularvideosviadiffusionmodels
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory formonocularvideosviadiffusionmodels. InProceedingsoftheIEEE/CVFInternationalConference on Computer Vision (ICCV), pages 100–111, October 2025
2025
-
[43]
Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien- Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[44]
Cheng Zhang, Boying Li, Meng Wei, Yan-Pei Cao, Camilo Cruz Gambardella, Dinh Phung, and Jianfei Cai. Unified camera positional encoding for controlled video generation.arXiv preprint arXiv:2512.07237, 2026
arXiv 2026
-
[45]
Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view synthesis
Shunyuan Zheng, Boyao Zhou, Ruobing Shao, Boning Liu, Shengping Zhang, Liang Nie, and Yebin Liu. Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1704–1714, 2024
2024
-
[46]
Kenny and Fu, Kailiang and Aguina-Kang, Rio and Morris, Stewart and Ritchie, Daniel , title =
Yihao Zhi, Chenghong Li, Hongjie Liao, Xihe Yang, Zhengwentai Sun, Jiahao Chang, Xiaodong Cun, Wensen Feng, and Xiaoguang Han. Mv-performer: Taming video diffusion model for faithful and synchronized multi-view performer synthesis. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, SA Conference Papers ’25, New York, NY, USA, 2025. Association for...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.