Automated reproducibility assessments in the social and behavioral sciences using large language models
Pith reviewed 2026-06-27 06:28 UTC · model grok-4.3
The pith
Large language models can automate reproducibility assessments by reanalyzing published studies and matching original conclusions in 80% of cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
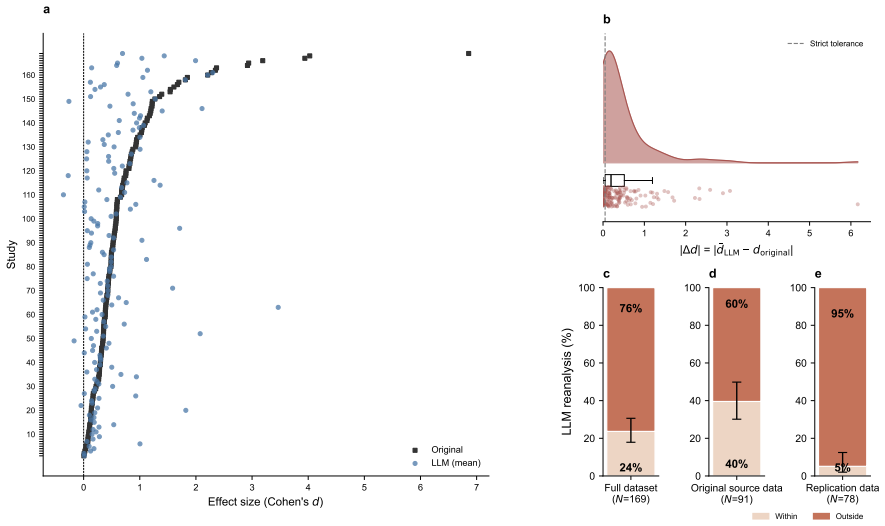
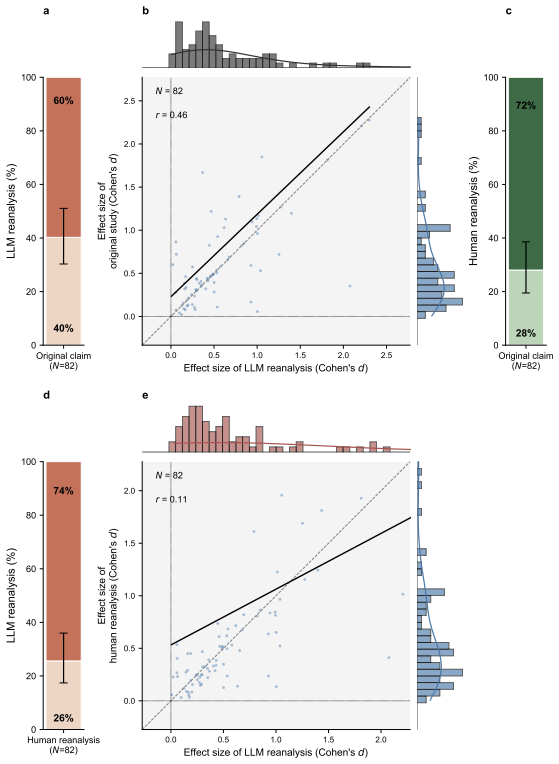
Using an LLM pipeline on N=180 published studies with predefined claims, the model reached the same qualitative conclusion as the original study in 80% of the 169 cases with viable effect size estimates and recovered the original effect sizes within +/-0.05 Cohen's d in 24% of studies. In the human-reanalysis subset, the LLM matched the original qualitative conclusion in 95% of studies (compared to 83% for humans) and recovered effect sizes in 40% of cases (compared to 28% for humans).
What carries the argument
An LLM pipeline that takes study data and generates statistical reanalyses to compute effect sizes and compare conclusions to the originals.
If this is right
- LLMs can support systematic audits of empirical results at larger scales than manual reanalysis allows.
- LLMs can act as a first-pass screening tool to flag studies for deeper expert review.
- Performance on qualitative conclusions is comparable to that of human reanalysts.
- LLMs should augment rather than replace expert judgment given current limitations on precise effect-size recovery.
Where Pith is reading between the lines
- The method could be tested on studies from other disciplines to see if agreement rates transfer.
- Integration into journal submission systems might allow automated reproducibility flags before publication.
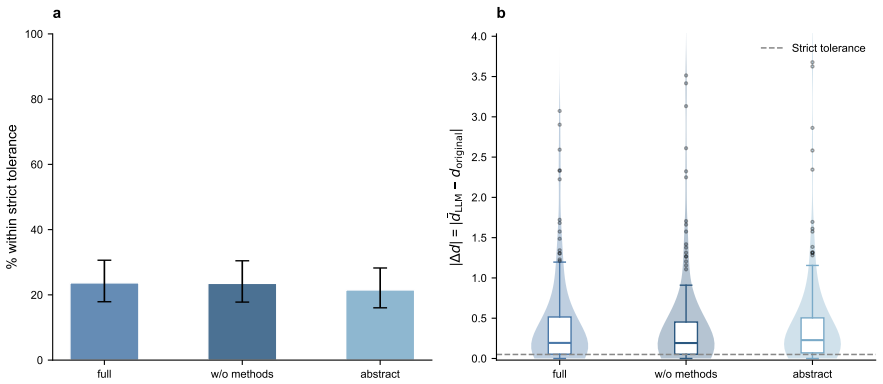
- Improvements in LLM reasoning could raise the rate of exact effect-size recovery above the current 24%.
- A hybrid workflow where LLMs handle initial screening and humans resolve ambiguous cases might increase overall throughput.
Load-bearing premise
The 180 studies with predefined claims represent the broader range of social and behavioral science research well enough for the results to generalize.
What would settle it
Apply the same LLM pipeline to a fresh, randomly sampled set of 100 studies without predefined claims and measure whether qualitative agreement stays near 80%.
Figures

read the original abstract
Reproducibility in the social and behavioral sciences is typically evaluated by independent researchers who reanalyze the original data to assess whether the published findings can be recovered. However, such approaches are resource-intensive and difficult to scale. Here, we show that large language models (LLMs) can automate reproducibility assessments. Using N = 180 published studies with predefined claims from the behavioral and social sciences, we compare LLM-generated analyses with the original findings. For 11 studies, the LLM pipeline could not produce a viable effect size estimate. For the remaining studies, the LLM reached the same qualitative conclusion as the original study in 80% of cases, and recovered the original effect sizes (using a +/-0.05 tolerance in Cohen's d) in 24% of studies. In a subset with human reanalyses, the LLM reached the same qualitative conclusion as the original study in 95% of studies, similar to human reanalysts (83%), and the LLM recovered the original effect sizes using a +/-0.05 tolerance in 40% of studies, again broadly similar to human reanalysts (28%). Given the current capabilities and limitations of LLMs, the findings show that LLMs can support systematic audits of empirical results rather than substitute expert judgment. As such, LLMs can serve as a scalable screening tool to improve the rigor and reproducibility in empirical research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that large language models can automate reproducibility assessments for empirical studies in the social and behavioral sciences. On a set of N=180 published studies with predefined claims, an LLM pipeline produced viable effect-size estimates for 169 studies and matched the original study's qualitative conclusion in 80% of those cases while recovering the original effect size (within ±0.05 Cohen's d) in 24%. In a human-reanalysis subset the LLM matched originals at 95% (vs. 83% for humans) and recovered effect sizes at 40% (vs. 28% for humans). The authors conclude that LLMs can serve as a scalable screening tool to support systematic audits rather than substitute for expert judgment.
Significance. If the performance numbers generalize beyond the tested sample and the pipeline details are made reproducible, the work would demonstrate a practical, low-cost method for large-scale reproducibility screening. The direct empirical comparison to both original claims and human reanalyses is a strength, as is the explicit framing that LLMs are not a full substitute. The absence of selection criteria and implementation details, however, prevents a firm assessment of how far the result can be extrapolated to typical papers in the field.
major comments (2)
- [Methods] Methods (or equivalent section describing the LLM pipeline): the manuscript supplies no information on the specific LLM used, the prompting strategy, the procedure for extracting effect sizes from text or code, or how missing data and non-viable outputs were handled. These omissions make the reported 80% qualitative agreement and 24% effect-size recovery rates impossible to evaluate or replicate, directly undermining the central performance claims.
- [Data and sample description] Data and sample description: the 180 studies are described only as 'published studies with predefined claims'; no sampling frame, inclusion/exclusion criteria, or justification for representativeness is provided. Because the screening-tool conclusion rests on the assumption that performance on this set predicts usefulness on typical social/behavioral-science papers, the lack of selection details is load-bearing for the generalizability claim.
minor comments (1)
- [Abstract] The abstract states that the LLM 'reached the same qualitative conclusion as the original study in 95% of studies' in the human-reanalysis subset; it would be clearer to specify the exact size of that subset and whether the 95% figure is computed on the same denominator as the 80% figure.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that additional details on the LLM pipeline and study sample are needed to strengthen the manuscript and will revise accordingly.
read point-by-point responses
-
Referee: [Methods] Methods (or equivalent section describing the LLM pipeline): the manuscript supplies no information on the specific LLM used, the prompting strategy, the procedure for extracting effect sizes from text or code, or how missing data and non-viable outputs were handled. These omissions make the reported 80% qualitative agreement and 24% effect-size recovery rates impossible to evaluate or replicate, directly undermining the central performance claims.
Authors: We agree that the manuscript currently lacks these implementation details. In the revised version we will add a dedicated Methods section specifying the LLM model, prompting strategy, effect-size extraction procedure, and handling of missing or non-viable outputs. This will directly address the replicability concern. revision: yes
-
Referee: [Data and sample description] Data and sample description: the 180 studies are described only as 'published studies with predefined claims'; no sampling frame, inclusion/exclusion criteria, or justification for representativeness is provided. Because the screening-tool conclusion rests on the assumption that performance on this set predicts usefulness on typical social/behavioral-science papers, the lack of selection details is load-bearing for the generalizability claim.
Authors: We acknowledge that the current description of the 180 studies is insufficient. We will expand the Data section in revision to include the sampling frame, explicit inclusion/exclusion criteria, and any justification for representativeness that can be provided from the study selection process. revision: yes
Circularity Check
No circularity: results are direct empirical comparisons to external original studies and human reanalyses
full rationale
The paper reports measured agreement rates (80% qualitative match, 24% effect-size recovery) between LLM reanalyses and the original published findings on N=180 studies, plus a human-reanalysis subset. These quantities are obtained by direct comparison to external benchmarks rather than by fitting parameters inside the paper and relabeling them as predictions. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain. The representativeness of the 180 studies is a sampling/generalizability limitation, not a circular reduction of the reported metrics to the paper's own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- effect size tolerance =
+/-0.05
axioms (1)
- domain assumption The 180 studies possess clearly defined claims and data that can be reanalyzed by an LLM without additional domain-specific preprocessing rules.
Reference graph
Works this paper leans on
-
[1]
Nature652, 126–134 (2026)
Miske, O.et al.Investigating the reproducibility of the social and behavioural sciences. Nature652, 126–134 (2026)
2026
-
[2]
Nature652, 135–142 (2026)
Aczel, B.et al.Investigating the analytical robustness of the social and behavioural sciences. Nature652, 135–142 (2026)
2026
-
[3]
Nature652, 151–156 (2026)
Brodeur, A.et al.Reproducibility and robustness of economics and political science research. Nature652, 151–156 (2026)
2026
-
[4]
E.et al.Analytic reproducibility in articles receiving open data badges at the journalPsychological Science: An observational study.Royal Society Open Science8, 201494 (2021)
Hardwicke, T. E.et al.Analytic reproducibility in articles receiving open data badges at the journalPsychological Science: An observational study.Royal Society Open Science8, 201494 (2021)
2021
-
[5]
& Cook, N
Brodeur, A., Mikola, D. & Cook, N. Mass reproducibility and replicability: A new hope. Tech. Rep., SSRN (2024)
2024
-
[6]
Fišar, M.et al.Reproducibility inManagement Science.Management Science70, 1343–1356 (2024)
2024
-
[7]
Nosek, B.et al.Reimagining and diversifying assessment of the credibility of research find- ings (2026)
2026
-
[8]
H.et al.Investigating the replicability of the social and behavioural sciences
Tyner, A. H.et al.Investigating the replicability of the social and behavioural sciences. Nature652, 143–150 (2026)
2026
-
[9]
Parsons, S.et al.A community-sourced glossary of open scholarship terms.Nature Human Behaviour6, 312–318 (2022)
2022
-
[10]
Estimating the reproducibility of psychological science.Science 349, aac4716 (2015)
Open Science Collaboration. Estimating the reproducibility of psychological science.Science 349, aac4716 (2015). 26
2015
-
[11]
Peng, R. D. Reproducible research in computational science.Science334, 1226–1227 (2011)
2011
-
[12]
Sun, M.et al.LAMBDA: A large model based data agent.Journal of the American Statistical Association121, 1–13 (2026)
2026
-
[13]
A., MacKnight, R., Kline, B
Boiko, D. A., MacKnight, R., Kline, B. & Gomes, G. Autonomous chemical research with large language models.Nature624, 570–578 (2023)
2023
-
[14]
In Ku, L.-W., Martins, A
Qian, C.et al.ChatDev: Communicative agents for software development. In Ku, L.-W., Martins, A. & Srikumar, V . (eds.)Proceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), 15174–15186 (Association for Computational Linguistics, Bangkok, Thailand, 2024)
2024
-
[15]
Lu, C.et al.Towards end-to-end automation of AI research.Nature651, 914–919 (2026)
2026
- [16]
-
[17]
& Hwang, S
Seo, M., Baek, J., Lee, S. & Hwang, S. J. Paper2Code: Automating code generation from scientific papers in machine learning.International Conference on Learning Representations (ICLR)(2026)
2026
-
[18]
& Tucker, J
Alizadeh, M., Mosleh, M., Gilardi, F. & Tucker, J. A. Evaluating AI coding agents in social science reproducibility (2026)
2026
-
[19]
Kohler, B., Zollikofer, D., Einsiedler, J., Hoyle, A. & Ash, E. Read the paper, write the code: Agentic reproduction of social-science results.arXiv:2604.21965(2026)
Pith/arXiv arXiv 2026
-
[20]
Miao, J., Davis, J. R., Zhang, Y ., Pritchard, J. K. & Zou, J. Paper2Agent: Reimagining research papers as interactive and reliable AI agents.arXiv:2509.06917(2025). 27
arXiv 2025
-
[21]
Song, Z.et al.Evaluating large language models in scientific discovery.arXiv:2512.15567 (2025)
Pith/arXiv arXiv 2025
-
[22]
Nature Computational Science6, 301–315 (2026)
Shao, E.et al.SciSciGPT: Advancing human–AI collaboration in the science of science. Nature Computational Science6, 301–315 (2026)
2026
-
[23]
Zhang, S., Fan, J., Fan, M., Li, G. & Du, X. DeepAnalyze: Agentic large language models for autonomous data science.arXiv:2510.16872(2025)
arXiv 2025
-
[24]
Gottweis, J.et al.Accelerating scientific discovery with co-scientist.Nature(2026)
2026
-
[25]
E.et al.A multi-agent system for automating scientific discovery.Nature forthcoming (2026)
Ghareeb, A. E.et al.A multi-agent system for automating scientific discovery.Nature forthcoming (2026)
2026
-
[26]
Yamada, Y .et al.The AI Scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv:2504.08066(2025)
Pith/arXiv arXiv 2025
-
[27]
Song, X.et al.StatLLM: A dataset for evaluating the performance of large language models in statistical analysis.Scientific Data13, 369 (2026)
2026
-
[28]
URL osf.io/preprints/socarxiv/46mnb_v1
Alipourfard, N.et al.Systematizing confidence in open research and evidence (score) (2021). URL osf.io/preprints/socarxiv/46mnb_v1
2021
-
[29]
Silberzahn, R.et al.Many analysts, one data set: Making transparent how variations in analytic choices affect results.Advances in Methods and Practices in Psychological Science 1, 337–356 (2018)
2018
-
[30]
Botvinik-Nezer, R.et al.Variability in the analysis of a single neuroimaging dataset by many teams.Nature582, 84–88 (2020)
2020
-
[31]
& Vanpaemel, W
Steegen, S., Tuerlinckx, F., Gelman, A. & Vanpaemel, W. Increasing transparency through a multiverse analysis.Perspectives on Psychological Science11, 702–712 (2016). 28
2016
-
[32]
Breznau, N.et al.Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty.Proceedings of the National Academy of Sciences119, e2203150119 (2022)
2022
-
[33]
many analysts, one data set
Auspurg, K. & Brüderl, J. Has the credibility of the social sciences been credibly destroyed? Reanalyzing the “many analysts, one data set” project.Socius7, 23780231211024421 (2021)
2021
-
[34]
Scheel, A. M. Why most psychological research findings are not even wrong.Infant and Child Development31, e2295 (2022)
2022
-
[35]
& Lewandowsky, S
Oberauer, K. & Lewandowsky, S. Addressing the theory crisis in psychology.Psychonomic Bulletin & Review26, 1596–1618 (2019)
2019
-
[36]
Coretta, S.et al.Multidimensional signals and analytic flexibility: Estimating degrees of freedom in human-speech analyses.Advances in Methods and Practices in Psychological Science6, 25152459231162567 (2023)
2023
-
[37]
fishing expedition
Gelman, A. & Loken, E. The garden of forking paths: Why multiple comparisons can be a problem, even when there is no “fishing expedition” or “p-hacking” and the research hypoth- esis was posited ahead of time. Tech. Rep., Department of Statistics, Columbia University, New York, NY (2013)
2013
-
[38]
J., Burford, B
Patel, C. J., Burford, B. & Ioannidis, J. P. Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations.Journal of Clinical Epidemiology68, 1046–1058 (2015)
2015
-
[39]
& Aczel, B
Wagenmakers, E.-J., Sarafoglou, A. & Aczel, B. One statistical analysis must not rule them all.Nature605, 423–425 (2022). 29
2022
-
[40]
statcheck
Nuijten, M. B. & Polanin, J. R. “statcheck”: Automatically detect statistical reporting in- consistencies to increase reproducibility of meta-analyses.Research Synthesis Methods11, 574–579 (2020)
2020
-
[41]
Bertran, M., Fogliato, R. & Wu, Z. S. Many AI analysts, one dataset: Navigating the agentic data science multiverse.arXiv:2602.18710(2026)
arXiv 2026
-
[42]
IZA Discussion Paper 17645, Institute of Labor Economics (IZA), Bonn (2025)
Brodeur, A.et al.Comparing human-only, AI-assisted, and AI-led teams on assessing re- search reproducibility in quantitative social science. IZA Discussion Paper 17645, Institute of Labor Economics (IZA), Bonn (2025)
2025
-
[43]
S., Kapoor, S., Nagdir, N., Stroebl, B
Siegel, Z. S., Kapoor, S., Nagdir, N., Stroebl, B. & Narayanan, A. CORE-Bench: Fostering the credibility of published research through a computational reproducibility agent bench- mark.Transactions on Machine Learning Research(2024)
2024
-
[44]
InInterna- tional Conference on Machine Learning, 56843–56873 (2025)
Starace, G.et al.PaperBench: Evaluating AI’s ability to replicate AI research. InInterna- tional Conference on Machine Learning, 56843–56873 (2025)
2025
-
[45]
G., Blazey, P., Moher, D., Khan, K
Wrightson, J. G., Blazey, P., Moher, D., Khan, K. M. & Ardern, C. L. GPT for RCTs? Using AI to determine adherence to clinical trial reporting guidelines.BMJ Open15, e088735 (2025)
2025
-
[46]
A., Ebersole, C
Nosek, B. A., Ebersole, C. R., DeHaven, A. C. & Mellor, D. T. The preregistration revolution. Proceedings of the National Academy of Sciences115, 2600–2606 (2018)
2018
-
[47]
& Heyes, A
Brodeur, A., Cook, N. & Heyes, A. Methods matter:p-hacking and publication bias in causal analysis in economics.American Economic Review110, 3634–3660 (2020)
2020
-
[48]
P., Nelson, L
Simmons, J. P., Nelson, L. D. & Simonsohn, U. False-positive psychology: Undisclosed flex- ibility in data collection and analysis allows presenting anything as significant.Psychological Science22, 1359–1366 (2011). 30
2011
-
[49]
Nori, H., King, N., McKinney, S. M., Carignan, D. & Horvitz, E. Capabilities of GPT-4 on medical challenge problems.arXiv:2303.13375(2023)
Pith/arXiv arXiv 2023
-
[50]
InFindings of the Association for Computational Linguistics: EMNLP 2023, 10776–10787 (Association for Computational Linguistics, 2023)
Sainz, O.et al.NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, 10776–10787 (Association for Computational Linguistics, 2023)
2023
-
[51]
& Auspurg, K
Krähmer, D., Schächtele, L. & Auspurg, K. Code sharing and reproducibility in survey-based social research: Evidence from a large-scale audit.Royal Society Open Science13, 251997 (2026)
2026
-
[52]
Holzmeister, F.et al.Heterogeneity in effect size estimates.Proceedings of the National Academy of Sciences121, e2403490121 (2024)
2024
-
[53]
A., Stoevenbelt, A
van Assen, M. A., Stoevenbelt, A. H. & van Aert, R. C. The end justifies all means: Ques- tionable conversion of different effect sizes to a common effect size measure.Religion, Brain & Behavior13, 345–347 (2023)
2023
-
[54]
A., Etz, A., Lucas, R
Zwaan, R. A., Etz, A., Lucas, R. E. & Donnellan, M. B. Making replication mainstream. Behavioral and Brain Sciences41, e120 (2018)
2018
-
[55]
& Miguel, E
Brodeur, A., Dreber, A., Hoces de la Guardia, F. & Miguel, E. Replication games: How to make reproducibility research more systematic.Nature621, 684–686 (2023)
2023
-
[56]
https://github.com/marton-balazs-kovacs/multi100/blob/ 47c0b8c6dd68e19eb80fa8843dce18f0d3655ae1/analysis/multi100_raw_processed.qmd# L160-L165
Multi100 conversion code. https://github.com/marton-balazs-kovacs/multi100/blob/ 47c0b8c6dd68e19eb80fa8843dce18f0d3655ae1/analysis/multi100_raw_processed.qmd# L160-L165
-
[57]
How to write effective prompts for large language models.Nature Human Behaviour 8, 611–615 (2024)
Lin, Z. How to write effective prompts for large language models.Nature Human Behaviour 8, 611–615 (2024). 31
2024
-
[58]
Prompt engineering with ChatGPT: A guide for academic writers.Annals of Biomedical Engineering51, 2629–2633 (2023)
Giray, L. Prompt engineering with ChatGPT: A guide for academic writers.Annals of Biomedical Engineering51, 2629–2633 (2023)
2023
-
[59]
Feuerriegel, S.et al.Using natural language processing to analyse text data in behavioural science.Nature Reviews Psychology4, 96–111 (2025)
2025
-
[60]
Adaptive thinking
Anthropic. Adaptive thinking. Claude API Documentation (2026). URL https://platform. claude.com/docs/en/build-with-claude/adaptive-thinking. Accessed: 2026-06-22
2026
-
[61]
Inspect AI: Framework for Large Language Model Evaluations
AI Security Institute, UK. Inspect AI: Framework for Large Language Model Evaluations. https://github.com/UKGovernmentBEIS/inspect_ai (2024). Software
2024
-
[62]
Nature Human Behaviour(2026)
Feuerriegel, S.et al.A reporting checklist for large language models in behavioural science. Nature Human Behaviour(2026). 32 Acknowledgments Funding from the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under the National Research Data Infrastructure – NFDI 27/1-2026, project number 460037581 is ac- knowledged. SF acknowledges fundin...
2026
-
[63]
Do you have knowledge of this specific paper in your training data? (yes / uncertain / no)
-
[64]
If yes: What is the main finding regarding the claim above? Be specific
-
[65]
If yes: What is the direction of the effect? (positive / negative / null / unknown)
-
[66]
If yes: Report the main test statistic in this structured format, type (z/t/F/chi2/r), numeric value, degrees of freedom (if applicable), and sample size
-
[67]
unknown" for any field you do not know. ‘‘‘probe_results PAPER_KNOWN: [yes / uncertain / no] RECALLED_FINDING: [brief description of finding, or
How confident are you in your recall of this paper’s results? (1-10, where 10 = certain) Fill in the block below. Use "unknown" for any field you do not know. ‘‘‘probe_results PAPER_KNOWN: [yes / uncertain / no] RECALLED_FINDING: [brief description of finding, or "unknown"] RECALLED_DIRECTION: [positive / negative / null / unknown] RECALLED_STAT_TYPE: [z ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.