Prompt2Effect: Training-Free Image-to-Video Model Specialization via LoRA Generation
Pith reviewed 2026-07-02 22:20 UTC · model grok-4.3
The pith
A hypernetwork generates effect-specific LoRA weights for image-to-video models from prompts and base weights in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prompt2Effect is a weight-driven hypernetwork that amortizes per-effect training by directly synthesizing effect-specific LoRA weights in a single forward pass, conditioned on the frozen base model weights to ground the prediction in each layer's structural geometry and using an SVD-canonicalized parameterization to resolve factorization ambiguity and stabilize large-scale synthesis.
What carries the argument
The weight-driven hypernetwork that predicts LoRA matrices from base model weights plus prompt semantics via SVD-canonicalized parameterization.
If this is right
- Generated LoRAs achieve on-par or better video quality and effect alignment than per-effect fine-tuning.
- Specialization cost falls from 56 GPU training hours to 3.3 seconds of inference.
- Predicted weights improve final performance and accelerate any follow-on fine-tuning by approximately 10x.
- The approach supports interactive control by allowing rapid switching between effects.
Where Pith is reading between the lines
- Real-time pipelines could apply new effects on demand without storing separate adapters.
- The same conditioning strategy might transfer to other parameter-efficient adaptation techniques beyond LoRA.
- Scaling the hypernetwork training set to cover more diverse effects would be the main route to broader generalization.
Load-bearing premise
A hypernetwork conditioned only on frozen base model weights and prompt semantics can produce effective LoRA weights that work for arbitrary new effects without any per-effect training data or optimization.
What would settle it
Measure video quality and effect alignment on a held-out visual effect never seen during hypernetwork training and compare the generated LoRA directly against a freshly trained LoRA for that same effect.
Figures




read the original abstract
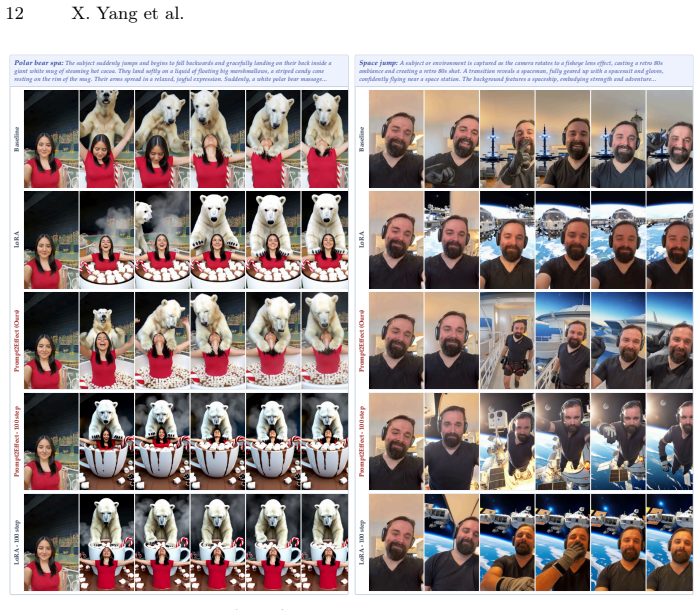
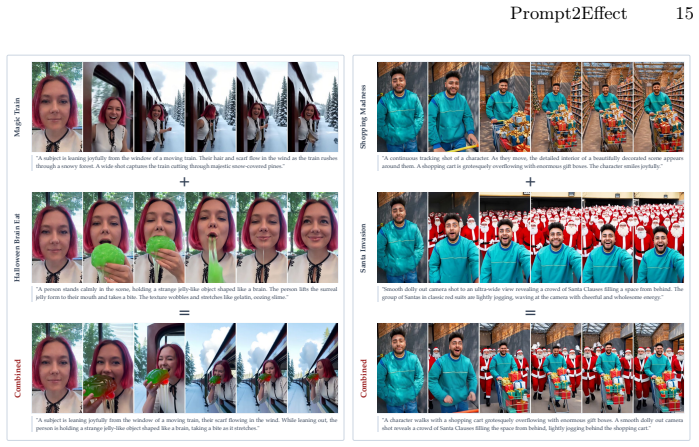
While personalizing Image-to-Video (I2V) diffusion models with specific visual effects is increasingly demanded for high-end generation, current practice requires training a separate Low-Rank Adaptation (LoRA) module for each effect, incurring substantial data curation and iterative optimization costs that hinder interactive control. We present Prompt2Effect, a weight-driven hypernetwork that amortizes per-effect training by directly synthesizing effect-specific LoRA weights in a single forward pass. Unlike prior hypernetworks that regress adapter weights purely from semantics, Prompt2Effect is explicitly conditioned on the frozen base model weights, grounding prediction in the structural geometry of each layer. Furthermore, instead of predicting raw LoRA matrices, we introduce an SVD-canonicalized parameterization that resolves factorization ambiguity and stabilizes large-scale synthesis. Extensive experiments demonstrate that Prompt2Effect achieves on-par or superior video quality and effect alignment compared to conventional LoRA fine-tuning, while reducing the computational cost from 56 GPU training hours to 3.3 seconds of hypernetwork inference. When used as initialization for subsequent fine-tuning, our predicted weights further improve final performance and accelerate optimization by approximately 10x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Prompt2Effect, a weight-driven hypernetwork that synthesizes effect-specific LoRA weights for frozen Image-to-Video diffusion models in a single forward pass. The hypernetwork is conditioned on both prompt semantics and the base model weights, employs an SVD-canonicalized parameterization to resolve factorization ambiguity, and is claimed to achieve on-par or superior video quality and effect alignment relative to per-effect LoRA fine-tuning while reducing cost from 56 GPU hours to 3.3 seconds of inference; the synthesized weights are also shown to accelerate subsequent fine-tuning by ~10x when used as initialization.
Significance. If the empirical claims hold, the approach would substantially lower the barrier to interactive personalization of I2V models by amortizing adaptation across effects. The explicit base-weight conditioning and SVD canonicalization address documented limitations of prior semantic-only hypernetworks and could influence adapter-generation methods more broadly.
major comments (3)
- [Abstract and §4] Abstract and §4: the central claim of on-par or superior performance and generalization to arbitrary new effects is asserted via 'extensive experiments,' yet the manuscript supplies no datasets, metrics, baselines, number of training effects, or OOD test protocol. Without these, it is impossible to determine whether the data support the generalization assumption.
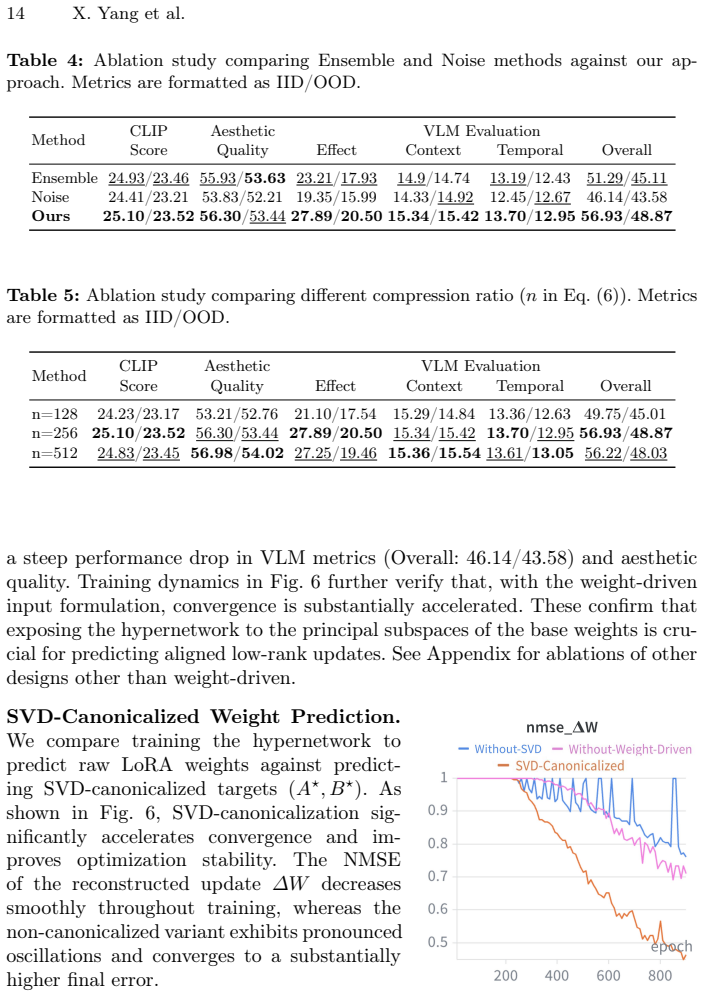
- [§3.2] §3.2: the novelty of conditioning on frozen base-model weights (as opposed to prompt semantics alone) is load-bearing for the architectural contribution, but no ablation isolating this conditioning is reported; the performance gain attributable to base-weight input versus prompt input therefore remains unquantified.
- [§4.3] §4.3: the claim that the method works for 'arbitrary' unseen effects rests on the training distribution of effects spanning the space of possible visual effects, yet no characterization of effect diversity, no explicit out-of-distribution evaluation protocol, and no failure-case analysis are provided.
minor comments (1)
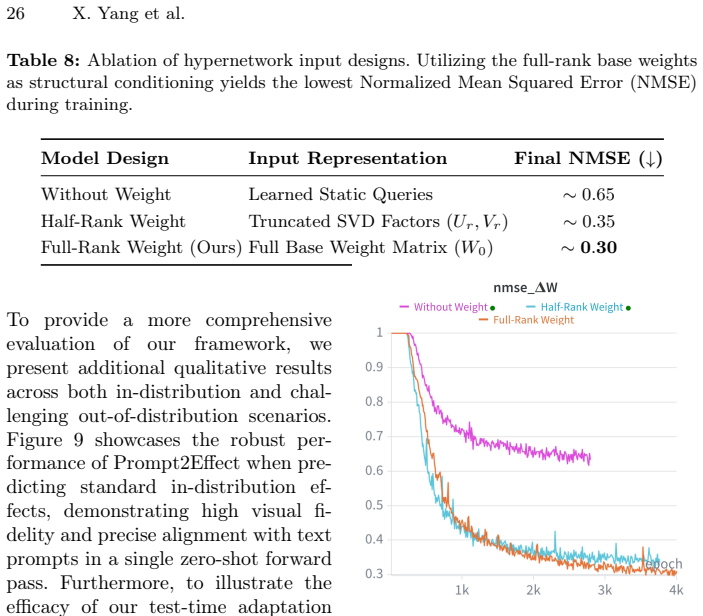
- [§3.1] The SVD-canonicalized parameterization is introduced to resolve factorization ambiguity, but the precise canonicalization steps (ordering of singular vectors, sign resolution, etc.) would benefit from an explicit equation or algorithm box for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the major comments point-by-point below and outline the revisions we will make to improve the clarity and completeness of the experimental section.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4: the central claim of on-par or superior performance and generalization to arbitrary new effects is asserted via 'extensive experiments,' yet the manuscript supplies no datasets, metrics, baselines, number of training effects, or OOD test protocol. Without these, it is impossible to determine whether the data support the generalization assumption.
Authors: We agree with the referee that the manuscript would benefit from a more explicit and structured presentation of the experimental setup. While §4 describes the experiments conducted, we will revise the section to include a clear summary table or subsection listing the datasets, metrics, baselines, the number of training effects, and the out-of-distribution test protocol used to evaluate generalization. revision: yes
-
Referee: [§3.2] §3.2: the novelty of conditioning on frozen base-model weights (as opposed to prompt semantics alone) is load-bearing for the architectural contribution, but no ablation isolating this conditioning is reported; the performance gain attributable to base-weight input versus prompt input therefore remains unquantified.
Authors: We acknowledge that an ablation study isolating the effect of base-model weight conditioning is important to quantify its contribution. We will add this ablation experiment in the revised manuscript, reporting performance metrics for variants with and without the base-weight conditioning. revision: yes
-
Referee: [§4.3] §4.3: the claim that the method works for 'arbitrary' unseen effects rests on the training distribution of effects spanning the space of possible visual effects, yet no characterization of effect diversity, no explicit out-of-distribution evaluation protocol, and no failure-case analysis are provided.
Authors: We agree that additional details on effect diversity, an explicit OOD protocol, and failure case analysis would better support the generalization claims. In the revised version, we will expand §4.3 to include a characterization of the training effects, a defined OOD evaluation protocol, and an analysis of observed failure cases. revision: yes
Circularity Check
No circularity; empirical architectural proposal with independent experimental validation
full rationale
The paper introduces Prompt2Effect as a hypernetwork that synthesizes LoRA weights from base-model weights and prompt semantics, with an SVD-canonicalized parameterization. Performance claims rest on direct comparisons to conventional LoRA fine-tuning via experiments, not on any derivation that reduces to fitted inputs or self-citations by construction. No equations or steps in the abstract equate predictions to their own training signals, and the central premise (amortized synthesis for unseen effects) is presented as an empirical hypothesis rather than a self-referential identity. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Abdal,R.,Patashnik,O.,Deyneka,E.,Chen,H.,Siarohin,A.,Tulyakov,S.,Cohen- Or, D., Aberman, K.: Zero-shot dynamic concept personalization with grid-based lora. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–10 (2025)
2025
-
[2]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers
Abdal, R., Patashnik, O., Skorokhodov, I., Menapace, W., Siarohin, A., Tulyakov, S., Cohen-Or, D., Aberman, K.: Dynamic concepts personalization from single videos. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–9 (2025)
2025
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
arXiv preprint arXiv:2510.20888 (2025)
Bian, Y., Chen, X., Li, Z., Zhi, T., Sang, S., Luo, L., Xu, Q.: Video-as-prompt: Unified semantic control for video generation. arXiv preprint arXiv:2510.20888 (2025)
-
[5]
Boutsidis, C., Woodruff, D.P.: Optimal cur matrix decompositions (2014),https: //arxiv.org/abs/1405.7910
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
Text-to-lora: Instant transformer adaption.arXiv preprint arXiv:2506.06105, 2025
Charakorn, R., Cetin, E., Tang, Y., Lange, R.T.: Text-to-lora: Instant transformer adaption. arXiv preprint arXiv:2506.06105 (2025)
-
[7]
arXiv preprint arXiv:2502.16894 (2025)
Fan, C., Lu, Z., Liu, S., Gu, C., Qu, X., Wei, W., Cheng, Y.: Make lora great again: Boosting lora with adaptive singular values and mixture-of-experts optimization alignment. arXiv preprint arXiv:2502.16894 (2025)
-
[8]
Ha, D., Dai, A., Le, Q.V.: Hypernetworks. arXiv preprint arXiv:1609.09106 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Hamm, K., Huang, L.: Perspectives on cur decompositions (2019),https://arxiv. org/abs/1907.12668
-
[10]
arXiv preprint arXiv:2512.08785 (2025)
Hao, Y., Xu, M., Ye, C., Qin, J., Lu, S., Qin, Y., Han, X.: Lofa: Learning to predict personalized priors for fast adaptation of visual generative models. arXiv preprint arXiv:2512.08785 (2025)
-
[11]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[13]
arXiv e-prints pp
Junhao Zhang, D., Li, D., Le, H., Shou, M.Z., Xiong, C., Sahoo, D.: Moonshot: Towards controllable video generation and editing with multimodal conditions. arXiv e-prints pp. arXiv–2401 (2024)
2024
-
[14]
arXiv preprint arXiv:2503.24354 (2025)
Khan, R.M.S., Tang, D., Li, P., Wang, K., Chen, T.: Oral: Prompting your large- scale loras via conditional recurrent diffusion. arXiv preprint arXiv:2503.24354 (2025)
-
[15]
In: The Thirty-ninth Annual Con- ference on Neural Information Processing Systems (2025),https://openreview
Liang, Z., Tang, D., Zhou, Y., Zhao, X., Shi, M., Zhao, W., Li, Z., Wang, P., Schürholt, K., Borth, D., Bronstein, M.M., You, Y., Wang, Z., Wang, K.: Drag- and-drop LLMs: Zero-shot prompt-to-weights. In: The Thirty-ninth Annual Con- ference on Neural Information Processing Systems (2025),https://openreview. net/forum?id=fTkBZLxBzV
2025
-
[16]
arXiv preprint arXiv:2502.05979 (2025) Prompt2Effect 17
Liu, X., Zeng, A., Xue, W., Yang, H., Luo, W., Liu, Q., Guo, Y.: Vfx creator: Animated visual effect generation with controllable diffusion transformer. arXiv preprint arXiv:2502.05979 (2025) Prompt2Effect 17
-
[17]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Lv, C., Li, L., Zhang, S., Chen, G., Qi, F., Zhang, N., Zheng, H.T.: Hyperlora: Efficient cross-task generalization via constrained low-rank adapters generation. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 16376–16393 (2024)
2024
-
[18]
In: ACM SIGGRAPH (2026)
Ma, Y., Ye, X., Wang, Q., Wang, Y., Liu, H., Zhang, Y., Wang, X., Che, Y., Mo, S., Liang, P., Zhan, F., Chen, Q.: Easyvfx: Frequency-driven decoupling for resource-efficient vfx generation. In: ACM SIGGRAPH (2026)
2026
-
[19]
arXiv preprint arXiv:2508.07981 (2025)
Mao, F., Hao, A., Chen, J., Liu, D., Feng, X., Zhu, J., Wu, M., Chen, C., Wu, J., Chu, X.: Omni-effects: Unified and spatially-controllable visual effects generation. arXiv preprint arXiv:2508.07981 (2025)
-
[20]
In: The Thirty-eighth Annual Con- ference on Neural Information Processing Systems (2024),https://openreview
Meng, F., Wang, Z., Zhang, M.: PiSSA: Principal singular values and singular vectors adaptation of large language models. In: The Thirty-eighth Annual Con- ference on Neural Information Processing Systems (2024),https://openreview. net/forum?id=6ZBHIEtdP4
2024
-
[21]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[22]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[24]
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth:Finetuningtext-to-imagediffusionmodelsforsubject-drivengeneration.In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 22500–22510 (2023)
2023
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ruiz, N., Li, Y., Jampani, V., Wei, W., Hou, T., Pritch, Y., Wadhwa, N., Rubin- stein, M., Aberman, K.: Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6527–6536 (2024)
2024
-
[26]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wu, J.Z., Ge, Y., Wang, X., Lei, S.W., Gu, Y., Shi, Y., Hsu, W., Shan, Y., Qie, X., Shou, M.Z.: Tune-a-video: One-shot tuning of image diffusion models for text- to-video generation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7623–7633 (2023)
2023
-
[28]
arXiv preprint arXiv:2408.06740 (2024)
Wu, Y., Shi, Y., Wei, J., Sun, C., Yang, Y., Shen, H.T.: Difflora: Generating person- alized low-rank adaptation weights with diffusion. arXiv preprint arXiv:2408.06740 (2024)
-
[29]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compati- ble image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
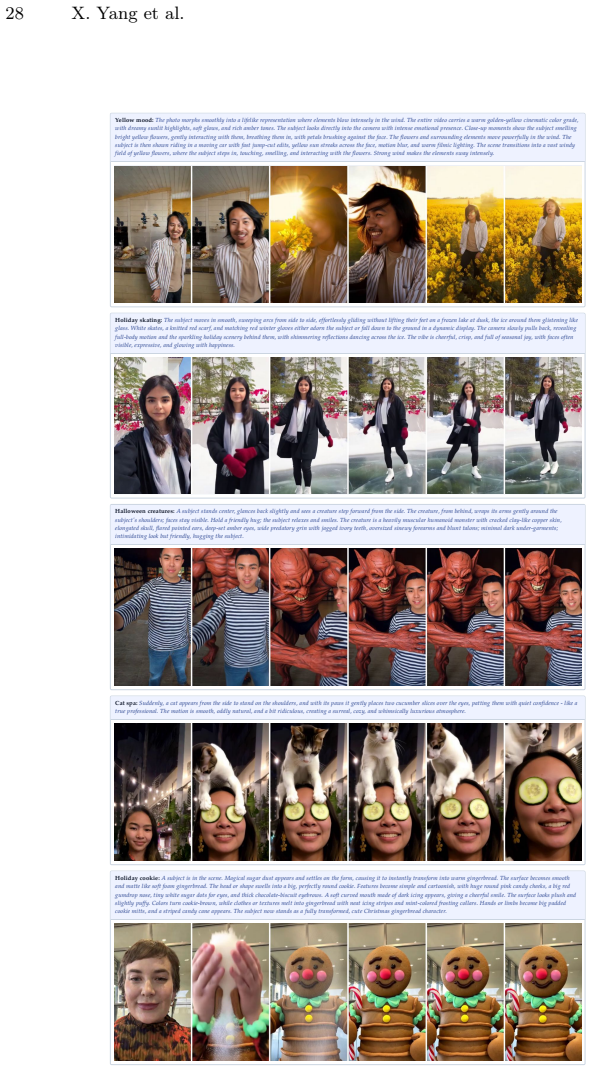
Ye, Z., Huang, H., Wang, X., Wan, P., Zhang, D., Luo, W.: Stylemaster: Stylize your video with artistic generation and translation. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 2630–2640 (2025) 18 X. Yang et al. A Public Model Experiments To validate that the proposed Prompt2Effect is fundamentally model-agnostic, we ad...
2025
-
[31]
An LLM generates detailed effect/LoRA descriptions alongside correspond- ing first-frame image prompts
-
[32]
A Text-to-Image (T2I) model, such as FLUX, renders the high-quality first frame
-
[33]
An LLM/VLM takes the first frame and effect description to generate Image- to-Video (I2V) or First-Frame-to-Video (FLF2V) prompts
-
[34]
Public video generation models (e.g., Wan) and our proprietary model ren- ders the target video
-
[35]
slow transformation
We apply aggressive filtering by human annotators to only keep the data with the highest quality and prompt alignment. The 75 curated effects span a wide variety of dynamic concepts, which we broadlycategorizeinto:Transformations(e.g.,skull_reveal,holiday_elf),Cam- era&Stylization(e.g.,fisheye_animation,dream_cute_sketch),SurrealAc- tions(e.g.,polarbear_r...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.