Applicability Condition Extraction for Therapeutic Drug-Disease Relations
Pith reviewed 2026-06-27 05:22 UTC · model grok-4.3
The pith
A new dataset and relation-enhanced LoRA method extract the conditions under which drugs treat specific diseases from research abstracts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Applicability conditions for therapeutic drug-disease relations can be extracted from abstracts by creating a dedicated annotated dataset of 1,119 triples and applying a LoRA variant that incorporates drug-disease relational signals, which outperforms standard baselines across evaluation settings.
What carries the argument
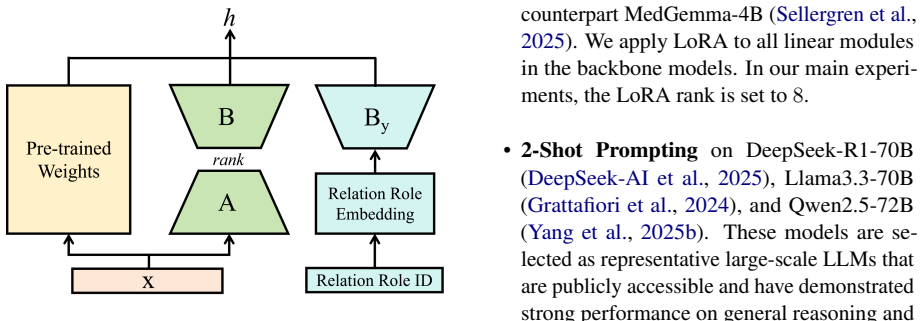
The relation-enhanced LoRA method that augments standard parameter-efficient fine-tuning by explicitly modeling interactions between drug and disease entities during condition extraction.
If this is right
- Clinical decision systems can move from generic drug-disease links to context-qualified recommendations drawn from literature.
- Information extraction pipelines gain a new layer that distinguishes applicable from inapplicable relations.
- Future datasets in biomedicine can adopt the triple annotation format to capture conditional relations.
- Relation-aware adaptation of language models becomes a reusable technique for other entity-pair tasks.
Where Pith is reading between the lines
- If the annotation scheme transfers to full-text papers, extraction performance may improve because abstracts often omit detailed conditions.
- The same relation-modeling trick could apply to other conditional biomedical relations such as drug-drug interactions or gene-disease associations.
- Integration with electronic health record systems would allow direct comparison of literature-derived conditions against observed patient responses.
Load-bearing premise
The manually created triples of drugs, diseases, and applicability conditions accurately represent real clinical applicability rather than only linguistic patterns in abstracts.
What would settle it
A held-out clinical validation set where extracted conditions are rated by practicing physicians for correctness against patient records or treatment guidelines, measuring agreement rates below those of the reported automatic metrics.
Figures


read the original abstract
Identifying conditions that a certain drug takes therapeutic effect on a target disease is crucial for clinical decision-making support. However, most existing biomedical information extraction methods have focused on identifying only relations between drugs and diseases, while largely overlooking the context-specific conditions where such relations can apply. To address this problem, we introduce the task of applicability condition extraction for therapeutic drug-disease relations from biomedical research literature. We create the first dataset that has manually annotated triples of drugs, diseases, and applicability conditions on biomedical paper abstracts with 1,119 drug-disease pairs. Using this dataset, we systematically evaluate the performance of a range of existing methods. In addition, we propose a new method that enhances LoRA to consider relations between drugs and diseases. Our method consistently outperforms strong baselines across different evaluation settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of applicability condition extraction for therapeutic drug-disease relations from biomedical abstracts. It constructs the first manually annotated dataset of 1,119 drug-disease pairs, systematically evaluates a range of existing methods on this data, and proposes an enhanced LoRA-based method that incorporates drug-disease relations, claiming consistent outperformance over strong baselines across multiple evaluation settings.
Significance. If the central claims hold, the work would be significant as the first dataset and systematic evaluation for this clinically relevant subtask of biomedical relation extraction. The proposed method's reported gains could inform future context-aware extraction systems, provided the annotations capture genuine therapeutic constraints rather than abstract-specific patterns.
major comments (3)
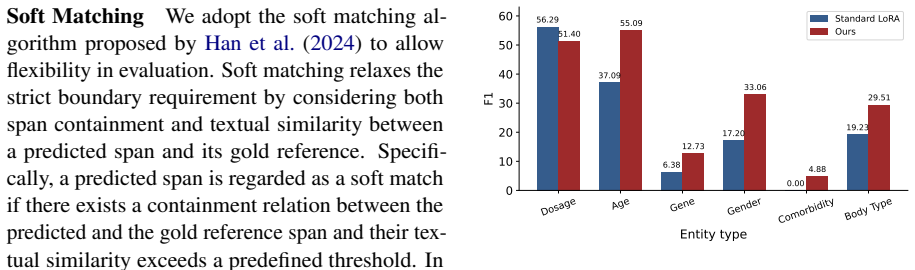
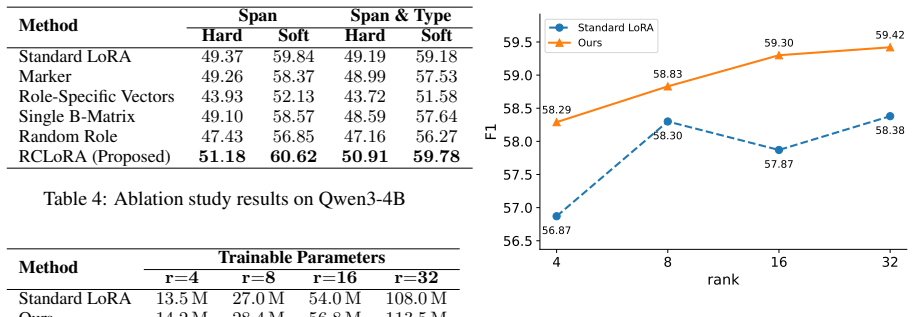
- [Abstract, §5] Abstract and §5 (Experiments): The central claim that the proposed method 'consistently outperforms strong baselines across different evaluation settings' is asserted without any reported metrics, baseline scores, data splits, or error analysis, making it impossible to assess or reproduce the result.
- [§3] §3 (Dataset Construction): The manually annotated applicability conditions are derived exclusively from abstracts with no described external grounding (e.g., against clinical guidelines, patient records, or post-annotation expert review), so superior extraction performance may reflect modeling of textual co-occurrence patterns rather than clinically valid constraints.
- [§4] §4 (Proposed Method): The description of how LoRA is enhanced to consider relations between drugs and diseases lacks sufficient implementation details (e.g., exact architectural modifications, training hyperparameters, or loss terms) to allow replication or comparison with the evaluated baselines.
minor comments (2)
- [Abstract] The abstract mentions 'different evaluation settings' without defining them; this should be clarified in the main text or a table.
- [§3] Notation for the annotated triples (drug, disease, condition) is introduced but not consistently used in later sections; standardize the notation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and have revised the manuscript accordingly to improve clarity, reproducibility, and transparency.
read point-by-point responses
-
Referee: [Abstract, §5] Abstract and §5 (Experiments): The central claim that the proposed method 'consistently outperforms strong baselines across different evaluation settings' is asserted without any reported metrics, baseline scores, data splits, or error analysis, making it impossible to assess or reproduce the result.
Authors: We agree that the abstract should be self-contained. Section 5 already contains the full results with metrics, baseline scores, data splits (including train/dev/test ratios), and error analysis. In the revision we will add the key performance figures (e.g., F1 improvements) directly into the abstract so the central claim is supported by numbers. revision: yes
-
Referee: [§3] §3 (Dataset Construction): The manually annotated applicability conditions are derived exclusively from abstracts with no described external grounding (e.g., against clinical guidelines, patient records, or post-annotation expert review), so superior extraction performance may reflect modeling of textual co-occurrence patterns rather than clinically valid constraints.
Authors: The task definition is extraction of applicability conditions as stated in the biomedical literature; therefore the annotations are intentionally grounded in the abstracts themselves. The annotation guidelines were developed from clinical literature and applied by two domain experts with adjudication. We acknowledge that additional external validation against guidelines or records would strengthen clinical validity and will add an explicit limitations paragraph plus a future-work statement on this point. revision: partial
-
Referee: [§4] §4 (Proposed Method): The description of how LoRA is enhanced to consider relations between drugs and diseases lacks sufficient implementation details (e.g., exact architectural modifications, training hyperparameters, or loss terms) to allow replication or comparison with the evaluated baselines.
Authors: We agree the current description is insufficient for replication. In the revised Section 4 we will provide the precise architectural changes (relation-aware adapter placement and input formatting), the complete hyperparameter table (learning rate, rank, alpha, epochs, batch size), and the exact loss formulation used for the enhanced LoRA model. revision: yes
Circularity Check
No circularity: new dataset and standard empirical comparison
full rationale
The paper introduces a new task of applicability condition extraction, manually annotates a dataset of 1,119 drug-disease pairs from abstracts, evaluates a range of existing methods, and proposes an enhancement to LoRA that is compared directly on the new data. No equations, fitted parameters presented as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work are present. The derivation chain consists of dataset creation followed by standard model evaluation; the outperformance claim is an empirical result on held-out data rather than a reduction to the inputs by construction. This matches the default expectation of a non-circular empirical NLP paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=. 1997 , url=
1997
-
[2]
Proceedings of ICML , volume=
Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data , author=. Proceedings of ICML , volume=
-
[3]
Akbik, Alan and Bergmann, Tanja and Blythe, Duncan and Rasul, Kashif and Schweter, Stefan and Vollgraf, Roland. FLAIR : An Easy-to-Use Framework for State-of-the-Art NLP. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics (Demonstrations). 2019. doi:10.18653/v1/N19-4010
-
[4]
Database , volume=
PubMed and beyond: a survey of web tools for searching biomedical literature , author=. Database , volume=. 2011 , url=
2011
-
[5]
Mayo Clinic Proceedings , volume=
Pharmacogenomics: precision medicine and drug response , author=. Mayo Clinic Proceedings , volume=. 2017 , url=
2017
-
[6]
Supporting Medical Relation Extraction via Causality-Pruned Semantic Dependency Forest
Jin, Yifan and Li, Jiangmeng and Lian, Zheng and Jiao, Chengbo and Hu, Xiaohui. Supporting Medical Relation Extraction via Causality-Pruned Semantic Dependency Forest. Proceedings of the 29th International Conference on Computational Linguistics. 2022
2022
-
[7]
Incorporating medical knowledge in BERT for clinical relation extraction
Roy, Arpita and Pan, Shimei. Incorporating medical knowledge in BERT for clinical relation extraction. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.435
-
[8]
Sahoo, Pranab and Singh, Ayush and Saha, Sriparna and Chadha, Aman and Mondal, Samrat. Enhancing Adverse Drug Event Detection with Multimodal Dataset: Corpus Creation and Model Development. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.667
-
[9]
Journal of the American Medical Informatics Association , volume=
2018 n2c2 shared task on adverse drug events and medication extraction in electronic health records , author=. Journal of the American Medical Informatics Association , volume=. 2020 , url=
2018
-
[10]
B io DEX : Large-Scale Biomedical Adverse Drug Event Extraction for Real-World Pharmacovigilance
D ' Oosterlinck, Karel and Remy, Fran c ois and Deleu, Johannes and Demeester, Thomas and Develder, Chris and Zaporojets, Klim and Ghodsi, Aneiss and Ellershaw, Simon and Collins, Jack and Potts, Christopher. B io DEX : Large-Scale Biomedical Adverse Drug Event Extraction for Real-World Pharmacovigilance. Findings of the Association for Computational Ling...
-
[11]
Briefings in Bioinformatics , volume=
BioRED: a rich biomedical relation extraction dataset , author=. Briefings in Bioinformatics , volume=. 2022 , url=
2022
-
[12]
Frontiers in Artificial Intelligence , volume=
DICE: A drug indication classification and encyclopedia for AI-based indication extraction , author=. Frontiers in Artificial Intelligence , volume=. 2021 , url=
2021
-
[13]
Plos medicine , volume=
Treatment effect modification due to comorbidity: Individual participant data meta-analyses of 120 randomised controlled trials , author=. Plos medicine , volume=. 2023 , url=
2023
-
[14]
International Conference on Research in Computational Molecular Biology , pages=
Renet: A deep learning approach for extracting gene-disease associations from literature , author=. International Conference on Research in Computational Molecular Biology , pages=. 2019 , url=
2019
-
[15]
Nguyen, Dat Quoc and Verspoor, Karin. Convolutional neural networks for chemical-disease relation extraction are improved with character-based word embeddings. Proceedings of the B io NLP 2018 workshop. 2018. doi:10.18653/v1/W18-2314
-
[16]
Briefings in Bioinformatics , volume=
A review of biomedical datasets relating to drug discovery: a knowledge graph perspective , author=. Briefings in Bioinformatics , volume=. 2022 , url=
2022
-
[17]
Database , volume=
Assessing the state of the art in biomedical relation extraction: overview of the BioCreative V chemical-disease relation (CDR) task , author=. Database , volume=. 2016 , url=
2016
-
[18]
Detecting Adverse Drug Reactions from Biomedical Texts with Neural Networks
Alimova, Ilseyar and Tutubalina, Elena. Detecting Adverse Drug Reactions from Biomedical Texts with Neural Networks. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop. 2019. doi:10.18653/v1/P19-2058
-
[19]
Adverse Drug Reaction Classification With Deep Neural Networks
Huynh, Trung and He, Yulan and Willis, Alistair and Rueger, Stefan. Adverse Drug Reaction Classification With Deep Neural Networks. Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. 2016
2016
-
[20]
Wang, Minjia and Liu, Fangzhou and Li, Xiuxing and Dong, Bowen and Li, Zhenyu and Pan, Tengyu and Wang, Jianyong. Bio- RFX : Refining Biomedical Extraction via Advanced Relation Classification and Structural Constraints. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.588
-
[21]
Federated Document-Level Biomedical Relation Extraction with Localized Context Contrast
Xiao, Yan and Jin, Yaochu and Hao, Kuangrong. Federated Document-Level Biomedical Relation Extraction with Localized Context Contrast. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[22]
Database , volume=
BioCreative V CDR task corpus: a resource for chemical disease relation extraction , author=. Database , volume=. 2016 , url=
2016
-
[23]
Instruction-Tuning LLM s for Event Extraction with Annotation Guidelines
Srivastava, Saurabh and Pati, Sweta and Yao, Ziyu. Instruction-Tuning LLM s for Event Extraction with Annotation Guidelines. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.677
-
[24]
Bai, Zewen and Yang, Liang and Yin, Shengdi and Lu, Junyu and Zeng, Jingjie and Zhu, Haohao and Sun, Yuanyuan and Lin, Hongfei. STATE T oxi CN : A Benchmark for Span-level Target-Aware Toxicity Extraction in C hinese Hate Speech Detection. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.532
-
[25]
Guellil, Imane and Andres, Salom \'e and Anand, Atul and Guthrie, Bruce and Zhang, Huayu and Hasan, Abul and Wu, Honghan and Alex, Beatrice. Adverse Event Extraction from Discharge Summaries: A New Dataset, Annotation Scheme, and Initial Findings. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
-
[26]
A Distant Supervision Corpus for Extracting Biomedical Relationships Between Chemicals, Diseases and Genes
Zhang, Dongxu and Mohan, Sunil and Torkar, Michaela and McCallum, Andrew. A Distant Supervision Corpus for Extracting Biomedical Relationships Between Chemicals, Diseases and Genes. Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022
2022
-
[27]
Zhao, Haodong and He, Ruifang and Xiao, Mengnan and Xu, Jing. Infusing Hierarchical Guidance into Prompt Tuning: A Parameter-Efficient Framework for Multi-level Implicit Discourse Relation Recognition. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.357
-
[28]
RST - L o RA : A Discourse-Aware Low-Rank Adaptation for Long Document Abstractive Summarization
Liu, Dongqi and Demberg, Vera. RST - L o RA : A Discourse-Aware Low-Rank Adaptation for Long Document Abstractive Summarization. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.121
-
[29]
2024 , cdate=
Gunjan Balde and Soumyadeep Roy and Mainack Mondal and Niloy Ganguly , title=. 2024 , cdate=
2024
-
[30]
Packed Levitated Marker for Entity and Relation Extraction
Ye, Deming and Lin, Yankai and Li, Peng and Sun, Maosong. Packed Levitated Marker for Entity and Relation Extraction. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.337
-
[31]
2019 , eprint=
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author=. 2019 , eprint=
2019
-
[32]
ACM Transactions on Computing for Healthcare (HEALTH) , volume=
Domain-specific language model pretraining for biomedical natural language processing , author=. ACM Transactions on Computing for Healthcare (HEALTH) , volume=. 2021 , url=
2021
-
[33]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=. 2022 , url=
2022
-
[34]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , url=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[37]
Database , volume=
Overview of DrugProt task at BioCreative VII: data and methods for large-scale text mining and knowledge graph generation of heterogenous chemical--protein relations , author=. Database , volume=. 2023 , publisher=
2023
-
[38]
Sosa and Rogier Hintzen and Betty Xiong and Alex
Daniel N. Sosa and Rogier Hintzen and Betty Xiong and Alex. Associating biological context with protein-protein interactions through text mining at PubMed scale , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.jbi.2023.104474 , url =
-
[39]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[40]
2023 , url=
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning , author=. 2023 , url=
2023
-
[41]
2025 , eprint=
MedGemma Technical Report , author=. 2025 , eprint=
2025
-
[42]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[43]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[44]
T able L o RA : Low-rank Adaptation on Table Structure Understanding for Large Language Models
He, Xinyi and Liu, Yihao and Zhou, Mengyu and He, Yeye and Dong, Haoyu and Han, Shi and Yuan, Zejian and Zhang, Dongmei. T able L o RA : Low-rank Adaptation on Table Structure Understanding for Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025....
-
[45]
Publicly Available Clinical BERT Embeddings
Alsentzer, Emily and Murphy, John and Boag, William and Weng, Wei-Hung and Jindi, Di and Naumann, Tristan and McDermott, Matthew. Publicly Available Clinical BERT Embeddings. Proceedings of the 2nd Clinical Natural Language Processing Workshop. 2019. doi:10.18653/v1/W19-1909
-
[46]
Bioinformatics , volume=
BioBERT: a pre-trained biomedical language representation model for biomedical text mining , author=. Bioinformatics , volume=. 2020 , url=
2020
-
[47]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[48]
2024 , eprint=
An Empirical Study on Information Extraction using Large Language Models , author=. 2024 , eprint=
2024
-
[49]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[50]
Publications Manual , year = "1983", publisher =
1983
-
[51]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[52]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[53]
Dan Gusfield , title =. 1997
1997
-
[54]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[55]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.