A New Multi-Domain Benchmark for Micro-Action Recognition and Detection
Pith reviewed 2026-06-27 05:14 UTC · model grok-4.3
The pith
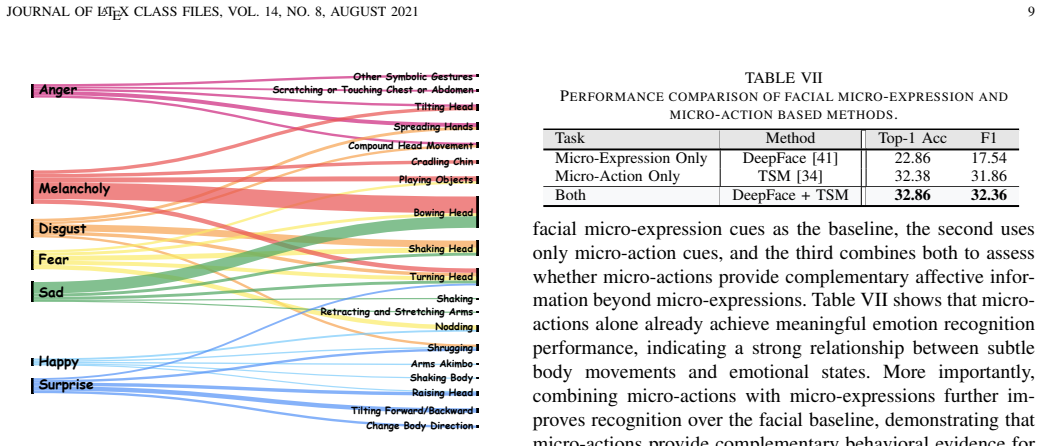
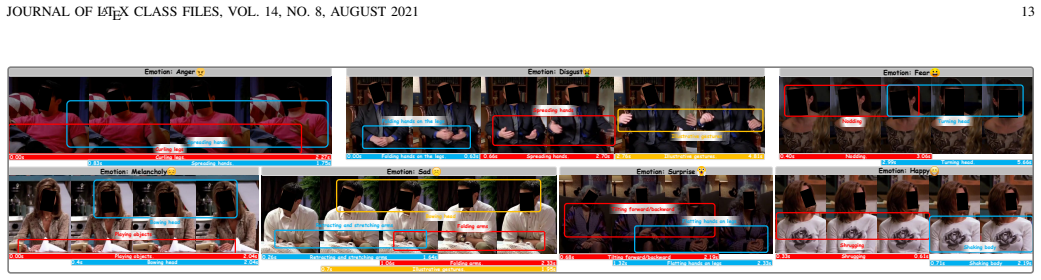
MMA-82 expands micro-action recognition to 82 categories across four real domains and links them to emotional states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce MMA-82, a large-scale multi-domain benchmark extending prior work with 82 fine-grained micro-action categories and 77,856 annotated instances from 454 subjects across laboratory interviews, street interviews, psychiatric patient interviews, and emotion-rich television videos. We establish Micro-Action Recognition and Multi-label Micro-Action Detection tasks, with protocols for in-domain, cross-domain, few-shot, and zero-shot evaluation. Experiments indicate that existing approaches still face difficulties with realistic micro-action understanding, particularly under domain shift, long-tailed distributions, and complex temporal localization. Additionally, micro-actions show stron
What carries the argument
The MMA-82 benchmark dataset, which supplies the expanded label space, four-domain coverage, and evaluation protocols that support tests of robustness and generalization.
If this is right
- Recognition systems must improve handling of domain shifts and long-tailed category distributions to work in practical settings.
- Micro-action cues can be combined with facial signals to raise accuracy in automated emotion recognition.
- Few-shot and zero-shot protocols show the need for stronger transfer methods when moving between interview and video domains.
- Multi-label detection requires better temporal localization techniques for overlapping or brief actions.
Where Pith is reading between the lines
- The dataset could support new monitoring tools that track subtle behavioral changes in mental-health or security contexts.
- Similar multi-domain designs may be useful for other fine-grained human-movement tasks such as micro-gestures.
- Integrating the annotations with existing facial-expression datasets could produce joint models that capture both body and face signals.
- Researchers could measure whether pre-training on MMA-82 improves performance on related video-understanding benchmarks.
Load-bearing premise
The four selected domains and the 77,856 annotations together represent the full variety of real-world micro-actions without large labeling errors or selection bias.
What would settle it
A controlled test in which leading models reach high accuracy on cross-domain recognition without extra adaptation, or an independent check showing no reliable statistical link between the micro-action labels and measured emotional states.
Figures


read the original abstract
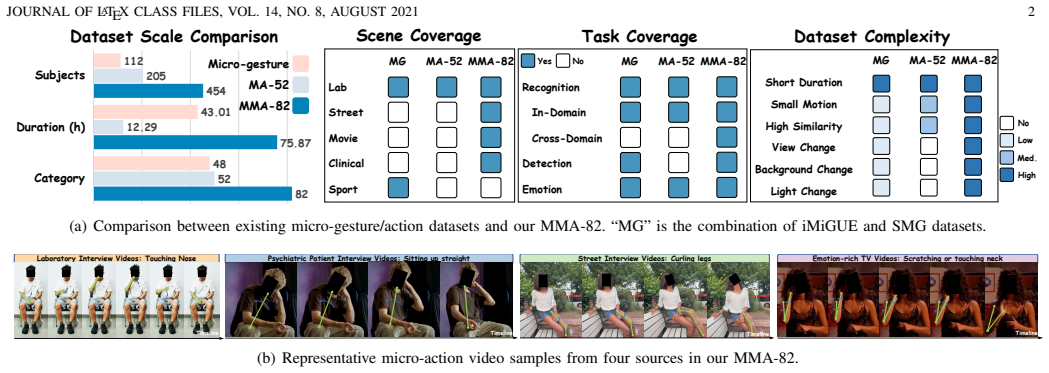
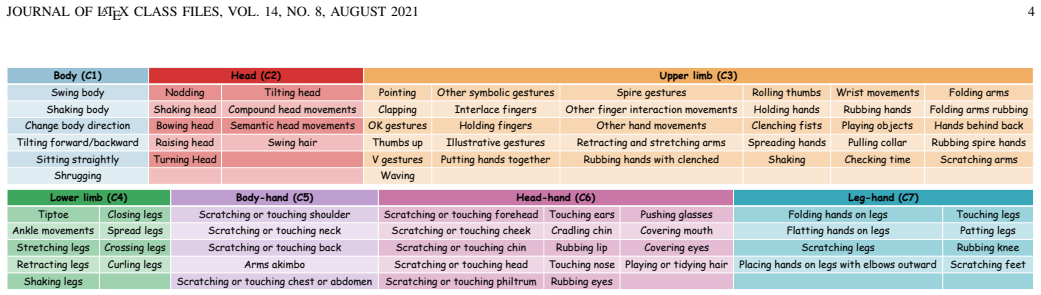
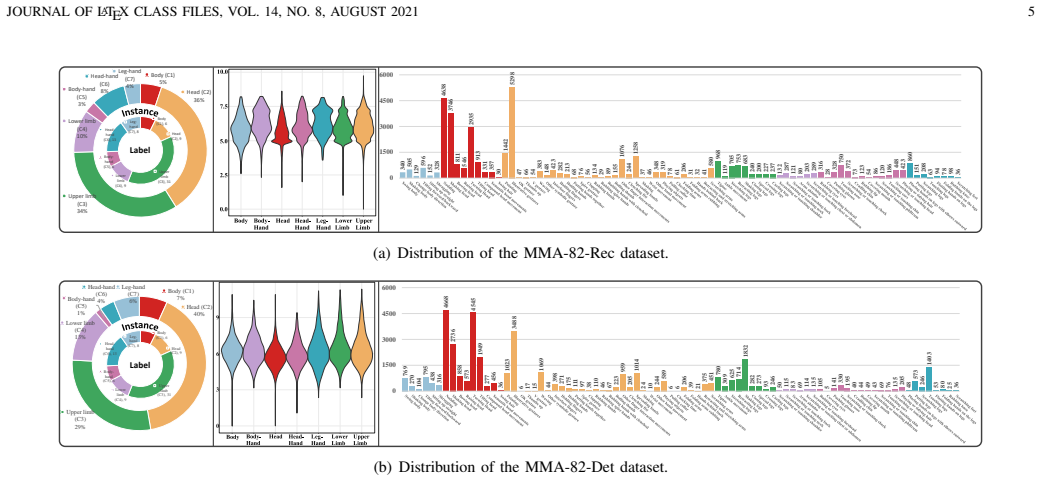
Micro-actions are short-duration, low-amplitude subtle body movements at the whole-body level that can reveal latent intentions, involuntary reactions, and fine-grained affective changes. Our previous MA-52 benchmark has provided an important foundation for micro-action recognition, but it remains limited in scale, scene diversity, task coverage, and evaluation protocols. To advance micro-action analysis toward more realistic and comprehensive settings, we introduce MMA-82, a large-scale multi-domain extension of MA-52. MMA-82 expands the label space from 52 to 82 fine-grained micro-action categories and covers four distinct domains, including laboratory interviews, street interviews, psychiatric patient interviews, and emotion-rich television videos, resulting in 77,856 annotated instances from 454 subjects. Built upon MMA-82, we establish two core tasks: Micro-Action Recognition and Multi-label Micro-Action Detection. For recognition, we further define in-domain and cross-domain protocols, including few-shot and zero-shot settings, to evaluate model robustness, transferability, and generalization. Extensive experiments show that current methods still struggle with realistic micro-action understanding, especially under domain shift, long-tailed category distributions, and complex temporal localization. Beyond benchmarking, we investigate the relationship between micro-actions and emotion, showing that micro-actions are strongly associated with emotional states and provide complementary cues to facial micro-expressions for improved emotion recognition. These results demonstrate that MMA-82 serves as a comprehensive and challenging benchmark for realistic micro-action analysis and a valuable resource for human-centered AI. MMA-82 is available at https://lpynow.github.io/MMA-82-AIM/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MMA-82, a multi-domain extension of the prior MA-52 benchmark for micro-action analysis. It expands the label space to 82 fine-grained categories with 77,856 annotated instances from 454 subjects across four domains (laboratory interviews, street interviews, psychiatric patient interviews, and emotion-rich TV videos). The work defines micro-action recognition (with in-domain, cross-domain, few-shot, and zero-shot protocols) and multi-label detection tasks, reports that existing methods struggle under domain shift and long-tailed distributions, and presents evidence that micro-actions correlate with emotional states and complement facial micro-expressions.
Significance. If annotation quality is validated, MMA-82 would provide a substantially larger and more diverse resource than MA-52 for studying subtle whole-body movements, enabling more realistic evaluation of recognition, detection, and transfer under domain shift. The emotion-association analysis could open avenues for affective computing that integrate body cues beyond faces. The public release of the dataset supports reproducibility in human-centered AI research.
major comments (1)
- [Dataset construction] Dataset construction section: No inter-annotator agreement statistics (e.g., Cohen's or Fleiss' kappa) or detailed annotation protocol (including guidelines for distinguishing the 82 subtle, low-amplitude categories) are reported. Because the central claims rest on these 77,856 instances serving as reliable ground truth for all recognition, detection, cross-domain, and emotion-correlation experiments, the absence of such validation leaves open the possibility of substantial label noise or bias, directly affecting the reported performance gaps and complementarity findings.
minor comments (1)
- The abstract and introduction could clarify the total video duration and number of source videos to better contextualize the scale of 77,856 instances relative to prior benchmarks.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of MMA-82's potential contribution and for the constructive major comment. We address the point on dataset validation below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: No inter-annotator agreement statistics (e.g., Cohen's or Fleiss' kappa) or detailed annotation protocol (including guidelines for distinguishing the 82 subtle, low-amplitude categories) are reported. Because the central claims rest on these 77,856 instances serving as reliable ground truth for all recognition, detection, cross-domain, and emotion-correlation experiments, the absence of such validation leaves open the possibility of substantial label noise or bias, directly affecting the reported performance gaps and complementarity findings.
Authors: We agree that explicit reporting of annotation quality is essential. The current manuscript focuses on benchmark construction and experimental protocols but omits these details. In the revision we will add a dedicated subsection under Dataset Construction that (1) describes the multi-stage annotation pipeline, including the guidelines used to differentiate the 82 low-amplitude categories, (2) reports inter-annotator agreement (Fleiss' kappa) computed on a randomly sampled subset of videos annotated by multiple independent annotators, and (3) discusses quality-control steps such as adjudication of disagreements. These additions will directly support the reliability of the ground-truth labels used throughout the experiments. revision: yes
Circularity Check
No circularity: dataset benchmark paper with no derivations or self-referential predictions
full rationale
This is a data contribution paper introducing the MMA-82 benchmark. No mathematical derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. The central claims rest on the new dataset collection and standard evaluations of existing models; there are no self-citation load-bearing uniqueness theorems, ansatzes smuggled via citation, or renamings of known results as novel derivations. Annotation quality and domain representativeness are assumptions but not derived quantities. Score 0 is the appropriate finding for a self-contained benchmark release.
Axiom & Free-Parameter Ledger
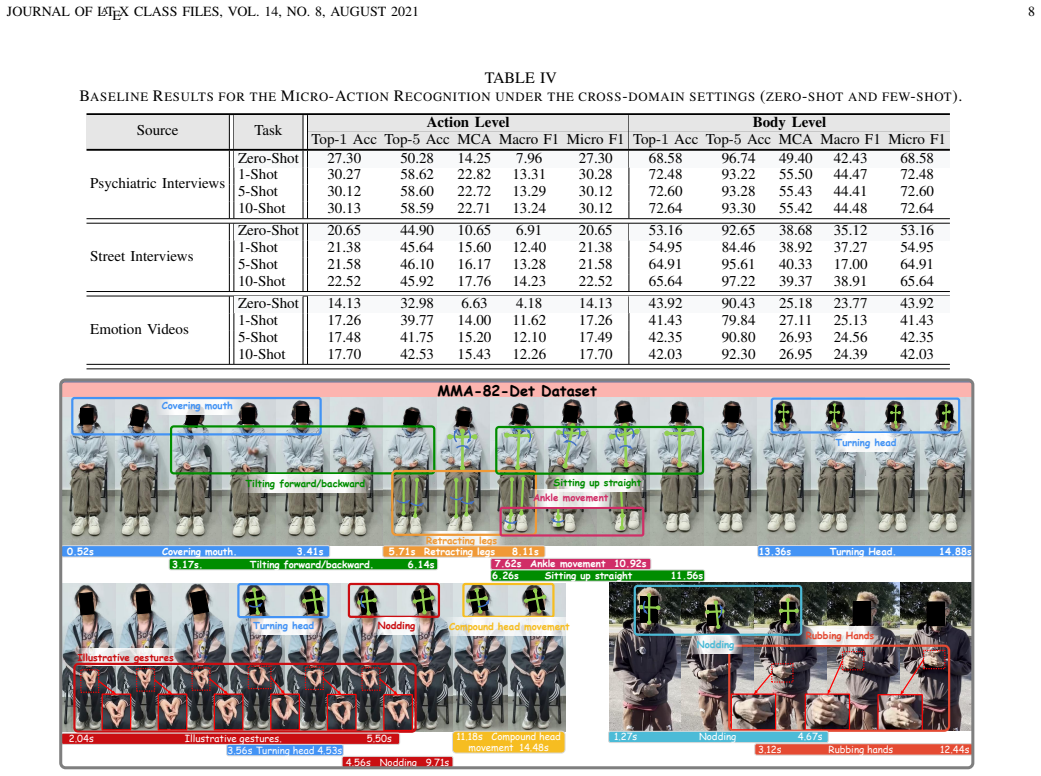
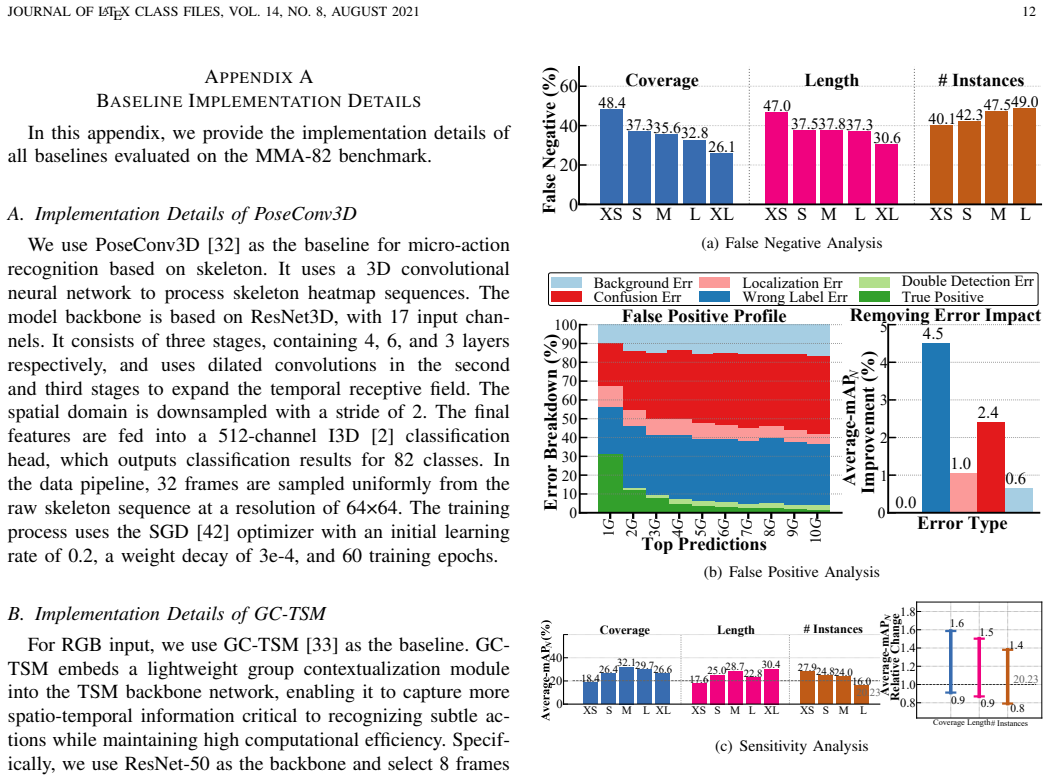
axioms (2)
- domain assumption Human annotators can reliably identify and label 82 fine-grained micro-action categories from video across multiple domains.
- domain assumption The selected four domains capture representative real-world variability in micro-action appearance and context.
Reference graph
Works this paper leans on
-
[1]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[2]
Quo vadis, action recognition? a new model and the kinetics dataset,
J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6299–6308
2017
-
[3]
The” something something
R. Goyal, S. Ebrahimi Kahou, V . Michalski, J. Materzynska, S. West- phal, H. Kim, V . Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitaget al., “The” something something” video database for learning and evaluat- ing visual common sense,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 5842–5850
2017
-
[4]
Slowfast networks for video recognition,
C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6202–6211
2019
-
[5]
Video swin transformer,
Z. Liu, J. Ning, Y . Cao, Y . Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 3202–3211
2022
-
[6]
Gpt4ego: unleashing the potential of pre-trained models for zero-shot egocentric action recognition,
G. Dai, X. Shu, W. Wu, R. Yan, and J. Zhang, “Gpt4ego: unleashing the potential of pre-trained models for zero-shot egocentric action recognition,”IEEE Transactions on Multimedia, vol. 27, pp. 401–413, 2024
2024
-
[7]
Facial action units as a joint dataset training bridge for facial expression recognition,
S. Mao, X. Li, F. Zhang, X. Peng, and Y . Yang, “Facial action units as a joint dataset training bridge for facial expression recognition,”IEEE Transactions on Multimedia, vol. 27, pp. 3331–3342, 2025
2025
-
[8]
Benchmarking micro-action recognition: Dataset, methods, and applications,
D. Guo, K. Li, B. Hu, Y . Zhang, and M. Wang, “Benchmarking micro-action recognition: Dataset, methods, and applications,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 7, pp. 6238–6252, 2024
2024
-
[9]
Mmad: Multi-label micro-action detection in videos,
K. Li, P. Liu, D. Guo, F. Wang, Z. Wu, H. Fan, and M. Wang, “Mmad: Multi-label micro-action detection in videos,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 13 225–13 236
2025
-
[10]
Ma- bench: Towards fine-grained micro-action understanding,
K. Li, J. Gu, F. Wang, Z. Wu, H. Fan, and D. Guo, “Ma- bench: Towards fine-grained micro-action understanding,”arXiv preprint arXiv:2603.26586, 2026
-
[11]
Motion matters: Motion-guided modulation network for skeleton-based micro- action recognition,
J. Gu, K. Li, F. Wang, Y . Wei, Z. Wu, H. Fan, and M. Wang, “Motion matters: Motion-guided modulation network for skeleton-based micro- action recognition,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 5461–5470
2025
-
[12]
Prototypical calibrating ambiguous samples for micro-action recogni- tion,
K. Li, D. Guo, G. Chen, C. Fan, J. Xu, Z. Wu, H. Fan, and M. Wang, “Prototypical calibrating ambiguous samples for micro-action recogni- tion,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 5, 2025, pp. 4815–4823
2025
-
[13]
imigue: An identity-free video dataset for micro-gesture understanding and emotion analysis,
X. Liu, H. Shi, H. Chen, Z. Yu, X. Li, and G. Zhao, “imigue: An identity-free video dataset for micro-gesture understanding and emotion analysis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 10 631–10 642
2021
-
[14]
Smg: A micro-gesture dataset towards spontaneous body gestures for emotional stress state analysis,
H. Chen, H. Shi, X. Liu, X. Li, and G. Zhao, “Smg: A micro-gesture dataset towards spontaneous body gestures for emotional stress state analysis,”International Journal of Computer Vision, vol. 131, no. 6, pp. 1346–1366, 2023
2023
-
[15]
Context-aware emotion recognition networks,
J. Lee, S. Kim, S. Kim, J. Park, and K. Sohn, “Context-aware emotion recognition networks,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 10 143–10 152
2019
-
[16]
Samm: A spontaneous micro-facial movement dataset,
A. K. Davison, C. Lansley, N. Costen, K. Tan, and M. H. Yap, “Samm: A spontaneous micro-facial movement dataset,”IEEE transactions on affective computing, vol. 9, no. 1, pp. 116–129, 2016
2016
-
[17]
A spontaneous micro-expression database: Inducement, collection and baseline,
X. Li, T. Pfister, X. Huang, G. Zhao, and M. Pietik ¨ainen, “A spontaneous micro-expression database: Inducement, collection and baseline,” in 2013 10th IEEE International Conference and Workshops on Automatic face and gesture recognition (fg). IEEE, 2013, pp. 1–6
2013
-
[18]
Casme database: A dataset of spontaneous micro-expressions collected from neutralized faces,
W.-J. Yan, Q. Wu, Y .-J. Liu, S.-J. Wang, and X. Fu, “Casme database: A dataset of spontaneous micro-expressions collected from neutralized faces,” in2013 10th IEEE international conference and workshops on automatic face and gesture recognition (FG). IEEE, 2013, pp. 1–7
2013
-
[19]
Cas (me) 2: a database for spontaneous macro-expression and micro-expression spotting and recognition,
F. Qu, S.-J. Wang, W.-J. Yan, H. Li, S. Wu, and X. Fu, “Cas (me) 2: a database for spontaneous macro-expression and micro-expression spotting and recognition,”IEEE Transactions on Affective Computing, vol. 9, no. 4, pp. 424–436, 2017
2017
-
[20]
Cas (me) 3: A third generation facial spontaneous micro- expression database with depth information and high ecological validity,
J. Li, Z. Dong, S. Lu, S.-J. Wang, W.-J. Yan, Y . Ma, Y . Liu, C. Huang, and X. Fu, “Cas (me) 3: A third generation facial spontaneous micro- expression database with depth information and high ecological validity,” IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 3, pp. 2782–2800, 2022
2022
-
[21]
Ntu rgb+ d: A large scale dataset for 3d human activity analysis,
A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, “Ntu rgb+ d: A large scale dataset for 3d human activity analysis,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1010–1019
2016
-
[22]
Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding,
J. Liu, A. Shahroudy, M. Perez, G. Wang, L.-Y . Duan, and A. C. Kot, “Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding,”IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 10, pp. 2684–2701, 2019
2019
-
[23]
The epic-kitchens dataset: Collection, challenges and baselines,
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kaza- kos, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray, “The epic-kitchens dataset: Collection, challenges and baselines,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 11, pp. 4125–4141, 2021
2021
-
[24]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liuet al., “Ego4d: Around the world in 3,000 hours of egocentric video,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18 995–19 012
2022
-
[25]
To- wards student actions in classroom scenes: New dataset and baseline,
Z. Tan, C. Gao, A. Qin, R. Chen, T. Song, F. Yang, and D. Meng, “To- wards student actions in classroom scenes: New dataset and baseline,” IEEE Transactions on Multimedia, 2025
2025
-
[26]
Casme ii: An improved spontaneous micro-expression database and the baseline evaluation,
W.-J. Yan, X. Li, S.-J. Wang, G. Zhao, Y .-J. Liu, Y .-H. Chen, and X. Fu, “Casme ii: An improved spontaneous micro-expression database and the baseline evaluation,”PloS one, vol. 9, no. 1, p. e86041, 2014
2014
-
[27]
Opendatalab: Empowering general artificial intelligence with open datasets,
C. He, W. Li, Z. Jin, C. Xu, B. Wang, and D. Lin, “Opendatalab: Empowering general artificial intelligence with open datasets,”arXiv preprint arXiv:2407.13773, 2024
-
[28]
The epic- kitchens dataset: Collection, challenges and baselines,
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kaza- kos, D. Moltisanti, J. Munro, T. Perrett, W. Priceet al., “The epic- kitchens dataset: Collection, challenges and baselines,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 43, no. 11, pp. 4125–4141, 2020
2020
-
[29]
Enhancing micro-video understanding by harnessing external sounds,
L. Nie, X. Wang, J. Zhang, X. He, H. Zhang, R. Hong, and Q. Tian, “Enhancing micro-video understanding by harnessing external sounds,” inProceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1192–1200
2017
-
[30]
Spatial temporal graph convolutional networks for skeleton-based action recognition,
S. Yan, Y . Xiong, and D. Lin, “Spatial temporal graph convolutional networks for skeleton-based action recognition,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
2018
-
[31]
Revisiting skeleton- based action recognition,
H. Duan, Y . Zhao, K. Chen, D. Lin, and B. Dai, “Revisiting skeleton- based action recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 2969–2978
2022
-
[32]
Pyskl: Towards good practices for skeleton action recognition,
H. Duan, J. Wang, K. Chen, and D. Lin, “Pyskl: Towards good practices for skeleton action recognition,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 7351–7354
2022
-
[33]
Group contextualization for video recognition,
Y . Hao, H. Zhang, C.-W. Ngo, and X. He, “Group contextualization for video recognition,” inProceedings of the ieee/cvf conference on computer vision and pattern recognition, 2022, pp. 928–938
2022
-
[34]
Tsm: Temporal shift module for efficient video understanding,
J. Lin, C. Gan, and S. Han, “Tsm: Temporal shift module for efficient video understanding,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 7083–7093
2019
-
[35]
Pointtad: Multi- label temporal action detection with learnable query points,
J. Tan, X. Zhao, X. Shi, B. Kang, and L. Wang, “Pointtad: Multi- label temporal action detection with learnable query points,”Advances in Neural Information Processing Systems, vol. 35, pp. 15 268–15 280, 2022
2022
-
[36]
End-to-end temporal action detection with 1b parameters across 1000 frames,
S. Liu, C.-L. Zhang, C. Zhao, and B. Ghanem, “End-to-end temporal action detection with 1b parameters across 1000 frames,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 18 591–18 601
2024
-
[37]
Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training,
Z. Tong, Y . Song, J. Wang, and L. Wang, “Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training,” Advances in neural information processing systems, vol. 35, pp. 10 078– 10 093, 2022
2022
-
[38]
The mastery of movement
R. Laban and L. Ullmann, “The mastery of movement.” 1971
1971
-
[39]
Emotion regulation through movement: unique sets of movement characteristics are associated with and enhance basic emotions,
T. Shafir, R. P. Tsachor, and K. B. Welch, “Emotion regulation through movement: unique sets of movement characteristics are associated with and enhance basic emotions,”Frontiers in psychology, vol. 6, p. 2030, 2016
2030
-
[40]
How do we recognize emotion from movement? specific motor components contribute to the recog- nition of each emotion,
A. Melzer, T. Shafir, and R. P. Tsachor, “How do we recognize emotion from movement? specific motor components contribute to the recog- nition of each emotion,”Frontiers in psychology, vol. 10, p. 392097, 2019
2019
-
[41]
Boosted lightface: A hybrid dnn and gbm model for boosted facial recognition,
S. I. Serengil and A. Ozpinar, “Boosted lightface: A hybrid dnn and gbm model for boosted facial recognition,”Gazi University Journal of Science, vol. 39, no. 1, pp. 452–466, 2026. [Online]. Available: https://dergipark.org.tr/en/pub/gujs/article/1794891 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11
-
[42]
Qsgd: Communication-efficient sgd via gradient quantization and encoding,
D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. V ojnovic, “Qsgd: Communication-efficient sgd via gradient quantization and encoding,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[43]
Actionformer: Localizing moments of actions with transformers,
C.-L. Zhang, J. Wu, and Y . Li, “Actionformer: Localizing moments of actions with transformers,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 492–510
2022
-
[44]
Diagnosing error in temporal action detectors,
H. Alwassel, F. C. Heilbron, V . Escorcia, and B. Ghanem, “Diagnosing error in temporal action detectors,” inProceedings of the European Conference on Computer Vision, 2018, pp. 256–272
2018
-
[45]
An information-theoretic perspective of tf–idf measures,
A. Aizawa, “An information-theoretic perspective of tf–idf measures,” Information Processing & Management, vol. 39, no. 1, pp. 45–65, 2003. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 APPENDIXA BASELINEIMPLEMENTATIONDETAILS In this appendix, we provide the implementation details of all baselines evaluated on the MMA-82 benchmark. A. Imple...
2003
-
[46]
The baseline achieves a low FN in most dimensions
False Negative Profiling:As shown in Figure 7(a), we report the model’s false negatives (FN) across three dimensions: coverage, length, and instances. The baseline achieves a low FN in most dimensions. As coverage and length increase, the FN decreases; however, as the number of instances increases, the FN rises
-
[47]
Confusion Error
False Positive Profiling:As shown in Figure 7(b), in the left figure, we analyze the false positives at tIoU=0.5. These errors fall into five major categories, with “Confusion Error” and “Wrong Label Error” accounting for the majority. Furthermore, in the right figure, we break down the impact of each error type on the average mAP. Removing “Wrong Label E...
-
[48]
Retracting and stretching arms
Sensitivity Profiling:To evaluate the model’s robustness, we analyze the performance sensitivity across different scales, as shown in Figure 7(c). The model performs stably under varying coverage levels, with performance maximizing at 32.1% when coverage is set to M. Performance tends to improve as action duration increases, but decreases as action densit...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.