When to Write and When to Suppress: Route-Specialized Dual Adapters for Memory-Assisted Knowledge Editing
Pith reviewed 2026-06-27 04:43 UTC · model grok-4.3
The pith
A relevance router pairs with dual adapters to decide when to apply or suppress memory edits in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
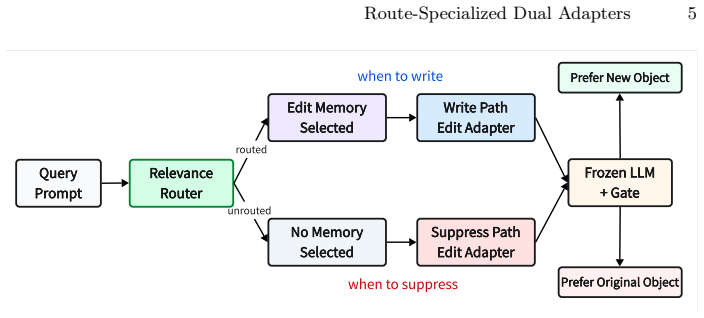
Route-specialized dual adapters let a model retrieve an edit memory at inference time, then apply either an edit adapter that prefers the new object or a locality adapter that restores the original-object preference, depending on a relevance router decision.
What carries the argument
Relevance router that routes prompts to either an edit adapter or a locality adapter, each trained separately under the same memory protocol.
If this is right
- Lexical neural routing performs best on CF while embedding routing performs best on ZSRE and MQuAKE.
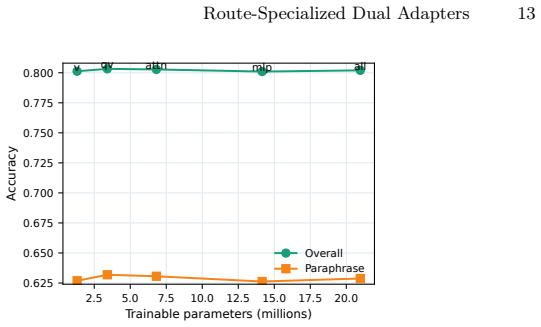
- The dual-adapter split produces higher overall accuracy than increasing LoRA rank or capacity in a single adapter.
- The same router-plus-dual-adapter pattern improves results on both Llama-3.1-8B-Instruct and Qwen3-8B.
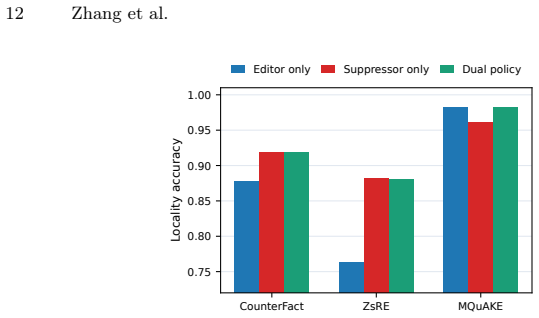
- Edit success and locality can be optimized independently by training the two adapters on disjoint prompt sets.
Where Pith is reading between the lines
- The approach could be tested on sequential editing streams where new facts arrive over time and router decisions must remain stable.
- Router training might be made dataset-agnostic by combining lexical and embedding signals in one model.
- The separation of edit and suppression objectives may reduce unintended changes when multiple overlapping edits are stored in the same memory.
Load-bearing premise
The relevance router correctly separates prompts that need an edit from those that should keep the original behavior, and the two adapters do not interfere when both are loaded.
What would settle it
Measuring whether accuracy falls below single-adapter baselines on any benchmark when the router is replaced by random routing or when both adapters are merged into one.
Figures
read the original abstract
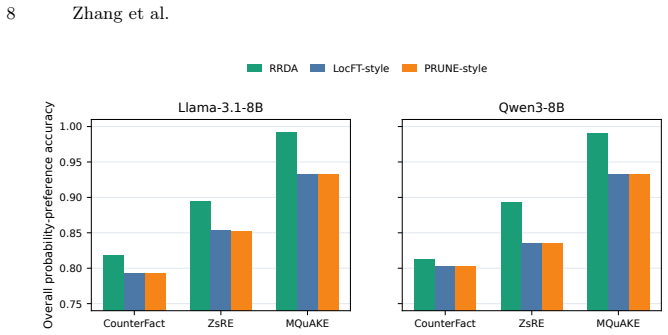
Knowledge editing systems must update selected facts while preserving nearby but irrelevant behavior. This paper studies this problem in a memory-assisted setting where an edit memory is retrieved at inference time and a parameter-efficient adapter corrects the model's object preference. We argue that the central design question is not only how to write an edit, but also when to suppress it. We introduce RRDA, a route-specialized dual-adapter editor. A relevance router first decides whether a prompt should receive an edit memory. Routed prompts use an edit adapter trained to prefer the new object over the original object; unrouted non-direct prompts use a separate locality adapter trained to preserve or restore the original-object preference. We evaluate RRDA on three 1,000-case protocols, CounterFact, ZsRE, and MQuAKE-CF, under the same memory protocol and two 7B/8B base models. On Llama-3.1-8B-Instruct, RRDA obtains the best overall probability-preference accuracy on all three benchmarks: 0.8180 on CounterFact, 0.8946 on ZsRE, and 0.9922 on MQuAKE-CF. The same trend holds on Qwen3-8B. Router ablations show that the relevant memory boundary differs across datasets: a lexical neural router is safest on CounterFact, while BGE embedding routing is better on ZsRE and MQuAKE-CF. Memory, component, and module ablations show that explicit memory supplies the largest edit gain, while route-specialized adapters improve the final reliability-locality balance rather than simply increasing LoRA capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Route-Specialized Dual Adapters (<method>), a memory-assisted knowledge editing approach in which a relevance router first classifies whether a prompt should receive an edit memory. Routed prompts are handled by an edit adapter trained to prefer the new object; non-routed prompts use a separate locality adapter trained to preserve the original-object preference. The method is evaluated under a fixed memory protocol on the CF, ZSRE, and MQuAKE benchmarks (1,000 cases each) using Llama-3.1-8B-Instruct and Qwen3-8B, reporting the highest probability-preference accuracies of 0.8180, 0.8946, and 0.9922 on the Llama model. Router ablations show dataset-specific optimal routers, and component ablations attribute gains to the separation of edit injection from suppression rather than added LoRA capacity.
Significance. If the reported accuracies and ablation attributions hold under detailed verification, the work offers a clear advance in knowledge editing by explicitly modeling the decision of when to suppress an edit. The empirical superiority across three standard benchmarks, the demonstration that dual specialization outperforms capacity increases, and the dataset-specific router analysis provide both a practical method and useful design insight for parameter-efficient editing systems.
major comments (2)
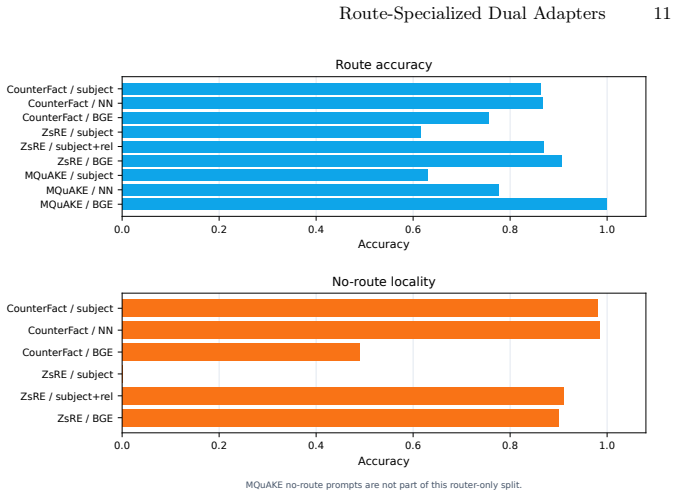
- [Router ablations] Router ablations: The relevance router is load-bearing for the central claim, yet the manuscript reports only that optimal router type differs by dataset (lexical neural safest on CF; BGE embedding better on ZSRE and MQuAKE) without providing router accuracy metrics, misrouting error analysis, or testing a single router across all datasets. This leaves the weakest assumption—that the router accurately identifies edit versus suppression cases—unverified.
- [Component ablations] Component ablations: The claim that performance gains derive from separating edit injection from off-route suppression rather than increased LoRA capacity is central, but the manuscript does not report exact parameter counts, training configurations, or baseline single-adapter setups used in the comparison, making the attribution difficult to assess.
minor comments (2)
- [Abstract] The abstract states that results hold 'under the same memory protocol' but provides no explicit description of that protocol, which would aid reproducibility and verification of the memory-assisted setting.
- [Evaluation] Reported accuracies lack any indication of variance, number of runs, or statistical significance testing, which would strengthen the 'best overall' claim across the three benchmarks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify gaps in the router and component ablation sections that we will address directly in revision.
read point-by-point responses
-
Referee: [Router ablations] Router ablations: The relevance router is load-bearing for the central claim, yet the manuscript reports only that optimal router type differs by dataset (lexical neural safest on CF; BGE embedding better on ZSRE and MQuAKE) without providing router accuracy metrics, misrouting error analysis, or testing a single router across all datasets. This leaves the weakest assumption—that the router accurately identifies edit versus suppression cases—unverified.
Authors: We agree that router accuracy metrics and misrouting analysis are needed to substantiate the central claim. In the revised manuscript we will report per-dataset router accuracy (edit vs. non-edit classification) on held-out prompts, include a confusion-matrix style error analysis of misrouted cases, and add results for a single fixed router (the best-performing one) evaluated across all three benchmarks to demonstrate cross-dataset robustness. revision: yes
-
Referee: [Component ablations] Component ablations: The claim that performance gains derive from separating edit injection from off-route suppression rather than increased LoRA capacity is central, but the manuscript does not report exact parameter counts, training configurations, or baseline single-adapter setups used in the comparison, making the attribution difficult to assess.
Authors: We will expand the component ablation section to include exact trainable parameter counts for the dual-adapter and single-adapter configurations, full training hyper-parameters (learning rate, epochs, batch size), and a clearer description of the single-adapter baselines (identical total capacity, same training data mixture). These additions will allow readers to verify that gains are attributable to specialization rather than capacity. revision: yes
Circularity Check
No significant circularity; empirical method validated on external benchmarks
full rationale
The paper proposes a dual-adapter architecture with a relevance router for knowledge editing and evaluates it through direct accuracy measurements and ablations on three standard benchmarks (CF, ZSRE, MQuAKE) using Llama-3.1-8B-Instruct and Qwen3-8B. All reported gains are attributed to component separation via explicit router and module ablations rather than any closed-form derivation, fitted parameter renamed as prediction, or self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked that reduce to the method's own inputs by construction. The work is self-contained against external benchmarks and does not rely on internal self-referential logic for its central claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- router selection per dataset
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.