When the Same Musical Knowledge Forgets Differently: A Clean Probe of Pathway-Dependent Forgetting
Pith reviewed 2026-06-27 04:48 UTC · model grok-4.3
The pith
Text-acquired musical knowledge forgets more than the same knowledge acquired via audio under identical pressure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
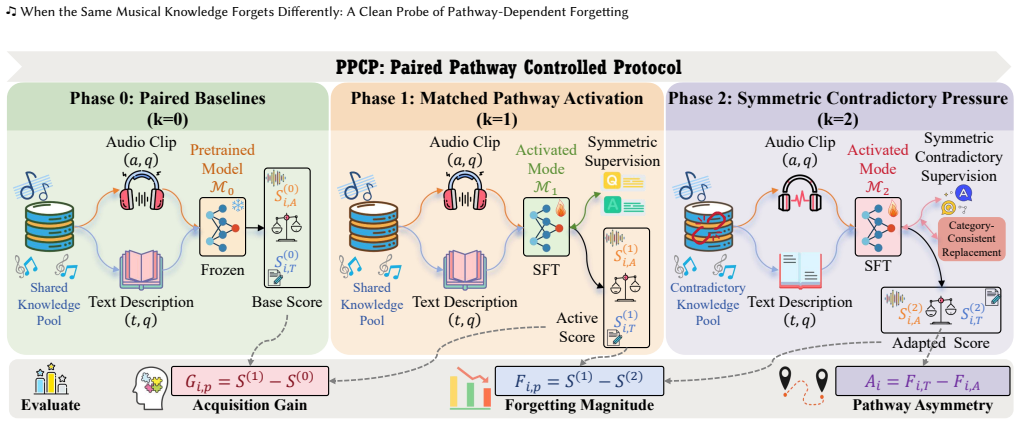
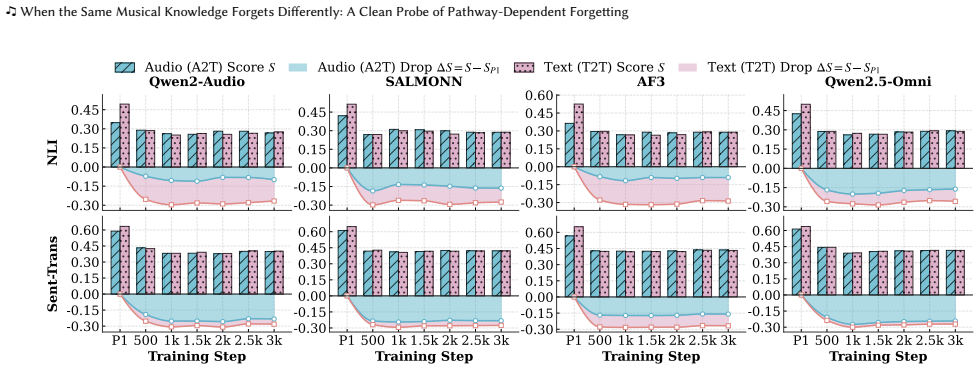
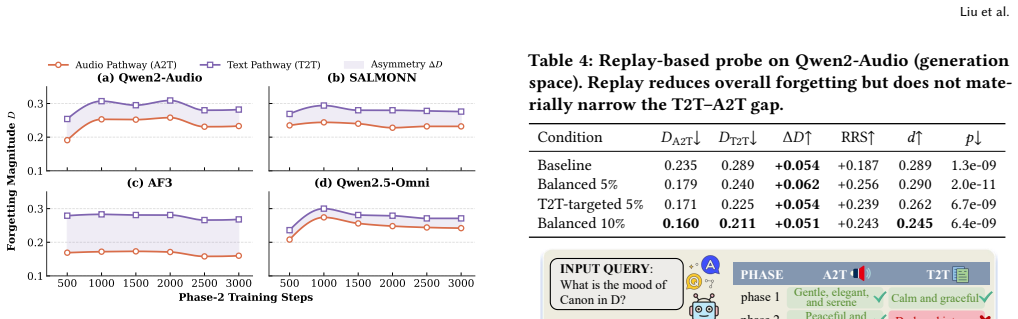
Across multiple architecturally distinct audio-language models, text-pathway knowledge is forgotten more than matched audio-pathway knowledge under identical adaptation pressure. To attribute this to route rather than confounds, the Paired Pathway Controlled Protocol establishes matched pathway baselines, activates both pathways under symmetric supervision on the same knowledge pool, and applies identical forgetting pressure to both pathways. The gap is stable across models and gain-controlled analyses, persists when contradictory overwrite is replaced by correct-label cross-domain learning, remains under single-modality pressure, and is not removed by lightweight replay. Two independent rou
What carries the argument
The Paired Pathway Controlled Protocol (PPCP), a three-phase design that matches pathways and applies symmetric forgetting pressure to isolate acquisition route effects.
Load-bearing premise
The Paired Pathway Controlled Protocol successfully attributes the observed asymmetry to the acquisition route rather than confounds such as architectural depth or data differences.
What would settle it
A replication using the same PPCP protocol across several models that finds equal forgetting rates for text and audio pathways would show the route does not drive the difference.
Figures

read the original abstract
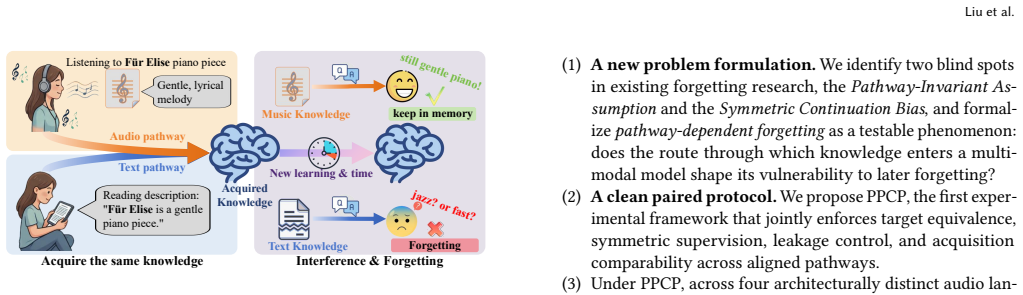
A model can learn that the piano piece F\"ur Elise is calm and reflective by listening to the audio or by reading a text description, but does it matter which route that knowledge took when it is later at risk of being forgotten? Forgetting research in multimodal models measures what knowledge is lost under adaptation, yet has not asked whether acquisition route affects how easily that knowledge is forgotten. We call this untested premise the Pathway-Invariant Assumption. Music understanding enables a clean test because a music clip and a canonical text description can be aligned to the same perceptual content, allowing the same knowledge unit to enter a model through listening or reading while the target remains fixed. Across multiple architecturally distinct audio-language models, we observe a consistent asymmetry: text-pathway knowledge is forgotten more than matched audio-pathway knowledge under identical adaptation pressure. To attribute this effect to route rather than confounds, we introduce the Paired Pathway Controlled Protocol (PPCP), a three-phase design that establishes matched pathway baselines, activates both pathways under symmetric supervision on the same knowledge pool, and applies identical forgetting pressure to both pathways. The gap is stable across models and gain-controlled analyses, persists when contradictory overwrite is replaced by correct-label cross-domain learning, remains under single-modality pressure, and is not removed by lightweight replay. Two independent routing-depth controls confirm that the effect is not explained by architectural depth, pointing to input representation as the dominant factor. Under PPCP, our results demonstrate that forgetting is highly route-dependent, establishing acquisition route as a new analytical dimension for forgetting research and multimodal system design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the acquisition route of knowledge affects forgetting rates in multimodal audio-language models, violating the Pathway-Invariant Assumption. Using music clips and aligned text descriptions as matched knowledge units, it reports that text-pathway knowledge is forgotten more readily than audio-pathway knowledge under identical adaptation pressure. The Paired Pathway Controlled Protocol (PPCP) is introduced to establish matched baselines, apply symmetric supervision on the same knowledge pool, and impose identical forgetting pressure while controlling for architectural depth and data mismatch. The asymmetry persists across architecturally distinct models, gain-controlled analyses, single-modality pressure, replay, cross-domain overwrite, and two independent routing-depth controls, attributing the effect primarily to input representation.
Significance. If the results hold under the described controls, the work supplies a clean empirical demonstration that acquisition route is a load-bearing factor in forgetting, adding a new analytical dimension to multimodal forgetting research and system design. The music testbed enables precise alignment of perceptual content across modalities, and the PPCP framework (matched baselines + symmetric supervision + identical pressure plus persistence checks) is a reusable methodological contribution. Explicit credit is due for the stability of the text-vs-audio gap across the listed controls and the routing-depth verifications, which directly address the main confounds.
minor comments (2)
- [Abstract] Abstract: the claim of stability 'across models' would be strengthened by stating the number of models and the typical magnitude of the asymmetry (e.g., percentage-point difference in forgetting rate).
- [Methods (PPCP)] The description of the PPCP three-phase design would benefit from an explicit diagram or table summarizing the matched conditions for each pathway at each phase.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, accurate summary of our contributions, and recommendation of minor revision. The referee correctly identifies the core claim, the role of the PPCP protocol, and the robustness checks across models and controls. No specific major comments were raised in the report.
Circularity Check
Empirical protocol with no derivation chain
full rationale
The paper is a controlled empirical study introducing the PPCP protocol to isolate acquisition-route effects on forgetting. No equations, derivations, fitted parameters, or self-citation chains are present that could reduce any claim to its own inputs by construction. The central attribution rests on experimental controls (matched baselines, symmetric supervision, routing-depth checks) rather than definitional equivalence or renamed fits. This matches the default expectation of no significant circularity for non-derivational work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A music clip and its canonical text description align to the same perceptual content allowing matched knowledge units
Reference graph
Works this paper leans on
-
[1]
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajber, and Stefano Soatto. 2019. Continual learning with tiny episodic memories. In Workshop on Multi-Task and Lifelong Reinforcement Learning
2019
-
[2]
Qizhou Chen, Chengyu Wang, Dakan Wang, Taolin Zhang, Wangyue Li, and Xiaofeng He. 2025. Lifelong knowledge editing for vision language models with low-rank mixture-of-experts. InProceedings of the Computer Vision and Pattern Recognition Conference. 9455–9466
2025
-
[3]
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, and Furu Wei. 2023. BEATs: Audio Pre-Training with Acoustic Tokenizers. In Proceedings of the 40th International Conference on Machine Learning (ICML), Vol. 202. PMLR, 5178–5193
2023
-
[4]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. https://lmsys.org/blog/2023-03-30-vicuna/
2023
-
[5]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, et al. 2024. Qwen2-Audio technical report.arXiv preprint arXiv:2407.10759(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
William G. Cochran. 1957. Analysis of Covariance: Its Nature and Uses.Biometrics 13, 3 (1957), 261–281
1957
-
[7]
1988.Statistical Power Analysis for the Behavioral Sciences(2nd ed.)
Jacob Cohen. 1988.Statistical Power Analysis for the Behavioral Sciences(2nd ed.). Lawrence Erlbaum Associates
1988
-
[8]
Bradley Efron. 1979. Bootstrap Methods: Another Look at the Jackknife.The Annals of Statistics7, 1 (1979), 1–26
1979
-
[9]
Robert M French. 1999. Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences3, 4 (1999), 128–135
1999
-
[10]
Sreyan Ghosh, Arushi Goel, Lasha Koroshinadze, Sang-gil Lee, Zhifeng Kong, Joao Felipe Santos, Ramani Duraiswami, Dinesh Manocha, Wei Ping, Mohammad Shoeybi, and Bryan Catanzaro. 2025. Music Flamingo: Scaling Music Under- standing in Audio Language Models.arXiv preprint arXiv:2511.10289(2025)
-
[11]
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang-gil Lee, Chao-Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. 2025. Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models.arXiv preprint arXiv:2507.08128 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Tianyu Huai, Jie Zhou, Xingjiao Wu, Qin Chen, Qingchun Bai, Ze Zhou, and Liang He. 2025. Cl-moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering. InProceedings of the computer vision and pattern recognition conference. 19608– 19617
2025
-
[13]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences114, 13 (2017), 3521– 3526
2017
-
[14]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: Boot- strapping Language-Image Pre-Training with Frozen Image Encoders and Large Language Models. InInternational Conference on Machine Learning. PMLR, 19730– 19742
2023
-
[15]
Shansong Liu, Atin Sakkeer Hussain, Chenshuo Sun, and Ying Shan. 2024. Music understanding llama: Advancing text-to-music generation with question an- swering and captioning. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 286–290
2024
- [16]
-
[17]
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary Chase Lipton, and J Zico Kolter. 2024. TOFU: A Task of Fictitious Unlearning for LLMs. InAdvances in Neural Information Processing Systems
2024
-
[18]
Michael McCloskey and Neal J Cohen. 1989. Catastrophic interference in con- nectionist networks: The sequential learning problem.Psychology of Learning and Motivation24 (1989), 109–165
1989
-
[19]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and Editing Factual Associations in GPT. InAdvances in Neural Information Processing Systems
2022
-
[20]
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. 2023. Mass-Editing Memory in a Transformer. InProceedings of the 11th International Conference on Learning Representations (ICLR)
2023
- [21]
-
[22]
Weiguo Pian, Shijian Deng, Shentong Mo, Yunhui Guo, and Yapeng Tian. 2025. Modality-Inconsistent Continual Learning of Multimodal Large Language Mod- els. InProceedings of the 39th AAAI Conference on Artificial Intelligence
2025
-
[23]
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. 2019. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 527–536
2019
-
[24]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust Speech Recognition via Large-Scale Weak Super- vision. InProceedings of the 40th International Conference on Machine Learning (ICML), Vol. 202. PMLR, 28492–28518
2023
-
[25]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing
2019
-
[26]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. 2016. Pro- gressive neural networks.arXiv preprint arXiv:1606.04671(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. 2025. Continual Learning of Large Language Models: A Comprehensive Survey.Comput. Surveys58, 5 (2025). doi:10.1145/3735633
-
[28]
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. 2023. Salmonn: Towards generic hearing abilities for large language models.arXiv preprint arXiv:2310.13289(2023). Liu et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Lukas Thede, Karsten Roth, Matthias Bethge, Zeynep Akata, and Tom Hartvigsen
- [30]
-
[31]
Gido M van de Ven, Nicholas Soures, and Dhireesha Kudithipudi. 2025. Continual Learning and Catastrophic Forgetting. InLearning and Memory: A Comprehensive Reference(3rd ed.), John Wixted (Ed.). Vol. 1. Academic Press, 153–168
2025
-
[32]
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. 2024. A Comprehensive Survey of Continual Learning: Theory, Method and Application.IEEE Trans- actions on Pattern Analysis and Machine Intelligence46, 8 (2024), 5362–5383. doi:10.1109/TPAMI.2024.3367329
-
[33]
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2022. Finetuned Language Models Are Zero-Shot Learners. InProceedings of the 10th International Conference on Learning Representations (ICLR)
2022
-
[34]
Xiwen Wei, Mustafa Munir, and Radu Marculescu. 2025. Mitigating Intra- and Inter-modal Forgetting in Continual Learning of Unified Multimodal Models. In Advances in Neural Information Processing Systems
2025
- [35]
-
[36]
Frank Wilcoxon. 1945. Individual Comparisons by Ranking Methods.Biometrics Bulletin1, 6 (1945), 80–83
1945
-
[37]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Jun- yang Lin. 2025. Qwen2.5-Omni Technical Report.arXiv preprint arXiv:2503.20215 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Yuexiang Zhai, Shengbang Tong, Xiao Li, Mu Cai, Qing Qu, Yong Jae Lee, and Yi Ma. 2024. Investigating the Catastrophic Forgetting in Multimodal Large Language Models. InConference on Parsimony and Learning
2024
-
[39]
Qiang Zhang, Fanrui Zhang, Jiawei Liu, Ming Hu, Junjun He, and Zheng-Jun Zha. [n. d.]. Reliable Lifelong Multimodal Editing: Conflict-Aware Retrieval Meets Multi-Level Guidance. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[40]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi
-
[41]
InProceedings of the 8th International Conference on Learning Representations (ICLR)
BERTScore: Evaluating Text Generation with BERT. InProceedings of the 8th International Conference on Learning Representations (ICLR)
-
[42]
Junhao Zheng, Qianli Ma, Zhen Liu, Binquan Wu, and Huawen Feng. 2024. Beyond Anti-Forgetting: Multimodal Continual Instruction Tuning with Positive Forward Transfer.arXiv preprint arXiv:2401.09181(2024). When the Same Musical Knowledge Forgets Differently: A Clean Probe of Pathway-Dependent Forgetting A Training Hyperparameters Table 5 lists the full trai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.