Show the Signal, Hide the Noise: Spectral Forcing for Pixel-Space Diffusion
Pith reviewed 2026-06-27 04:18 UTC · model grok-4.3
The pith
A time-conditional low-pass filter on noisy inputs improves pixel-space diffusion by enforcing the signal-noise boundary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
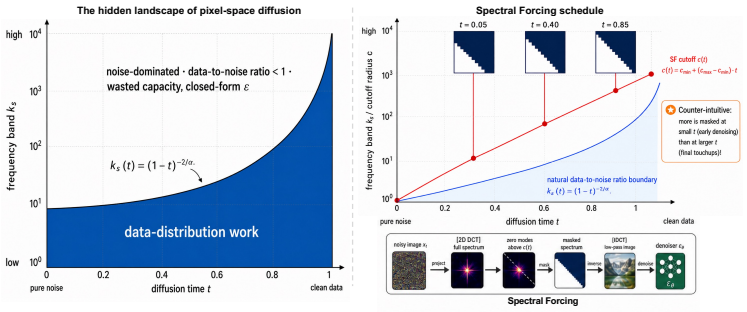
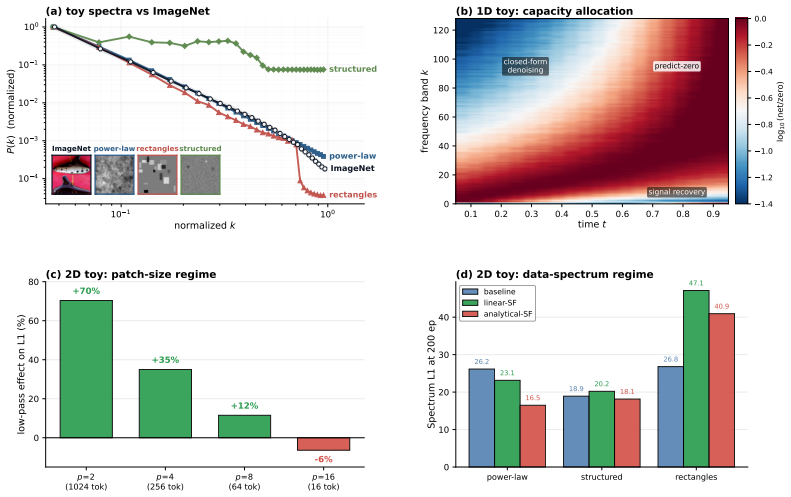
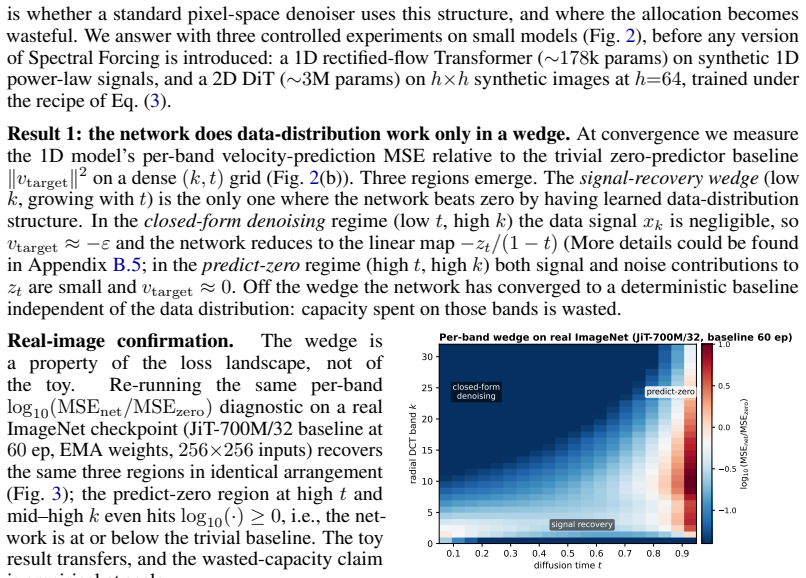
Under rectified-flow diffusion and natural-image power-law spectra, the per-band data-to-noise contour k*(t) = (1-t)^{-2/α} separates a signal-bearing low-frequency region from a noise-dominated high-frequency region at each time t. This contour induces a capacity-allocation problem because a standard pixel-space denoiser must discover the moving boundary internally. Spectral Forcing renders the boundary explicit by applying a parameter-free, time-conditional 2D-DCT low-pass operator to the noisy input before the patch embedder; the cutoff expands monotonically with diffusion time and equals the identity at the data endpoint.
What carries the argument
Spectral Forcing: a parameter-free, time-conditional 2D-DCT low-pass operator applied to the noisy input whose cutoff expands with diffusion time t.
If this is right
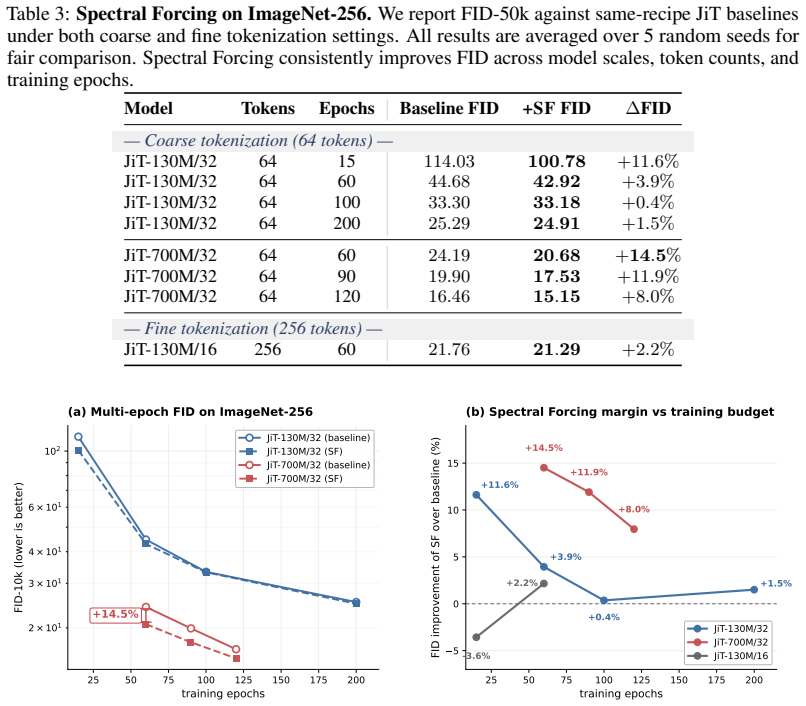
- On ImageNet-256 the operator improves both FID and Inception Score across training epochs.
- The gains persist at finer tokenization levels where the method remains competitive.
- The same unchanged operator raises benchmark scores when inserted into a unified text-to-image model.
- The results indicate that an input-side spectral prior can transfer beyond class-conditional generation.
Where Pith is reading between the lines
- The same operator could be tested on diffusion schedules other than rectified flow to check whether the derived boundary generalizes.
- If high-frequency content carries task-specific signal on certain datasets, the operator might be replaced by a learnable or data-dependent cutoff.
- Capacity savings from hiding noise could allow smaller models to reach performance previously requiring larger ones.
Load-bearing premise
High-frequency content in the target data is predominantly noise rather than essential signal in the regime of coarse patch tokenization.
What would settle it
Training a pixel-space diffusion model on ImageNet-256 both with and without the low-pass operator and finding no gain or a loss in FID at the final checkpoint.
Figures

read the original abstract
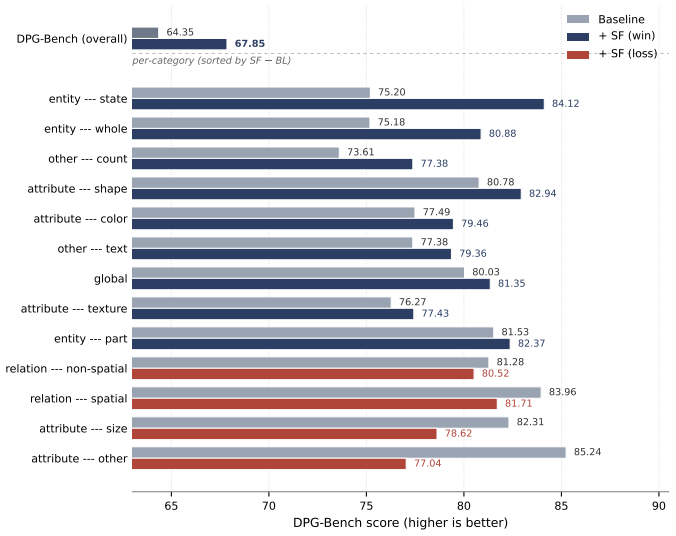
Pixel-space diffusion models are trained on full-bandwidth noisy images, yet the useful signal available to the denoiser is strongly frequency dependent. Under rectified-flow diffusion and natural-image power-law spectra, the per-band data-to-noise contour $k^{*}(t) = (1-t)^{-2/\alpha}$ separates a signal-bearing low-frequency region from a noise-dominated high-frequency region at each time $t$. We show that this implicit coarse-to-fine structure is not merely descriptive: it induces a capacity-allocation problem. A standard pixel-space denoiser must discover the moving bandwidth boundary internally and can spend computation on frequency-time regions where the optimal prediction collapses to deterministic baselines rather than data-distribution modeling. To make this boundary explicit, we introduce Spectral Forcing, a parameter-free, time-conditional 2D-DCT low-pass operator applied to the noisy input before the patch embedder. Its cutoff expands monotonically with the diffusion time and becomes the identity at the data endpoint. Through controlled synthetic experiments, we identify the regime in which the operator is beneficial: coarse patch tokenization and data whose high-frequency content is predominantly noise rather than essential signal. On ImageNet-256 with JiT-700M/32, Spectral Forcing consistently improves both FID and Inception Score across different training epochs, demonstrating robust gains throughout training; at finer tokenization, the spectral forcing is still competitive. We further insert the unchanged operator into SenseNova-U1, a unified text-to-image model, where it improves DPG-Bench and GenEval, showing that the input-side spectral prior transfers beyond class-conditional generation. These results suggest a route to capacity-efficient pixel-space diffusion by showing the signal and hiding the noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under rectified-flow diffusion and natural-image power-law spectra, the contour k*(t)=(1-t)^{-2/α} delineates signal-bearing low-frequency bands from noise-dominated high-frequency bands; a standard pixel-space denoiser wastes capacity discovering this moving boundary internally. Spectral Forcing is introduced as a parameter-free, time-conditional 2D-DCT low-pass operator applied to the noisy input that explicitly enforces the boundary, becoming the identity at t=0. Controlled synthetic experiments identify the beneficial regime (coarse patch tokenization with noise-dominated HF content). On ImageNet-256 with JiT-700M/32 the operator yields consistent FID and IS gains across training epochs and remains competitive at finer tokenization; the same unchanged operator improves DPG-Bench and GenEval when inserted into SenseNova-U1.
Significance. If the reported gains survive rigorous controls and are shown to arise from the explicit k*(t) boundary rather than generic high-frequency attenuation, the method supplies a lightweight, input-side spectral prior that could improve capacity efficiency in pixel-space diffusion models without changing the backbone. The identification of a specific regime via synthetic experiments and the demonstration of transfer to a unified text-to-image model are positive features; the absence of error bars, multiple random seeds, and targeted ablations against alternative regularizers currently limits how strongly the capacity-allocation interpretation can be endorsed.
major comments (2)
- [Experiments (ImageNet-256 and SenseNova-U1)] Experiments section (ImageNet-256 and SenseNova results): the reported FID/IS and DPG-Bench/GenEval improvements are presented without error bars, without comparison to a fixed-cutoff low-pass baseline, a mismatched time schedule, or a non-spectral high-frequency attenuator. These controls are required to distinguish the claimed mechanism (explicit enforcement of the derived k*(t) boundary) from generic regularization or aliasing reduction; their absence makes the central capacity-allocation claim load-bearing yet under-supported.
- [§2] §2 (derivation of k*(t) and operator definition): the operator is described as making the boundary 'explicit,' yet the manuscript does not report a direct verification that the chosen DCT cutoff schedule matches the theoretical contour on the actual training data distribution; without this check the link between the analytic derivation and the implemented low-pass remains an assumption rather than a demonstrated property.
minor comments (2)
- [§2] Notation: the power-law exponent α is introduced without an explicit statement of its empirical value or fitting procedure on ImageNet; a short appendix table would clarify reproducibility.
- [Synthetic experiments] Figure clarity: the synthetic-experiment plots would benefit from an additional panel showing the effective cutoff frequency versus t for the chosen α, to allow direct visual comparison with the theoretical k*(t) curve.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the experimental section would benefit from additional controls and that a direct empirical check on the training distribution would strengthen the link between theory and implementation. We respond to each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: Experiments section (ImageNet-256 and SenseNova results): the reported FID/IS and DPG-Bench/GenEval improvements are presented without error bars, without comparison to a fixed-cutoff low-pass baseline, a mismatched time schedule, or a non-spectral high-frequency attenuator. These controls are required to distinguish the claimed mechanism (explicit enforcement of the derived k*(t) boundary) from generic regularization or aliasing reduction; their absence makes the central capacity-allocation claim load-bearing yet under-supported.
Authors: We agree these controls are required to isolate the contribution of the time-dependent k*(t) contour. In the revision we will report FID and IS with error bars over at least three random seeds on ImageNet-256. We will add ablations comparing Spectral Forcing against (i) a fixed (time-independent) DCT cutoff, (ii) a deliberately mismatched cutoff schedule, and (iii) a non-spectral attenuator (Gaussian blur in pixel space). These will be presented alongside the existing results to test whether gains arise specifically from the derived boundary rather than generic high-frequency attenuation. For the proprietary SenseNova-U1 model we retain the single-run numbers but note the limitation. revision: yes
-
Referee: §2 (derivation of k*(t) and operator definition): the operator is described as making the boundary 'explicit,' yet the manuscript does not report a direct verification that the chosen DCT cutoff schedule matches the theoretical contour on the actual training data distribution; without this check the link between the analytic derivation and the implemented low-pass remains an assumption rather than a demonstrated property.
Authors: The k*(t) contour follows directly from the power-law spectrum assumption (α≈2) that is standard for natural images under rectified flow; the synthetic experiments already identify the regime where this contour is beneficial. To make the connection explicit, the revised manuscript will include an empirical verification: we will compute per-frequency signal-to-noise ratios on ImageNet training samples at multiple diffusion times t and overlay the theoretical k*(t) contour against the implemented DCT cutoff schedule, confirming alignment on the actual data distribution. revision: yes
Circularity Check
No circularity: derivation rests on external assumptions and separate empirical tests
full rationale
The k*(t)=(1-t)^{-2/α} contour is obtained from rectified-flow dynamics plus an assumed power-law spectrum; these are stated as pre-existing inputs rather than fitted or self-defined within the paper. The Spectral Forcing operator is then defined directly from that contour as a time-dependent DCT low-pass applied to the input. No equation or claim reduces the operator, the capacity-allocation argument, or the reported FID/IS gains to a tautology, a renamed fit, or a self-citation chain. The synthetic regime identification and ImageNet/SenseNova results are presented as independent measurements, not as outputs forced by the derivation itself. The paper therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Natural images obey power-law spectra with exponent α
- domain assumption Rectified-flow diffusion dynamics
Reference graph
Works this paper leans on
-
[1]
Stochastic interpolants: A unifying framework for flows and diffusions
Michael Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions. volume 26, pages 1–80, 2025
2025
-
[2]
Latent forcing: Reordering the diffusion trajectory for pixel-space image generation
Alan Baade, Eric Ryan Chan, Kyle Sargent, Changan Chen, Justin Johnson, Ehsan Adeli, and Li Fei-Fei. Latent forcing: Reordering the diffusion trajectory for pixel-space image generation. 2026
2026
-
[3]
Color and spatial structure in natural scenes.Applied optics, 26 (1):157–170, 1987
Geoffrey J Burton and Ian R Moorhead. Color and spatial structure in natural scenes.Applied optics, 26 (1):157–170, 1987
1987
-
[4]
Pixelflow: Pixel-space generative models with flow
Shoufa Chen, Chongjian Ge, Shilong Zhang, Peize Sun, and Ping Luo. Pixelflow: Pixel-space generative models with flow. 2025
2025
-
[5]
Deep generative image models using a laplacian pyramid of adversarial networks
Emily L Denton, Soumith Chintala, Rob Fergus, et al. Deep generative image models using a laplacian pyramid of adversarial networks. volume 28, 2015
2015
-
[6]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. volume 34, pages 8780–8794, 2021. 10
2021
-
[7]
From pixels to words–towards native vision-language primitives at scale
Haiwen Diao, Mingxuan Li, Silei Wu, Linjun Dai, Xiaohua Wang, Hanming Deng, Lewei Lu, Dahua Lin, and Ziwei Liu. From pixels to words–towards native vision-language primitives at scale. 2025
2025
-
[8]
Haiwen Diao, Penghao Wu, Hanming Deng, Jiahao Wang, Shihao Bai, Silei Wu, Weichen Fan, Wenjie Ye, Wenwen Tong, and Xiangyu Fan et al. Sensenova-u1: Unifying multimodal understanding and generation with neo-unify architecture.arXiv preprint arXiv:2605.12500, 2026
Pith/arXiv arXiv 2026
-
[9]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, and Sylvain Gelly et al. An image is worth 16x16 words: Transformers for image recognition at scale. 2020
2020
-
[10]
Scaling rectified flow transformers for high- resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, and Frederic Boesel et al. Scaling rectified flow transformers for high- resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[11]
Frido: Feature pyramid diffusion for complex scene image synthesis
Wan-Cyuan Fan, Yen-Chun Chen, DongDong Chen, Yu Cheng, Lu Yuan, and Yu-Chiang Frank Wang. Frido: Feature pyramid diffusion for complex scene image synthesis. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 579–587, 2023
2023
-
[12]
The prism hypothesis: Harmonizing semantic and pixel representations via unified autoencoding
Weichen Fan, Haiwen Diao, Quan Wang, Dahua Lin, and Ziwei Liu. The prism hypothesis: Harmonizing semantic and pixel representations via unified autoencoding. 2025
2025
-
[13]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. 2022
2022
-
[14]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. volume 33, pages 6840–6851, 2020
2020
-
[15]
Cascaded diffusion models for high fidelity image generation
Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation. volume 23, pages 1–33, 2022
2022
-
[16]
Blurring diffusion models
Emiel Hoogeboom and Tim Salimans. Blurring diffusion models. 2022
2022
-
[17]
Simpler diffusion: 1.5 fid on imagenet512 with pixel-space diffusion
Emiel Hoogeboom, Thomas Mensink, Jonathan Heek, Kay Lamerigts, Ruiqi Gao, and Tim Salimans. Simpler diffusion: 1.5 fid on imagenet512 with pixel-space diffusion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18062–18071, 2025
2025
-
[18]
Spectralar: Spectral autoregressive visual generation, 2025
Yuanhui Huang, Weiliang Chen, Wenzhao Zheng, Yueqi Duan, Jie Zhou, and Jiwen Lu. Spectralar: Spectral autoregressive visual generation, 2025
2025
-
[19]
Nfig: multi-scale autoregressive image generation via frequency ordering
Zhihao Huang, Xi Qiu, Yukuo Ma, Yifu Zhou, Junjie Chen, Hongyuan Zhang, Chi Zhang, and Xuelong Li. Nfig: multi-scale autoregressive image generation via frequency ordering. 2025
2025
-
[20]
Focal frequency loss for image reconstruction and synthesis
Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. Focal frequency loss for image reconstruction and synthesis. InProceedings of the IEEE/CVF international conference on computer vision, pages 13919–13929, 2021
2021
-
[21]
Alias-free generative adversarial networks
Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Alias-free generative adversarial networks. volume 34, pages 852–863, 2021
2021
-
[22]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. volume 35, pages 26565–26577, 2022
2022
-
[23]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, and Patrick Esser et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space. 2025
2025
-
[24]
Back to basics: Let denoising generative models denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise. 2025
2025
-
[25]
Autoregressive image generation without vector quantization
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization. volume 37, pages 56424–56445, 2024
2024
-
[26]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. 2022
2022
-
[27]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. 2022
2022
-
[28]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In European Conference on Computer Vision, pages 23–40. Springer, 2024. 11
2024
-
[29]
An image is worth more than 16x16 patches: Exploring transformers on individual pixels
Duy-Kien Nguyen, Mahmoud Assran, Unnat Jain, Martin R Oswald, Cees GM Snoek, and Xinlei Chen. An image is worth more than 16x16 patches: Exploring transformers on individual pixels. 2024
2024
-
[30]
Glide: Towards photorealistic image generation and editing with text-guided diffusion models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. 2021
2021
-
[31]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International conference on machine learning, pages 8162–8171. PMLR, 2021
2021
-
[32]
Dctdiff: Intriguing properties of image generative modeling in the dct space
Mang Ning, Mingxiao Li, Jianlin Su, Haozhe Jia, Lanmiao Liu, Martin Beneš, Wenshuo Chen, Albert Ali Salah, and Itir Onal Ertugrul. Dctdiff: Intriguing properties of image generative modeling in the dct space. 2024
2024
-
[33]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[34]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. 2023
2023
-
[35]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
2019
-
[36]
Generative modelling with inverse heat dissipation
Severi Rissanen, Markus Heinonen, and Arno Solin. Generative modelling with inverse heat dissipation. 2022
2022
-
[37]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[38]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[39]
The statistics of natural images.Network: computation in neural systems, 5(4):517, 1994
Daniel L Ruderman. The statistics of natural images.Network: computation in neural systems, 5(4):517, 1994
1994
-
[40]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, and Tim Salimans et al. Photorealistic text-to-image diffusion models with deep language understanding. volume 35, pages 36479–36494, 2022
2022
-
[41]
Latent diffusion model without variational autoencoder
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Jiwen Lu. Latent diffusion model without variational autoencoder. 2025
2025
-
[42]
Implicit neural representations with periodic activation functions
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. volume 33, pages 7462–7473, 2020
2020
-
[43]
Hierarchical patch diffusion models for high-resolution video generation
Ivan Skorokhodov, Willi Menapace, Aliaksandr Siarohin, and Sergey Tulyakov. Hierarchical patch diffusion models for high-resolution video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7569–7579, 2024
2024
-
[44]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
2015
-
[45]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. volume 32, 2019
2019
-
[46]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. 2020
2020
-
[47]
Fourier features let networks learn high frequency functions in low dimensional domains
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. volume 33, pages 7537–7547, 2020
2020
-
[48]
Visual autoregressive modeling: Scalable image generation via next-scale prediction
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction. volume 37, pages 84839–84865, 2024. 12
2024
-
[49]
Statistics of natural image categories.Network: computation in neural systems, 14(3):391, 2003
Antonio Torralba and Aude Oliva. Statistics of natural image categories.Network: computation in neural systems, 14(3):391, 2003
2003
-
[50]
Pixnerd: Pixel neural field diffusion
Shuai Wang, Ziteng Gao, Chenhui Zhu, Weilin Huang, and Limin Wang. Pixnerd: Pixel neural field diffusion. 2025
2025
-
[51]
Next visual granularity generation
Yikai Wang, Zhouxia Wang, Zhonghua Wu, Qingyi Tao, Kang Liao, and Chen Change Loy. Next visual granularity generation. 2025
2025
-
[52]
Reconstruction vs
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15703–15712, 2025
2025
-
[53]
Zoomldm: Latent diffusion model for multi-scale image generation
Srikar Yellapragada, Alexandros Graikos, Kostas Triaridis, Prateek Prasanna, Rajarsi Gupta, Joel Saltz, and Dimitris Samaras. Zoomldm: Latent diffusion model for multi-scale image generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23453–23463, 2025
2025
-
[54]
Representation alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. 2024
2024
-
[55]
Uniflow: A unified pixel flow tokenizer for visual understanding and generation
Zhengrong Yue, Haiyu Zhang, Xiangyu Zeng, Boyu Chen, Chenting Wang, Shaobin Zhuang, Lu Dong, Yi Wang, Limin Wang, and Yali Wang. Uniflow: A unified pixel flow tokenizer for visual understanding and generation. 2025
2025
-
[56]
loss at convergence
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders. 2025. 13 A Implementation Details Our implementation closely follows the JiT recipe of Li and He [24], with Spectral Forcing as a deterministic input-side adapter applied before the patch embedder. The configurations of all our experiments are...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.