Beyond Monolingual Deep Research: Evaluating Agents and Retrievers with Cross-Lingual BrowseComp-Plus
Pith reviewed 2026-06-27 04:09 UTC · model grok-4.3
The pith
Deep research agents and retrievers lose performance when evidence appears in a language different from the query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
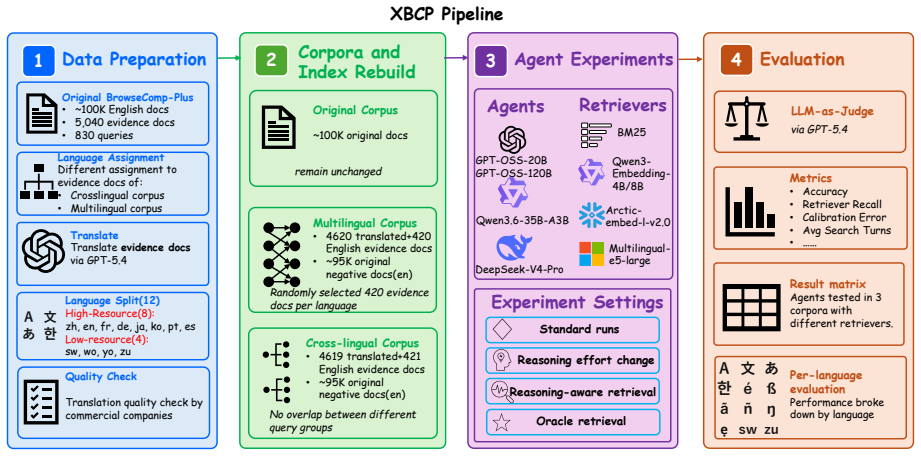
XBCP keeps the English question-and-answer pairs from BrowseComp-Plus but replaces the supporting documents with translations in either a single assigned language per query or a balanced distribution across twelve languages. When four agents are run with sparse and dense multilingual retrievers, evidence recall falls, calibration worsens, citations become less reliable, and final answer accuracy declines. These accuracy reductions remain even under oracle conditions that supply every gold document directly, indicating that cross-lingual deep research reveals both retrieval shortfalls and a distinct agent-side limitation in integrating language-mismatched evidence.
What carries the argument
The XBCP benchmark, which holds English queries and answers fixed while varying document languages across single-language and evenly distributed multilingual corpora to isolate mismatch effects.
If this is right
- Both sparse and dense multilingual retrievers lose evidence recall when documents are translated.
- Agents exhibit reduced calibration and lower citation fidelity in cross-lingual and multilingual evidence settings.
- Answer accuracy stays lower even when every gold document is supplied directly to the agent.
- Performance varies across the high-resource and low-resource languages included in the multilingual corpus.
Where Pith is reading between the lines
- Agents may need additional mechanisms for cross-lingual evidence synthesis that go beyond current retrieval-plus-reasoning pipelines.
- Monolingual benchmarks likely overestimate agent reliability in real environments where relevant sources appear in multiple languages.
- Testing the same agents on additional language pairs could expose whether integration difficulty scales with resource level or linguistic distance.
Load-bearing premise
The translations used to create the non-English documents preserve semantic content and factual accuracy without introducing artifacts that confound the language-mismatch variable.
What would settle it
Measuring no drop in answer accuracy when agents receive all gold evidence in a mismatched language compared with the original English setting would falsify the claim of an independent agent-side integration difficulty.
Figures
read the original abstract
Deep research agents are increasingly evaluated on their ability to search for evidence, reason over retrieved sources, and produce grounded answers. Existing browsing benchmarks, however, largely assume that the user's query and the supporting evidence are written in the same language, leaving open whether agentic search systems can operate when relevant evidence appears in another language. We introduce XBCP (Cross-lingual BrowseComp-Plus), a controlled benchmark that preserves the English question-and-answer space of BrowseComp-Plus but varies the languages of the supporting documents. XBCP instantiates two complementary settings: in the cross-lingual setting, each query is paired with evidence in a single assigned language. In the multilingual setting, the full evidence corpus is distributed equally and randomly across 12 languages spanning high-resource and low-resource regimes. We evaluate four deep research agents using sparse and dense multilingual retrievers, measuring answer accuracy, evidence recall, search behavior, calibration, citation fidelity, and oracle retrieval. Results reveal substantial degradation when evidence is translated. Even strong, dense retrievers lose evidence recall, and agents become less calibrated and cite evidence less reliably. Notably, accuracy remains lower even when all gold evidence is supplied directly. These findings suggest that cross-lingual deep research exposes both retrieval failures and an independent, agent-side difficulty in integrating language-mismatched evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces XBCP (Cross-lingual BrowseComp-Plus), a controlled benchmark extending BrowseComp-Plus by translating supporting documents while preserving the English query-answer space. It evaluates four deep research agents paired with sparse and dense multilingual retrievers across cross-lingual (single assigned language) and multilingual (evidence distributed across 12 languages) settings. The central claim is that cross-lingual evidence causes substantial degradation in answer accuracy, evidence recall, calibration, and citation fidelity, with accuracy remaining lower even under oracle retrieval; this is interpreted as exposing both retrieval failures and an independent agent-side difficulty integrating language-mismatched evidence.
Significance. If the results hold after addressing the translation-fidelity concern, the work is significant for highlighting a practical limitation in current agentic systems for multilingual web search and reasoning. The controlled separation of retrieval versus integration effects, combined with coverage of both high- and low-resource languages, offers a useful diagnostic benchmark for the field.
major comments (1)
- [Benchmark construction (XBCP)] Benchmark construction section: the claim that performance drops (including under oracle retrieval) can be attributed to language mismatch rather than content degradation rests on the unverified assumption that the translations preserve semantic content and factual accuracy without artifacts. No back-translation checks, human fidelity ratings, or error-rate reporting are described, which is load-bearing for the strongest claim of an 'independent, agent-side difficulty'.
minor comments (1)
- [Abstract] The abstract states directional results without any quantitative metrics, error bars, or statistical tests; these should be summarized in the abstract for immediate assessment of effect sizes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the importance of translation fidelity in supporting our central claims. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Benchmark construction section: the claim that performance drops (including under oracle retrieval) can be attributed to language mismatch rather than content degradation rests on the unverified assumption that the translations preserve semantic content and factual accuracy without artifacts. No back-translation checks, human fidelity ratings, or error-rate reporting are described, which is load-bearing for the strongest claim of an 'independent, agent-side difficulty'.
Authors: We agree that this is a substantive concern and that the absence of explicit fidelity verification weakens the strongest version of the agent-side difficulty claim. The translations were generated via a commercial MT system followed by light post-editing, but the manuscript indeed provides no quantitative checks. In the revision we will add a dedicated subsection to Benchmark Construction that (1) fully specifies the translation pipeline and languages, (2) reports back-translation BLEU and COMET scores on a 5% held-out sample per language, and (3) presents human semantic-preservation ratings (0-5 scale) on 50 randomly sampled documents stratified by resource level. These additions will allow readers to assess whether content degradation is a plausible confound. We view the requested changes as necessary and will implement them in full. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation
full rationale
The paper introduces XBCP via translation of an existing English benchmark and reports accuracy, recall, and calibration metrics across agents and retrievers. No equations, fitted parameters, predictions, or derivations appear. Claims rest on direct experimental comparisons rather than any self-definitional reduction or self-citation chain. The translation-fidelity precondition is a methodological assumption, not a circular step that reduces the result to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Machine translation of documents preserves the semantic content needed for evidence-based question answering.
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent , author=. 2025 , eprint=
2025
-
[2]
2025 , eprint=
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents , author=. 2025 , eprint=
2025
-
[3]
2024 , eprint=
Arctic-Embed 2.0: Multilingual Retrieval Without Compromise , author=. 2024 , eprint=
2024
-
[4]
Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and Zhang, Meishan and Li, Wenjie and Zhang, Min. mGTE : Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval. Proceedings of the 2024 Conference on Empiri...
-
[5]
Evaluating Large Language Models for Cross-Lingual Retrieval
Zuo, Longfei and Hong, Pingjun and Kraus, Oliver and Plank, Barbara and Litschko, Robert. Evaluating Large Language Models for Cross-Lingual Retrieval. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.612
-
[6]
2025 , eprint=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. 2025 , eprint=
2025
-
[7]
2025 , eprint=
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese , author=. 2025 , eprint=
2025
-
[8]
2026 , eprint=
Tongyi DeepResearch Technical Report , author=. 2026 , eprint=
2026
-
[9]
Tongyi DeepResearch: A New Era of Open-Source AI Researchers , year=
-
[10]
2026 , eprint=
Marco DeepResearch: Unlocking Efficient Deep Research Agents via Verification-Centric Design , author=. 2026 , eprint=
2026
-
[11]
2026 , eprint=
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling , author=. 2026 , eprint=
2026
-
[12]
2025 , eprint=
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning , author=. 2025 , eprint=
2025
-
[13]
2026 , eprint=
SealQA: Raising the Bar for Reasoning in Search-Augmented Language Models , author=. 2026 , eprint=
2026
-
[14]
2025 , eprint=
Bridging Language Gaps: Advances in Cross-Lingual Information Retrieval with Multilingual LLMs , author=. 2025 , eprint=
2025
-
[15]
A survey on multilingual large language models: corpora, alignment, and bias , volume=
Xu, Yuemei and Hu, Ling and Zhao, Jiayi and Qiu, Zihan and Xu, Kexin and Ye, Yuqi and Gu, Hanwen , year=. A survey on multilingual large language models: corpora, alignment, and bias , volume=. Frontiers of Computer Science , publisher=. doi:10.1007/s11704-024-40579-4 , number=
-
[16]
Xu and Luyu Gao and Zhiqing Sun and Qian Liu and Jane Dwivedi
Jiang, Zhengbao and Xu, Frank and Gao, Luyu and Sun, Zhiqing and Liu, Qian and Dwivedi-Yu, Jane and Yang, Yiming and Callan, Jamie and Neubig, Graham. Active Retrieval Augmented Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.495
-
[17]
Multilingual vs Crosslingual Retrieval of Fact-Checked Claims: A Tale of Two Approaches
Ramponi, Alan and Rovera, Marco and Moro, Robert and Tonelli, Sara. Multilingual vs Crosslingual Retrieval of Fact-Checked Claims: A Tale of Two Approaches. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1480
-
[18]
2024 , eprint=
Multilingual E5 Text Embeddings: A Technical Report , author=. 2024 , eprint=
2024
-
[19]
arXiv preprint arXiv:2502.13595 , year=
MMTEB: Massive Multilingual Text Embedding Benchmark , author=. arXiv preprint arXiv:2502.13595 , year=
-
[20]
MIRACL : A Multilingual Retrieval Dataset Covering 18 Diverse Languages
Zhang, Xinyu and Thakur, Nandan and Ogundepo, Odunayo and Kamalloo, Ehsan and Alfonso-Hermelo, David and Li, Xiaoguang and Liu, Qun and Rezagholizadeh, Mehdi and Lin, Jimmy. MIRACL : A Multilingual Retrieval Dataset Covering 18 Diverse Languages. Transactions of the Association for Computational Linguistics. 2023. doi:10.1162/tacl_a_00595
-
[21]
In: Findings of the Association for Computational Lin- guistics 2024
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[22]
Robertson, Stephen and Zaragoza, Hugo , title =. Found. Trends Inf. Retr. , month = apr, pages =. 2009 , issue_date =. doi:10.1561/1500000019 , abstract =
-
[23]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[24]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[25]
Liu, Wei and Trenous, Sony and Ribeiro, Leonardo F. R. and Byrne, Bill and Hieber, Felix. XRAG : Cross-lingual Retrieval-Augmented Generation. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.849
-
[26]
Multilingual Retrieval-Augmented Generation for Knowledge-Intensive Question Answering Task
Ranaldi, Leonardo and Haddow, Barry and Birch, Alexandra. Multilingual Retrieval-Augmented Generation for Knowledge-Intensive Question Answering Task. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.35
-
[27]
2026 , eprint=
CroSearch-R1: Better Leveraging Cross-lingual Knowledge for Retrieval-Augmented Generation , author=. 2026 , eprint=
2026
-
[28]
2026 , eprint=
Code-Switching Information Retrieval: Benchmarks, Analysis, and the Limits of Current Retrievers , author=. 2026 , eprint=
2026
-
[29]
2026 , eprint=
AgentIR: Reasoning-Aware Retrieval for Deep Research Agents , author=. 2026 , eprint=
2026
-
[30]
2026 , month = mar, day =
2026
-
[31]
2025 , eprint=
MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[33]
2025 , month = apr, day =
Introducing GPT-4.1 in the API , author =. 2025 , month = apr, day =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.