Is RISC-V Ready for Massively Parallel Astrophysical Codes?
Pith reviewed 2026-06-27 03:33 UTC · model grok-4.3
The pith
RISC-V runs three major astrophysical codes correctly but three to six times slower than x86.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
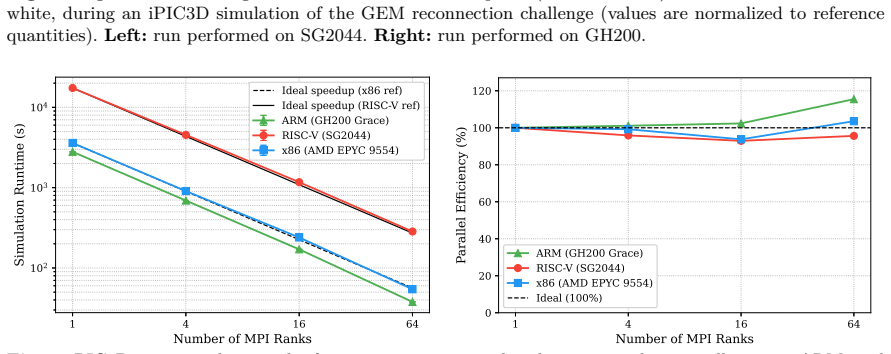
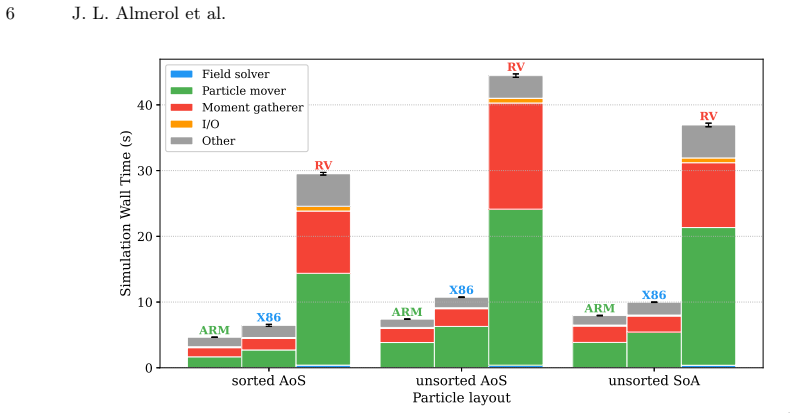
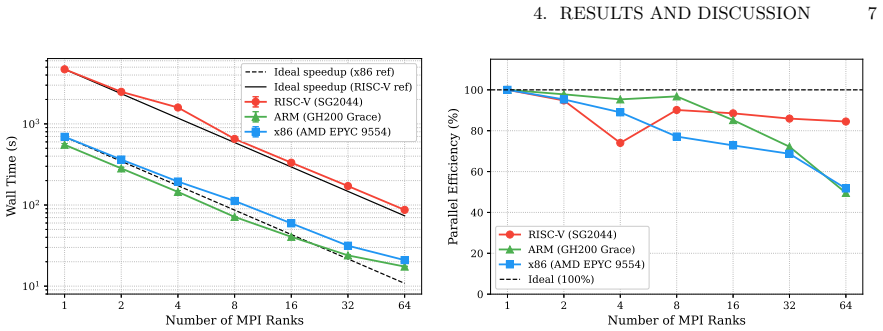
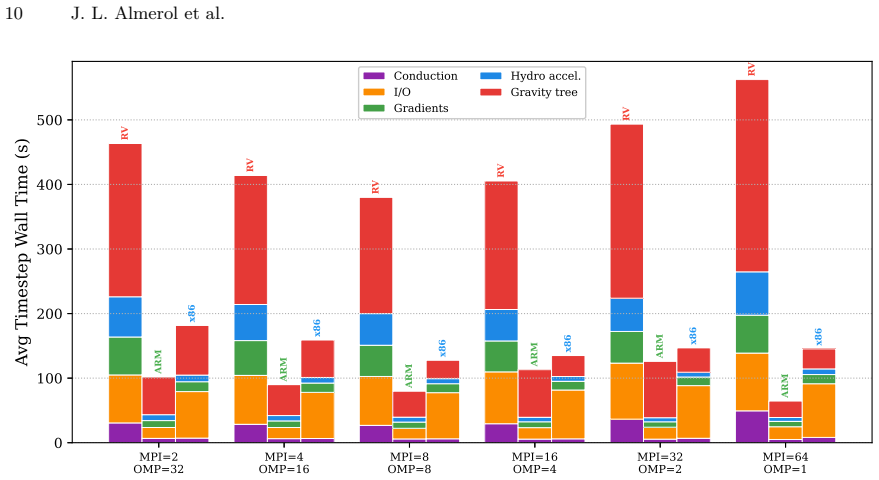
The central claim is that the three codes (iPIC3D for memory-bound work, PLUTO for compute-bound work, and OpenGadget3 for hybrid work) execute with full numerical correctness on RISC-V, yet exhibit slowdowns of roughly 3-6 times versus x86 and 5-9 times versus ARM. The performance difference is driven primarily by limited memory bandwidth that saturates early, contention in shared caches, 128-bit vector units, lower clock frequency, and less mature auto-vectorization in the GNU compiler. Memory-bound kernels suffer most at high thread counts, while hybrid MPI+OpenMP runs reach their best results at intermediate thread counts that balance memory pressure against communication cost. The autho
What carries the argument
Direct performance comparison of memory-bound, compute-bound, and hybrid astrophysical codes across RISC-V, x86, and ARM platforms, with measurements isolating bandwidth saturation, cache contention, vector-unit width, clock frequency, and compiler auto-vectorization effects.
If this is right
- Memory-bound kernels reach bandwidth limits earliest and therefore show the largest scalability drop at high thread counts.
- Hybrid MPI+OpenMP configurations achieve peak performance only at intermediate thread counts where memory contention and communication overhead are balanced.
- Compiler improvements focused on auto-vectorization would reduce the performance gap more than hardware changes alone.
- No source-code modifications are required for numerical portability across the three architectures.
Where Pith is reading between the lines
- Other memory-intensive scientific domains such as computational fluid dynamics or climate modeling would likely encounter similar bandwidth-driven slowdowns on current RISC-V hardware.
- RISC-V designs that prioritize higher memory bandwidth and wider vector units could close most of the gap without requiring application rewrites.
- Compiler teams working on RISC-V support could use these three codes as regression tests to measure progress in vectorization quality.
Load-bearing premise
The three tested codes and the specific RISC-V, x86, and ARM configurations used are representative of the memory and compute demands typical in massively parallel astrophysical applications.
What would settle it
A repeat of the same three codes on a later RISC-V system that doubles sustained memory bandwidth, widens vector units to 256 bits, raises clock frequency, and uses a compiler with mature auto-vectorization, yielding performance within 1.5 times of the x86 baseline, would falsify the claim that the observed gaps are structural.
Figures
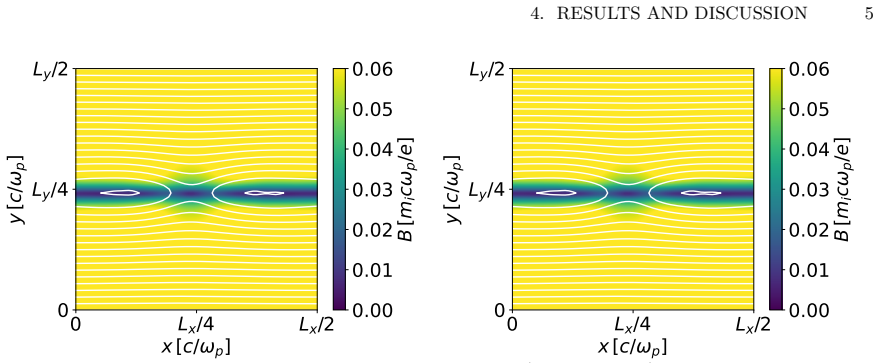
read the original abstract
We present a performance and portability evaluation of three well-established astrophysical production codes, namely iPIC3D, PLUTO, and OpenGadget3, on a Sophgo SG2044 RISC-V processor (part of the Monte Cimone cluster), with comparisons to AMD EPYC 9554 (x86) and NVIDIA GH200 Grace (ARM) systems. These applications represent memory-bound, compute-bound, and hybrid workloads, respectively. Numerical correctness is verified across all platforms, confirming portability. RISC-V shows consistently lower performance, with slowdowns of about $3-6\times$ relative to x86 and $5-9\times$ relative to ARM. The gap is mainly due to limited memory bandwidth, shared cache constraints, narrower 128-bit vector units, and lower clock frequency, but also less-mature auto-vectorization capability of the GNU compiler suite. Memory-bound kernels are the most affected, where early bandwidth saturation and L2 cache contention reduce scalability at higher thread counts. Hybrid MPI+OpenMP configurations reveal a trade-off between memory contention and communication overhead, with intermediate configurations achieving the best performance. These results suggest that RISC-V is capable of supporting scientific workloads; however, additional improvements in both hardware and compiler technology, particularly in auto-vectorization, are required to achieve competitive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates portability and performance of three astrophysical production codes (iPIC3D, PLUTO, OpenGadget3) representing memory-bound, compute-bound, and hybrid workloads on a Sophgo SG2044 RISC-V processor, with direct comparisons to AMD EPYC 9554 (x86) and NVIDIA GH200 Grace (ARM) systems. It reports verified numerical correctness across platforms and consistent slowdowns on RISC-V of 3-6× versus x86 and 5-9× versus ARM, attributes the gaps primarily to limited memory bandwidth, shared L2 cache, 128-bit vectors, clock frequency, and GNU compiler auto-vectorization maturity, and notes that memory-bound kernels suffer most from early bandwidth saturation and cache contention while hybrid MPI+OpenMP shows configuration trade-offs.
Significance. If the reported timings and causal attributions are substantiated, the work supplies concrete empirical benchmarks for RISC-V in production scientific HPC, quantifying scalability limits in representative astrophysical kernels and identifying concrete hardware/compiler targets (vectorization, bandwidth) whose improvement would directly benefit memory-bound and hybrid codes.
major comments (2)
- [Abstract] Abstract: the claim that observed slowdowns are 'mainly due to' limited memory bandwidth, shared cache constraints, 128-bit vector units, clock frequency, and GNU auto-vectorization maturity is stated without citation to isolating measurements (performance counters, achieved bandwidth, vectorization reports, or controlled microbenchmarks) from the three codes; the attribution therefore rests on correlation with published hardware specifications rather than run-time data.
- [Results] Results section (implied by abstract description of thread scaling and MPI+OpenMP trade-offs): the absence of error bars, repeated-run statistics, or full profiling data (e.g., memory bandwidth utilization, cache miss rates) prevents verification that the listed factors dominate over other variables such as memory-controller implementation or library versions.
minor comments (2)
- [Methods] Methods: the manuscript should supply the exact compiler flags, library versions, and thread/MPI binding policies used on each platform to allow reproduction of the reported timings.
- [Figures] Figures: scaling plots would benefit from explicit indication of the number of runs and any observed variability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the empirical basis for our performance attributions and on improving statistical rigor. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that observed slowdowns are 'mainly due to' limited memory bandwidth, shared cache constraints, 128-bit vector units, clock frequency, and GNU auto-vectorization maturity is stated without citation to isolating measurements (performance counters, achieved bandwidth, vectorization reports, or controlled microbenchmarks) from the three codes; the attribution therefore rests on correlation with published hardware specifications rather than run-time data.
Authors: We agree that the abstract's phrasing attributes the slowdowns to specific factors without direct isolating measurements such as performance counters or vectorization reports from the application runs. Our conclusions draw from the observed differential scaling (memory-bound kernels saturate earliest) together with the documented hardware characteristics of the SG2044 (shared L2, 128-bit vectors, bandwidth limits) and the known state of GNU auto-vectorization. We will revise the abstract to qualify the attribution as 'primarily inferred from workload-specific scaling behavior and published hardware specifications' and will add a short discussion of this inference basis in the results section. If the Monte Cimone cluster provides accessible counters, we will include a limited set of bandwidth and cache-miss figures in a revision; otherwise the language will remain qualified. revision: partial
-
Referee: [Results] Results section (implied by abstract description of thread scaling and MPI+OpenMP trade-offs): the absence of error bars, repeated-run statistics, or full profiling data (e.g., memory bandwidth utilization, cache miss rates) prevents verification that the listed factors dominate over other variables such as memory-controller implementation or library versions.
Authors: We acknowledge that the presented results lack error bars, repeated-run statistics, and detailed profiling data, which limits independent verification that bandwidth and cache effects dominate other possible variables. The reported timings reflect single representative executions, although we observed stable behavior across preliminary runs. We will add error bars derived from at least three repeated executions per configuration, include a brief statement on run-to-run variability, and incorporate any available high-level profiling output (e.g., reported memory bandwidth from the codes) to support the causal discussion. These additions will be placed in the results section. revision: yes
Circularity Check
No circularity: purely empirical benchmarking with no derivations or fitted predictions
full rationale
The paper consists of direct runtime measurements of three astrophysical codes on RISC-V, x86, and ARM hardware, with numerical correctness checks and performance comparisons. No equations, parameters fitted to subsets of data, predictions, or first-principles derivations appear in the provided text. Attributions to hardware factors (bandwidth, cache, vector width, frequency, compiler) are interpretive statements correlated with known specs and observed scaling behavior, but they do not reduce any claimed result to its own inputs by construction. Self-citations are absent from the abstract and central claims. This is a standard empirical evaluation whose central results stand independently of any internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Almerol, J.L., et al.: Accelerating gravitational N-body simulations using the RISC-V-based Tenstorrent Wormhole. In: Proceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. pp. 1729–1735. Association for Computing Machinery, New York, NY, USA (2025). https://doi.org/10.1145/373...
-
[2]
Almerol, J.L., et al.: Assessing performance and porting strategies for gravitational n-body sim- ulations on the risc-v-based tenstorrent wormhole. Astronomy and Computing p. 101121 (2026). https://doi.org/https://doi.org/10.1016/j.ascom.2026.101121
-
[3]
Nature 324(6096), 446–449 (1986)
Barnes, J., Hut, P.: A hierarchical o(n log n) force-calculation algorithm. Nature 324(6096), 446–449 (1986). https://doi.org/10.1038/324446a0
-
[4]
In: 2022 IEEE 35th International System-on-Chip Conference (SOCC)
Bartolini, A., et al.: Monte cimone: paving the road for the first generation of risc-v high-performance computers. In: 2022 IEEE 35th International System-on-Chip Conference (SOCC). pp. 1–6. IEEE (2022)
2022
-
[5]
Journal of Computational Physics 499, 112701 (2024)
Berta, V., et al.: A fourth-order accurate finite volume method for ideal classical and special relativis- tic mhd based on pointwise reconstructions. Journal of Computational Physics 499, 112701 (2024). https://doi.org/10.1016/j.jcp.2023.112701
-
[6]
Journal of Geophysical Research: Space Physics 106(A3), 3715–3719 (2001)
Birn, J., et al.: Geospace environmental modeling (gem) magnetic re- connection challenge. Journal of Geophysical Research: Space Physics 106(A3), 3715–3719 (2001). https://doi.org/https://doi.org/10.1029/1999JA900449, https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/1999JA900449
-
[7]
Boella, E., et al.: Accelerating the particle-in-cell code ecsim with openacc (2026), https://arxiv.org/abs/2603.16624
arXiv 2026
-
[8]
arXiv preprint arXiv:2307.14774 (2023)
Bramas, B.: Spc5: An efficient spmv framework vectorized using arm sve and x86 avx-512. arXiv preprint arXiv:2307.14774 (2023)
arXiv 2023
-
[10]
In: ISC High Performance 2024 Workshops
Brown, N., Jamieson, M.: Performance characterisation of the 64-core sg2042 risc-v cpu for hpc. In: ISC High Performance 2024 Workshops. Lecture Notes in Computer Science, vol. 15058. Springer (2025)
2024
-
[11]
In: Proceedings of the SC’23 Workshops (2023)
Brown, N., et al.: Initial rajaperf evaluation on sophon sg2042. In: Proceedings of the SC’23 Workshops (2023)
2023
-
[12]
Brown, N.: Is risc-v ready for high performance computing? an evaluation of the sophon sg2044 (2025), https://arxiv.org/abs/2508.13840
arXiv 2025
-
[13]
arXiv preprint arXiv:2309.06530 (2023)
Diehl, P., Daiß, G., et al.: Evaluating hpx and kokkos on risc-v using an astrophysics application (octo- tiger). arXiv preprint arXiv:2309.06530 (2023)
arXiv 2023
-
[14]
arXiv preprint arXiv:2407.00026 (2024)
Diehl, P., et al.: Preparing for hpc on risc-v: Examining vectorization and distributed perfor- mance of an astrophysics application with hpx and kokkos. arXiv preprint arXiv:2407.00026 (2024). https://doi.org/10.48550/arXiv.2407.00026
-
[15]
ACM Transactions on Quantum Computing 6(3), 1–46 (2025)
Elsharkawy, A., et al.: Integration of quantum accelerators with high performance computinga review of quantum programming tools. ACM Transactions on Quantum Computing 6(3), 1–46 (2025)
2025
-
[16]
Monthly Notices of the Royal Astronomical Society 526(1), 616–644 (2023)
Groth, F., et al.: The cosmological simulation code opengadget3: Implementation of mesh- less finite mass. Monthly Notices of the Royal Astronomical Society 526(1), 616–644 (2023). https://doi.org/10.1093/mnras/stad2717
-
[17]
Hennessy, J.L., Patterson, D.A.: A new golden age for computer architecture. Commun. ACM 62(2), 4860 (Jan 2019). https://doi.org/10.1145/3282307, https://doi.org/10.1145/3282307
-
[18]
Mathematics and Computers in Simu- lation 80(7), 1509–1519 (2010)
Markidis, S., et al.: Multi-scale simulations of plasma with ipic3d. Mathematics and Computers in Simu- lation 80(7), 1509–1519 (2010). https://doi.org/10.1016/j.matcom.2009.08.038
-
[19]
The Astrophysical Journal Supplement Series 170(1), 228–242 (2007)
Mignone, A., et al.: Pluto: A numerical code for computational astrophysics. The Astrophysical Journal Supplement Series 170(1), 228–242 (2007). https://doi.org/10.1086/513421 14 J. L. Almerol et al
-
[20]
Journal of Computational Physics 229, 5896–5920 (2010)
Mignone, A., et al.: High-order conservative finite difference glm-mhd schemes for cell-centered mhd. Journal of Computational Physics 229, 5896–5920 (2010). https://doi.org/10.1016/j.jcp.2010.04.013
-
[21]
Ristov, S., et al.: Superlinear speedup in hpc systems: Why and when? In: 2016 federated conference on computer science and information systems (fedcsis). pp. 889–898. IEEE (2016)
2016
-
[22]
In: 2025 IEEE In- ternational Conference on Quantum Computing and Engineering (QCE)
Rocco, R., et al.: Dynamic solutions for hybrid quantum-hpc resource allocation. In: 2025 IEEE In- ternational Conference on Quantum Computing and Engineering (QCE). vol. 02, pp. 34–40 (2025). https://doi.org/10.1109/QCE65121.2025.10289
-
[23]
Journal of Parallel and Distributed Computing 205, 105156 (2025)
Rocco, R., et al.: To repair or not to repair: Assessing fault resilience in mpi stencil applications. Journal of Parallel and Distributed Computing 205, 105156 (2025)
2025
-
[24]
Astronomy and Computing 55, 101076 (2026)
Rossazza, M., et al.: The pluto code on gpus: A first look at eulerian mhd methods. Astronomy and Computing 55, 101076 (2026). https://doi.org/10.1016/j.parco.2016.01.001
-
[25]
Shukla, N., et al.: Eurohpc space coe: Redesigning scalable parallel astrophysical codes for ex- ascale (invited paper). In: Proceedings of the 22nd ACM International Conference on Comput- ing Frontiers Workshops and Special Sessions. pp. 177–184. CF ’25 Companion, ACM (Jul 2025). https://doi.org/10.1145/3706594.3728892
-
[26]
Shukla, N., et al.: Towards exascale computing for astrophysical simulation leveraging the leonardo eurohpc system. Procedia Computer Science pp. 112–123 (2025). https://doi.org/10.1016/j.procs.2025.08.238267
-
[27]
Shukla, N., et al.: Exascale computing to accelerate discoveries in astrophysics and space plasma physics. Nature Astronomy (2026). https://doi.org/10.1038/s41550-026-02807-8
-
[28]
ACM Computing Surveys 57(11), 1–39 (2025)
Silvano, C., et al.: A survey on deep learning hardware accelerators for heterogeneous hpc platforms. ACM Computing Surveys 57(11), 1–39 (2025)
2025
-
[29]
In: SC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis
Simsek, O.S., et al.: Increasing energy efficiency of astrophysics simulations through gpu frequency scaling. In: SC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. pp. 1826–1834. IEEE (2024)
2024
-
[30]
Sishtla, C., et al.: Multi-GPU Acceleration of the iPIC3D Implicit Particle-in-Cell Code, p. 612618. Springer International Publishing (2019)
2019
-
[31]
Astronomy and Computing 55, 101088 (2026)
Suriano, A., et al.: The pluto code on gpus: Offloading lagrangian particle methods. Astronomy and Computing 55, 101088 (2026). https://doi.org/https://doi.org/10.1016/j.ascom.2026.101088
-
[32]
In: Neuwirth, S., Paul, A.K., Weinzierl, T., Carson, E.C
Venieri, E., et al.: Monte cimone v2: Hpc risc-v cluster evaluation and optimization. In: Neuwirth, S., Paul, A.K., Weinzierl, T., Carson, E.C. (eds.) High Performance Computing. pp. 576–585. Springer Nature Switzerland, Cham (2026)
2026
-
[33]
Venieri, E., Manoni, S., et al.: Monte cimone v2: Hpc risc-v cluster evaluation and optimization. In: Neuwirth, S., et al. (eds.) High Performance Computing, Lecture Notes in Computer Science, vol. 16091, pp. 576–585. Springer, Cham (2026). https://doi.org/10.1007/978-3-032-07612-0_44
-
[34]
Viviani, P., et al.: Assessing the elephant in the room in scheduling for current hybrid hpc-qc clusters. In: 2025 55th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W). pp. 184–187 (2025). https://doi.org/10.1109/DSN-W65791.2025.00059
-
[35]
Williams, J.J., et al.: Characterizing the performance of the implicit massively parallel particle-in-cell ipic3d code. In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’23) (2023). https://doi.org/10.48550/arXiv.2408.01983, arXiv:2408.01983
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.