Self-Generated Error Training for Token Editing in Diffusion Language Models
Pith reviewed 2026-06-27 03:22 UTC · model grok-4.3
The pith
Training token editors on a model's own draft errors improves accuracy and reduces edit intensity over random corruptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
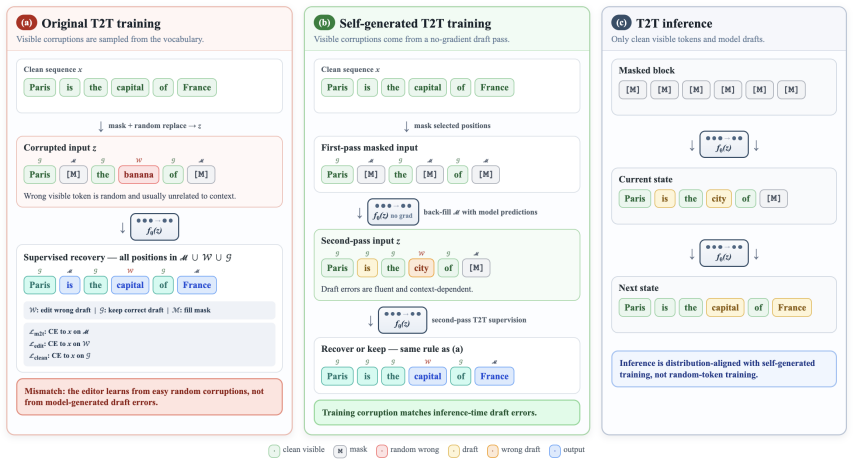
Performing a no-gradient draft pass to fill masked positions with the model's own predicted tokens, then supervising the editor to recover under those self-generated corruptions, aligns the training distribution with inference conditions and yields higher accuracy together with lower T2T edit intensity under the official Q-Mode procedure with fixed inference parameters.
What carries the argument
The self-generated T2T procedure, which creates training corruptions via a single no-gradient draft pass instead of random vocabulary replacement.
If this is right
- Accuracy rises on multiple benchmarks while T2T edit intensity falls.
- Specific failure modes such as final-digit transcription errors after correct reasoning are reduced.
- Excessive self-correction before short factual answers occurs less often.
- The gains appear with unchanged inference parameters after only a short continued-pretraining pass.
Where Pith is reading between the lines
- The same draft-pass corruption idea might apply to other iterative generation procedures that suffer training-inference distribution shift.
- Lower edit intensity could translate into faster overall decoding if edit steps carry non-trivial cost.
- Collecting multiple draft passes instead of one might further refine the error distribution used for supervision.
Load-bearing premise
Corruptions produced by one no-gradient draft pass are representative enough of the errors the editor will see at inference that supervising recovery on them transfers without creating new failure modes.
What would settle it
Applying the self-generated T2T update and observing no accuracy gain or an increase in edit intensity on the same benchmarks under the official evaluation procedure would falsify the central claim.
Figures
read the original abstract
Token-to-token (T2T) editing lets LLaDA2.1 revise committed tokens during block-diffusion decoding. The released recipe trains this editor on random vocabulary corruptions, but at inference the editor sees the model's own fluent, high-confidence draft errors instead. We study this training-inference mismatch and propose self-generated T2T, which performs a no-gradient draft pass, fills masked positions with predicted tokens, and supervises recovery in a second pass under these self-generated corruptions. We implement the update as a short LoRA continued-pretraining pass on LLaDA2.1-mini and evaluate on several benchmarks under the official Q-Mode T2T procedure with unchanged inference parameters. The method generally improves accuracy while reducing T2T edit intensity, mitigating failure modes such as final-digit transcription errors after otherwise correct reasoning and excessive self-correction before short factual answers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes self-generated T2T training to address the mismatch between random-vocabulary corruptions used in prior T2T editor training and the fluent, high-confidence draft errors encountered at inference in block-diffusion decoding. It generates training corruptions via a single no-gradient draft pass on LLaDA2.1-mini, fills masked positions with the model's predictions, and performs LoRA continued pretraining to supervise recovery from these self-generated errors. The update is evaluated on several benchmarks under the official Q-Mode T2T procedure with unchanged inference parameters, claiming general accuracy gains, reduced T2T edit intensity, and mitigation of failure modes such as final-digit transcription errors.
Significance. If the empirical improvements hold under the reported conditions, the method offers a lightweight, inference-parameter-preserving way to better align T2T editor training with the error distribution seen at test time. Credit is due for the efficient LoRA implementation and the explicit focus on a concrete training-inference distribution shift rather than generic data augmentation.
major comments (1)
- [Method and Experiments sections] The central claim that supervised recovery on base-model self-generated corruptions transfers to inference under the LoRA-adapted weights requires that the token-level error distribution (positions, confidence patterns, error types) remains stable after adaptation. No verification or ablation of this stability is described, which directly affects whether the training-inference alignment targeted by the method is achieved at inference time.
minor comments (2)
- [Abstract] The abstract states that the method 'generally improves accuracy' on 'several benchmarks' but does not name the benchmarks or report quantitative deltas, error bars, or ablation details in the provided summary; these should appear in the opening paragraphs or a results table for immediate assessment.
- [Experiments] Dataset descriptions, exact benchmark names, and the number of training steps or LoRA rank are referenced only at a high level; adding a short table or paragraph with these details would improve reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive feedback on the stability of the error distribution under LoRA adaptation. We address the major comment below.
read point-by-point responses
-
Referee: [Method and Experiments sections] The central claim that supervised recovery on base-model self-generated corruptions transfers to inference under the LoRA-adapted weights requires that the token-level error distribution (positions, confidence patterns, error types) remains stable after adaptation. No verification or ablation of this stability is described, which directly affects whether the training-inference alignment targeted by the method is achieved at inference time.
Authors: We agree this is a substantive point: the method relies on the assumption that base-model self-generated corruptions remain representative after the LoRA update. The manuscript does not contain any direct comparison of error statistics (positions, confidence, or types) between the base and adapted models. While the small LoRA rank and short continued-pretraining schedule make large distributional shifts unlikely, and the reported benchmark gains are consistent with successful transfer, this remains an unverified assumption. In revision we will add a targeted analysis (new subsection in Experiments) that samples error distributions on a held-out validation set before and after adaptation and reports quantitative differences. revision: yes
Circularity Check
No circularity; empirical training procedure evaluated on external benchmarks
full rationale
The paper proposes a training recipe (no-gradient draft pass to generate corruptions, followed by supervised recovery under LoRA) and reports accuracy gains on benchmarks under fixed inference settings. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The method is a procedural intervention whose validity rests on experimental transfer rather than any definitional reduction or imported uniqueness result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block discrete denoising diffusion language models. InInternational Conference on Learning Representations, 2025
2025
-
[2]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. InAdvances in Neural Information Processing Systems, 2021
2021
-
[3]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InAdvances in Neural Information Processing Systems, 2015
2015
-
[4]
Llada2.1: Speeding up text diffusion via token editing.arXiv preprint arXiv:2602.08676, 2026
Tiwei Bie, Maosong Cao, Xiang Cao, Bingsen Chen, Fuyuan Chen, Kun Chen, Lun Du, Daozhuo Feng, Haibo Feng, Mingliang Gong, et al. Llada2.1: Speeding up text diffusion via token editing.arXiv preprint arXiv:2602.08676, 2026
arXiv 2026
-
[5]
PIQA: Reasoning about physical intuition in natural language.arXiv preprint arXiv:1911.11641, 2020
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical intuition in natural language.arXiv preprint arXiv:1911.11641, 2020
Pith/arXiv arXiv 1911
-
[6]
Analog bits: Generating discrete data using diffusion models with self-conditioning
Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning. InInternational Conference on Learning Representations, 2023
2023
-
[7]
Scaling diffusion language models via adaptation from autoregressive models.International Conference on Learning Representations, 2025
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, Hao Peng, and Lingpeng Kong. Scaling diffusion language models via adaptation from autoregressive models.International Conference on Learning Representations, 2025
2025
-
[8]
Don’t settle too early: Self-reflective remasking for diffusion language models
Zemin Huang, Yuhang Wang, Zhiyang Chen, and Guo-Jun Qi. Don’t settle too early: Self-reflective remasking for diffusion language models. InInternational Conference on Learning Representations, 2026
2026
-
[9]
Mercury: Ultra-fast language models based on diffusion.arXiv preprint arXiv:2506.17298, 2025
Inception Labs, Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, Stefano Ermon, Aditya Grover, and V olodymyr Kuleshov. Mercury: Ultra-fast language models based on diffusion.arXiv preprint arXiv:2506.17298, 2025
Pith/arXiv arXiv 2025
-
[10]
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension.arXiv preprint arXiv:1705.03551, 2017
Pith/arXiv arXiv 2017
-
[11]
Wonjun Kang, Kevin Galim, Seunghyuk Oh, Minjae Lee, Yuchen Zeng, Shuibai Zhang, Coleman Hooper, Yuezhou Hu, Hyung Il Koo, Nam Ik Cho, and Kangwook Lee. ParallelBench: Understanding the trade-offs of parallel decoding in diffusion LLMs.arXiv preprint arXiv:2510.04767, 2025
Pith/arXiv arXiv 2025
-
[12]
Liming Liu, Binxuan Huang, Zixuan Zhang, Xin Liu, Bing Yin, and Tuo Zhao. Backplay: Head-only look-back self-correction for diffusion language models.arXiv preprint arXiv:2601.06428, 2026
Pith/arXiv arXiv 2026
-
[13]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. InInternational Conference on Machine Learning, 2024
2024
-
[14]
Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025. 8
Pith/arXiv arXiv 2025
-
[15]
Your absorbing discrete diffusion secretly models the conditional distributions of clean data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. InInternational Conference on Learning Representations, 2025
2025
-
[16]
Gordon, and J
St´ephane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics, 2011
2011
-
[17]
Chiu, Alexander M
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander M. Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. InAdvances in Neural Information Processing Systems, 2024
2024
-
[18]
Yair Schiff, Omer Belhasin, Roy Uziel, Guanghan Wang, Marianne Arriola, Gilad Turok, Michael Elad, and V olodymyr Kuleshov. Learn from your mistakes: Self-correcting masked diffusion models.arXiv preprint arXiv:2602.11590, 2026
Pith/arXiv arXiv 2026
-
[19]
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis K. Titsias. Simplified and generalized masked diffusion for discrete data. InAdvances in Neural Information Processing Systems, 2024
2024
-
[20]
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling.arXiv preprint arXiv:2503.00307, 2025
arXiv 2025
-
[21]
Tianwen Wei, Jian Luan, Wei Liu, Shuang Dong, and Bin Wang. CMATH: Can your language model pass chinese elementary school math test?arXiv preprint arXiv:2306.16636, 2023
arXiv 2023
-
[22]
Lin Yao. Remask, don’t replace: Token-to-mask refinement in diffusion large language models.arXiv preprint arXiv:2604.18738, 2026
Pith/arXiv arXiv 2026
-
[23]
Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025. 9
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.