Beyond Parallel Sampling: Diverse Query Initialization for Agentic Search
Pith reviewed 2026-06-27 03:36 UTC · model grok-4.3
The pith
Selecting diverse first queries from one model call reduces retrieval overlap and improves multi-hop QA performance by five to seven points at matched compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
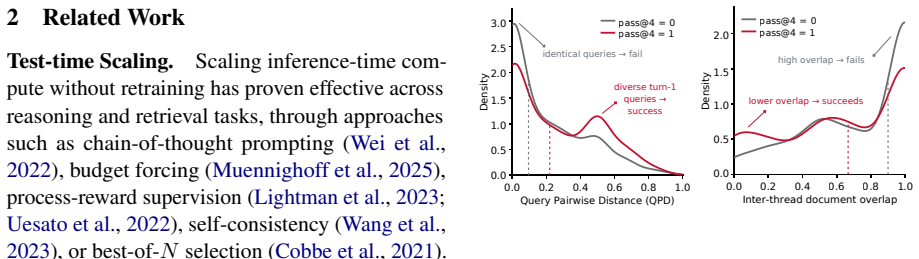
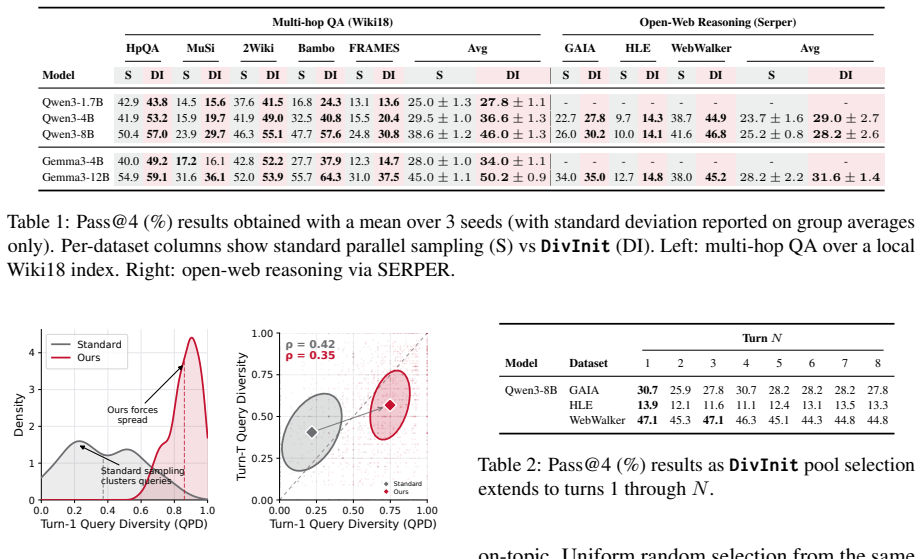
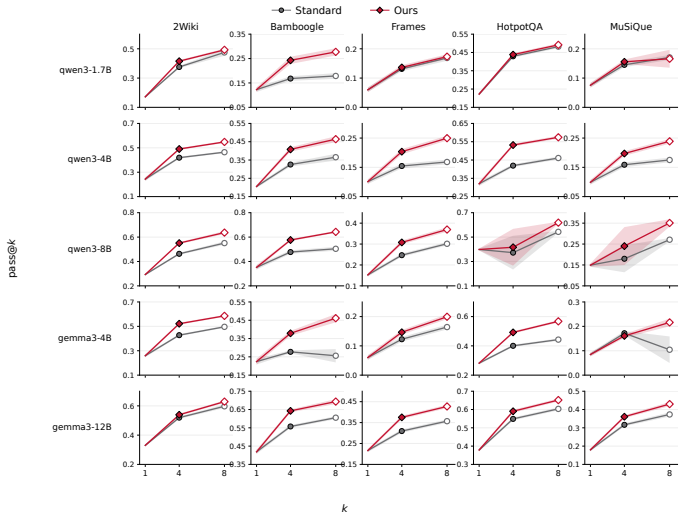
DivInit draws n candidates from a single model call at the first turn, selects k diverse seeds, and runs them as parallel trajectories, leading to less overlapping retrieval and higher final answer quality compared to sampling k independent queries.
What carries the argument
DivInit, the procedure of generating n first-turn query candidates in one forward pass then selecting k diverse seeds to initialize parallel agent trajectories.
If this is right
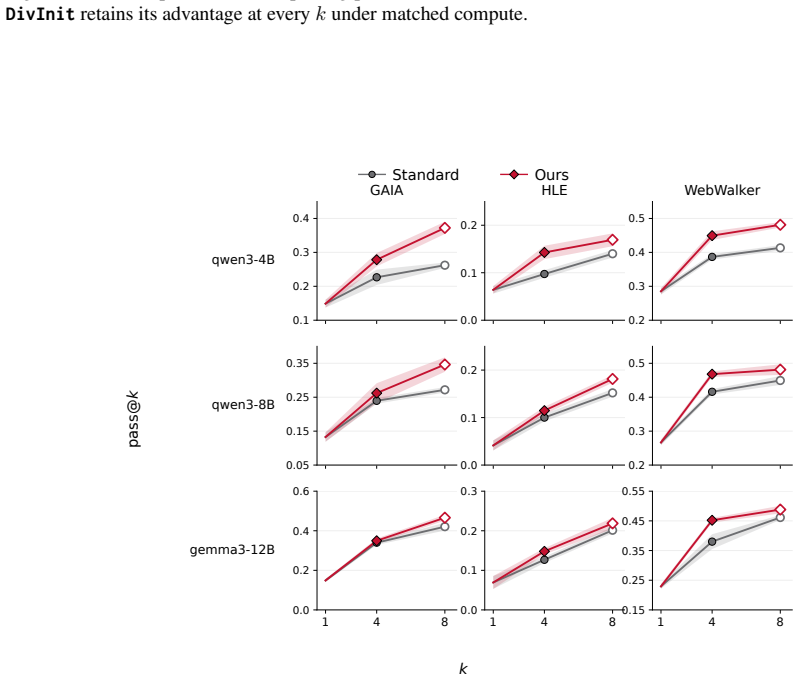
- At matched compute, parallel sampling yields higher accuracy on multi-hop QA across five models and eight benchmarks.
- Diversity at the first turn matters more for final quality than simply increasing the count of independent rollouts.
- The intervention requires no training and works on open-weight models without task-specific changes.
- Later turns in each trajectory receive more distinct evidence, reducing shared conditioning.
Where Pith is reading between the lines
- The same initialization trick could be tested on other breadth-scaling methods such as tree search or ensemble reasoning.
- Redundancy problems may appear in non-search agent loops where early outputs shape later context.
- Replacing the current diversity selection rule with a learned metric might further increase the gains.
- Pairing this breadth fix with depth scaling could produce larger combined improvements on harder tasks.
Load-bearing premise
That redundancy among first-turn queries is the primary driver of diminishing returns and that diverse seeds from one call will produce sufficiently non-overlapping retrieval sets.
What would settle it
A controlled run in which first-turn queries are forced to be diverse by an independent method yet final answer quality shows no gain over standard parallel sampling.
Figures


read the original abstract
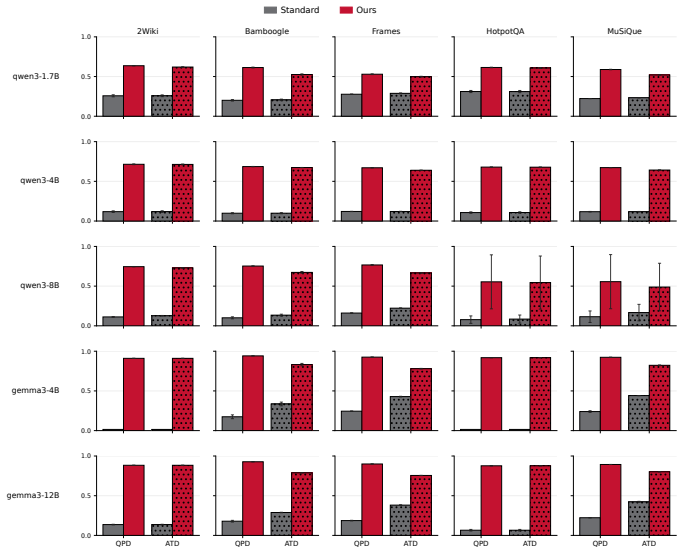
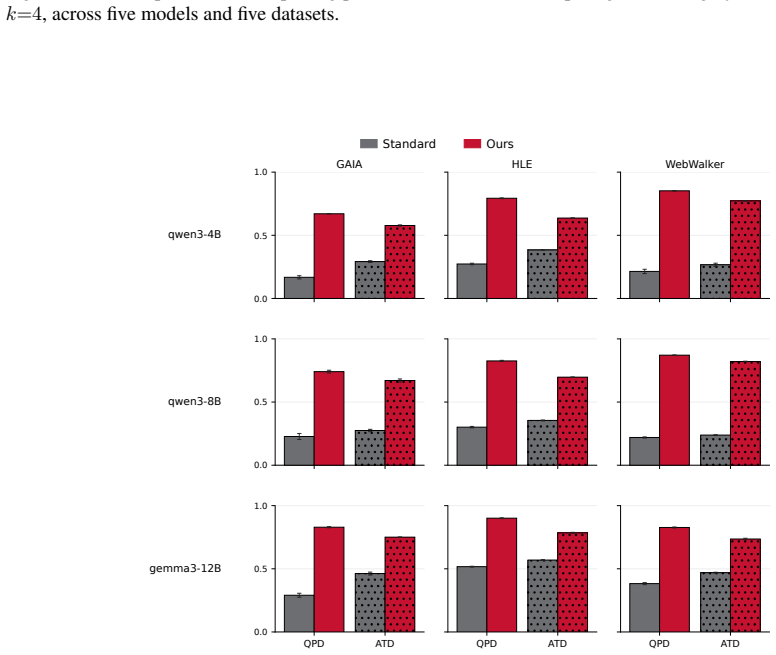
Test-time scaling for agentic search typically increases depth (i.e., more turns and tokens per trajectory) or breadth (i.e., more parallel rollouts). Here we focus on breadth scaling, showing that standard parallel sampling yields diminishing returns, tracing this to query redundancy at the first turn. When models issue similar first queries across rollouts, the threads retrieve overlapping evidence, and subsequent turns are conditioned on this shared retrieval. We address this limitation with DivInit, a training-free intervention at the first turn. Rather than sampling k independent first queries, DivInit draws n candidates from a single call, picks k < n diverse seeds, and runs them as parallel trajectories. Across five open-weight models and eight benchmarks, DivInit consistently improves over standard parallel sampling, with average gains of five to seven points on multi-hop QA at matched compute. Code available at https://github.com/cxcscmu/diverse-query-initialization
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that standard parallel sampling in agentic search exhibits diminishing returns due to redundancy among first-turn queries, which produces overlapping retrieval sets and shared conditioning for subsequent turns. It introduces DivInit, a training-free intervention that generates n candidate first-turn queries in a single model call, selects k < n diverse seeds, and initializes parallel trajectories with them. Across five open-weight models and eight benchmarks, DivInit yields consistent gains of 5-7 points on multi-hop QA at matched compute.
Significance. If the reported gains hold under rigorous controls and the mechanism is confirmed, DivInit provides a simple, compute-matched improvement to breadth scaling in retrieval-augmented agentic systems. The public code release is a clear strength for reproducibility.
major comments (3)
- [Abstract and §3] Abstract and §3 (method): the central mechanism—that selecting diverse seeds reduces first-turn query redundancy and thereby produces non-overlapping retrieval sets—is asserted but never directly measured. No pairwise Jaccard indices, unique-document counts, or embedding cosine similarities on the retrieved document sets are reported for DivInit versus standard parallel sampling.
- [§4] §4 (experiments): performance tables show 5-7 point average gains, yet the diversity selection criterion itself is described only at high level ('picks k diverse seeds'); the precise metric, embedding model, or selection algorithm is unspecified, preventing verification that the intervention differs from simply increasing first-turn diversity by other means.
- [§4] §4: no statistical significance tests, variance across random seeds, or controls for prompt-length or sampling-temperature confounds are provided, so it remains unclear whether the gains are robust or attributable to the claimed redundancy-reduction mechanism.
minor comments (1)
- [§3] Notation for n and k is introduced in the abstract but never formalized with an equation or pseudocode; a short algorithm box would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below with clarifications and commitments to revisions that strengthen the evidence for our claims without misrepresenting the current manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central mechanism—that selecting diverse seeds reduces first-turn query redundancy and thereby produces non-overlapping retrieval sets—is asserted but never directly measured. No pairwise Jaccard indices, unique-document counts, or embedding cosine similarities on the retrieved document sets are reported for DivInit versus standard parallel sampling.
Authors: We agree that direct measurement of retrieval-set overlap would provide stronger mechanistic evidence. While the consistent 5-7 point gains across five models and eight benchmarks are consistent with the hypothesized redundancy reduction, we will add the requested analyses (pairwise Jaccard indices, unique-document counts, and embedding cosine similarities on retrieved sets) comparing DivInit to standard parallel sampling. These results will appear in a new subsection of §3 or §4. revision: yes
-
Referee: [§4] §4 (experiments): performance tables show 5-7 point average gains, yet the diversity selection criterion itself is described only at high level ('picks k diverse seeds'); the precise metric, embedding model, or selection algorithm is unspecified, preventing verification that the intervention differs from simply increasing first-turn diversity by other means.
Authors: We acknowledge the high-level description in the current draft. The revised manuscript will specify the exact similarity metric, embedding model, and selection algorithm used to choose the k diverse seeds from the n candidates. This will allow readers to verify that the procedure is distinct from other diversity-increasing methods. revision: yes
-
Referee: [§4] §4: no statistical significance tests, variance across random seeds, or controls for prompt-length or sampling-temperature confounds are provided, so it remains unclear whether the gains are robust or attributable to the claimed redundancy-reduction mechanism.
Authors: We will augment §4 with statistical significance tests (e.g., paired tests across benchmarks), variance or standard deviations over multiple random seeds, and explicit controls or ablations for prompt length and sampling temperature. These additions will help establish robustness and support attribution to the redundancy-reduction mechanism. revision: yes
Circularity Check
No circularity: purely empirical intervention with external benchmarks
full rationale
The paper introduces DivInit as a training-free method and evaluates it directly on eight external benchmarks across five models, reporting average gains of 5-7 points. No equations, fitted parameters, or derivation steps are present that could reduce the claimed improvements to quantities defined inside the paper. The central claim rests on benchmark results rather than any self-referential construction, self-citation chain, or ansatz smuggled via prior work. This is the standard case of an empirical contribution whose validity is assessed against outside data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diverse first-turn queries produce sufficiently non-overlapping retrieved evidence that subsequent trajectory turns yield higher-quality final answers.
Reference graph
Works this paper leans on
-
[1]
Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks
Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks.arXiv preprint arXiv:2604.11753. Xiaochuan Li, Ryan Ming, Pranav Setlur, Abhijay Paladugu, Andy Tang, Hao Kang, Shuai Shao, Rong Jin, and Chenyan Xiong. 2026. Benchmark Test- time Scaling of General LLM Agents.arXiv preprint arXiv:2602.18998. Xiaoxi Li and 1 others. 2025. Search-o1: Ag...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Let’s Verify Step by Step.arXiv preprint arXiv:2305.20050. Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. GAIA: a benchmark for General AI Assistants. InInter- national Conference on Learning Representations (ICLR). Niklas Muennighoff, Zitong Yang, Weijia Shi, and 1 others. 2025. S1: Simple Test-Time Scaling.arXiv...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
SmartSearch: Process Reward-Guided Query Refinement for Search Agents.arXiv preprint arXiv:2601.04888. An Yang and 1 others. 2025. Qwen3 Technical Report. arXiv preprint arXiv:2505.09388. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Lan- guage Models. InInte...
-
[4]
Every response must use exactly one of these two formats
-
[5]
If you need more information: output <thought>...</thought> then <search>your single search query here</search>
-
[6]
If you have the answer (or it is the last turn): output <thought>...</thought> then <answer>your concise final answer here</answer>
-
[7]
Do not output search and answer in the same turn
Do not output an answer outside <answer>...</answer>. Do not output search and answer in the same turn
-
[8]
Open-Web agent prompt You are a precise research assistant answering web-reasoning questions by searching the internet
On the last turn (turn {max_turns}) you MUST output <answer>...</answer> with your best guess if unsure. Open-Web agent prompt You are a precise research assistant answering web-reasoning questions by searching the internet. You have {max_turns} turns total. You are on turn {turn}. Question: {question} Search history: {history} Available actions per turn ...
-
[9]
Use EXACTLY one action per response
-
[10]
Answers must be exact: a name, number, date, or short phrase
-
[11]
On turn {max_turns} you MUST give <answer>...</answer>
-
[12]
Avoid generic queries
Search for specific facts. Avoid generic queries. Pool-generation prompt Generate exactly {n} diverse search queries to investigate this question. Each query should approach the question from a different angle, specifically targeting different constraints or components of the question. {history_block} Question: {question} Output exactly {n} queries, one p...
-
[13]
Factuality: the answer must contain the core correct information
-
[14]
Semantic equivalence: mark CORRECT if the meaning is the same despite phrasing differences
-
[15]
Completeness: for multi-part questions, all parts must be correctly answered
-
[16]
Contradiction: mark INCORRECT only if the answer directly contradicts the ground truth
-
[17]
CORRECT” or “INCORRECT
Extra information: ignore extra details if the core answer is correct. Briefly explain your reasoning, then output “CORRECT” or “INCORRECT” on the final line. A.3 Infrastructure and Reproducibility Open-weight models are served locally with vLLM in bf16 with prefix caching enabled on4× NVIDIA L40S GPUs (48 GB VRAM). Per-rollout seeds are derived determini...
2026
-
[18]
p=0.04 implications;16.Nature’s policy on significance 2020
retracted articles for statistical misinterpretation; 15. p=0.04 implications;16.Nature’s policy on significance 2020. Standard Parallel(QPD = 0.120) Thread 0 ,→search:total number of articles published by Nature in 2020 ←-result:Volumes | Nature . . . fewer than 8% of sub- mitted papers . . . T2–T5: Loops on same query; never extracts count. Answer:[malf...
2020
-
[19]
First Last
Carolyn Collins Petersen Universe Today astrophysics June 2023; 6. R. G. Arendt NASA funding acknowledgment 2023; 7. Universe Today June 2023 linked paper authors; 8. galactic center observations paper June 2023 NASA grant. Standard Parallel(QPD = 0.098) Thread 0 ,→ search: Carolyn Collins Petersen June 6 2023 Universe Today R.G. Arendt NASA award ←-resul...
2023
-
[20]
Standard Parallel(QPD = 0.241) Thread 0 No query issued on turn 1; malformed output
viral hamster song same melody rooster video origin. Standard Parallel(QPD = 0.241) Thread 0 No query issued on turn 1; malformed output. Answer:[malformed] Thread 1 ,→ search: song performed by rooster and hamster animated videos separate tempos ←-result:Hampton the Hamster . . . viral character . . . Answer:Hampton ✗ Thread 2 ,→ search: song performed b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.