Safety, Security, and Cognitive Risks in Neuro-Symbolic AI
Pith reviewed 2026-06-27 03:13 UTC · model grok-4.3
The pith
Neuro-symbolic AI systems face enlarged attack surfaces allowing low-budget symbolic poisoning to cause high integrity violations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
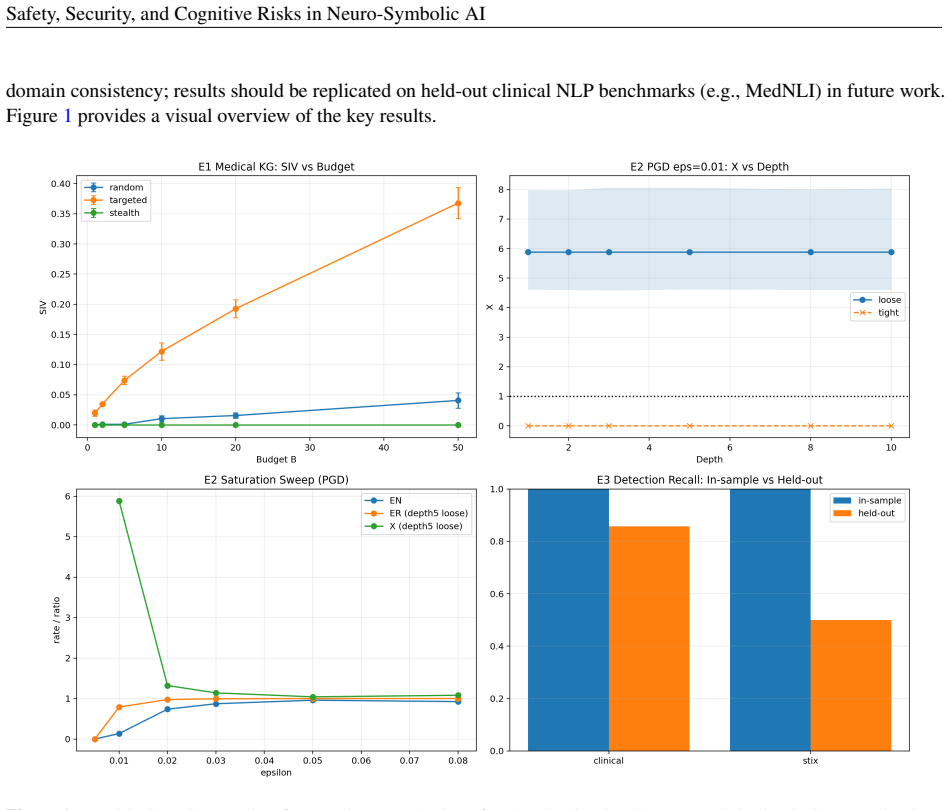
The paper claims that the NeSy attack surface spans neural perception, symbolic knowledge bases, reasoning engines, agentic orchestration, and data stores, with symbolic-layer threats enabling targeted KG poisoning to reach break-even SIV at an injection budget of 5 on a 205-entity medical KG, PGD perturbations producing an amplification ratio of 5.884, and single-axiom OWL edits succeeding in 93.3% of cases with full stealth against consistency checks.
What carries the argument
The central mechanism is the five-layer NeSy Attack Surface decomposition paired with the Symbolic Integrity Violation (SIV) metric and Cross-Layer Amplification Ratio X, which quantify how attacks on one layer affect overall system integrity and amplify effects.
If this is right
- Symbolic knowledge bases in NeSy systems require dedicated protection against poisoning attacks beyond standard neural defenses.
- Cognitive risks such as automation bias increase when systems provide explicit logical explanations.
- Detection methods for symbolic edits, like STIX, need improvement as they perform at random levels against certain attacks.
- Threat models must incorporate NeSy-specific tactics to address the hybrid nature of these systems.
- Mitigations should include measurable criteria aligned with existing AI safety standards.
Where Pith is reading between the lines
- These findings imply that security evaluations for AI in high-stakes domains should separately test symbolic components for integrity violations.
- The amplification ratio suggests that small neural perturbations can have outsized effects when combined with symbolic reasoning, warranting further study in varied architectures.
- Regulatory compliance for AI systems may need to account for the unique stealth properties of axiom-level edits in ontologies.
- Future work could explore whether these attack patterns generalize to other neuro-symbolic frameworks beyond the tested pipelines.
Load-bearing premise
The assumption that the Symbolic Integrity Violation metric and the five-layer attack surface model accurately reflect real-world security impacts in diverse neuro-symbolic deployments.
What would settle it
Demonstrating that the reported attack success rates, such as 93.3% SIV from single-axiom edits, do not occur or are easily detectable in operational neuro-symbolic systems would falsify the claims of practical vulnerability.
Figures
read the original abstract
Neuro-symbolic AI (NeSy) pairs neural perception with symbolic reasoning, making it attractive for high-stakes domains where explainability and structured inference are required. However, this hybrid architecture introduces an enlarged attack surface spanning five layers: neural perception, symbolic knowledge bases, reasoning engines, agentic orchestration, and data stores -- each exploitable in ways absent from purely neural systems. This paper makes six contributions: (1) formal definitions of NeSy Attack Surface, Symbolic Integrity Violation (SIV), and Cross-Layer Amplification Ratio $\mathcal{X}$, decomposed into neural-caused and autonomous symbolic sensitivity components; (2) a unified threat model extending MITRE ATLAS with 11 NeSy-specific tactic extensions and a five-profile attacker taxonomy; (3) a symbolic-layer threat catalogue covering knowledge graph (KG) poisoning, ontology-merging, and inference-engine subversion; (4) analysis of cognitive risks -- automation bias, authority bias, and sycophantic reinforcement -- structurally amplified by NeSy's explicit logical explanations relative to black-box neural outputs; (5) interdisciplinary mitigations with measurable acceptance criteria aligned to NIST AI 600-1 and the EU AI Act; (6) three empirical benchmarks: (E1) targeted KG poisoning achieves break-even SIV at injection budget $B=5$ on a 205-entity medical KG, with a KG-specific stealth/SIV trade-off; (E2) PGD-10 at $\varepsilon=0.01$ yields $\mathcal{X}=5.884$ (95% CI $[4.64,\, 8.00]$, $p<0.0001$), confirmed adversarially specific by a matched-random baseline ($E^{R}_{\mathrm{rand}}=0$), on a DistilBERT+ProbLog pipeline; (E3) single-axiom OWL edits achieve 93.3% SIV success with 100% Pellet-consistency stealth, but held-out STIX detection fails at 50% (random-guessing level), an open problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that neuro-symbolic AI enlarges the attack surface across five layers (neural perception, symbolic KBs, reasoning engines, agentic orchestration, data stores) and introduces formal definitions of the NeSy Attack Surface, Symbolic Integrity Violation (SIV), and Cross-Layer Amplification Ratio X (decomposed into neural-caused and autonomous symbolic sensitivity components). It extends MITRE ATLAS with 11 NeSy-specific tactics and a five-profile attacker taxonomy, catalogues symbolic threats including KG poisoning and OWL edits, analyzes structurally amplified cognitive risks (automation bias, authority bias, sycophantic reinforcement), proposes mitigations aligned to NIST AI 600-1 and the EU AI Act, and reports three benchmarks: (E1) targeted KG poisoning reaches break-even SIV at injection budget B=5 on a 205-entity medical KG; (E2) PGD-10 at ε=0.01 yields X=5.884 (95% CI [4.64, 8.00], p<0.0001) on DistilBERT+ProbLog with matched-random baseline E^R_rand=0; (E3) single-axiom OWL edits achieve 93.3% SIV success with 100% Pellet-consistency stealth but 50% STIX detection.
Significance. If the results hold, the work would be significant for establishing a structured framework and quantitative metrics to assess security and cognitive risks unique to hybrid NeSy systems, which are increasingly relevant for high-stakes domains. The explicit statistical reporting in the benchmarks (confidence intervals, p-values, and matched baselines) provides a reproducible empirical foundation that strengthens the threat catalogue and mitigation proposals. The alignment of acceptance criteria with existing standards adds immediate applicability, and the formal definitions of SIV and X offer a potential basis for future cross-layer analyses if their validity can be established.
major comments (2)
- [Contribution (1), benchmarks E1–E3] Contribution (1) and benchmarks E1–E3: The definitions of SIV and X are load-bearing for every quantitative claim (break-even B=5, X=5.884, 93.3% success), yet the manuscript supplies no validation, mapping, or comparison of these metrics against external attacker models, established red-team outcomes, or other NeSy deployments. This leaves open whether the reported values measure real security impact or are artifacts of the chosen formalization.
- [E2] E2: The claim that X=5.884 demonstrates cross-layer amplification rests on the DistilBERT+ProbLog pipeline and the matched-random baseline; the manuscript does not address whether this pipeline or the five-layer decomposition is representative of broader NeSy systems, limiting the generalizability of the amplification result.
minor comments (2)
- The abstract states that full methods, data exclusion rules, and baseline details appear in the experimental sections; ensure these are explicitly cross-referenced from the benchmark descriptions for readers who encounter the results first in the abstract.
- Notation: The decomposition of X into neural-caused and autonomous symbolic sensitivity components is introduced in contribution (1); verify that both components are defined with explicit equations or pseudocode in the main text before their use in the benchmarks.
Simulated Author's Rebuttal
Thank you for the constructive review and for recognizing the statistical controls in the benchmarks. We respond point-by-point to the two major comments below, proposing targeted textual revisions that clarify scope and limitations while preserving the core contributions.
read point-by-point responses
-
Referee: Contribution (1) and benchmarks E1–E3: The definitions of SIV and X are load-bearing for every quantitative claim (break-even B=5, X=5.884, 93.3% success), yet the manuscript supplies no validation, mapping, or comparison of these metrics against external attacker models, established red-team outcomes, or other NeSy deployments. This leaves open whether the reported values measure real security impact or are artifacts of the chosen formalization.
Authors: We agree that external validation of the newly introduced metrics SIV and X against established red-team outcomes or other NeSy systems is not provided in the current manuscript. The metrics are formally defined from the five-layer attack surface and the experiments include internal controls (matched-random baseline E^R_rand=0, confidence intervals, and p-values). In revision we will add an explicit limitations subsection that (a) maps SIV to selected MITRE ATLAS tactics where overlap exists and (b) states that the reported numerical values are illustrative of the formalization rather than externally validated security-impact measures. This revision will be textual only and will not alter the definitions or benchmark results. revision: partial
-
Referee: E2: The claim that X=5.884 demonstrates cross-layer amplification rests on the DistilBERT+ProbLog pipeline and the matched-random baseline; the manuscript does not address whether this pipeline or the five-layer decomposition is representative of broader NeSy systems, limiting the generalizability of the amplification result.
Authors: The DistilBERT+ProbLog pipeline was chosen as a minimal, reproducible instance of neural perception paired with symbolic probabilistic reasoning; the five-layer decomposition is offered as an organizing framework rather than a claim of universality. We will revise the E2 discussion to (a) label the pipeline as illustrative, (b) cite additional NeSy architectures (e.g., Logic Tensor Networks, Neural Theorem Provers) for context, and (c) note that cross-layer amplification ratios may vary with architecture. New experiments on additional pipelines lie outside the scope of a revision. revision: partial
Circularity Check
No circularity in derivation chain; metrics defined and experiments reported independently
full rationale
The paper introduces new formal definitions for NeSy Attack Surface, SIV, and X as contribution (1), extends MITRE ATLAS with new tactics, catalogues threats, discusses cognitive risks, proposes mitigations, and reports three direct empirical benchmarks (E1-E3) on concrete setups like the 205-entity KG and DistilBERT+ProbLog pipeline. No equations, predictions, or first-principles results are shown that reduce by construction to fitted parameters or prior self-citations. The reported values (B=5 break-even, X=5.884, 93.3% success) are experimental measurements using the newly defined metrics, not statistically forced outputs. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neurosymbolic AI – why, what, and how.arXiv preprint arXiv:2305.00813, 2023
Amit Sheth, Kaushik Roy, and Manas Gaur. Neurosymbolic AI – why, what, and how.arXiv preprint arXiv:2305.00813, 2023. URLhttps://arxiv.org/abs/2305.00813. Accessed 2025
arXiv 2023
-
[2]
Farrar, Straus and Giroux, New York, 2011
Daniel Kahneman.Thinking, Fast and Slow. Farrar, Straus and Giroux, New York, 2011
2011
-
[3]
Neurosymbolic AI for safe and trustworthy high-stakes applications
Ritu Kumari, Manas Gaur, Amit Sheth, et al. Neurosymbolic AI for safe and trustworthy high-stakes applications. Preprints.org, 2025. URL https://www.preprints.org/manuscript/202511.1342/v1. DOI: 10.20944/preprints202511.1342.v1
-
[5]
URLhttps://arxiv.org/abs/2509.06921
-
[6]
How a neuro-symbolic AI approach can improve trust in AI ap- plications
AllegroGraph. How a neuro-symbolic AI approach can improve trust in AI ap- plications. AllegroGraph Blog, 2024. URL https://allegrograph.com/ how-a-neuro-symbolic-ai-approach-can-improve-trust-in-ai-apps/. 26 Safety, Security, and Cognitive Risks in Neuro-Symbolic AI
2024
-
[7]
Towards the psychological security of agentic AI
Microsoft Research. Towards the psychological security of agentic AI. Microsoft Research Project, 2025. URL https://www.microsoft.com/en-us/research/project/ towards-the-psychological-security-of-agentic-ai/
2025
-
[8]
Neuro-symbolic artificial intelligence
European Data Protection Supervisor (EDPS). Neuro-symbolic artificial intelligence. EDPS TechSonar,
-
[9]
URL https://www.edps.europa.eu/data-protection/technology-monitoring/ techsonar/neuro-symbolic-artificial-intelligence
-
[10]
MITRE ATLAS: AI security framework with 16 tactics and 84 techniques
Vectra AI. MITRE ATLAS: AI security framework with 16 tactics and 84 techniques. Vectra AI Topics, 2024. URLhttps://www.vectra.ai/topics/mitre-atlas
2024
-
[11]
OWASP top 10 2025 for LLM applications: What’s new? risks and mitiga- tion techniques
Confident AI. OWASP top 10 2025 for LLM applications: What’s new? risks and mitiga- tion techniques. Confident AI Blog, 2025. URL https://www.confident-ai.com/blog/ owasp-top-10-2025-for-llm-applications-risks-and-mitigation-techniques
2025
-
[12]
Assessing gaps in MITRE ATLAS (oct 2024)
Shawn Riley. Assessing gaps in MITRE ATLAS (oct 2024). LinkedIn Pulse, 2024. URL https://www. linkedin.com/pulse/assessing-gaps-mitre-atlas-oct-2024-shawn-riley-2ettc
2024
-
[13]
System 1 and system 2 thinking explained by kahneman
Sue Behavioural Design. System 1 and system 2 thinking explained by kahneman. Sue Be- havioural Design Blog, 2024. URL https://www.suebehaviouraldesign.com/en/blog/ system-1-and-system-2-explained/
2024
-
[14]
Cognitive security risks: AI manipulation and distorted belief – sycophantic AI
Michael Varga. Cognitive security risks: AI manipulation and distorted belief – sycophantic AI. LinkedIn Post, 2024. URL https://www.linkedin.com/posts/michael-varga-6b00b3167_ breaking-sycophantic-ai-distorts-belief-activity-7434970624256532481-eNfe
2024
-
[15]
What is cognitive security? Blackbird AI Blog, 2024
Blackbird AI. What is cognitive security? Blackbird AI Blog, 2024. URL https://blackbird.ai/blog/ what-is-cognitive-security/
2024
-
[16]
Artificial intelligence risk management framework: Generative artificial intelligence profile (NIST AI 600-1)
National Institute of Standards and Technology. Artificial intelligence risk management framework: Generative artificial intelligence profile (NIST AI 600-1). Technical report, NIST, 2024. URL https://nvlpubs.nist. gov/nistpubs/ai/NIST.AI.600-1.pdf
2024
-
[17]
Regulation (EU) 2024/1689 of the european parliament and of the council — artificial intelligence act
European Union. Regulation (EU) 2024/1689 of the european parliament and of the council — artificial intelligence act. Official Journal of the European Union, 2024. URL https://eur-lex.europa.eu/eli/reg/ 2024/1689/oj/eng
2024
-
[18]
Michel-Delétie and M
C. Michel-Delétie and M. K. Sarker. Neuro-symbolic methods for trustworthy AI: A systematic review.Neu- rosymbolic AI Journal, 2024. URL https://neurosymbolic-ai-journal.com/system/files/ nai-paper-726.pdf
2024
-
[19]
Manas Gaur and Amit Sheth. Building trustworthy NeuroSymbolic AI systems: Consistency, reliability, explain- ability, and safety.arXiv preprint arXiv:2312.06798, 2023. URL https://arxiv.org/abs/2312.06798
arXiv 2023
-
[20]
Experimenting with neurosymbolic AI for defending against cyber threats.Neurosymbolic AI Journal, 2025
Magnus Wiik Eckhoff, Jonas Halvorsen, Bjørn Jervell Hansen, Martin Eian, Vasileios Mavroeidis, Robert Andrew Chetwyn, Geir Skjøtskift, and Gudmund Grov. Experimenting with neurosymbolic AI for defending against cyber threats.Neurosymbolic AI Journal, 2025. URL https://neurosymbolic-ai-journal.com/ system/files/nai-paper-828.pdf
2025
-
[21]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InInternational Conference on Learning Representations (ICLR), 2015. URL https://arxiv.org/abs/ 1412.6572. 27 Safety, Security, and Cognitive Risks in Neuro-Symbolic AI
Pith/arXiv arXiv 2015
-
[22]
Towards robust graph neural networks for noisy graphs with sparse labels
Xu Zou, Qiuling Xu, Hanghang Tong, Jiliang Tang, et al. Towards robust graph neural networks for noisy graphs with sparse labels. InACM International Conference on Web Search and Data Mining (WSDM), 2022. URL https://arxiv.org/abs/2201.00232
arXiv 2022
-
[23]
A review of agentic AI in cybersecurity: Cognitive autonomy, risks, and mitigations
Ibrahim Adabara, Bashir Olaniyi Sadiq, Aliyu Nuhu Shuaibu, Yale Ibrahim Danjuma, and Maninti Venkateswarlu. A review of agentic AI in cybersecurity: Cognitive autonomy, risks, and mitigations. F1000Research, 14:843, 2025. URL https://pmc.ncbi.nlm.nih.gov/articles/PMC12569510/. DOI: 10.12688/f1000research.169337.1
-
[24]
Automation bias in human-AI collaboration: A review
Bochao Zou et al. Automation bias in human-AI collaboration: A review. AI & Society, 2025. URL https: //link.springer.com/article/10.1007/s00146-025-02422-7
-
[25]
Available: https://doi.org/10.6028/NIST.AI.100-1
National Institute of Standards and Technology. Artificial intelligence risk management framework (AI RMF 1.0), NIST AI 100-1. Technical report, NIST, 2023. URLhttps://doi.org/10.6028/NIST.AI.100-1
-
[26]
Neurosymbolic AI: Bridging neural learning and symbolic reasoning for next-generation intelligent systems
Infosys. Neurosymbolic AI: Bridging neural learning and symbolic reasoning for next-generation intelligent systems. Infosys Emerging Technology Blog, 2024. URL https://blogs. infosys.com/emerging-technology-solutions/artificial-intelligence/ neurosymbolic-ai-bridging-neural-learning-and-symbolic-reasoning-for-next-generation-intelligent-systems. html
2024
-
[27]
Michel-Delétie and M
C. Michel-Delétie and M. K. Sarker. Neuro-symbolic methods for trustworthy AI. Neu- rosymbolic AI Journal, 2024. URL https://neurosymbolic-ai-journal.com/paper/ neuro-symbolic-methods-trustworthy-ai-systematic-review
2024
-
[28]
The OWASP top 10 for LLM applications (2025): Explained simply
Aembit. The OWASP top 10 for LLM applications (2025): Explained simply. Aembit Blog, 2025. URL https://aembit.io/blog/owasp-top-10-llm-risks-explained/
2025
-
[29]
MITRE ATLAS framework – AI security reference
Repello AI. MITRE ATLAS framework – AI security reference. Repello AI Blog, 2024. URL https: //repello.ai/blog/mitre-atlas-framework
2024
-
[30]
MITRE ATLAS framework 2026 – guide to securing AI systems
Practical DevSecOps. MITRE ATLAS framework 2026 – guide to securing AI systems. Practical DevSecOps Blog, 2026. URL https://www.practical-devsecops.com/ mitre-atlas-framework-guide-securing-ai-systems/
2026
-
[31]
OWASP top 10 LLM: How to test your gen AI app in 2025
Evidently AI. OWASP top 10 LLM: How to test your gen AI app in 2025. Evidently AI Blog, 2025. URL https://www.evidentlyai.com/blog/owasp-top-10-llm
2025
-
[32]
OWASP top 10 LLM, updated 2025: Examples and mitigation strate- gies
Oligo Security. OWASP top 10 LLM, updated 2025: Examples and mitigation strate- gies. Oligo Academy, 2025. URL https://www.oligo.security/academy/ owasp-top-10-llm-updated-2025-examples-and-mitigation-strategies
2025
-
[33]
System 1 and system 2 thinking
The Marketing Society. System 1 and system 2 thinking. Marketing Society Think Piece, 2024. URL https: //www.marketingsociety.com/think-piece/system-1-and-system-2-thinking
2024
-
[34]
Daniel kahneman explains the machinery of thought
Farnam Street. Daniel kahneman explains the machinery of thought. Farnam Street Blog, 2024. URL https: //fs.blog/daniel-kahneman-the-two-systems/
2024
-
[35]
Can you trust an AI agent? learn cognitive AI safety guide
Tredence. Can you trust an AI agent? learn cognitive AI safety guide. Tredence Blog, 2025. URL https: //www.tredence.com/blog/cognitive-ai-safety
2025
-
[36]
Alireza S. Ziabari, Nona Ghazizadeh, Zhivar Sourati, Farzan Karimi-Malekabadi, Payam Piray, and Morteza Dehghani. Reasoning on a spectrum: Aligning LLMs to system 1 and system 2 reasoning. arXiv preprint arXiv:2502.12470, 2025. URLhttps://arxiv.org/abs/2502.12470
arXiv 2025
-
[37]
A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2): 65–70, 1979
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2): 65–70, 1979. 28
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.