Examining the Limits of Word2Vec with Toki Pona
Pith reviewed 2026-06-27 02:58 UTC · model grok-4.3
The pith
Word2Vec captures semantic structure in Toki Pona's 130-word lexicon when trained on large text volumes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
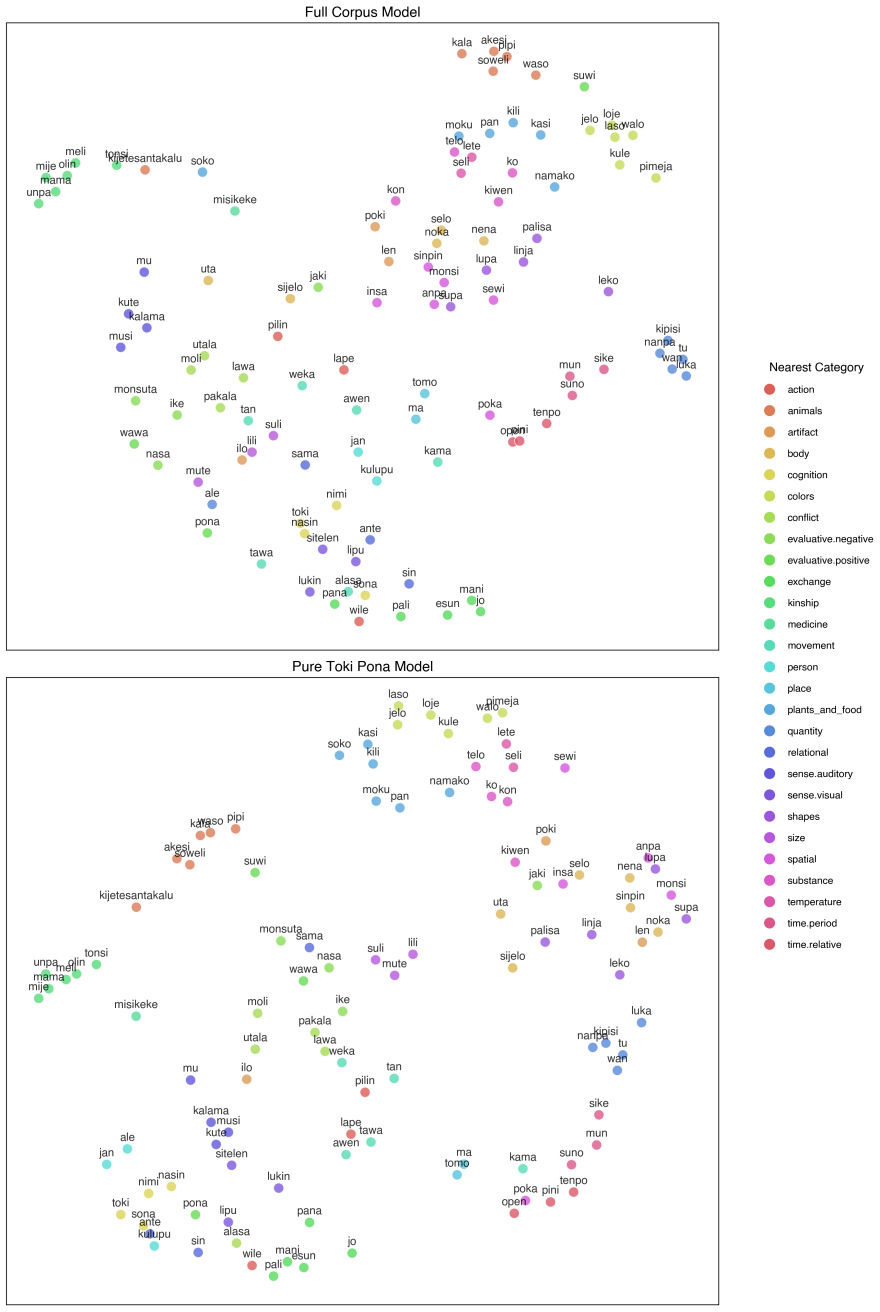
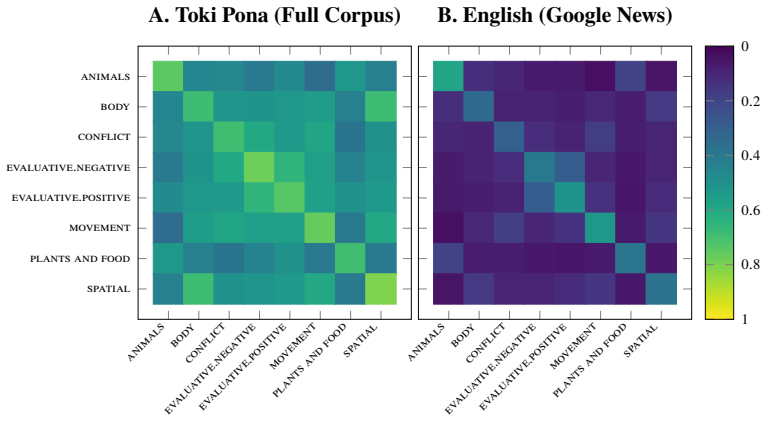
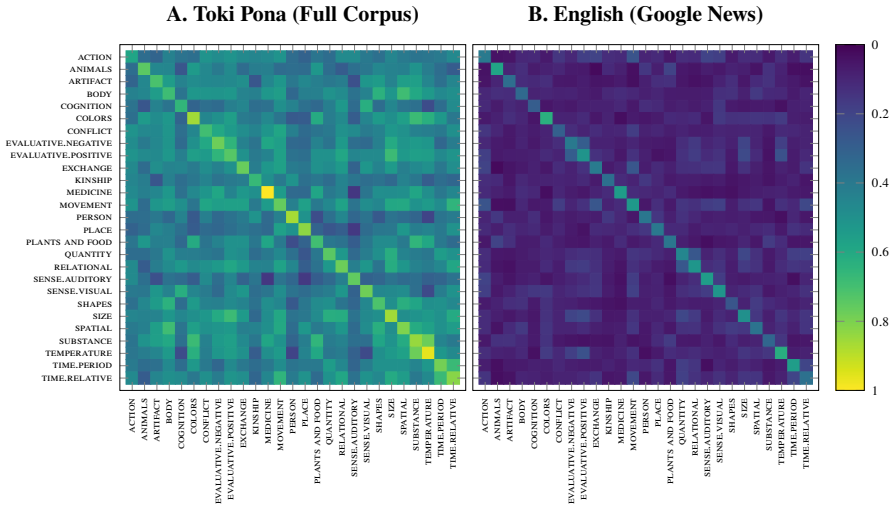
Word2Vec successfully generates embeddings that capture semantic relationships in Toki Pona despite its extreme vocabulary reduction to approximately 130 words. Training on 1.4 million sentences reveals that effectiveness stems primarily from distributional patterns in the corpus rather than lexicon size. Retaining incidental tokens such as named entities and loanwords draws similar words closer together in vector space while leaving the relative embedding structure intact, as confirmed by centroid proximity measures, agglomerative clustering silhouette scores, and similarity matrices aligned with English.
What carries the argument
Two parallel Word2Vec models on the same Toki Pona corpus, one retaining and one filtering non-core tokens, evaluated via semantic category centroid proximity, agglomerative clustering silhouette scores, and English representational similarity matrices.
If this is right
- Embeddings remain stable in relative structure when sparse non-core tokens are retained in training data.
- Incidental tokens improve the tightness of similar-word clusters without harming overall organization.
- Semantic relationships in embeddings arise chiefly from co-occurrence statistics rather than total unique word count.
- Word2Vec can be applied to other minimal-vocabulary constructed or low-resource languages given adequate text volume.
Where Pith is reading between the lines
- The findings point toward testing the same approach on other constructed languages or pidgins to see if corpus size consistently overrides lexicon limits.
- One could examine whether the observed benefit from incidental tokens holds when the extra items are systematically varied in type or frequency.
- This setup invites direct comparison with other embedding methods to check if the pattern is specific to Word2Vec or general to distributional models.
- Results suggest that data collection efforts for small languages should prioritize volume of usage examples over vocabulary expansion.
Load-bearing premise
The chosen quantitative metrics of centroid proximity, silhouette scores, and similarity matrices to English measure genuine semantic capture instead of artifacts from the small vocabulary or mixed corpus composition.
What would settle it
Finding that the similarity matrices or cluster structures for the Toki Pona embeddings differ markedly from English patterns in a manner attributable to vocabulary size alone, or that removing incidental tokens produces substantially worse clustering scores.
Figures
read the original abstract
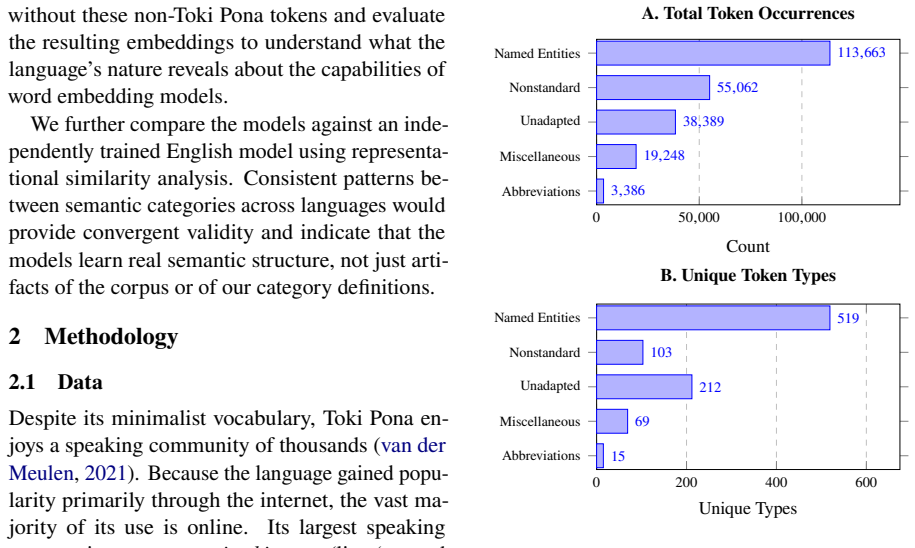
Word2Vec's effectiveness at generating semantic embeddings has been widely validated, yet it has been tested almost exclusively on languages with large vocabulary inventories. This study examines whether Word2Vec can successfully capture semantic relationships within an extremely reduced vocabulary using data from Toki Pona, a constructed language with approximately 130 words. We sourced 1.4 million sentences (7.95 million tokens) from the Toki Pona community for training. Approximately 23% of sentences in the corpus contain non-Toki Pona tokens such as named entities, loanwords, and neologisms. To investigate whether this linguistic noise enhances or hinders performance -- a topic rarely addressed in word embedding literature -- we trained two distinct models: one retaining these incidental tokens and another filtering them out completely. Evaluation was conducted using quantitative methods measuring word proximity to semantic category centroids, automated silhouette scores via agglomerative clustering, and qualitative analysis utilizing representational similarity matrices compared against English. The results indicate that while sparse, non-core tokens do not affect the relative structure of the learned embeddings, they actually draw similar words closer together in the vector space. Importantly, Word2Vec's effectiveness depends more on distributional patterns than lexicon size even at this extreme lower bound.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript trains Word2Vec on a corpus of 1.4 million Toki Pona sentences (7.95 million tokens) drawn from community sources to test whether semantic embeddings can be learned from an extremely small ~130-word lexicon. Two models are compared (one retaining incidental non-Toki Pona tokens, one filtering them), and evaluation uses three methods: proximity of words to semantic category centroids, silhouette scores from agglomerative clustering, and representational similarity matrices versus English embeddings. The central claim is that Word2Vec captures semantic relationships via distributional patterns even at this extreme lower bound, that incidental tokens do not disrupt relative structure (and may draw similar words closer), and that lexicon size is less important than distributional statistics.
Significance. If the quantitative evaluations are shown to measure semantics rather than corpus artifacts and the numerical results support the claims, the work would provide evidence that Word2Vec remains effective under extreme vocabulary reduction, using Toki Pona's deliberately broad senses as a strong test case. This could clarify the minimal conditions for distributional semantics and the robustness of embedding methods to lexicon size.
major comments (3)
- [Abstract] Abstract: the abstract states results from training and three evaluation approaches but provides no numerical values, error bars, statistical tests, or details on how category centroids were defined; the central claim therefore rests on unshown quantitative support.
- [Evaluation methods] Evaluation methods: proximity to semantic category centroids presupposes independently defined categories whose validity is not cross-checked against external criteria; with Toki Pona's broad, overlapping senses, this risks capturing usage regularities alone rather than independent semantic capture.
- [Evaluation methods] Evaluation methods: silhouette scores from agglomerative clustering on the embeddings themselves quantify clusterability of the learned space, which any sufficiently consistent co-occurrence model would produce, without establishing alignment with ground-truth semantics.
minor comments (2)
- [Abstract] The noisy-vs-clean ablation shows only that incidental tokens do not disrupt relative structure; it does not test whether that structure encodes meaning beyond frequency patterns.
- [Evaluation methods] The representational similarity matrices versus English compare two embedding spaces without establishing that either aligns with ground-truth semantics.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our evaluation approach. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract states results from training and three evaluation approaches but provides no numerical values, error bars, statistical tests, or details on how category centroids were defined; the central claim therefore rests on unshown quantitative support.
Authors: We agree that the abstract would be strengthened by including key numerical results. In the revised version, we will add specific values such as mean distances to category centroids, silhouette scores with standard deviations, and details on the definition of the 10 semantic categories (drawn from the official Toki Pona dictionary). Where appropriate, we will report statistical tests comparing the two models. revision: yes
-
Referee: [Evaluation methods] Evaluation methods: proximity to semantic category centroids presupposes independently defined categories whose validity is not cross-checked against external criteria; with Toki Pona's broad, overlapping senses, this risks capturing usage regularities alone rather than independent semantic capture.
Authors: The categories were constructed from the canonical Toki Pona word list and documented community usage to reflect the language's deliberately broad senses. To address the concern about external validation, we will add a mapping of these categories to English semantic equivalents and report alignment with resources such as WordNet synsets. This provides an independent check while preserving the focus on Toki Pona's reduced lexicon. revision: partial
-
Referee: [Evaluation methods] Evaluation methods: silhouette scores from agglomerative clustering on the embeddings themselves quantify clusterability of the learned space, which any sufficiently consistent co-occurrence model would produce, without establishing alignment with ground-truth semantics.
Authors: We acknowledge that silhouette scores primarily assess internal structure. In the manuscript, these scores are interpreted in conjunction with the predefined semantic categories and the representational similarity analysis against English embeddings, which serves as an external semantic reference. We will revise the methods and discussion sections to explicitly state how the three evaluation approaches are combined to link clusterability to semantic alignment rather than generic co-occurrence patterns. revision: partial
Circularity Check
No circularity; purely empirical training and evaluation
full rationale
The paper trains Word2Vec models on a Toki Pona corpus (1.4M sentences) and evaluates using standard metrics (centroid proximity, agglomerative clustering silhouette scores, and RSM vs. English). No equations, fitted parameters renamed as predictions, self-citations, or derivations are present. All reported outcomes follow directly from corpus statistics and off-the-shelf embedding training without any reduction of claims to inputs by construction. The study is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Toki Pona: The Language of Good , publisher=
Lang, Sonja , year=. Toki Pona: The Language of Good , publisher=
-
[2]
Spencer van der Meulen , title =
-
[3]
Efficient Estimation of Word Representations in Vector Space , author=. 2013 , month=. 1301.3781 , archivePrefix=
Pith/arXiv arXiv 2013
-
[4]
ma pona pi toki pona
-
[5]
2025 , publisher =
Danielson, III, Gregory. 2025 , publisher =
2025
-
[6]
2025 , month = sep, day = 20, publisher =
Asi, kala , title =. 2025 , month = sep, day = 20, publisher =
2025
-
[7]
Advances in Neural Information Processing Systems , volume=
On the Dimensionality of Word Embedding , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
2013 , eprint=
Efficient Estimation of Word Representations in Vector Space , author=. 2013 , eprint=
2013
-
[9]
Leland McInnes and John Healy and James Melville , year=. 1802.03426 , archivePrefix=
-
[10]
Computational Linguistics , volume =
Hill, Felix and Reichart, Roi and Korhonen, Anna , title =. Computational Linguistics , volume =. 2015 , month =. doi:10.1162/COLI_a_00237 , url =
-
[11]
Placing search in context: The concept revisited , volume =
Finkelstein, Lev and Gabrilovich, Evgeniy and Matias, Yossi and Rivlin, Ehud and Solan, Zach and Wolfman, Gadi and Ruppin, Eytan , year =. Placing search in context: The concept revisited , volume =. ACM Transactions on Information Systems - TOIS , doi =
-
[12]
Evaluation of Word Vector Representations by Subspace Alignment
Tsvetkov, Yulia and Faruqui, Manaal and Ling, Wang and Lample, Guillaume and Dyer, Chris. Evaluation of Word Vector Representations by Subspace Alignment. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015. doi:10.18653/v1/D15-1243
-
[13]
Miller, George A. , title =. Commun. ACM , month = nov, pages =. 1995 , issue_date =. doi:10.1145/219717.219748 , abstract =
-
[14]
Augmenting E nglish Adjective Senses with Supersenses
Tsvetkov, Yulia and Schneider, Nathan and Hovy, Dirk and Bhatia, Archna and Faruqui, Manaal and Dyer, Chris. Augmenting E nglish Adjective Senses with Supersenses. Proceedings of the Ninth International Conference on Language Resources and Evaluation ( LREC '14). 2014
2014
-
[15]
Linguistic Issues in Language Technology , author=
On Achieving and Evaluating Language-Independence in. Linguistic Issues in Language Technology , author=. 2011 , month=. doi:10.33011/lilt.v6i.1239 , abstractNote=
-
[16]
Semantic Drift in Multilingual Representations
Beinborn, Lisa and Choenni, Rochelle. Semantic Drift in Multilingual Representations. Computational Linguistics. 2020. doi:10.1162/coli_a_00382
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.