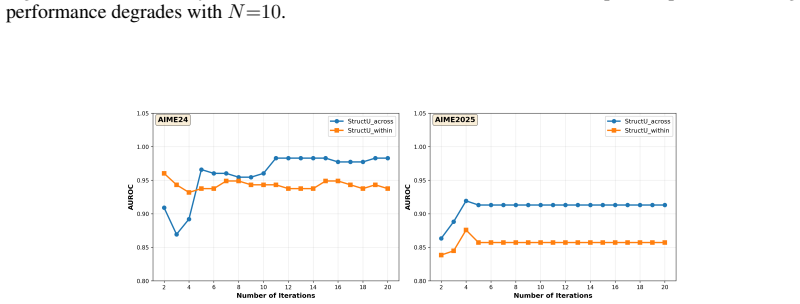
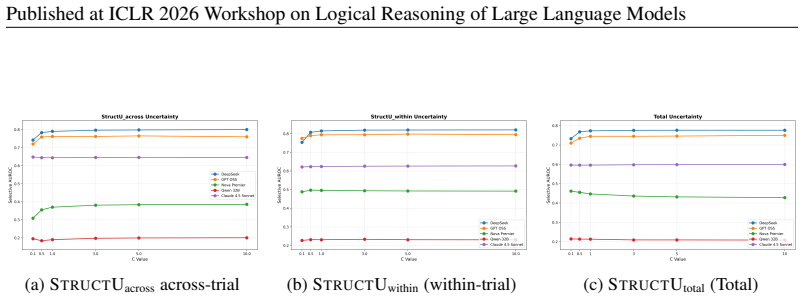
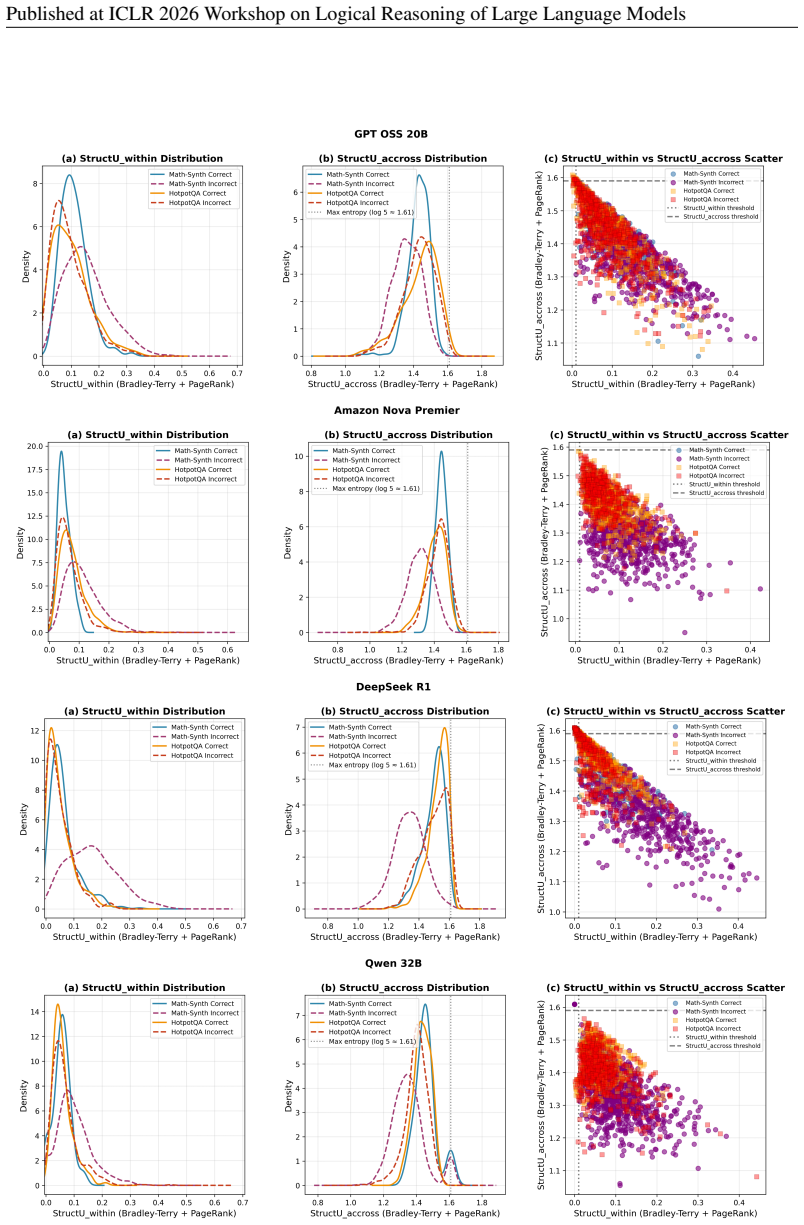
Quantifying Consistency in LLM Logical Reasoning via Structural Uncertainty
Pith reviewed 2026-06-27 03:14 UTC · model grok-4.3
The pith
Structural uncertainty from self-preference rankings complements answer dispersion to identify unreliable LLM reasoning on logic and math tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
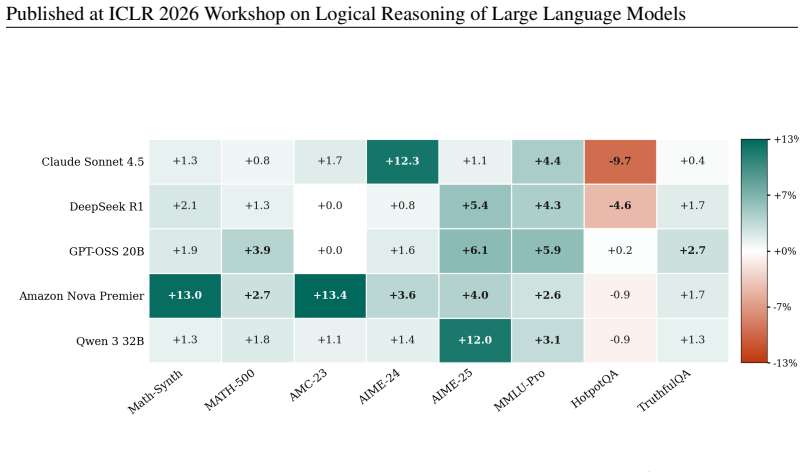
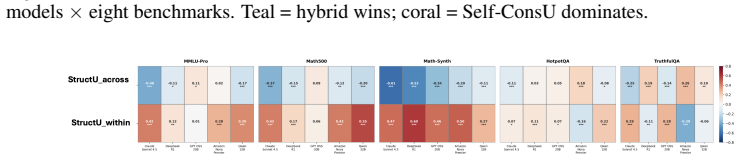
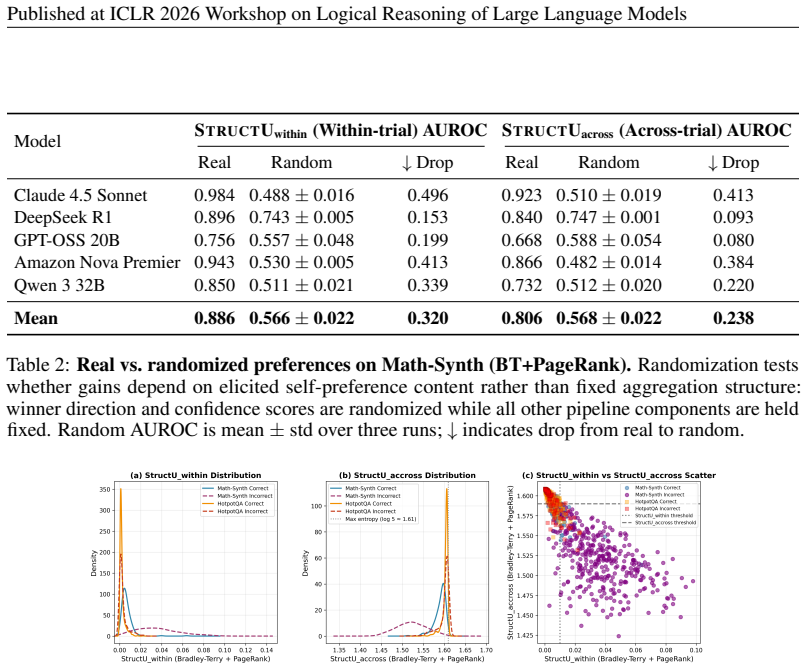
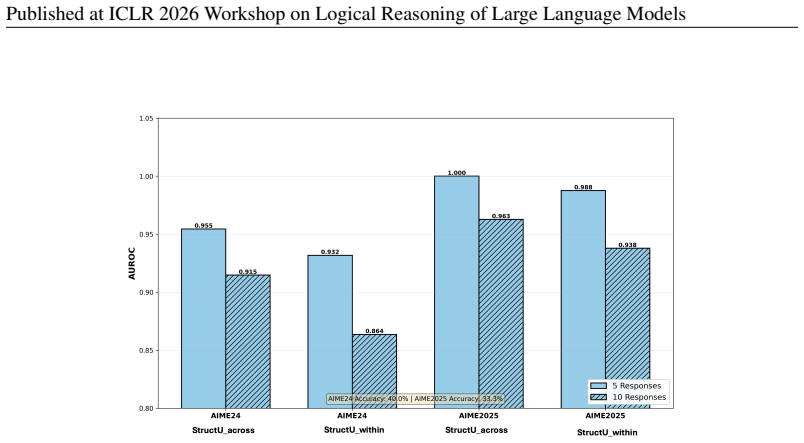
Structural uncertainty is derived from the stability of rankings obtained by aggregating an LLM's pairwise self-preferences among multiple sampled solutions using Bradley-Terry modeling and PageRank. This yields two components—across-trial ranking instability that correlates negatively with accuracy, and within-trial candidate ambiguity that correlates positively—providing a signal complementary to answer dispersion specifically for logical and mathematical reasoning tasks while collapsing to uniformity on factual retrieval.
What carries the argument
Structural uncertainty, computed as entropy decompositions of ranking distributions from self-preference judgments.
Load-bearing premise
The model's pairwise self-preferences among its own outputs form a stable ranking signal that reflects genuine reasoning consistency rather than its own judgment biases.
What would settle it
An experiment showing that on logical reasoning tasks the combination of structural uncertainty and answer dispersion does not improve detection of incorrect answers compared to dispersion alone would falsify the main claim.
Figures



read the original abstract
Large language models can arrive at the same answer through reasoning paths that are unstable, contradictory, or difficult to rank consistently -- a failure mode especially prevalent in multi-step deductive reasoning. Existing methods assess reliability primarily through output dispersion -- measuring how much sampled answers differ -- but this discards a complementary signal: whether the model can consistently rank competing reasoning candidates. We propose structural uncertainty, a consistency-aware framework derived from the stability of self-preference-induced rankings over sampled reasoning solutions. Given a query, we generate multiple candidate solutions and ask the model to judge pairwise preferences among its own outputs. We aggregate self-preferences into ranking distributions via Bradley-Terry modeling with PageRank, and decompose the signal into two entropy-based components: across-trial ranking instability and within-trial candidate ambiguity. Across five LLMs and eight benchmarks, structural signals provide information complementary to answer dispersion: on logical and mathematical reasoning tasks, the combination improves identification of unreliable instances, while on factual retrieval the structural signal collapses toward uniformity, diagnosing a regime boundary where reasoning-level consistency evaluation is uninformative. The two components relate differently to accuracy: within-trial ambiguity correlates positively with correctness -- consistent with settings where multiple plausible solution paths remain competitive -- while across-trial instability correlates negatively, signaling unreliable reasoning. Structural uncertainty is best understood not as a universal confidence estimator, but as a regime-sensitive evaluator of logical reasoning consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that structural uncertainty—derived from aggregating model self-preferences over sampled reasoning solutions via Bradley-Terry modeling and PageRank, then decomposing into across-trial ranking instability (negatively correlated with accuracy) and within-trial candidate ambiguity (positively correlated)—supplies information complementary to answer dispersion. This complementarity improves detection of unreliable instances on logical and mathematical tasks but collapses toward uniformity on factual retrieval, across five LLMs and eight benchmarks; the framework is positioned as a regime-sensitive evaluator of logical reasoning consistency rather than a universal confidence measure.
Significance. If the structural signal is shown to track reasoning consistency independent of elicitation artifacts, the work supplies a useful decomposition and task-regime distinction for LLM reliability assessment. The reported differential correlations and the breadth of models/benchmarks constitute a concrete empirical contribution that could be strengthened by targeted validation.
major comments (2)
- [Abstract] Abstract and framework description: the central claim that self-preference rankings yield entropy components tracking genuine reasoning instability (rather than LLM-as-judge artifacts such as position or length bias) is load-bearing for both the complementarity result and the logical-vs-factual regime boundary, yet the manuscript does not report controls for order randomization, length normalization, or consistency under prompt perturbation.
- [Results on task regimes] Task-regime results: the reported improvement from combining structural uncertainty with dispersion on logical/math tasks (and collapse on factual retrieval) depends on the pairwise tournament matrix being driven by logical content; without explicit checks that the Bradley-Terry + PageRank aggregation is robust to known self-preference biases, the task-type distinction risks being an artifact of the elicitation procedure.
minor comments (2)
- [Methods] Specify the precise entropy formulas used for the across-trial and within-trial components and how they are normalized across varying numbers of samples.
- [Experimental setup] Clarify the exact set of eight benchmarks, their categorization into logical/math vs. factual, and any selection criteria.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to validate the structural uncertainty framework against potential elicitation artifacts. We address the major comments point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and framework description: the central claim that self-preference rankings yield entropy components tracking genuine reasoning instability (rather than LLM-as-judge artifacts such as position or length bias) is load-bearing for both the complementarity result and the logical-vs-factual regime boundary, yet the manuscript does not report controls for order randomization, length normalization, or consistency under prompt perturbation.
Authors: We agree that the manuscript does not include explicit controls for order randomization, length normalization, or prompt perturbation consistency, and that such controls are necessary to more rigorously support the claim that the entropy components track reasoning instability rather than judge artifacts. The differential task-regime results provide indirect evidence, but direct validation is warranted. In the revised version we will add these controls as additional experiments and report the outcomes. revision: yes
-
Referee: [Results on task regimes] Task-regime results: the reported improvement from combining structural uncertainty with dispersion on logical/math tasks (and collapse on factual retrieval) depends on the pairwise tournament matrix being driven by logical content; without explicit checks that the Bradley-Terry + PageRank aggregation is robust to known self-preference biases, the task-type distinction risks being an artifact of the elicitation procedure.
Authors: We acknowledge that the manuscript lacks explicit robustness checks against known self-preference biases (position, length, etc.) in the Bradley-Terry + PageRank aggregation, and that this leaves open the possibility that the logical-vs-factual distinction is partly elicitation-driven. While the observed complementarity on logical tasks versus uniformity on factual retrieval is consistent with content-driven behavior, targeted bias-mitigation experiments are needed. We will incorporate such checks in the revision. revision: yes
Circularity Check
No significant circularity; derivation applies standard models to self-generated data without reduction to inputs
full rationale
The paper's chain generates candidate solutions, elicits pairwise self-preferences, aggregates them via Bradley-Terry + PageRank into ranking distributions, and decomposes the resulting entropy into across-trial instability and within-trial ambiguity. These steps use externally standard ranking techniques on the model's own outputs; the central claim of complementarity to answer dispersion (and task-regime differences) is presented as an empirical observation across benchmarks rather than a quantity forced by the equations themselves. No self-citations, fitted parameters renamed as predictions, or ansatzes imported via prior work appear as load-bearing in the provided abstract or derivation description. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Bradley-Terry model produces valid preference probabilities from pairwise comparisons
- standard math PageRank applied to preference graph yields stable ranking distributions
Reference graph
Works this paper leans on
-
[1]
Rank analysis of incomplete block designs: I. the method of paired comparisons,
doi: 10.1093/biomet/39.3-4.324. Sergey Brin and Lawrence Page. The anatomy of a large-scale hypertextual Web search engine. InComputer Networks and ISDN Systems, volume 30, pages 107–117,
-
[2]
Tiejin Chen, Xiaoou Liu, Longchao Da, Jia Chen, Vagelis Papalexakis, and Hua Wei
doi: 10.1016/ S0169-7552(98)00110-X. Tiejin Chen, Xiaoou Liu, Longchao Da, Jia Chen, Vagelis Papalexakis, and Hua Wei. Uncertainty quantification of large language models through multi-dimensional responses.arXiv preprint arXiv:2502.16820,
-
[3]
Uncertainty in language models: Assessment through rank-calibration
Xinmeng Huang, Shuo Li, Mengxin Yu, Matteo Sesia, Hamed Hassani, Insup Lee, Osbert Bastani, and Edgar Dobriban. Uncertainty in language models: Assessment through rank-calibration. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2851–2873. Association for Computational Linguistics,
2024
-
[4]
Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma. Look before you leap: An exploratory study of uncertainty measurement for large language models.arXiv preprint arXiv:2307.10236,
-
[5]
AIME 2024: American invitational mathematics examination dataset
HuggingFaceH4. AIME 2024: American invitational mathematics examination dataset. HuggingFace Dataset,
2024
-
[6]
doi: 10.1214/aos/1079120141. Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DaSilva, Eli Elhage, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
-
[7]
Calibration-tuning: Teaching large language models to know what they don’t know
11 Published at ICLR 2026 Workshop on Logical Reasoning of Large Language Models Sanyam Kapoor, Nate Gruver, Manley Roberts, Arka Pal, Samuel Dooley, Micah Goldblum, and Andrew Wilson. Calibration-tuning: Teaching large language models to know what they don’t know. InProceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024), pages 1–14,
2026
-
[8]
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?
URL https: //arxiv.org/abs/1703.04977. Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in llms.arXiv preprint arXiv:2406.15927,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with confidence: Uncertainty quantifica- tion for black-box large language models.arXiv preprint arXiv:2305.19187,
-
[10]
Estimating llm uncertainty with evidence.arXiv preprint arXiv:2502.00290,
Huan Ma, Jingdong Chen, Joey Tianyi Zhou, Guangyu Wang, and Changqing Zhang. Estimating llm uncertainty with evidence.arXiv preprint arXiv:2502.00290,
-
[11]
Vaishnavi Shrivastava, Percy Liang, and Ananya Kumar. Llamas know what gpts don’t show: Surrogate models for confidence estimation.arXiv preprint arXiv:2311.08877,
-
[12]
Vaishnavi Shrivastava, Ananya Kumar, and Percy Liang. Language models prefer what they know: Relative confidence estimation via confidence preferences.arXiv preprint arXiv:2502.01126,
-
[13]
12 Published at ICLR 2026 Workshop on Logical Reasoning of Large Language Models Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D. Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings ...
2026
-
[14]
Alexey Vashurin, Maria Vikhreva, Tom Kocmi, and Andrey Malinin
URL https://huggingface.co/datasets/TIGER-Lab/AIME25. Alexey Vashurin, Maria Vikhreva, Tom Kocmi, and Andrey Malinin. CoCoA: A minimum Bayes risk framework bridging confidence and consistency for uncertainty quantification in large language models. InAdvances in Neural Information Processing Systems, volume 38, 2025a. Roman Vashurin, Ekaterina Fadeeva, Ar...
-
[15]
Association for Computing Machinery. doi: 10.1145/237814.237880. Jae Oh Woo. Analytic mutual information in bayesian neural networks. In2022 IEEE International Symposium on Information Theory (ISIT), pages 300–305. IEEE,
-
[16]
Maqa: Evaluating uncertainty quantification in llms regarding data uncertainty
Yongjin Yang, Haneul Yoo, and Hwaran Lee. Maqa: Evaluating uncertainty quantification in llms regarding data uncertainty. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5846–5863,
2025
-
[17]
Kg-uq: Knowledge graph-based uncertainty quantification for long text in large language models
Yingqing Yuan, Linwei Tao, Haohui Lu, Matloob Khushi, Imran Razzak, Mark Dras, Jian Yang, and Usman Naseem. Kg-uq: Knowledge graph-based uncertainty quantification for long text in large language models. InCompanion Proceedings of the ACM on Web Conference 2025, pages 2071–2077,
2025
-
[18]
CoT-UQ: Improving response-wise uncertainty quantification in LLMs with chain-of-thought
13 Published at ICLR 2026 Workshop on Logical Reasoning of Large Language Models Boxuan Zhang and Ruqi Zhang. CoT-UQ: Improving response-wise uncertainty quantification in LLMs with chain-of-thought. InFindings of the Association for Computational Linguistics: ACL
2026
-
[19]
Kaitlyn Zhou, Jena D Hwang, Xiang Ren, and Maarten Sap. Relying on the unreliable: The impact of language models’ reluctance to express uncertainty.arXiv preprint arXiv:2401.06730,
-
[20]
We instead sample a connected sparse graph per trial by drawing a uniform random spanning tree T (m) on the N nodes and querying only its N−1 edges
14 Published at ICLR 2026 Workshop on Logical Reasoning of Large Language Models A ADDITIONALMETHODDETAILS A.1 RANDOMSPANNINGTREECOMPARISONGRAPHS A complete comparison graph on N candidates requires N 2 judge calls. We instead sample a connected sparse graph per trial by drawing a uniform random spanning tree T (m) on the N nodes and querying only its N−1...
2026
-
[21]
In dense graphs, Wilson sampling runs in expected O(N) time and produces an unbiased sample from the uniform distribution over spanning trees
based on loop- erased random walks. In dense graphs, Wilson sampling runs in expected O(N) time and produces an unbiased sample from the uniform distribution over spanning trees. A.2 BRADLEY–TERRY WITHL2 REGULARIZATION Model.BT assigns each response i a latent utility θi ∈R . The probability that i is preferred over j is P(i≻j) = exp(θi) exp(θi) + exp(θj)...
1957
-
[22]
We extend with confidence-weighted fractional updates
represents each response i with Gaussian rating ri = (µi, σi) and updates ratings sequentially from pairwise outcomes. We extend with confidence-weighted fractional updates. Inputs and filtering.Judge returns matches (w, ℓ, cwℓ) with confidence cwℓ ∈[0,100] . Convert to probabilityp wℓ =c wℓ/100, retain onlyp wℓ >0.5, discardp wℓ = 0.5. Confidence weighti...
2026
-
[23]
What is −(−(−(−(−(−(−(−500)×200))))) +−(−(−1)) ?
A.6 UNCERTAINTYDECOMPOSITIONDETAILS Running M trials yields PageRank distributions {π(1), . . . ,π(M) } where each π(m) ∈∆ N is a distribution over N candidates. Let ω denote stochastic trial factors. The identity H(π) = I(ω;π) +H(π|ω) motivates decomposing into across-trial (mutual information) and within-trial (conditional entropy) components. 16 Publis...
2026
-
[24]
HotpotQA signature
For each ques- tion, we sample N=5 candidate responses using the diverse prompt templates in Appendix E.6.1, and repeat the complete generation →comparison→ranking pipeline for M=5 independent trials. All models and datasets use identical decoding hyperparameters (Appendix C.2) to ensure fair comparison. Within each trial m, we obtain pairwise self-prefer...
2026
-
[25]
R4’s PageRank fluctuates between 0.055 and 0.212 (CV=0.497) because ranking depends on which spanning tree edges are sampled. This instability maps onto the two uncertainty components.Across-trial( StructUacross = 0.035): competing quality criteria (verification depth, metacognitive clarity, modularity) produce different winners depending on sampled edges...
2026
-
[26]
7 negations total (odd) applied to −500× 200 =−100,000 gives −100,000
→ −100,000 [correct: +100,000]→ −100,000 + 1 =−99,999 0.215 R3 Socratic Reframes as parity problem: “7 negations total (odd) applied to −500× 200 =−100,000 gives −100,000” — conflates inner negation with outer count [correct: 6 outer negations (even) applied to +100,000] → −100,000 + 1 =−99,999 0.224 R4 Decomposition Sub-problem 1: left expression → Sub-p...
-
[27]
I need to work from the innermost parentheses outward
All five responses unanimously answer10 000 000 000 000, matching the ground truth. All responses correct.Every response reaches the correct answer through sound reasoning. The five prompt templates produce identical arithmetic but differ in presentation: R1 adds self-check with (verified) annotations; R2 narrates thinking with even/odd shortcut; R3 frame...
2026
-
[28]
Straight No Chaser and Kristen Bell
but fail hop 2 due to missing context describing the group’s origins. Every response correctly reports the answer cannot be determined—unanimous incorrect agreement( Self-ConsU= 0 ) driven by shared retrieval gap, not reasoning error. Table 15 shows identical retrieval chains despite different prompts, with variation limited to surface reformulation. Page...
2026
-
[29]
Each response reaches the same abstention via a stylistically different but substantively identical path
but fail hop 2 due to missing context. Each response reaches the same abstention via a stylistically different but substantively identical path. Ground truth: Indiana University; unanimous model answer:cannot be determined. R1 R2 R3 R4 R5 Trial 0 0.202 0.208 0.196 0.196 0.196 Trial 1 0.201 0.207 0.201 0.195 0.195 Trial 2 0.201 0.207 0.195 0.195 0.201 Tria...
2026
-
[30]
Observation.Every response executes identical retrieval: scan all documents for ”1964” and folklore creatures → identify Documents 1, 5, 8 as partially relevant (creatures but no
All responses correctly identify this gap and abstain. Observation.Every response executes identical retrieval: scan all documents for ”1964” and folklore creatures → identify Documents 1, 5, 8 as partially relevant (creatures but no
1964
-
[31]
Response 1
→ note closest match is Chessie (1977/1980s sightings) → conclude information absent → abstain. Variation is surface-level only: R1 adds self-check; R2 lists documents; R3 uses Socratic framing; R4 decomposes; R5 casts as date-retrieval pattern. The uncertainty profile is statistically indistinguishable from the incorrect example: StructUacross < 0.001, S...
1977
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.