MemTrace: Probing What Final Accuracy Misses in Long-Term Memory
Pith reviewed 2026-06-27 03:10 UTC · model grok-4.3
The pith
The dominant bottleneck in LLM agents' long-term memory is evidence use rather than retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
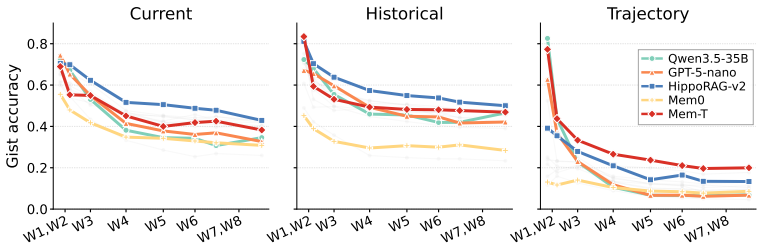
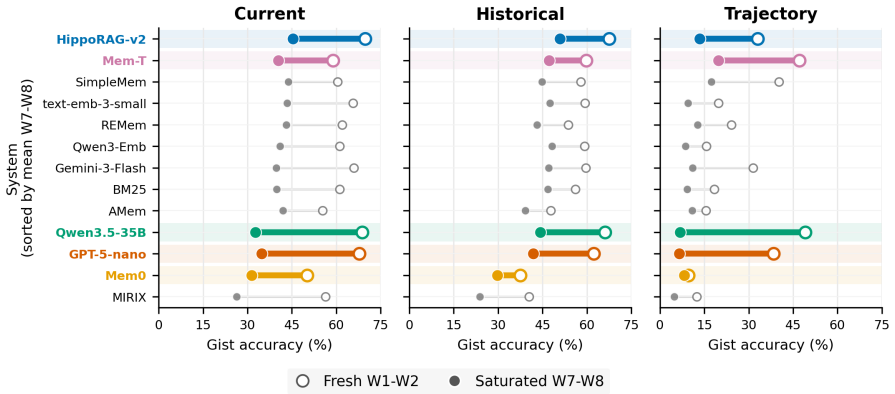
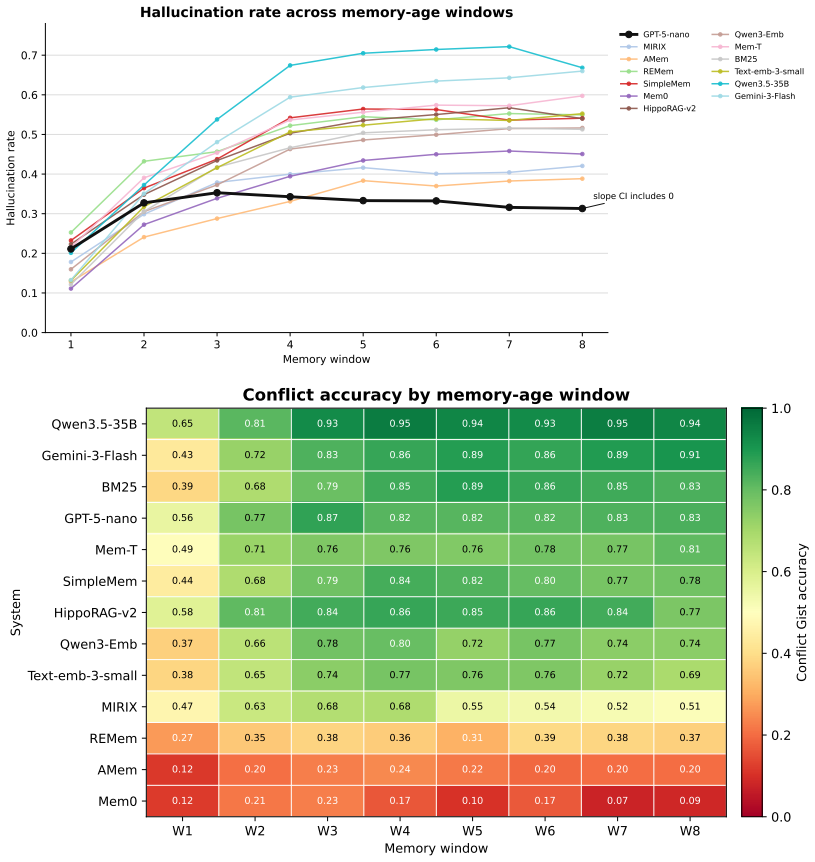
MemTrace measures long-term memory performance at the level of knowledge points, probing each along memory age, question type, and evidence condition. Across 13 configurations, the results indicate that recovering current and earlier states does not guarantee tracking trajectories of change, and abstaining safely differs from correcting false premises. The dominant issue is evidence use: evidence was retrievable ten times more often than missing when failures occurred.
What carries the argument
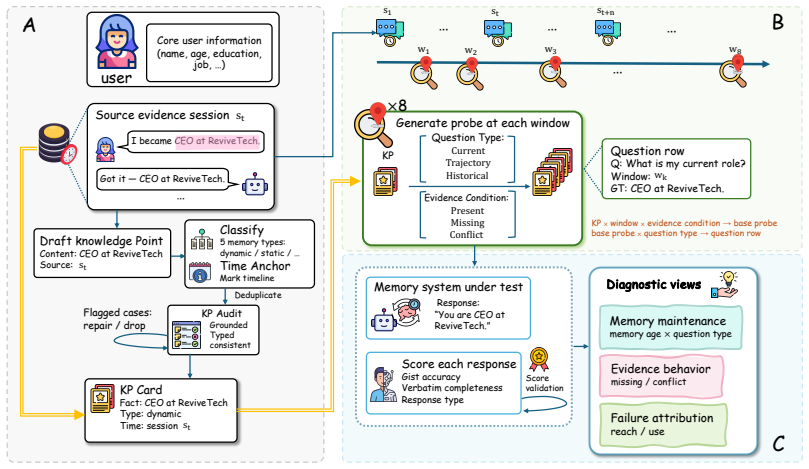
The MemTrace benchmark, which measures memory performance on individual knowledge points probed along the three dimensions of memory age, question type, and evidence condition.
If this is right
- Pooled accuracy scores can mask distinct failure modes such as inability to track fact changes or correct false premises.
- Ability to recall a fact's current and past states does not ensure ability to follow how the fact changed.
- Systems that safely abstain when evidence is missing still differ from those that correct false premises.
- Improving long-term memory requires advances in using reachable evidence, not only more storage or retrieval.
Where Pith is reading between the lines
- Training approaches that emphasize explicit reasoning steps over retrieved memory content could address the evidence-use gap.
- Benchmarks focused only on retrieval volume may miss the utilization issues identified here.
- Extending the same probing method to multi-turn user conversations could test whether the patterns persist outside controlled sessions.
Load-bearing premise
The three probing dimensions and the 13 chosen memory-system configurations are sufficient to identify the primary bottlenecks in long-term memory for LLM agents in general.
What would settle it
An experiment in which systems given explicit direct access to the relevant evidence in previously failing cases still produce the same error rate would show that evidence use is not the dominant bottleneck.
Figures



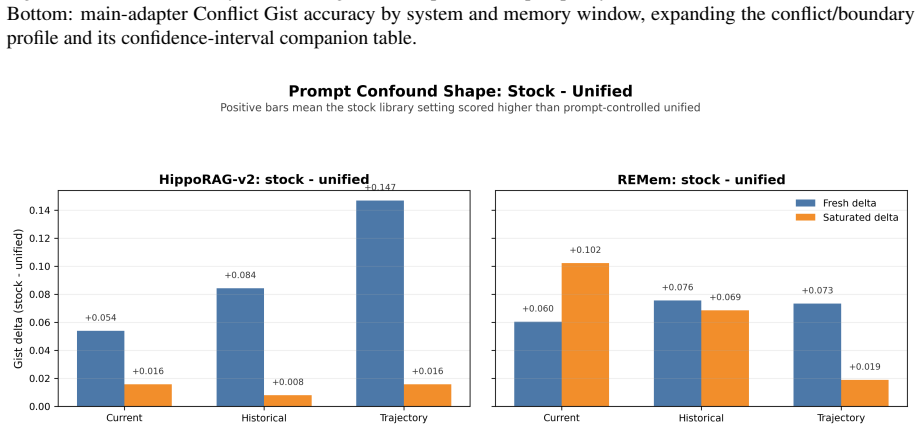
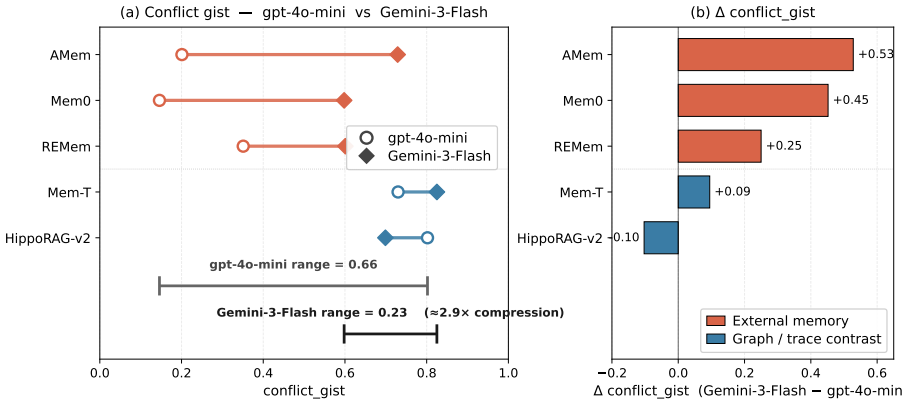
read the original abstract
LLM agents increasingly maintain long-term memory of user facts across sessions. Yet such memory is usually evaluated by aggregating accuracy over question rows or episodes. Because this approach scores question rows independently, even when several questions probe the same fact, it cannot show how that fact behaves as conditions change. We introduce MemTrace, a benchmark whose unit of measurement is the knowledge point: a single typed fact about the user, rather than an individual question. MemTrace probes each fact along three controlled dimensions: memory age, defined by how many sessions ago the fact appeared in the history; question type, covering current state, earlier state, and trajectory of change; and evidence condition, covering present, missing, and contradicted-by-false-premise settings. Evaluating 13 memory-system configurations across four paradigms, we find that similar pooled accuracy hides different failures: recovering a fact's current and earlier states does not imply tracking how it changed, and safe abstention does not imply correcting a false premise. The dominant bottleneck is evidence use, not retrieval: when systems fail, the evidence was retrievable 10 times more often than it was missing. These results suggest that improving long-term memory requires better use of reachable evidence, not simply more storage or retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemTrace, a benchmark that shifts evaluation of long-term memory in LLM agents from per-question accuracy to the 'knowledge point' (a single typed user fact) as the unit of analysis. It probes each fact along three dimensions—memory age (sessions since appearance), question type (current state, earlier state, or trajectory of change), and evidence condition (present, missing, or contradicted by false premise)—and reports results from 13 memory-system configurations across four paradigms. The central findings are that pooled accuracy conceals distinct failure modes (e.g., state recovery does not imply trajectory tracking) and that evidence use, not retrieval, is the dominant bottleneck, quantified by a 10x ratio of retrievable vs. missing evidence in failure cases.
Significance. If the quantitative claims hold under broader sampling, MemTrace supplies a diagnostic lens that could redirect memory-augmented agent research from storage/retrieval scaling toward evidence-utilization mechanisms. The multi-configuration empirical design is a positive feature for an evaluation paper.
major comments (2)
- [Abstract and experimental setup] The claim that 'evidence use, not retrieval' is the dominant bottleneck (Abstract) with a 10x retrievability ratio rests on the 13 configurations and three probing dimensions being representative. No selection criteria, coverage argument, or sensitivity check for these choices is supplied, so the ratio cannot yet be treated as diagnostic for LLM agents in general.
- [Results] The evidence-condition axis is used to separate retrieval vs. use failures, but without reported controls for how 'retrievable' is operationalized (e.g., oracle retrieval success rate per configuration) or statistical tests on the 10x ratio, the separation remains unverified.
minor comments (2)
- [Abstract] The abstract states evaluation across 'four paradigms' without naming them; this should be stated explicitly in the introduction or methods.
- [Introduction] Notation for 'knowledge point' is introduced without a formal definition or example in the opening paragraphs; a short boxed definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on representativeness and verification of our central claims. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and experimental setup] The claim that 'evidence use, not retrieval' is the dominant bottleneck (Abstract) with a 10x retrievability ratio rests on the 13 configurations and three probing dimensions being representative. No selection criteria, coverage argument, or sensitivity check for these choices is supplied, so the ratio cannot yet be treated as diagnostic for LLM agents in general.
Authors: The four paradigms were selected to span the primary architectural families in the literature (parametric, retrieval-augmented, memory-augmented, and hybrid), with the 13 configurations chosen as representative instantiations within each. The three probing dimensions directly operationalize the dimensions of interest for long-term memory (age, question type, evidence condition). We agree that an explicit coverage argument and sensitivity check were omitted; the revised manuscript will add a dedicated subsection in the experimental setup that justifies the selection, reports coverage relative to recent surveys, and includes a sensitivity analysis varying the number of configurations per paradigm. revision: yes
-
Referee: [Results] The evidence-condition axis is used to separate retrieval vs. use failures, but without reported controls for how 'retrievable' is operationalized (e.g., oracle retrieval success rate per configuration) or statistical tests on the 10x ratio, the separation remains unverified.
Authors: Retrievability is operationalized in the methods as whether the relevant knowledge point appears in the context returned by the memory system for that query (i.e., the system had access to the evidence but still produced an incorrect answer). We will add per-configuration oracle retrieval success rates as a control column in the main results table and report bootstrap confidence intervals and a paired statistical test on the 10x ratio to quantify uncertainty. These additions will appear in the revised results section. revision: yes
Circularity Check
Empirical benchmark study with no derivations or self-referential reductions
full rationale
The paper presents MemTrace as an empirical benchmark that evaluates 13 memory-system configurations on external LLM agents by measuring outcomes across three probing dimensions. All reported results, including the 10x retrievable-vs-missing ratio and claims about evidence use as the dominant bottleneck, are direct aggregates of evaluation data rather than outputs of equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing step reduces by construction to the paper's own inputs, and the work contains no mathematical derivations, ansatzes, or uniqueness theorems.
Axiom & Free-Parameter Ledger
invented entities (1)
-
knowledge point
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
Memory in the Age of AI Agents , author=. 2026 , eprint=
2026
-
[2]
2026 , eprint=
Rethinking Memory Mechanisms of Foundation Agents in the Second Half: A Survey , author=. 2026 , eprint=
2026
-
[3]
2026 , eprint =
HaluMem: Evaluating Hallucinations in Memory Systems of Agents , author =. 2026 , eprint =
2026
-
[4]
Hu, Yuyang and others , year =. Memory in the Age of. 2512.13564 , archivePrefix =
-
[5]
2026 , eprint =
Evaluating Long-Horizon Memory for Multi-Party Collaborative Dialogues , author =. 2026 , eprint =
2026
-
[6]
2026 , eprint =
From Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents , author =. 2026 , eprint =
2026
-
[7]
2026 , eprint =
Mem2ActBench: A Benchmark for Evaluating Long-Term Memory Utilization in Task-Oriented Autonomous Agents , author =. 2026 , eprint =
2026
-
[8]
2026 , eprint =
EMemBench: Interactive Benchmarking of Episodic Memory for VLM Agents , author =. 2026 , eprint =
2026
-
[9]
2026 , eprint =
Beyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs , author =. 2026 , eprint =
2026
-
[10]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , booktitle =. Evaluating Very Long-Term Conversational Memory of. 2024 , publisher =
2024
-
[11]
International Conference on Learning Representations , year =
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , author =. International Conference on Learning Representations , year =
-
[12]
2024 , eprint =
PerLTQA: A Personal Long-Term Memory Dataset for Memory Classification, Retrieval, and Synthesis in Question Answering , author =. 2024 , eprint =
2024
-
[13]
Jiang, Bowen and Hao, Zhuoqun and Cho, Young-Min and Li, Bryan and Yuan, Yuan and Chen, Sihao and Ungar, Lyle and Taylor, Camillo J. and Roth, Dan , year =. Know Me, Respond to Me: Benchmarking. 2504.14225 , archivePrefix =
-
[14]
Zhao, Siyan and Hong, Mingyi and Liu, Yang and Hazarika, Devamanyu and Lin, Kaixiang , booktitle =. Do
-
[15]
Hu, Yuanzhe and Wang, Yu and McAuley, Julian , year =. Evaluating Memory in. 2507.05257 , archivePrefix =
-
[16]
Tan, Haoran and Zhang, Zeyu and Ma, Chen and Chen, Xu and Dai, Quanyu and Dong, Zhenhua , booktitle =. 2025 , publisher =. doi:10.18653/v1/2025.findings-acl.989 , url =
-
[17]
Ai, Qingyao and Tang, Yichen and Wang, Changyue and Long, Jianming and Su, Weihang and Liu, Yiqun , year =. 2510.17281 , archivePrefix =
-
[18]
Mem0: Building Production-Ready
Chhikara, Prateek and Khant, Dev and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj , year =. Mem0: Building Production-Ready. 2504.19413 , archivePrefix =
-
[19]
2024 , eprint =
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , author =. 2024 , eprint =
2024
-
[20]
MIRIX: Multi-Agent Memory System for
Wang, Yu and Chen, Xi , year =. MIRIX: Multi-Agent Memory System for. 2507.07957 , archivePrefix =
-
[21]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and Li, Tianle and Ku, Max and Wang, Kai and Zhuang, Alex and Fan, Rongqi and Yue, Xiang and Chen, Wenhu , year =. doi:10.48550/arXiv.2406.01574 , note =. 2406.01574 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.01574
-
[22]
doi:10.48550/arXiv.2410.02694 , note =
Yen, Howard and Gao, Tianyu and Hou, Minmin and Ding, Ke and Fleischer, Daniel and Izsak, Peter and Wasserblat, Moshe and Chen, Danqi , year =. doi:10.48550/arXiv.2410.02694 , note =. 2410.02694 , archivePrefix =
-
[23]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Mirzadeh, Iman and Alizadeh, Keivan and Shahrokhi, Hooman and Tuzel, Oncel and Bengio, Samy and Farajtabar, Mehrdad , year =. doi:10.48550/arXiv.2410.05229 , note =. 2410.05229 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.05229
-
[24]
MEMTRACK: Evaluating Long-Term Memory and State Tracking in Multi-Platform Dynamic Agent Environments , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.01353 , note =
-
[25]
A-MEM: Agentic Memory for LLM Agents
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng , year =. A-MEM: Agentic Memory for. doi:10.48550/arXiv.2502.12110 , note =. 2502.12110 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.12110
-
[26]
2026 , eprint =
Shu, Yiheng and Jonnalagedda, Saisri Padmaja and Gao, Xiang and Jim. 2026 , eprint =
2026
-
[27]
Liu, Jiaqi and Su, Yaofeng and Xia, Peng and Han, Siwei and Zheng, Zeyu and Xie, Cihang and Ding, Mingyu and Yao, Huaxiu , year =. 2601.02553 , archivePrefix =
-
[28]
2025 , eprint =
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author =. 2025 , eprint =
2025
-
[29]
The Probabilistic Relevance Framework:
Robertson, Stephen and Zaragoza, Hugo , journal =. The Probabilistic Relevance Framework:. 2009 , doi =
2009
-
[30]
2024 , howpublished =
New Embedding Models and. 2024 , howpublished =
2024
-
[31]
2025 , howpublished =
Introducing. 2025 , howpublished =
2025
-
[32]
Chao, Hanxiang and Bai, Yihan and Sheng, Rui and Li, Tianle and Sun, Yushi , year =. 2605.06527 , archivePrefix =
-
[33]
Wang, Shu and Yu, Edwin and Love, Oscar and Zhang, Tom and Wong, Tom and Scargall, Steve and Fan, Charles , year =. 2604.04853 , archivePrefix =
-
[34]
Li, Shuyue Stella and Paranjape, Bhargavi and Oktar, Kerem and Ma, Zhongyao and Zhou, Gelin and Guan, Lin and Zhang, Na and Park, Sem and Chen, Lin and Yang, Diyi and Tsvetkov, Yulia and Celikyilmaz, Asli , year =. 2604.17283 , archivePrefix =
-
[35]
Zhao, Yujie and Yuan, Boqin and Huang, Junbo and Yuan, Haocheng and Yu, Zhongming and Xu, Haozhou and Hu, Lanxiang and Shankarampeta, Abhilash and Huang, Zimeng and Ni, Wentao and Tian, Yuandong and Zhao, Jishen , year =. 2602.22769 , archivePrefix =
-
[36]
2026 , eprint =
Anatomy of Agentic Memory: Taxonomy and Empirical Analysis of Evaluation and System Limitations , author =. 2026 , eprint =
2026
- [37]
-
[38]
Jim. From. 2025 , eprint =
2025
-
[39]
Yue, Yanwei and Zhang, Guibin and Peng, Boci and Fan, Xuanbo and Guo, Jiaxin and Li, Qiankun and Zhang, Yan , year =. 2601.23014 , archivePrefix =
-
[40]
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , year =. 2308.14508 , archivePrefix =
-
[41]
Zhang, Xinrong and Chen, Yingfa and Hu, Shengding and Xu, Zihang and Chen, Junhao and Hao, Moo and Han, Xu and Thai, Zhen and Wang, Shuo and Liu, Zhiyuan and Sun, Maosong , year =. 2402.13718 , archivePrefix =
-
[42]
Hsieh, Cheng-Ping and Sun, Simeng and Kriman, Samuel and Acharya, Shantanu and Rekesh, Dima and Jia, Fei and Zhang, Yang and Ginsburg, Boris , year =. 2404.06654 , archivePrefix =
-
[43]
Bai, Yushi and Tu, Shangqing and Zhang, Jiajie and Peng, Hao and Cui, Xiaozhi and Wang, Xin and Lv, Xin and Cao, Shulin and Xu, Jiazheng and Liu, Lei and Wang, Zhen and Lv, Chaoyue and Zhang, Yichuan and Liu, Xu and Liu, Xiao and Wang, Yang and Zhang, Ge and Wong, Ka-Hei and Han, Pengcheng and Wang, Chenglei and Chen, Wengyu and Nie, Jian-Yun and Tang, Ji...
-
[44]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and Kuttler, Heinrich and Lewis, Mike and Yih, Wen-tau and Rockt. Retrieval-Augmented Generation for Knowledge-Intensive. 2020 , eprint =
2020
-
[45]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , year =. Self-. 2310.11511 , archivePrefix =
-
[46]
2023 , eprint =
Generative Agents: Interactive Simulacra of Human Behavior , author =. 2023 , eprint =
2023
-
[47]
and Lin, Kevin and Wooders, Sarah and Gonzalez, Joseph E
Packer, Charles and Fang, Vivian and Patil, Shishir G. and Lin, Kevin and Wooders, Sarah and Gonzalez, Joseph E. , year =. 2310.08560 , archivePrefix =
-
[48]
Wang, Weizhi and Dong, Li and Cheng, Hao and Liu, Xiaodong and Yan, Xifeng and Gao, Jianfeng and Wei, Furu , year =. 2306.07174 , archivePrefix =
-
[49]
2023 , eprint =
Modarressi, Ali and Imani, Ayyoob and Fayyaz, Mohsen and Sch. 2023 , eprint =
2023
-
[50]
and Si, Yanjun and Zhang, Ruiyi and Derr, Tyler , year =
Wang, Yu and Lipka, Nedim and Rossi, Ryan A. and Si, Yanjun and Zhang, Ruiyi and Derr, Tyler , year =. 2402.04624 , archivePrefix =
-
[51]
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , year =. 2305.10250 , archivePrefix =
-
[52]
Bian, Haonan and Yao, Zhiyuan and Hu, Sen and Xu, Zishan and Zhang, Shaolei and Guo, Yifu and Yang, Ziliang and Han, Xueran and Wang, Huacan and Chen, Ronghao , year =. 2601.06966 , archivePrefix =
-
[53]
Deng, Xinle and Xue, Yida and Chen, Yijun and Mao, Mingjun and Zhong, Ruobin and Xu, Buqiang and Fang, Jizhan and Xu, Haoming and Wu, Tingwei and Xu, Yajing and Deng, Shumin and Wang, Haofen and Chen, Huajun and Zhang, Ningyu , year =
-
[54]
Beyond Goldfish Memory: Long-Term Open-Domain Conversation
Beyond Goldfish Memory: Long-Term Open-Domain Conversation , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2022 , publisher =. doi:10.18653/v1/2022.acl-long.356 , url =
-
[55]
Kim, Jiho and Chay, Woosog and Hwang, Hyeonji and Kyung, Daeun and Chung, Hyunseung and Cho, Eunbyeol and Kwon, Yeonsu and Jo, Yohan and Choi, Edward , year =. 2406.13144 , archivePrefix =
-
[56]
Chen, Tiantian and Lu, Jiaqi and Shen, Ying and Zhang, Lin , year =. 2602.01885 , archivePrefix =
-
[57]
Li, Yifei and Guo, Weidong and Zhang, Lingling and Xu, Rongman and Huang, Muye and Liu, Hui and Xu, Lijiao and Xu, Yu and Liu, Jun , year =. 2602.10715 , archivePrefix =
-
[58]
Evaluating Memory Structure in
Shutova, Alina and Olenina, Alexandra and Vinogradov, Ivan and Sinitsin, Anton , year =. Evaluating Memory Structure in. 2602.11243 , archivePrefix =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.