Bifrost: Hybrid TEE-FHE Inference for Privacy-Preserving Transformer and LLM Serving
Pith reviewed 2026-06-27 00:54 UTC · model grok-4.3
The pith
Bifrost splits LLM inference so CPU TEE handles non-linear parts while FHE on accelerators runs linear layers, cutting projected latency by nearly 10x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
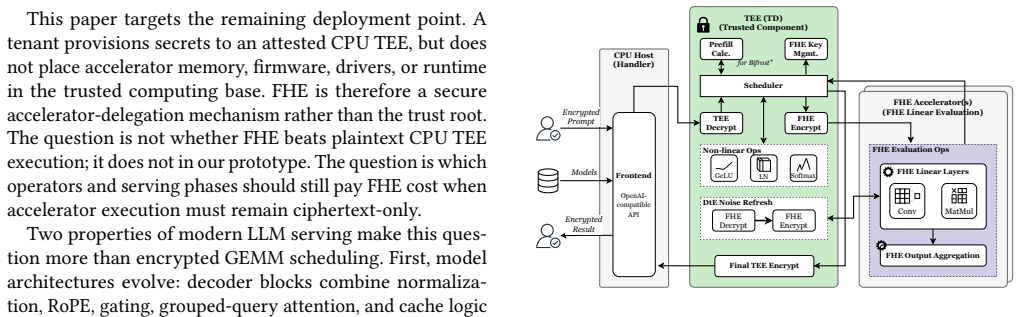
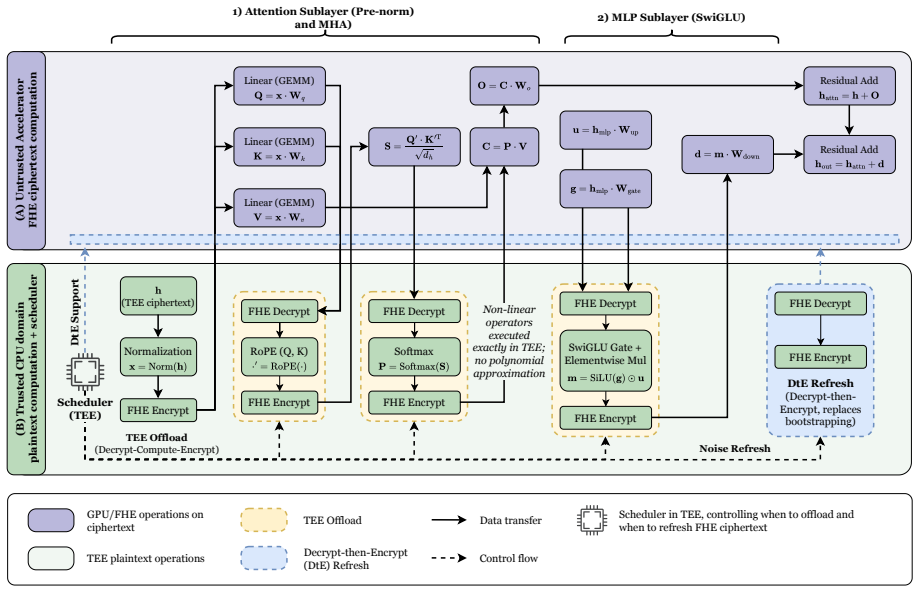
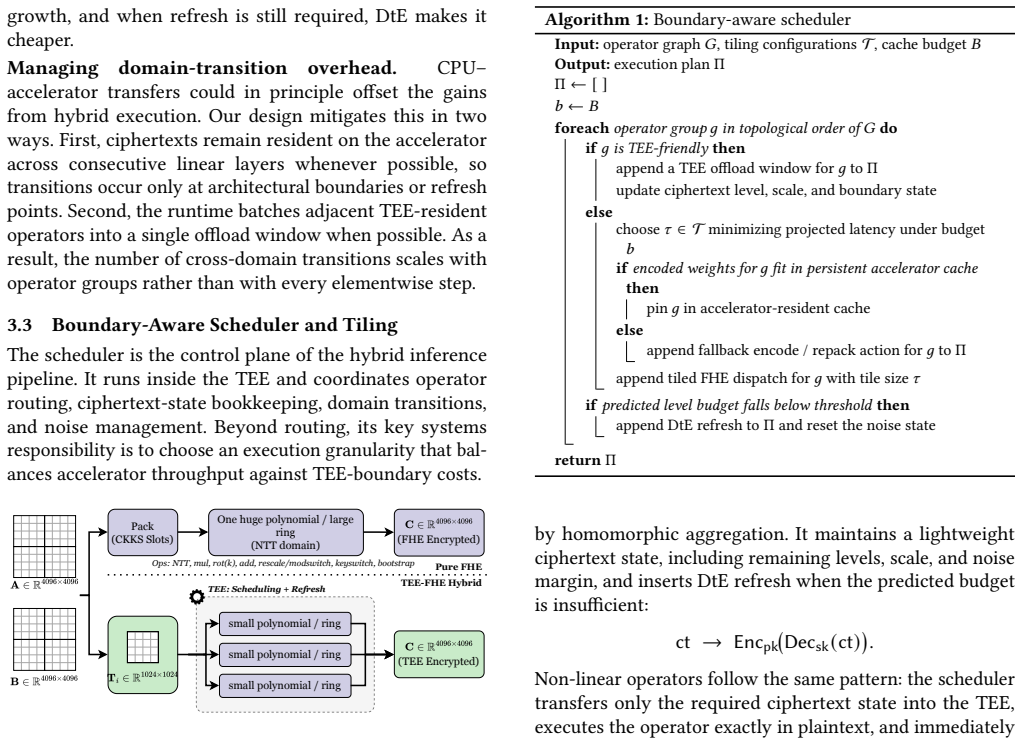
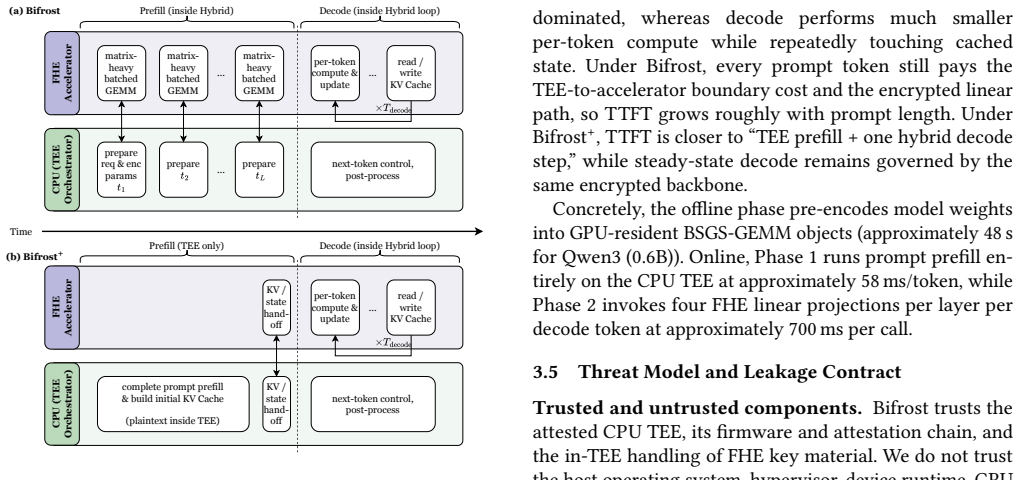
Bifrost provisions secrets only to an attested CPU TEE, while the accelerator, device memory, driver/runtime stack, and host software remain outside the trusted computing base. It uses FHE as a secure delegation mechanism for projection and feed-forward linear layers on accelerator-backed CKKS, while non-linear operators, attention-side control logic, KV-state transitions, and decrypt-then-encrypt refresh execute inside the CPU TEE. Bifrost+ further applies a prefill/decode split: prompt-side KV state is built inside the CPU TEE, and only decode-side state enters the hybrid ciphertext path. In an estimator-style comparison matching prior methodology, Bifrost reduces projected latency by 9.25
What carries the argument
Selective encrypted execution that delegates only linear layers to FHE on accelerators while executing non-linear operators, attention logic, and KV-state transitions inside the CPU TEE.
If this is right
- Linear layers execute on untrusted accelerators without exposing plaintext data to the full software stack.
- Non-linear and stateful operations remain protected inside the CPU TEE without full-model encryption cost.
- The prefill/decode split in Bifrost+ keeps prompt-side KV state out of the slower ciphertext path.
- End-to-end private inference becomes feasible for models up to 8B parameters under the reported speedups.
- The architecture maintains the same security boundary as a pure TEE while adding accelerator participation for linear work.
Where Pith is reading between the lines
- Similar layer-type splits could be tested on other model families such as diffusion or multimodal networks to check generality.
- The hybrid boundary may influence hardware designs that expose tighter TEE-FHE interfaces on future accelerators.
- Longer context lengths would likely amplify the benefit of keeping KV-state management inside the TEE.
- Deployment on multi-tenant clouds could reduce the trusted computing base size compared with full-TEE accelerator solutions.
Load-bearing premise
The performance improvements measured through estimator-style comparisons accurately reflect real hardware behavior without unaccounted security or runtime overheads.
What would settle it
A full hardware implementation of Bifrost on GPT-2 (1.5B) that shows latency reduction below 5x would indicate the projections do not hold in practice.
Figures

read the original abstract
Cloud-hosted transformer and large language model (LLM) inference creates a direct confidentiality problem: user prompts may contain sensitive code, business data, personal information, or regulated documents, yet remote serving exposes intermediate state to the cloud software stack and accelerator runtime. Fully homomorphic encryption (FHE) keeps accelerator-side execution ciphertext-only, but end-to-end LLM inference remains expensive because linear layers are interleaved with non-linear, cache-state, and refresh-sensitive operators. CPU trusted execution environments (TEEs) can execute those operators natively, but a CPU TEE alone does not define how an untrusted accelerator should participate. We present Bifrost, a hybrid TEE-FHE serving architecture in which secrets are provisioned only to an attested CPU TEE, while the accelerator, device memory, driver/runtime stack, and host software remain outside the trusted computing base. Bifrost uses FHE as a secure delegation mechanism for projection and feed-forward linear layers on accelerator-backed CKKS, while non-linear operators, attention-side control logic, KV-state transitions, and decrypt-then-encrypt refresh execute inside the CPU TEE. Bifrost+ further applies a prefill/decode split: prompt-side KV state is built inside the CPU TEE, and only decode-side state enters the hybrid ciphertext path. In an estimator-style comparison matching Euston's methodology, Bifrost reduces projected latency by 9.25x on GPT-2 (1.5B) and 9.91x on LLaMA 3 (8B). In direct CKKS/FHE deployments, Bifrost+ reduces TTFT by 14.6-45.8x on GPT-2 (124M) and 15.3-53.4x on Qwen3 (0.6B). The systems lesson is selective encrypted execution: use FHE only where ciphertext-only accelerator delegation is required, and keep non-linear, refresh, and prompt-side work inside the CPU TEE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Bifrost, a hybrid TEE-FHE architecture for privacy-preserving transformer and LLM inference. Secrets are provisioned only to an attested CPU TEE; linear layers (projection and feed-forward) are delegated to accelerator-backed CKKS FHE, while non-linear operators, attention control logic, KV-state transitions, and decrypt-then-encrypt refresh execute inside the TEE. Bifrost+ adds a prefill/decode split with prompt-side KV built in the TEE. Using an estimator-style comparison matching Euston’s methodology, the paper reports projected latency reductions of 9.25× on GPT-2 (1.5B) and 9.91× on LLaMA 3 (8B), plus TTFT reductions of 14.6–53.4× on smaller models in direct CKKS/FHE settings. The central systems lesson is selective encrypted execution.
Significance. If the projections are shown to be accurate, the selective-hybrid design would represent a practical advance for confidential LLM serving by limiting FHE to linear layers where ciphertext-only accelerator delegation is required and retaining non-linear and stateful work in the TEE. This addresses a recognized gap between pure-FHE cost and pure-TEE trust boundaries. The manuscript does not ship machine-checked proofs or end-to-end reproducible measurements, so the significance assessment remains conditional on future validation of the estimator.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation (implied by performance claims): the reported speedups (9.25× GPT-2 1.5B, 9.91× LLaMA-3 8B; 14.6–53.4× TTFT) are produced by an estimator-style comparison rather than measured end-to-end runs of the hybrid system. No quantitative accounting is supplied for TEE-to-accelerator ciphertext handoff latency, attestation overhead, data-movement costs under realistic batch sizes, or refresh frequency; if any of these are under-modeled the central performance claims do not hold.
- [Architecture] Architecture description (Bifrost and Bifrost+): the security argument that the accelerator, device memory, driver/runtime, and host software remain outside the TCB is stated but not accompanied by a concrete reduction showing that the hybrid transitions preserve the claimed confidentiality properties without introducing new side channels or attestation requirements.
minor comments (2)
- [Abstract] The abstract refers to “Euston’s methodology” without a citation or self-contained description of the estimator parameters; a brief appendix or footnote would improve reproducibility.
- [Bifrost+ description] Notation for the prefill/decode split and the exact placement of KV-state transitions is introduced without a diagram or pseudocode; a single figure would clarify the data-flow.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each of the major comments below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation (implied by performance claims): the reported speedups (9.25× GPT-2 1.5B, 9.91× LLaMA-3 8B; 14.6–53.4× TTFT) are produced by an estimator-style comparison rather than measured end-to-end runs of the hybrid system. No quantitative accounting is supplied for TEE-to-accelerator ciphertext handoff latency, attestation overhead, data-movement costs under realistic batch sizes, or refresh frequency; if any of these are under-modeled the central performance claims do not hold.
Authors: We agree that the performance numbers are derived from an estimator-style comparison, consistent with the methodology used in Euston. While the estimator focuses on the primary computational costs of linear layers in FHE versus TEE execution, we acknowledge the absence of explicit quantitative modeling for TEE-to-accelerator handoff latencies, attestation overheads, data-movement costs at scale, and refresh frequencies. In the revised version, we will augment the evaluation section with a detailed sensitivity analysis that incorporates these factors, including estimates based on typical hardware parameters and batch sizes, to provide a more complete picture of the projected performance. revision: yes
-
Referee: [Architecture] Architecture description (Bifrost and Bifrost+): the security argument that the accelerator, device memory, driver/runtime, and host software remain outside the TCB is stated but not accompanied by a concrete reduction showing that the hybrid transitions preserve the claimed confidentiality properties without introducing new side channels or attestation requirements.
Authors: The security model in Bifrost relies on provisioning secrets exclusively to the attested CPU TEE, with FHE ensuring that the accelerator operates only on ciphertexts. We recognize that a more rigorous, concrete security reduction would better substantiate that the hybrid transitions maintain confidentiality without new side channels. In the revision, we will expand the security analysis section to include a step-by-step argument detailing the trust boundaries, the role of attestation, and why the transitions between TEE and FHE components do not introduce additional vulnerabilities beyond the standard assumptions of each technology. revision: yes
Circularity Check
No circularity; performance projections reference external estimator methodology
full rationale
The paper's central claims consist of projected latency and TTFT reductions obtained via an estimator-style comparison that explicitly matches Euston's methodology. No equations, fitted parameters, or uniqueness theorems are defined in terms of the target results. No self-citations are load-bearing for the architecture or performance arguments. The derivation chain is therefore self-contained against the cited external benchmark and does not reduce any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[n. d.]. AMD Secure Encrypted Virtualization (SEV).https://www. amd.com/en/developer/sev.html
-
[2]
[n. d.]. Intel®Trust Domain Extensions (Intel®TDX). https://www.intel.com/content/www/us/en/developer/tools/trust- domain-extensions/overview.html
-
[3]
Rashmi Agrawal, Leo de Castro, Guowei Yang, Chiraag Juvekar, Rabia Yazicigil, Anantha Chandrakasan, Vinod Vaikuntanathan, and Ajay Joshi. 2023. FAB: An FPGA-based Accelerator for Bootstrappable Fully Homomorphic Encryption. In2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 882–895. doi:10. 1109/HPCA56546.2023.10070953
arXiv 2023
-
[4]
Asra Ali, Jaeho Choi, Bryant Gipson, Shruthi Gorantala, Jeremy Kun, Wouter Legiest, Lawrence Lim, Alexander Viand, Meron Zerihun Demissie, and Hongren Zheng. 2025. HEIR: A Universal Compiler for Homomorphic Encryption. arXiv:2508.11095 [cs.CR]https://arxiv. org/abs/2508.11095
arXiv 2025
-
[5]
Roman Bredehoft and Jordan Frery. 2025. Towards Encrypted Large Language Models with FHE. https://huggingface.co/blog/encrypted- llm
2025
-
[6]
Jung Hee Cheon, Andrey Kim, Miran Kim, and Yongsoo Song. 2017. Homomorphic Encryption for Arithmetic of Approximate Numbers. InAdvances in Cryptology – ASIACRYPT 2017, Tsuyoshi Takagi and Thomas Peyrin (Eds.). Springer International Publishing, Cham, 409–
2017
-
[7]
doi:10.1007/978-3-319-70694-8_15
-
[8]
Marcin Chrapek, Marcin Copik, Etienne Mettaz, and Torsten Hoefler
-
[9]
Confidential LLM Inference: Performance and Cost Across CPU 12 and GPU TEEs. In2025 IEEE International Symposium on Workload Characterization (IISWC). 84–98. doi:10.1109/IISWC66894.2025.00017
-
[10]
Ali Şah Özcan and Erkay Savaş. 2024. HEonGPU: a GPU-based Fully Homomorphic Encryption Library 1.0. Cryptology ePrint Archive, Paper 2024/1543.https://eprint.iacr.org/2024/1543
2024
-
[11]
Leo De Castro, Daniel Escudero, Adya Agrawal, Antigoni Polychroni- adou, and Manuela Veloso. 2025. EncryptedLLM: Privacy-Preserving Large Language Model Inference via GPU-Accelerated Fully Homo- morphic Encryption. InProceedings of the 42nd International Confer- ence on Machine Learning (Proceedings of Machine Learning Research, Vol. 267), Aarti Singh, Ma...
2025
-
[12]
Xianglong Deng, Shengyu Fan, Zhicheng Hu, Zhuoyu Tian, Zihao Yang, Jiangrui Yu, Dingyuan Cao, Dan Meng, Rui Hou, Meng Li, Qian Lou, and Mingzhe Zhang. 2024. Trinity: A General Purpose FHE Accelerator. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). 338–351. doi:10.1109/MICRO61859.2024. 00033
-
[13]
Austin Ebel, Karthik Garimella, and Brandon Reagen. 2025. Orion: A Fully Homomorphic Encryption Framework for Deep Learning. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (ASPLOS ’25). Association for Computing Machinery, New York, NY, USA, 734–749. doi:10.1145/36...
-
[14]
Guang Fan, Mingzhe Zhang, Fangyu Zheng, Shengyu Fan, Tian Zhou, Xianglong Deng, Wenxu Tang, Liang Kong, Yixuan Song, and Shoumeng Yan. 2025. WarpDrive: GPU-Based Fully Homomorphic Encryption Acceleration Leveraging Tensor and CUDA Cores. In2025 IEEE International Symposium on High Performance Computer Archi- tecture (HPCA). 1187–1200. doi:10.1109/HPCA6190...
-
[15]
Shengyu Fan, Xianglong Deng, Liang Kong, Guiming Shi, Guang Fan, Dan Meng, Rui Hou, and Mingzhe Zhang. 2025. FAST:An FHE Accelerator for Scalable-parallelism with Tunable-bit. InProceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25). Association for Computing Machinery, New York, NY, USA, 92–106. doi:10.1145/3695053.3731407
-
[16]
Xinwen Gao, Shaojing Fu, Lin Liu, Zhuotao Liu, Yuchuan Luo, and Yongjun Wang. 2026. Euston: Efficient and User-Friendly Secure Transformer Inference with Non-Interactivity. In2026 IEEE Sympo- sium on Security and Privacy (SP). IEEE Computer Society, 899–918. doi:10.1109/SP63933.2026.00048
-
[17]
Craig Gentry. 2009. Fully Homomorphic Encryption Using Ideal Lat- tices. InProceedings of the Forty-First Annual ACM Symposium on Theory of Computing (STOC ’09). Association for Computing Machin- ery, New York, NY, USA, 169–178. doi:10.1145/1536414.1536440
-
[18]
Dian Jiao, Xianglong Deng, Zhiwei Wang, Shengyu Fan, Yi Chen, Dan Meng, Rui Hou, and Mingzhe Zhang. 2025. Neo: Towards Efficient Fully Homomorphic Encryption Acceleration Using Tensor Core. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25). Association for Computing Machinery, New York, NY, USA, 107–121. doi:10....
-
[19]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[20]
InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23)
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23). ACM, 611–626. doi:10.1145/ 3600006.3613165
-
[21]
Ryan Lehmkuhl, Pratyush Mishra, Akshayaram Srinivasan, and Raluca Ada Popa. 2021. Muse: Secure Inference Resilient to Mali- cious Clients. In30th USENIX Security Symposium (USENIX Security 21). 2201–2218
2021
-
[22]
Wen-jie Lu, Zhicong Huang, Zhen Gu, Jingyu Li, Jian Liu, Cheng Hong, Kui Ren, Tao Wei, and Wenguang Chen. 2025. BumbleBee: Secure Two-party Inference Framework for Large Transformers. In 32nd Annual Network and Distributed System Security Symposium, NDSS 2025. The Internet Society
2025
-
[23]
Jianan Mu, Husheng Han, Shangyi Shi, Jing Ye, Zizhen Liu, Shengwen Liang, Meng Li, Mingzhe Zhang, Song Bian, Xing Hu, Huaiwei Li, and Xiaowei Li. 2024. Alchemist: A Unified Accelerator Architecture for Cross-Scheme Fully Homomorphic Encryption. InProceedings of the 61st ACM/IEEE Design Automation Conference (DAC ’24). Association for Computing Machinery, ...
arXiv 2024
-
[24]
Qi Pang, Jinhao Zhu, Helen Möllering, Wenting Zheng, and Thomas Schneider. 2024. BOLT: Privacy-Preserving, Accurate and Efficient Inference for Transformers. In2024 IEEE Symposium on Security and Privacy (SP). 4753–4771. doi:10.1109/SP54263.2024.00130
-
[25]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. InProceedings of the 51st Annual International Symposium on Computer Architecture (ISCA ’24). ACM, 118–132. doi:10.1145/3620665.3640401
-
[26]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. (2019)
2019
-
[27]
Qwen Team. 2026. Qwen3.5: Accelerating Productivity with Native Multimodal Agents.https://qwen.ai/blog?id=qwen3.5
2026
-
[28]
Qifan Wang and David Oswald. 2026. Confidential Computing on Heterogeneous CPU-GPU Systems: Survey and Future Directions. Comput. Surveys58, 9 (Feb. 2026), 230:1–230:35. doi:10.1145/3793532
-
[29]
Qifan Wang, Lei Zhou, Jianli Bai, Yun Sing Koh, Shujie Cui, and Gio- vanni Russello. 2023. HT2ML: An Efficient Hybrid Framework for Privacy-Preserving Machine Learning Using HE and TEE.Computers & Security135 (Dec. 2023), 103509. doi:10.1016/j.cose.2023.103509
-
[30]
Wenhao Wang, Yichen Jiang, Qintao Shen, Weihao Huang, Hao Chen, Shuang Wang, XiaoFeng Wang, Haixu Tang, Kai Chen, Kristin Lauter, and Dongdai Lin. 2019. Toward Scalable Fully Homo- morphic Encryption Through Light Trusted Computing Assistance. arXiv:1905.07766 [cs] doi:10.48550/arXiv.1905.07766
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1905.07766 2019
-
[31]
Tianshi Xu, Wen-jie Lu, Jiangrui Yu, Yi Chen, Chenqi Lin, Runsheng Wang, and Meng Li. 2025. Breaking the layer barrier: remodeling private transformer inference with hybrid CKKS and MPC. InProceed- ings of the 34th USENIX Conference on Security Symposium(Seattle, WA, USA)(SEC ’25). USENIX Association, USA, Article 137, 20 pages
2025
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[33]
Xingkai Yu. 2026. GeeeekExplorer/Nano-Vllm
2026
-
[34]
Jiawen Zhang, Xinpeng Yang, Lipeng He, Kejia Chen, Wen-jie Lu, Yinghao Wang, Xiaoyang Hou, Jian Liu, Kui Ren, and Xiaohu Yang
-
[35]
InPro- ceedings 2025 Network and Distributed System Security Symposium
Secure Transformer Inference Made Non-interactive. InPro- ceedings 2025 Network and Distributed System Security Symposium. Internet Society, San Diego, CA, USA. doi:10.14722/ndss.2025.230868 13
-
[36]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). USENIX Association, 193–210. 14 A Generalization The architecture is b...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.