Non-negative Matrix Factorisation with Topological Regularisation
Pith reviewed 2026-06-27 01:24 UTC · model grok-4.3
The pith
Persistent homology supplies stable topological scores that regularise non-negative matrix factorisation without thresholds or discreteness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
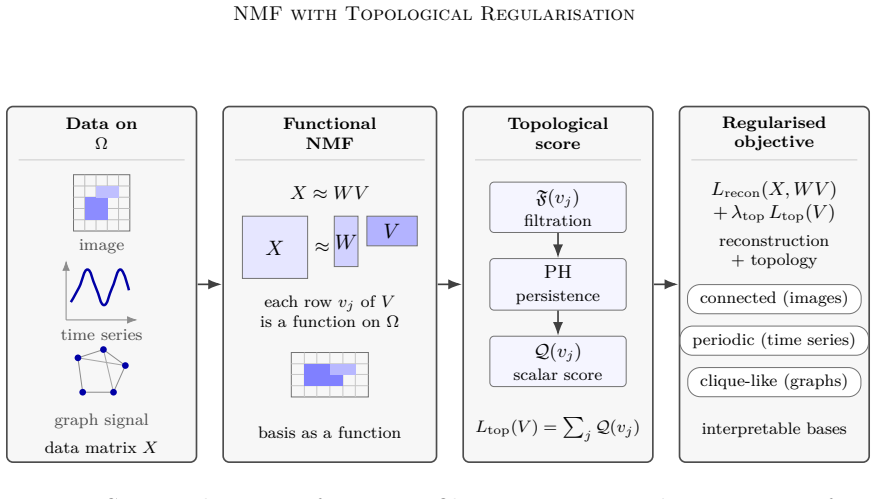
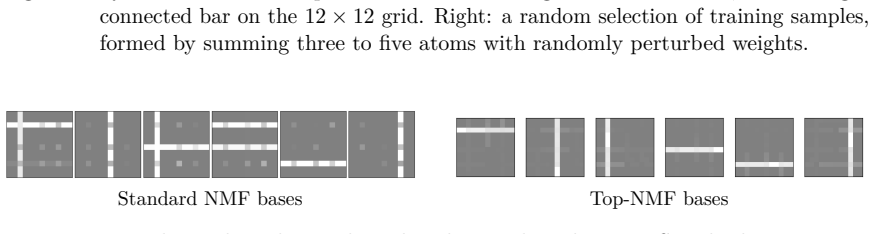
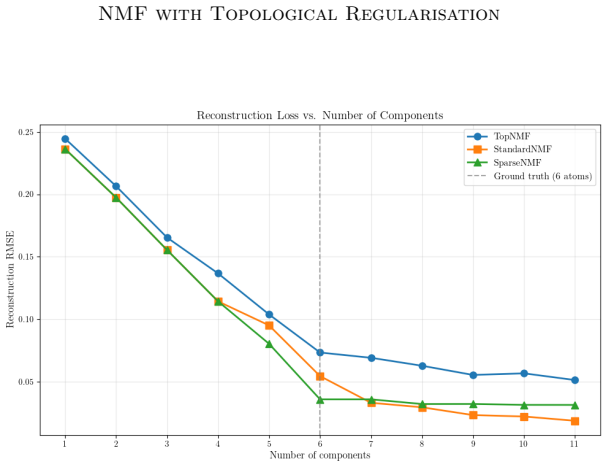
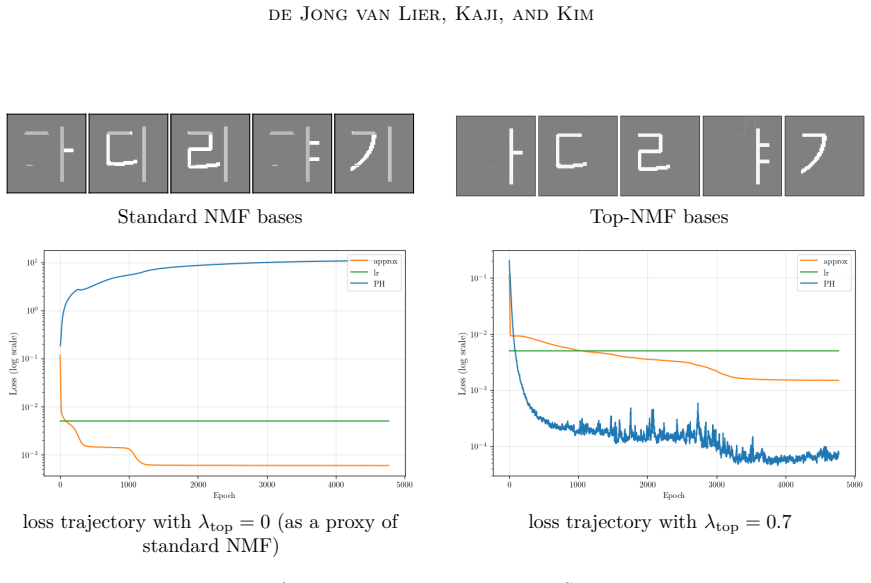
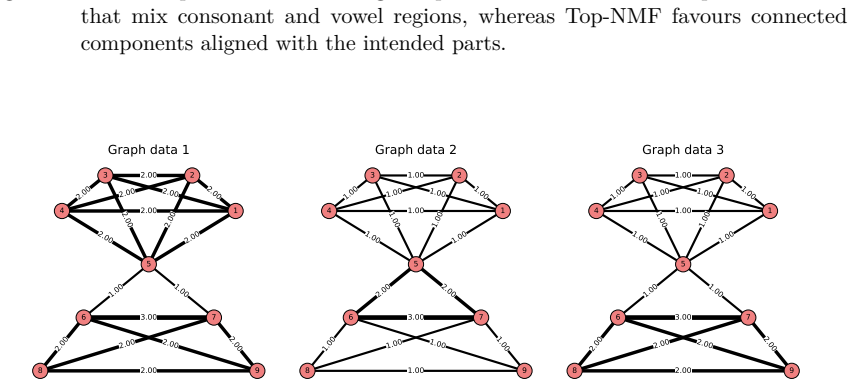
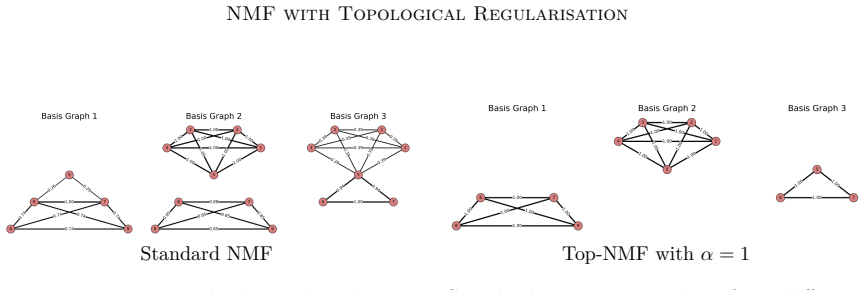
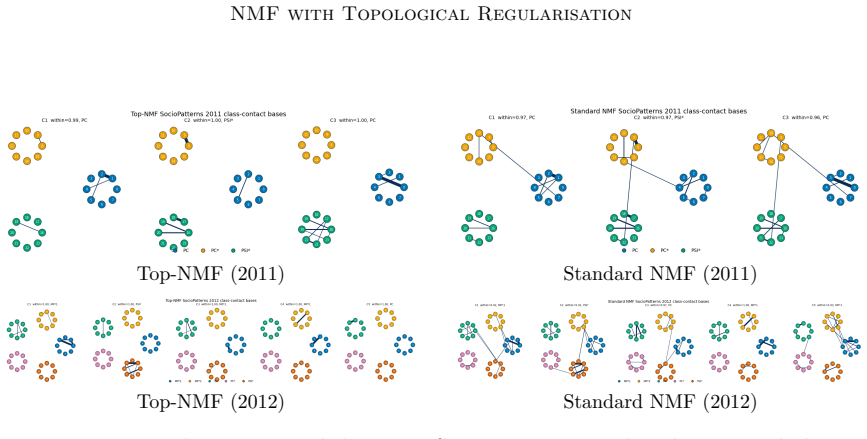
We employ persistent homology as a stable, threshold-free topological quantifier and design topological scores that integrate into the NMF objective as regularisers. The resulting framework encompasses spatially coherent image components, periodic time-series structures, and clique-like graph signals within a unified modelling language.
What carries the argument
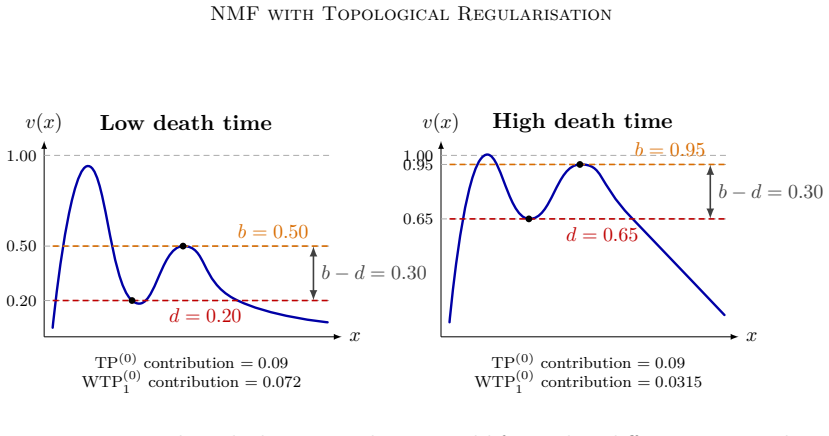
Persistent homology computed on the support of each basis function, converted into differentiable regularisation terms added to the NMF loss.
If this is right
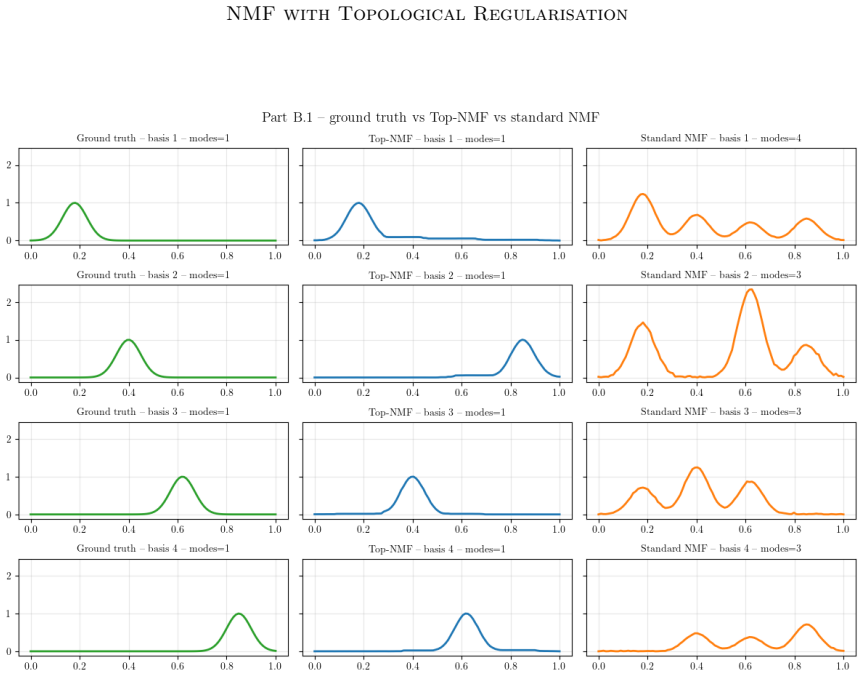
- Spatially coherent components emerge for image data without extra post-processing.
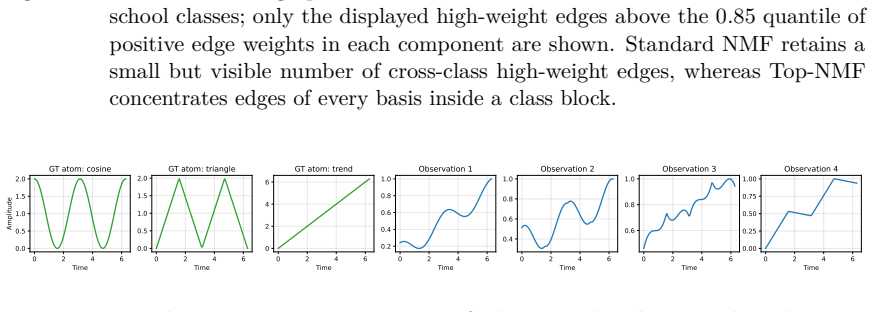
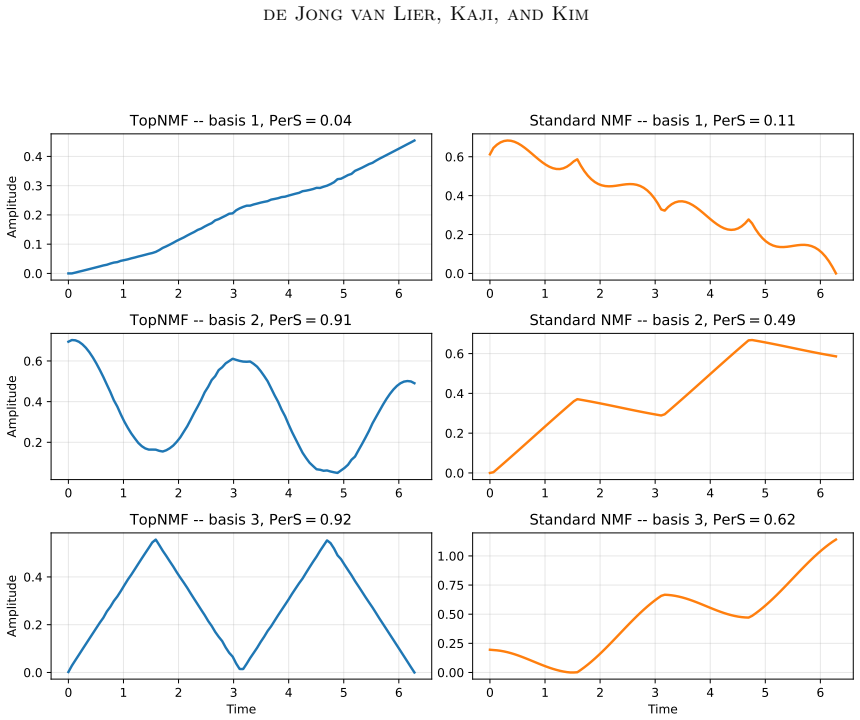
- Periodic structures are favoured in time-series factorisation.
- Clique-like signals are recovered in graph-valued data.
- All three cases are handled by the same regularisation term inside one optimisation loop.
Where Pith is reading between the lines
- The same regulariser could be dropped into other non-negative decompositions such as topic models.
- Synthetic benchmarks with controlled topology would isolate how much each persistent-homology feature contributes.
- The approach might reduce the need for hand-crafted smoothness penalties in domains where topology is the dominant prior.
Load-bearing premise
The topology of a basis function's support is intrinsically linked to the quality of that basis in a way that persistent homology scores can measure and enforce during continuous optimisation.
What would settle it
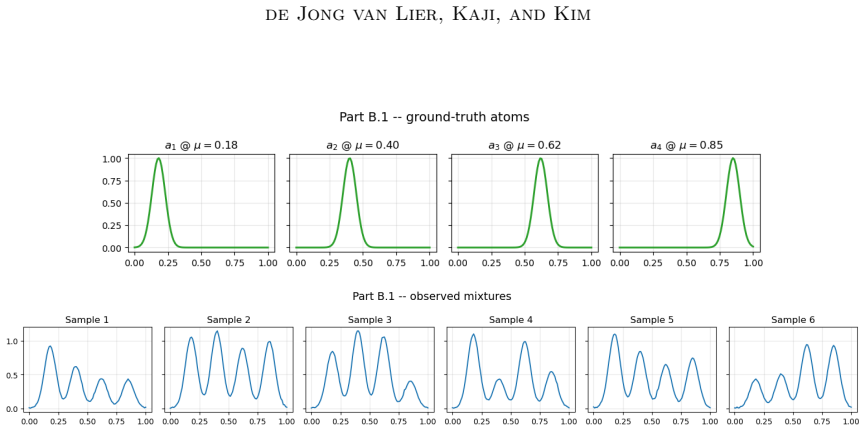
Run the regularised NMF on a dataset whose ground-truth bases have known topology; if the learned bases show no improvement in topological fidelity or reconstruction quality over plain NMF, the claim fails.
Figures



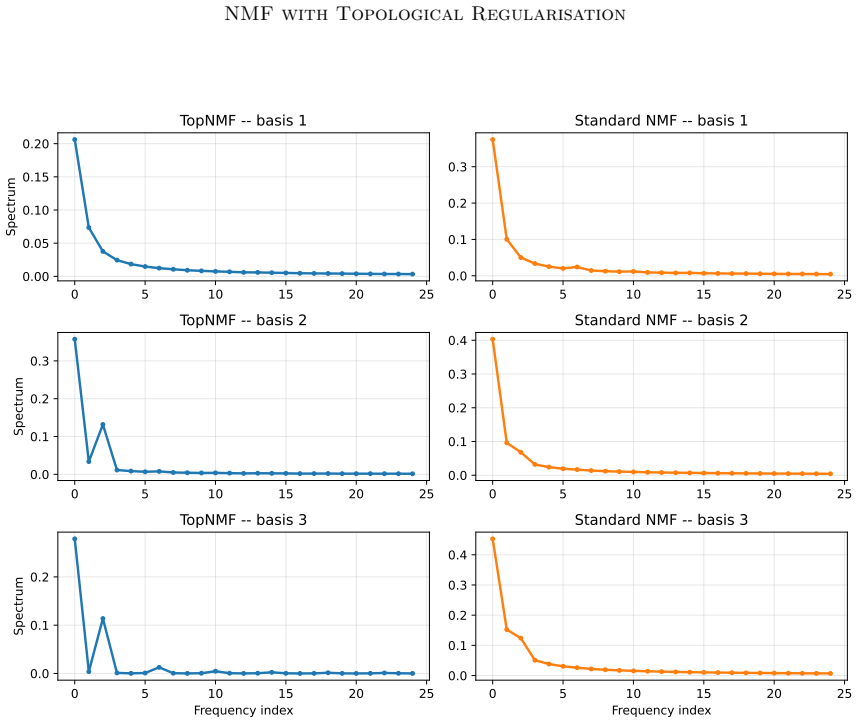
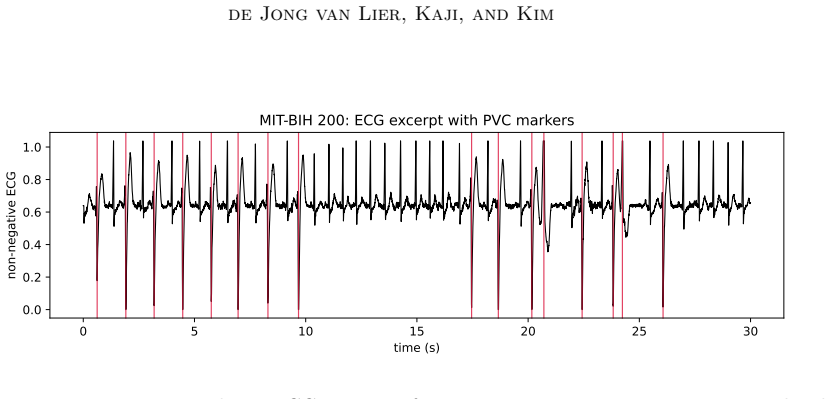
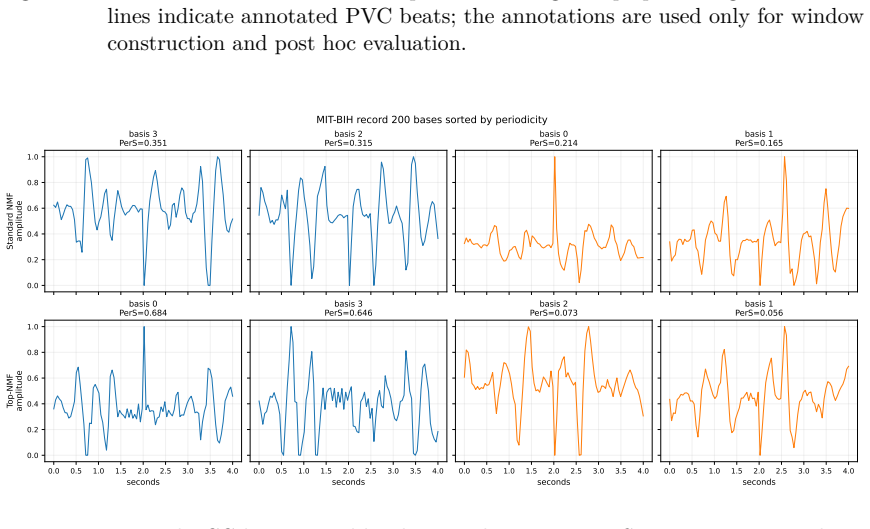
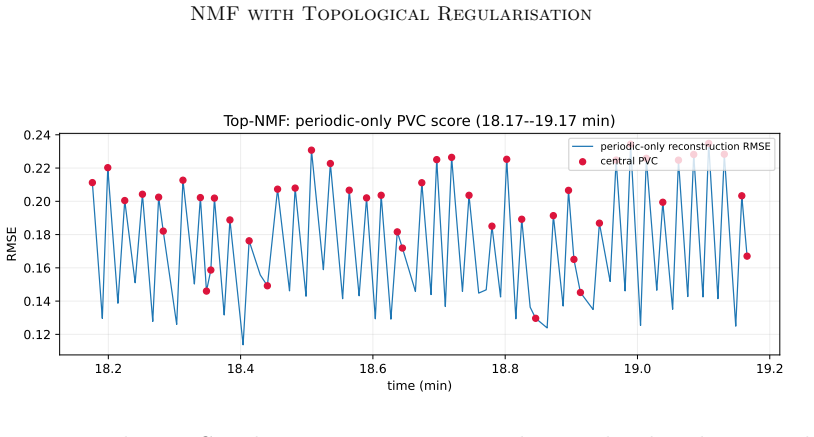
read the original abstract
We investigate the learning of interpretable bases in non-negative matrix factorisation (NMF) by regularising the topology of the learned basis functions. Our approach is motivated by the observation that many data modalities can be viewed as non-negative functions on a structured domain, where the quality of a basis is intrinsically linked to its topology. However, naive methods for incorporating the topology of the support are often hindered by discreteness and threshold dependence, rendering them unsuitable for continuous optimisation. We address these challenges by employing persistent homology as a stable, threshold-free topological quantifier and by designing topological scores that integrate into the NMF objective as regularisers. The resulting framework encompasses spatially coherent image components, periodic time-series structures, and clique-like graph signals within a unified modelling language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes integrating persistent homology into the NMF objective as regularizers to enforce topological properties (spatial coherence for images, periodicity for time series, clique structure for graphs) on the learned non-negative basis functions. The central claim is that persistent homology supplies a stable, threshold-free topological quantifier that can be turned into differentiable scores suitable for gradient-based optimization of the factorization.
Significance. If the claimed differentiable topological scores can be constructed without reintroducing effective thresholds or extra hyperparameters, the work would supply a unified modelling language for topology-aware NMF across modalities. The absence of any parameter-free derivation or machine-checked verification in the supplied abstract, however, leaves the practical utility of the framework unestablished.
major comments (2)
- [Abstract] Abstract (and §3–4, assuming standard placement of the loss): the claim that the topological scores are 'threshold-free' and 'integrate into the NMF objective' is load-bearing for the central contribution, yet the abstract supplies neither the explicit regularizer term nor its gradient with respect to the basis matrix. Without this construction it is impossible to verify that the persistent-homology approximation remains compatible with continuous optimisation.
- [Abstract] The weakest assumption identified in the stress-test note is not discharged by the abstract: standard persistent homology is combinatorial; any practical regulariser must employ an approximation whose stability under perturbation of the basis functions is demonstrated. No such verification (e.g., Lipschitz bound on the score or empirical gradient check) appears in the provided text.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the framework.
read point-by-point responses
-
Referee: [Abstract] Abstract (and §3–4, assuming standard placement of the loss): the claim that the topological scores are 'threshold-free' and 'integrate into the NMF objective' is load-bearing for the central contribution, yet the abstract supplies neither the explicit regularizer term nor its gradient with respect to the basis matrix. Without this construction it is impossible to verify that the persistent-homology approximation remains compatible with continuous optimisation.
Authors: We agree that the abstract, as a concise summary, does not include the explicit regularizer expression or gradient formula. Sections 3 and 4 of the full manuscript derive the persistent-homology-based topological scores, show their incorporation as differentiable regularizers in the NMF objective, and detail the gradient computation with respect to the basis matrix. To address the concern directly, we will revise the abstract to include a brief statement of the regularizer term and note its differentiability for gradient-based optimization. revision: yes
-
Referee: [Abstract] The weakest assumption identified in the stress-test note is not discharged by the abstract: standard persistent homology is combinatorial; any practical regulariser must employ an approximation whose stability under perturbation of the basis functions is demonstrated. No such verification (e.g., Lipschitz bound on the score or empirical gradient check) appears in the provided text.
Authors: We acknowledge that neither the abstract nor the current text provides an explicit stability analysis such as a Lipschitz bound or empirical gradient check. The framework relies on differentiable approximations to persistent homology to enable continuous optimization. In the revised version we will add a subsection discussing the stability properties of the scores, including an empirical gradient verification and analysis of the approximation error under perturbations of the basis functions. revision: yes
Circularity Check
No circularity; topological regularisers presented as external inputs to NMF
full rationale
The abstract and provided context describe persistent homology as an independent, stable quantifier imported to regularize the NMF objective, addressing discreteness and threshold issues via new score designs. No equations, self-citations, or fitted parameters are shown reducing the claimed predictions or framework to the inputs by construction. The motivation links topology to basis quality but does not define the regulariser in terms of the NMF result itself. This is the common case of an externally supported addition, warranting score 0 rather than any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Christos Boutsidis and Efstratios Gallopoulos
URLhttps://proceedings.neurips.cc/paper_files/paper/2001/file/ f106b7f99d2cb30c3db1c3cc0fde9ccb-Paper.pdf. Christos Boutsidis and Efstratios Gallopoulos. NNDSVD: Nonnegative matrix factorization based on singular value decomposition.Pattern Recognition, 41(4):1350–1362,
2001
-
[2]
Jean-Philippe Brunet, Pablo Tamayo, Todd R Golub, and Jill P Mesirov
doi: 10.1111/cgf.14079. Jean-Philippe Brunet, Pablo Tamayo, Todd R Golub, and Jill P Mesirov. Metagenes and molecular pattern discovery using matrix factorization.Proceedings of the national academy of sciences, 101(12):4164–4169,
-
[3]
IEEE Tra nsactions on Pattern Analysis and Machine Intelligence 33(8), 1548–1560 (20 11)
doi: 10.1109/TPAMI.2010.231. Mathieu Carriere, Frédéric Chazal, Marc Glisse, Yuichi Ike, Hariprasad Kannan, and Yuhei Umeda. Optimizing persistent homology based functions. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 1294–1303. PMLR,
-
[4]
Damek Davis, Dmitriy Drusvyatskiy, Sham Kakade, and Jason D Lee
doi: 10.1109/MSP.2008.4408452. Damek Davis, Dmitriy Drusvyatskiy, Sham Kakade, and Jason D Lee. Stochastic subgradient method converges on tame functions.Foundations of Computational Mathematics, 20(1): 119–154,
-
[5]
Found Comput Math20, 119–154 (2020) https://doi.org/10.1007/s10208-018-09409-5
doi: 10.1007/s10208-018-09409-5. Tamal Krishna Dey and Yusu Wang.Computational topology for data analysis. Cambridge University Press,
-
[6]
Herbert Edelsbrunner and John Harer
URLhttps://proceedings.neurips.cc/paper_files/paper/2003/ file/1843e35d41ccf6e63273495ba42df3c1-Paper.pdf. Herbert Edelsbrunner and John Harer. Persistent homology–a survey. InSurveys on Discrete and Computational Geometry: Twenty Years Later, volume 453 ofContemporary Mathematics, pages 257–282. American Mathematical Society,
2003
-
[7]
Julie Fournet and Alain Barrat
doi: 10.1090/conm/ 453/08802. Julie Fournet and Alain Barrat. Contact patterns among high school students.PLoS ONE, 9(9):e107878,
-
[8]
doi: 10.1371/journal.pone.0107878. Ary L Goldberger, Luis A N Amaral, Leon Glass, Jeffrey M Hausdorff, Plamen Ch Ivanov, Roger G Mark, Joseph E Mietus, George B Moody, Chung-Kang Peng, and H Eugene Stanley. Physiobank, physiotoolkit, and physionet: Components of a new research resource for complex physiologic signals.Circulation, 101(23):e215–e220,
-
[9]
Circulation101(23), E215–E220 (2000).https://doi.org/10.1161/01.CIR.101.23.E215
doi: 10.1161/01.CIR.101.23.e215. Christoph Hofer, Florian Graf, Bastian Rieck, Marc Niethammer, and Roland Kwitt. Graph filtration learning. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 4314–4323. PMLR,
-
[10]
Shizuo Kaji, Takanori Sudo, and Kazushi Ahara. Cubicalripser: Software for computing persistent homology of images and volume data.arXiv preprint arXiv:2005.11270,
arXiv 2005
-
[11]
Daniel D Lee and H Sebastian Seung
URLhttps://proceedings.neurips.cc/paper_ files/paper/2000/file/f9d1152547c0bde01830b7e8bd60024c-Paper.pdf. Daniel D Lee and H Sebastian Seung. Learning the parts of objects by non-negative matrix factorization.Nature, 401(6755):788–791,
2000
-
[12]
34 NMF with Topological Regularisation Julien Mairal, Francis Bach, Jean Ponce, and Guillermo Sapiro
doi: 10.1007/s10208-021-09522-y. 34 NMF with Topological Regularisation Julien Mairal, Francis Bach, Jean Ponce, and Guillermo Sapiro. Online learning for matrix factorization and sparse coding.Journal of Machine Learning Research, 11(1):19–60,
-
[13]
The impact of the MIT-BIH arrhythmia database,
doi: 10.1109/51.932724. Naoki Nishikawa, Yuichi Ike, and Kenji Yamanishi. Adaptive topological feature via persistent homology: Filtration learning for point clouds.Advances in Neural Information Processing Systems, 36:9131–9143,
-
[14]
Jose A Perea, Anastasia Deckard, Steve B Haase, and John Harer
doi: 10.1007/s10208-014-9206-z. Jose A Perea, Anastasia Deckard, Steve B Haase, and John Harer. Sw1pers: Sliding windows and 1-persistence scoring; discovering periodicity in gene expression time series data.BMC Bioinformatics, 16(1):257,
-
[15]
Ron Rubinstein, Alfred M Bruckstein, and Michael Elad
doi: 10.1186/s12859-015-0645-6. Ron Rubinstein, Alfred M Bruckstein, and Michael Elad. Dictionaries for sparse representa- tion modeling.Proceedings of the IEEE, 98(6):1045–1057,
-
[16]
Wasserstein stability for persistence diagrams.arXiv preprint arXiv:2006.16824,
Primoz Skraba and Katharine Turner. Wasserstein stability for persistence diagrams.arXiv preprint arXiv:2006.16824,
arXiv 2006
-
[17]
doi: 10.1371/journal.pone.0046331. The GUDHI Project. GUDHI user and reference manual.GUDHI Editorial Board,
-
[18]
Yu-Xiong Wang and Yu-Jin Zhang
doi: 10.1038/s41592-022-01687-w. Yu-Xiong Wang and Yu-Jin Zhang. Nonnegative matrix factorization: A comprehensive review.IEEE Transactions on Knowledge and Data Engineering, 25(6):1336–1353,
-
[19]
35 de Jong van Lier, Kaji, and Kim Wei Xu, Xin Liu, and Yihong Gong
doi: 10.1109/TKDE.2012.51. 35 de Jong van Lier, Kaji, and Kim Wei Xu, Xin Liu, and Yihong Gong. Document clustering based on non-negative matrix factorization. InProceedings of the 26th annual international ACM SIGIR conference on Research and development in information retrieval, pages 267–273,
-
[20]
Taiping Zhang, Bin Fang, Yuan Yan Tang, Guanghui He, and Jing Wen
doi: 10.1016/j.patrec.2010.08.001. Taiping Zhang, Bin Fang, Yuan Yan Tang, Guanghui He, and Jing Wen. Topology preserving non-negative matrix factorization for face recognition.IEEE Transactions on Image Processing, 17(4):574–584,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.