Continuous-time Optimal Stopping through Deep Reinforcement Learning
Pith reviewed 2026-06-27 02:31 UTC · model grok-4.3
The pith
CARLOS uses an aggregate deep neural network to learn continuous-time optimal stopping boundaries by progressively refining grids and adaptive sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
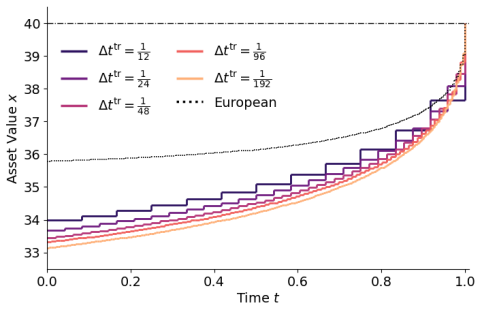
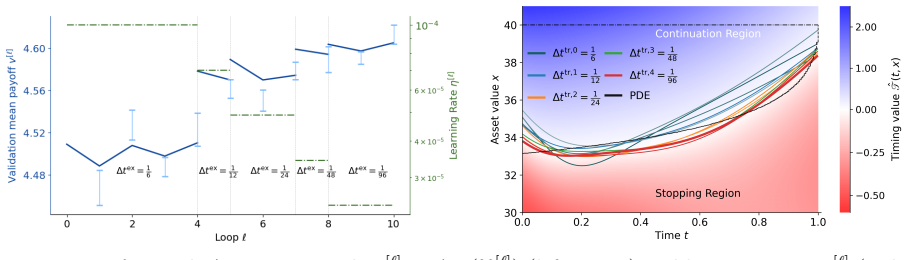
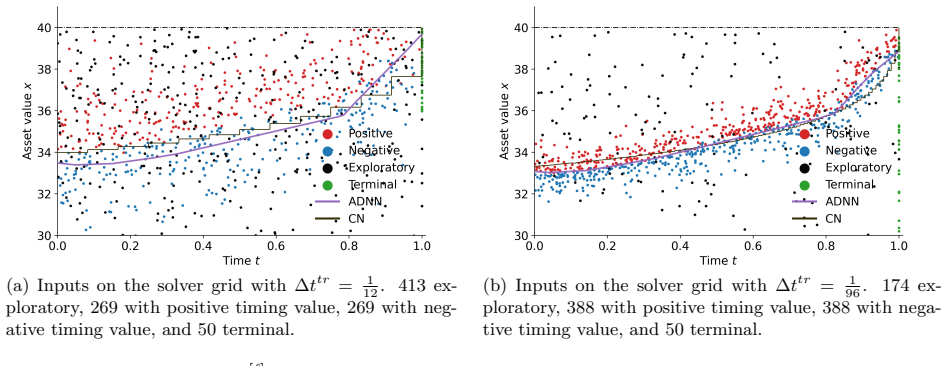
CARLOS (Continuous-time Adaptive Reinforcement Learning for Optimal Stopping) utilizes an aggregate deep neural network (ADNN) to learn a joint space-time decision boundary. Starting from a coarse time grid, the frequency of stopping opportunities is progressively increased while training the ADNN in parallel to refine timing-value estimates, combined with an adaptive sampling strategy that concentrates effort near the stopping boundary.
What carries the argument
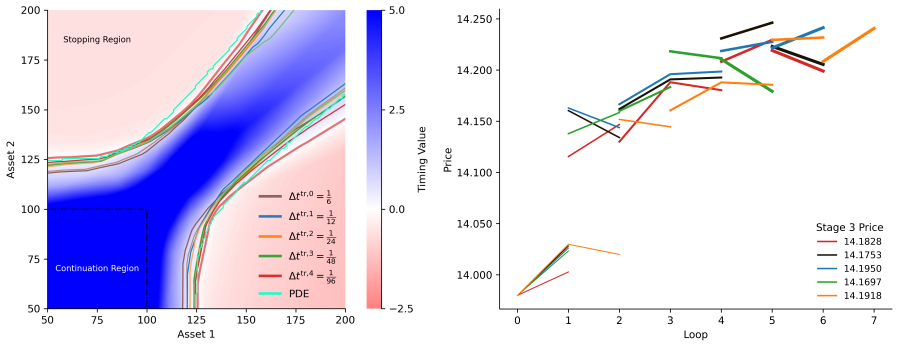
Aggregate Deep Neural Network (ADNN) that represents the joint space-time decision boundary for the exercise rule.
If this is right
- CARLOS produces higher option prices than existing Bermudan solvers.
- The values approach the American upper bound more closely than standard methods.
- Computational efficiency remains high relative to non-RL comparators.
- The exercise rule can be learned at arbitrarily fine time resolution.
Where Pith is reading between the lines
- The joint space-time network representation may transfer to other stochastic control tasks that currently rely on fixed time discretizations.
- Adaptive sampling near decision boundaries could reduce sample needs in related reinforcement learning problems with sparse rewards.
- Direct implementation in existing option pricing software would allow side-by-side testing on market-calibrated models.
Load-bearing premise
The method assumes that progressively refining the time grid while training the aggregate deep neural network on the joint space-time boundary will converge to the true continuous-time optimum without bias from adaptive sampling or network approximation.
What would settle it
Running CARLOS on a problem with a known closed-form continuous-time optimum and checking whether the computed value exceeds all Bermudan discretizations yet remains strictly below the known true value without overshooting.
Figures
read the original abstract
Simulation based solvers for optimal stopping problems must discretize the stopping decision. Under classical dynamic programming, a coarse exercise grid with only a few stopping opportunities can materially undervalue the optimal expected reward, whereas on a very fine grid, approximation errors accumulate through the backward recursion. To remove this limitation, we develop a new reinforcement-learning inspired algorithm that enables us to learn the exercise rule at arbitrarily fine time resolution. Our CARLOS (Continuous-time Adaptive Reinforcement Learning for Optimal Stopping) algorithm utilizes an aggregate deep neural network (ADNN) to learn a joint space-time decision boundary. Starting from a coarse time grid, we progressively increase the frequency of stopping opportunities, while in parallel training the ADNN to refine its timing-value estimates. We moreover design an adaptive sampling strategy that gradually concentrates training effort near the stopping boundary. Benchmarked results show that CARLOS delivers higher prices than existing Bermudan solvers, approaching the American upper bound, and achieves high computational efficiency relative to non-RL comparators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the CARLOS algorithm for continuous-time optimal stopping problems. It employs an aggregate deep neural network (ADNN) to learn a joint space-time decision boundary, beginning with a coarse exercise grid that is progressively refined while the network is trained in parallel and training samples are adaptively concentrated near the estimated stopping boundary. The central claim is that this procedure produces higher prices than standard Bermudan dynamic-programming solvers, approaches the American upper bound, and does so with improved computational efficiency.
Significance. If the convergence claim holds, the work would remove a long-standing discretization bias in simulation-based optimal stopping and supply a scalable RL route to high-resolution continuous-time problems. The adaptive-sampling and joint space-time network ideas are technically interesting and could be reused in other free-boundary problems.
major comments (1)
- The headline claim that CARLOS converges to the true continuous-time optimum (and therefore delivers prices approaching the American upper bound) rests on the unproven assertion that iterative grid refinement plus boundary-focused adaptive sampling drives both discretization and approximation error to zero. No error bounds, contraction argument, or continuous-time limit theorem are supplied to guarantee that the learned stopping set converges to the Snell envelope as mesh size → 0. This is load-bearing for the benchmark superiority statement.
Simulated Author's Rebuttal
We thank the referee for the constructive comment. We respond to the major point below.
read point-by-point responses
-
Referee: The headline claim that CARLOS converges to the true continuous-time optimum (and therefore delivers prices approaching the American upper bound) rests on the unproven assertion that iterative grid refinement plus boundary-focused adaptive sampling drives both discretization and approximation error to zero. No error bounds, contraction argument, or continuous-time limit theorem are supplied to guarantee that the learned stopping set converges to the Snell envelope as mesh size → 0. This is load-bearing for the benchmark superiority statement.
Authors: We agree that the manuscript supplies no error bounds, contraction mapping, or continuous-time limit theorem establishing convergence of the learned stopping set to the Snell envelope. All superiority statements rest on numerical experiments in which CARLOS produces higher values than standard Bermudan dynamic-programming solvers and approaches the American upper bound. We will revise the abstract, introduction, and conclusion to state explicitly that the results are empirical, to remove any implication of proven convergence, and to add a dedicated limitations paragraph noting the absence of theoretical guarantees together with directions for future analysis. revision: yes
- Supplying a rigorous convergence theorem, contraction argument, or error bounds that guarantee the learned stopping set converges to the Snell envelope as the mesh size tends to zero.
Circularity Check
No circularity; algorithmic procedure is independent of its inputs
full rationale
The CARLOS algorithm is presented as a standalone RL procedure that starts from a coarse grid, progressively refines the time discretization, trains an ADNN on the joint space-time boundary, and applies adaptive sampling near the boundary. No equations, fitted parameters, or self-citations are described that would make any claimed performance (higher prices approaching the American bound) equivalent to the inputs by construction. Benchmarking results are external to the method itself, and the derivation chain contains no self-definitional steps, fitted-input predictions, or load-bearing self-citations. The approach is self-contained against external comparators.
Axiom & Free-Parameter Ledger
invented entities (2)
-
CARLOS algorithm
no independent evidence
-
Aggregate deep neural network (ADNN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , address =. Proceedings of the National Academy of Sciences - PNAS ,...
-
[2]
Journal of Machine Learning Research , month =
Becker, Sebastian and Cheridito, Patrick and Jentzen, Arnulf , title =. Journal of Machine Learning Research , month =. 2019 , issue_date =. doi:https://dl.acm.org/doi/10.5555/3322706.3362015 , keywords =
-
[3]
IEEE transaction on neural networks and learning systems , keywords =
Peng, Jian and Tang, Bo and Jiang, Hao and Li, Zhuo and Lei, Yinjie and Lin, Tao and Li, Haifeng , address =. IEEE transaction on neural networks and learning systems , keywords =. 2021 , volume =
2021
-
[4]
2018 , abstract =
Ritter, Hippolyt and Botev, Aleksandar and Barber, David , copyright =. 2018 , abstract =
2018
-
[5]
The Review of Financial Studies14(1), 113–147 (2001) https://doi.org/10.1093/rfs/14.1.113
Longstaff, Francis A. and Schwartz, Eduardo S. , address =. Valuing. The Review of Financial Studies , keywords =. 2001 , volume =. doi:http://dx.doi.org/10.1093/rfs/14.1.113 , publisher =
-
[6]
Optimal stopping and free-boundary problems , isbn =
Peskir, Goran and Shiryaev, Albert , address =. Optimal stopping and free-boundary problems , isbn =. 2006 , abstract =
2006
-
[7]
Introduction to stochastic calculus applied to finance , edition =
Lamberton, Damien , address =. Introduction to stochastic calculus applied to finance , edition =. 2008 , abstract =
2008
-
[8]
2023 , title =
Ludkovski, Mike , journal=. 2023 , title =
2023
-
[9]
Machine Learning for Semi Linear PDEs , volume =
Chan-Wai-Nam, Quentin and Mikael, Joseph and Warin, Xavier , address =. Machine Learning for Semi Linear PDEs , volume =. Journal of scientific computing , keywords =
-
[10]
Connectionist Models of Recognition Memory: Constraints Imposed by Learning and Forgetting Functions , volume =
Ratcliff, Roger , copyright =. Connectionist Models of Recognition Memory: Constraints Imposed by Learning and Forgetting Functions , volume =. Psychological review , keywords =
-
[11]
Ferenc Huszár , title =
-
[12]
Kohler, Michael and Krzyżak, Adam and Todorovic, Nebojsa , address =. Pricing of High-dimensional. Mathematical Finance , keywords =. 2010 , abstract =. doi:https://doi.org/10.1111/j.1467-9965.2010.00404.x , publisher =
-
[13]
Iterative construction of the optimal
Kolodko, Anastasia and Schoenmakers, John , address =. Iterative construction of the optimal. Finance and Stochastics , keywords =. 2006 , abstract =
2006
-
[14]
Applied Mathematics and Computation , keywords =
The Stochastic Grid Bundling Method: Efficient pricing of. Applied Mathematics and Computation , keywords =. 2015 , abstract =
2015
-
[15]
Approximation theory of the
Pinkus, Allan , address =. Approximation theory of the. Acta Numerica , language =. 1999 , abstract =
1999
-
[16]
Multilayer feedforward networks with a nonpolynomial activation function can approximate any function , volume =
Leshno, Moshe and Lin, Vladimir Ya and Pinkus, Allan and Schocken, Shimon , address =. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function , volume =. Neural Networks , keywords =. 1993 , abstract =
1993
-
[17]
Understanding Catastrophic Forgetting and Remembering in Continual Learning with Optimal Relevance Mapping , year =
Kaushik, Prakhar and Gain, Alex and Kortylewski, Adam and Yuille, Alan , doi =. Understanding Catastrophic Forgetting and Remembering in Continual Learning with Optimal Relevance Mapping , year =
-
[18]
Titsias, Jonathan Schwarz, Alexander G
Functional Regularisation for Continual Learning with Gaussian Processes , year =. doi:https://doi.org/10.48550/arXiv.1901.11356 , abstract =
-
[19]
Continual learning with extended
Lee, Janghyeon and Hong, Hyeong Gwon and Joo, Donggyu and Kim, Junmo , booktitle=. Continual learning with extended
-
[20]
doi:https://doi.org/10.48550/arXiv.2004.14070 , abstract =
Continual Deep Learning by Functional Regularisation of Memorable Past , year =. doi:https://doi.org/10.48550/arXiv.2004.14070 , abstract =
-
[21]
Optimal stopping via randomized neural networks , volume =
Herrera, Calypso and Krach, Florian and Ruyssen, Pierre and Teichmann, Josef , journal =. Optimal stopping via randomized neural networks , volume =
-
[22]
Max and Soner, H
Reppen, A. Max and Soner, H. Mete and Tissot-Daguette, Valentin , journal =. Neural Optimal Stopping Boundary , volume =. 2025 , url =
2025
-
[23]
2021 , author =
Neural network regression for. 2021 , author =
2021
-
[24]
European Journal of Applied Mathematics , keywords =
Becker, Sebastian and Cheridito, Patrick and Jentzen, Arnulf and Welti, Timo , address =. European Journal of Applied Mathematics , keywords =. 2021 , abstract =. doi:https://doi.org/10.1017/S0956792521000073 , publisher =
-
[25]
Andréasson, Johan G. and Shevchenko, Pavel V. , address =. A bias-corrected Least-Squares. European Actuarial Journal , keywords =. doi:http://dx.doi.org/10.2139/ssrn.2985828 , publisher =
-
[26]
Quantitative Finance , volume=
Dynamic portfolio optimization with liquidity cost and market impact: a simulation-and-regression approach , author=. Quantitative Finance , volume=. 2019 , publisher=
2019
-
[27]
Li, Zhizhong and Hoiem, Derek , address =. Learning without Forgetting , volume =. IEEE transactions on Pattern Analysis and Machine Intelligence , keywords =. doi:https://doi.org/10.1109/TPAMI.2017.2773081 , number =
-
[28]
Rusu, Andrei A and Rabinowitz, Neil C and Desjardins, Guillaume and Soyer, Hubert and Kirkpatrick, James and Kavukcuoglu, Koray and Pascanu, Razvan and Hadsell, Raia , address =. Progressive Neural Networks , year =. arXiv.org , keywords =. doi:https://doi.org/10.48550/arXiv.1606.04671 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606.04671
-
[29]
Gradient Episodic Memory for Continual Learning , year =
Lopez-Paz, David and Ranzato, Marc'Aurelio , address =. Gradient Episodic Memory for Continual Learning , year =. arXiv.org , keywords =. doi:https://doi.org/10.48550/arXiv.1706.08840 , publisher =
-
[30]
Multiscale stochastic volatility for equity, interest rate, and credit derivatives , isbn =
Fouque, Jean-Pierre , address =. Multiscale stochastic volatility for equity, interest rate, and credit derivatives , isbn =. 2011 , abstract =
2011
-
[31]
Simultaneous upper and lower bounds of
Guo, Ivan and Langren. Simultaneous upper and lower bounds of. Quantitative Finance , volume=. 2025 , publisher=
2025
-
[32]
Deep Reinforcement Learning for Optimal Stopping with Application in Financial Engineering , year =
Fathan, Abderrahim and Delage, Erick , address =. Deep Reinforcement Learning for Optimal Stopping with Application in Financial Engineering , year =
-
[33]
Solving optimal stopping problems with Deep
Ery, John and Michel, Loris , address =. Solving optimal stopping problems with Deep. 2024 , abstract =
2024
-
[34]
Solving the optimal stopping problem with reinforcement learning: an application in financial option exercise , year =
Felizardo, Leonardo Kanashiro and Matsumoto, Elia and Del-Moral-Hernandez, Emilio , booktitle =. Solving the optimal stopping problem with reinforcement learning: an application in financial option exercise , year =
-
[35]
Expert Systems with Applications , volume =. 2023 , issn =. doi:https://doi.org/10.1016/j.eswa.2023.120702 , author =
-
[36]
Human-level control through deep reinforcement learning , volume =
Mnih, Volodymyr and Kavukcuoglu, Koray and Silver, David and Rusu, Andrei A and Veness, Joel and Bellemare, Marc G and Graves, Alex and Riedmiller, Martin and Fidjeland, Andreas K and Ostrovski, Georg and Petersen, Stig and Beattie, Charles and Sadik, Amir and Antonoglou, Ioannis and King, Helen and Kumaran, Dharshan and Wierstra, Daan and Legg, Shane and...
2015
-
[37]
Dueling Network Architectures for Deep Reinforcement Learning , year =
Wang, Ziyu and Schaul, Tom and Hessel, Matteo and Hado van Hasselt and Lanctot, Marc and Nando de Freitas , address =. Dueling Network Architectures for Deep Reinforcement Learning , year =. arXiv.org , keywords =
-
[38]
Communications in Mathematical Sciences , volume = 19, number = 5, pages =
Jentzen, Arnulf and Salimova, Diyora and Welti, Timo , title =. Communications in Mathematical Sciences , volume = 19, number = 5, pages =
-
[39]
Analysis of the Generalization Error: Empirical Risk Minimization over Deep Artificial Neural Networks Overcomes the Curse of Dimensionality in the Numerical Approximation of
Berner, Julius and Grohs, Philipp and Jentzen, Arnulf , issn =. Analysis of the Generalization Error: Empirical Risk Minimization over Deep Artificial Neural Networks Overcomes the Curse of Dimensionality in the Numerical Approximation of. SIAM journal on Mathematics of Data Science , language =. 2020 , doi =
2020
-
[40]
Primal-Dual Simulation Algorithm for Pricing Multidimensional
Andersen, Leif and Broadie, Mark , address =. Primal-Dual Simulation Algorithm for Pricing Multidimensional. Management Science , keywords =. 2004 , doi =
2004
-
[41]
Solving optimal stopping problems via empirical dual optimization , volume =
Belomestny, Denis , address =. Solving optimal stopping problems via empirical dual optimization , volume =. The Annals of Applied Probability , keywords =. 2013 , abstract =
2013
-
[42]
Mastering the game of Go with deep neural networks and tree search , volume =
Silver, David and Huang, Aja and Maddison, Chris J and Guez, Arthur and Sifre, Laurent and van den Driessche, George and Schrittwieser, Julian and Antonoglou, Ioannis and Panneershelvam, Veda and Lanctot, Marc and Dieleman, Sander and Grewe, Dominik and Nham, John and Kalchbrenner, Nal and Sutskever, Ilya and Lillicrap, Timothy and Leach, Madeleine and Ka...
2016
-
[43]
On the Convergence from Discrete to Continuous Time in an Optimal Stopping Problem , volume =
Dupuis, Paul and Wang, Hui , doi =. On the Convergence from Discrete to Continuous Time in an Optimal Stopping Problem , volume =. The Annals of Applied Probability , keywords =. 2005 , abstract =
2005
-
[44]
The mathematics of financial derivatives: a student introduction , year =
Wilmott, Paul and Howison, Sam and Dewynne, Jeff , address =. The mathematics of financial derivatives: a student introduction , year =. The Mathematics of Financial Derivatives: A Student Introduction , isbn =
-
[45]
SIAM Journal on Financial Mathematics , volume =
Yang, Jiefei and Li, Guanglian , title =. SIAM Journal on Financial Mathematics , volume =. 2025 , doi =
2025
-
[46]
2007 , organization=
Yu, Huizhen and Bertsekas, Dimitri P , booktitle=. 2007 , organization=
2007
-
[47]
Advances in Neural Information Processing Systems , volume=
Deep recurrent optimal stopping , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
Learning exercise policies for
Li, Yuxi and Szepesvari, Csaba and Schuurmans, Dale , booktitle=. Learning exercise policies for. 2009 , organization=
2009
-
[49]
Optimal stopping of
Tsitsiklis, John N and Van Roy, Benjamin , journal=. Optimal stopping of. 2002 , publisher=
2002
-
[50]
IEEE Transactions on Neural Networks , volume=
Regression methods for pricing complex American-style options , author=. IEEE Transactions on Neural Networks , volume=. 2001 , publisher=
2001
-
[51]
American Option Pricing in Continuous Time via Reinforcement Learning
Cosmin Borsa. American Option Pricing in Continuous Time via Reinforcement Learning
-
[52]
2018 , publisher=
Sirignano, Justin and Spiliopoulos, Konstantinos , journal=. 2018 , publisher=
2018
-
[53]
Deep neural network framework based on backward stochastic differential equations for pricing and hedging
Chen, Yangang and Wan, Justin WL , journal=. Deep neural network framework based on backward stochastic differential equations for pricing and hedging. 2021 , publisher=
2021
-
[54]
arXiv preprint arXiv:2405.11392 , year=
Deep penalty methods: A class of deep learning algorithms for solving high dimensional optimal stopping problems , author=. arXiv preprint arXiv:2405.11392 , year=
-
[55]
Management Science , year=
Learning to optimally stop diffusion processes, with financial applications , author=. Management Science , year=
-
[56]
arXiv preprint arXiv:2512.22961 , year=
Deep Learning for the Multiple Optimal Stopping Problem , author=. arXiv preprint arXiv:2512.22961 , year=
-
[57]
A deep primal-dual
Yang, Jiefei and Li, Guanglian , journal=. A deep primal-dual
-
[58]
Adaptive batching for
Lyu, Xiong and Ludkovski, Michael , journal=. Adaptive batching for. 2022 , publisher=
2022
-
[59]
Quantitative Finance , volume=
Deep learning for ranking response surfaces with applications to optimal stopping problems , author=. Quantitative Finance , volume=. 2020 , publisher=
2020
-
[60]
Convergence of the backward deep
Gao, Chengfan and Gao, Siping and Hu, Ruimeng and Zhu, Zimu , journal=. Convergence of the backward deep. 2023 , publisher=
2023
-
[61]
Synchronizing pretrained kernel regressors with applications to
Yang, Xuwei and Kratsios, Anastasis and Krach, Florian and Grasselli, Matheus and Lucchi, Aurelien , journal=. Synchronizing pretrained kernel regressors with applications to. 2026 , publisher=
2026
-
[62]
MathematicS In Action , volume=
Deep combinatorial optimisation for optimal stopping time problems: application to swing options pricing , author=. MathematicS In Action , volume=
-
[63]
Regression
Ludkovski, Mike , journal=. Regression
-
[64]
Applied Stochastic Models in Business and Industry , volume=
Swing option pricing consistent with futures smiles , author=. Applied Stochastic Models in Business and Industry , volume=. 2024 , publisher=
2024
-
[65]
Finance and Stochastics , volume=
Deep neural network expressivity for optimal stopping problems , author=. Finance and Stochastics , volume=. 2024 , publisher=
2024
-
[66]
arXiv preprint arXiv:2602.15643 , year=
Reinforcement Learning in Real Option Models , author=. arXiv preprint arXiv:2602.15643 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.