When Dynamics Models Read the Wrong Time Steps: Label-Free Event Credit Re-Anchoring for Robust Global Readouts
Pith reviewed 2026-06-27 02:13 UTC · model grok-4.3
The pith
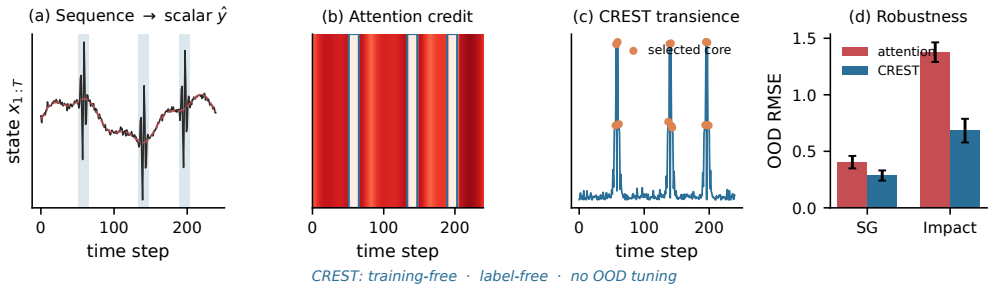
CREST re-anchors pooled readouts to transient physical events using label-free event-versus-rest contrast.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors prove that pooled linear readouts assign functional credit to background correlates rather than brief physical events as the event fraction decreases, and they introduce CREST, a label-free interface that estimates the transient event core from existing features and re-anchors the global representation via event-versus-rest contrast, thereby restoring credit to the determining events without retraining or supervision.
What carries the argument
CREST readout, which estimates a transient event core from learned features and re-anchors the pooled representation through event-versus-rest contrast.
If this is right
- CREST reduces out-of-distribution error on simulated gear and impact systems.
- The method restores event credit across both recurrent and attention-based encoders.
- It improves performance on public bearing vibration data while shifting credit to event steps.
- Stable-step selection and receptive-field shrinking do not achieve equivalent credit restoration or error reduction.
Where Pith is reading between the lines
- The same interface-level credit probe could diagnose analogous dilution problems in other sequence-to-global tasks such as video action recognition or audio event classification.
- CREST-style re-anchoring might be combined with existing physics-informed losses to address both data and credit issues simultaneously.
- The closed-form credit routing result suggests that any global pooling operation on sparse-event sequences will require an explicit re-anchoring step once event density falls below a computable threshold.
- Testing CREST on non-vibration time series with known sparse events, such as financial transaction streams or sensor networks, would reveal whether the core estimation step generalizes beyond mechanical systems.
Load-bearing premise
A transient event core can be reliably estimated from the model's learned features using event-versus-rest contrast without labels or supervision.
What would settle it
Applying CREST to a new dynamics model and observing neither a drop in out-of-distribution error nor a measurable increase in credit assigned to labeled event steps would falsify the central claim.
Figures


read the original abstract
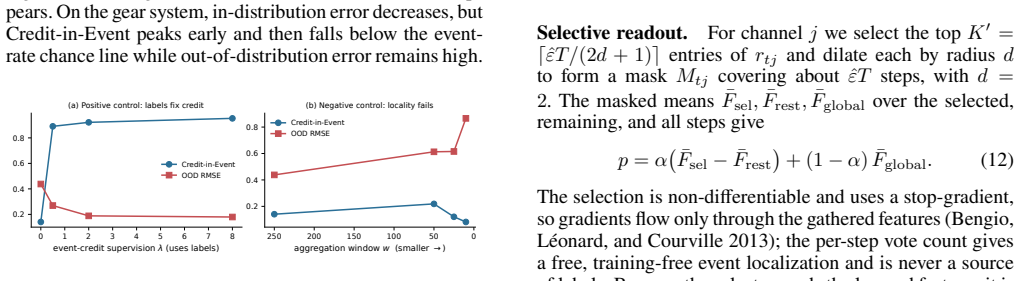
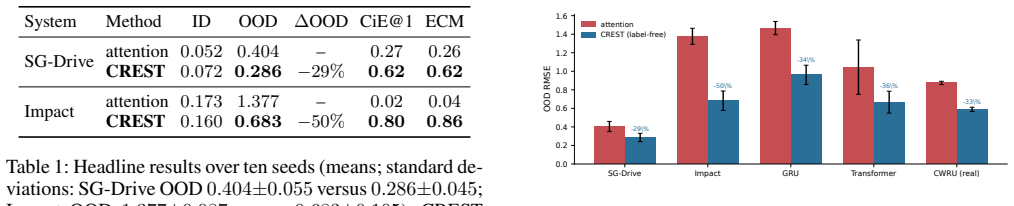
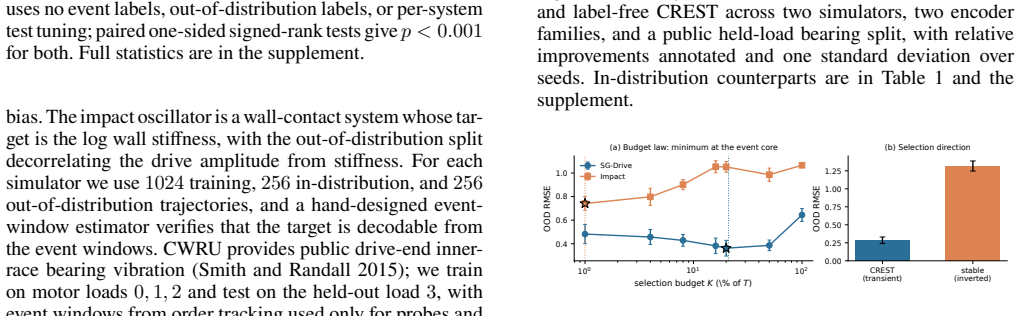
Learned dynamics models often answer global physical questions, such as fault severity or impact stiffness, by pooling a per-step feature sequence into one readout vector. This sequence-to-global interface creates an under-studied temporal credit problem: with only trajectory-level supervision, a model can predict accurately in training conditions while reading from abundant smooth correlates rather than the brief physical events that determine the target. We call this failure temporal credit dilution. It is not exposed by the training loss and is not removed by standard physics-informed residuals, because the error lies in where the global readout assigns functional credit. We introduce Credit-in-Event, an interface-level probe for measuring how much pooled credit lands on event steps, and prove in closed form that a pooled linear reader routes credit to a spurious background channel as the event fraction shrinks. We then propose CREST, a training-free and label-free readout that estimates a transient event core from learned features and re-anchors the pooled representation through event-versus-rest contrast. Across simulated gear and impact systems, recurrent and attention encoders, and public bearing vibration data, CREST reduces out-of-distribution error while restoring event credit. Ablations show that stable-step selection and receptive-field shrinking fail, confirming that the gain comes from event-core credit re-anchoring rather than a generic locality or stability prior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies temporal credit dilution in dynamics models, where sequence-to-global readouts assign functional credit to abundant smooth background signals rather than brief physical events that determine targets like fault severity. It introduces Credit-in-Event as an interface-level probe, provides a closed-form proof that linear pooled readers route credit to spurious channels as event fraction shrinks, and proposes CREST: a training-free, label-free readout that estimates a transient event core from learned encoder features via event-versus-rest contrast and re-anchors the pooled representation. Experiments across simulated gear/impact systems, RNN and attention encoders, and public bearing vibration data report reduced out-of-distribution error and restored event credit, with ablations indicating gains are not due to generic locality or stability priors.
Significance. If the unsupervised event-core estimation reliably isolates causal physical events from learned features, the work addresses an under-studied credit-assignment failure mode that is invisible to standard training losses or physics-informed residuals. The closed-form proof for the linear case and the empirical results across multiple encoders and real data would represent a practical contribution to robust global readouts in physical dynamics modeling without requiring retraining or labels.
major comments (2)
- [Abstract] Abstract: The closed-form proof demonstrates credit misrouting only for a linear reader operating directly on raw inputs as the event fraction approaches zero. CREST, however, applies event-versus-rest contrast to already-learned per-step features from RNN or attention encoders; the manuscript does not show that these features separate the true physical event from other high-variance transients, leaving the re-anchoring claim unsupported by the provided derivation.
- [Abstract] Abstract (experiments section): The central claim that CREST restores event credit via label-free contrast rests on the assumption that the estimated event core corresponds to the load-bearing physical transient rather than background correlates. No quantitative verification (e.g., alignment with ground-truth event locations or sensitivity analysis under feature-space perturbations) is described to test this assumption, which is load-bearing for the OOD gains reported.
minor comments (1)
- The new terminology (temporal credit dilution, Credit-in-Event, CREST) is introduced without an early formal definition or comparison table to related credit-assignment concepts; a brief related-work paragraph would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the scope of the theoretical analysis and the need for direct verification of the event-core estimation. We address both points below and will revise the manuscript to improve clarity and add supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The closed-form proof demonstrates credit misrouting only for a linear reader operating directly on raw inputs as the event fraction approaches zero. CREST, however, applies event-versus-rest contrast to already-learned per-step features from RNN or attention encoders; the manuscript does not show that these features separate the true physical event from other high-variance transients, leaving the re-anchoring claim unsupported by the provided derivation.
Authors: We agree that the closed-form proof applies specifically to a linear reader on raw inputs and serves primarily to illustrate the temporal credit dilution phenomenon in its simplest setting. CREST extends the idea heuristically to learned per-step features via contrast, with its validity supported by the empirical results on RNN and attention encoders. We will revise the abstract, introduction, and theory section to explicitly delineate the proof's scope as motivational for the linear case and to clarify that the feature-space re-anchoring is justified by the Credit-in-Event measurements and OOD improvements rather than by direct extension of the derivation. revision: yes
-
Referee: [Abstract] Abstract (experiments section): The central claim that CREST restores event credit via label-free contrast rests on the assumption that the estimated event core corresponds to the load-bearing physical transient rather than background correlates. No quantitative verification (e.g., alignment with ground-truth event locations or sensitivity analysis under feature-space perturbations) is described to test this assumption, which is load-bearing for the OOD gains reported.
Authors: The referee is correct that explicit quantitative checks on the event-core assumption would strengthen the claims. In the simulated gear and impact systems, ground-truth event locations are known and the Credit-in-Event probe already quantifies credit allocation to those steps. We will add (i) explicit alignment metrics between the estimated event core and ground-truth locations and (ii) a limited sensitivity analysis under controlled feature perturbations in the revised experiments section to directly test the assumption. revision: yes
Circularity Check
No significant circularity; closed-form proof and post-hoc method are independent of training loss
full rationale
The paper's central derivation consists of a closed-form proof that a linear pooled reader on raw inputs routes credit to background as event fraction shrinks, plus a training-free CREST procedure that estimates an event core from already-learned features via contrast. Neither step reduces by construction to the original training loss, fitted parameters, or a self-citation chain; the proof is presented as mathematically independent, and CREST operates downstream on encoder outputs without re-deriving from the model's objective. No load-bearing ansatz, renaming, or uniqueness claim is shown to collapse into its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math A pooled linear reader routes credit to a spurious background channel as the event fraction shrinks
invented entities (3)
-
temporal credit dilution
no independent evidence
-
Credit-in-Event
no independent evidence
-
CREST
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , doi=
2020
-
[2]
International Conference on Learning Representations (ICLR) , year=
Vision Transformers Need Registers , author=. International Conference on Learning Representations (ICLR) , year=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Vision Transformers Need More Than Registers , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[4]
2025 International Conference on Machine Learning and Applications (ICMLA) , pages=
Gradient-based Model Shortcut Detection for Time Series Classification , author=. 2025 International Conference on Machine Learning and Applications (ICMLA) , pages=. 2025 , doi=
2025
-
[5]
Invariant Risk Minimization , author=. arXiv preprint arXiv:1907.02893 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[6]
International Conference on Learning Representations (ICLR) , year=
Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization , author=. International Conference on Learning Representations (ICLR) , year=
-
[7]
International Conference on Learning Representations (ICLR) , year=
Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations , author=. International Conference on Learning Representations (ICLR) , year=
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Learning from Failure: Training Debiased Classifier from Biased Classifier , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Attention is All You Need , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[10]
Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation , author=. Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=. 2014 , doi=
2014
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Neural Ordinary Differential Equations , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[12]
Journal of Computational Physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational Physics , volume=. 2019 , doi=
2019
-
[13]
Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages=
Attention is not Explanation , author=. Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages=. 2019 , doi=
2019
-
[14]
Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Attention is not not Explanation , author=. Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=. 2019 , doi=
2019
-
[15]
Mechanical Systems and Signal Processing , volume=
Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study , author=. Mechanical Systems and Signal Processing , volume=. 2015 , doi=
2015
-
[16]
Proceedings of the 35th International Conference on Machine Learning (ICML) , series=
Attention-based Deep Multiple Instance Learning , author=. Proceedings of the 35th International Conference on Machine Learning (ICML) , series=
-
[17]
IEEE Transactions on Systems, Man, and Cybernetics , volume=
A threshold selection method from gray-level histograms , author=. IEEE Transactions on Systems, Man, and Cybernetics , volume=. 1979 , doi=
1979
-
[18]
International Conference on Learning Representations (ICLR) , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations (ICLR) , year=
-
[19]
International Conference on Machine Learning (ICML) , year=
Axiomatic Attribution for Deep Networks , author=. International Conference on Machine Learning (ICML) , year=
-
[20]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation , author=. arXiv preprint arXiv:1308.3432 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.