Brick-DICL: Dynamic In-Context Learning for Automated Brick Schema Classification
Pith reviewed 2026-06-27 01:15 UTC · model grok-4.3
The pith
Brick-DICL uses two-stage RAG retrieval inside dynamic in-context learning to map building points to any of 936 Brick classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
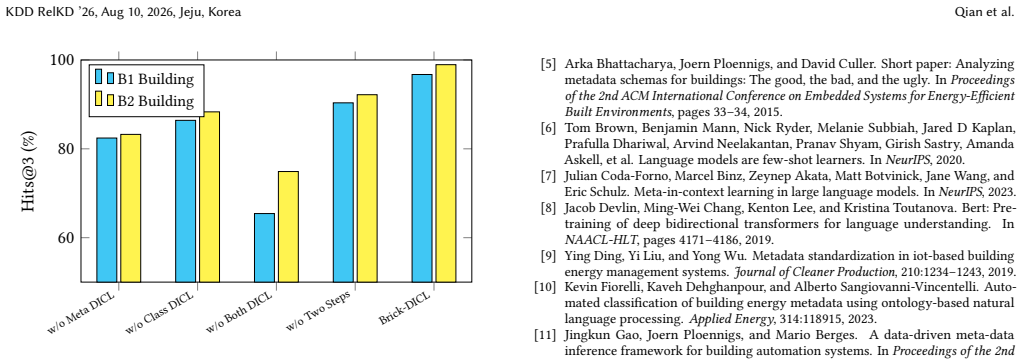
Brick-DICL is a two-stage dynamic in-context learning framework that first applies metadata-RAG to retrieve relevant examples and then applies class-RAG to restrict the candidate set among 936 Brick classes, combined with multi-LLM filtering that routes low-confidence predictions to human review, and this combination produces higher classification accuracy than prior methods on multiple building datasets.
What carries the argument
The two-stage RAG pipeline (metadata-RAG for example retrieval and class-RAG for candidate narrowing) inside a dynamic in-context learning loop, plus the multi-LLM consensus filter.
If this is right
- The framework applies to building management systems from any manufacturer and any metadata format.
- Multi-LLM filtering reduces the volume of cases that need manual verification.
- The method speeds up the process of bringing building data into a standardized, interoperable form.
- Accuracy gains hold across diverse building datasets without requiring domain-specific training data.
Where Pith is reading between the lines
- The same retrieval-plus-filter pattern could be tested on classification tasks that use other large, hierarchical building or industrial ontologies.
- Gains in base LLM knowledge or retrieval quality could shrink the fraction of cases sent for human review.
- Widespread adoption would support larger-scale energy optimization applications that rely on consistent point labels across sites.
Load-bearing premise
A small number of retrieved metadata examples is enough to give an LLM the domain knowledge required to choose correctly among 936 Brick classes.
What would settle it
Evaluation on a new building dataset where Brick-DICL accuracy falls below the best baseline method or where most outputs still require human review.
Figures
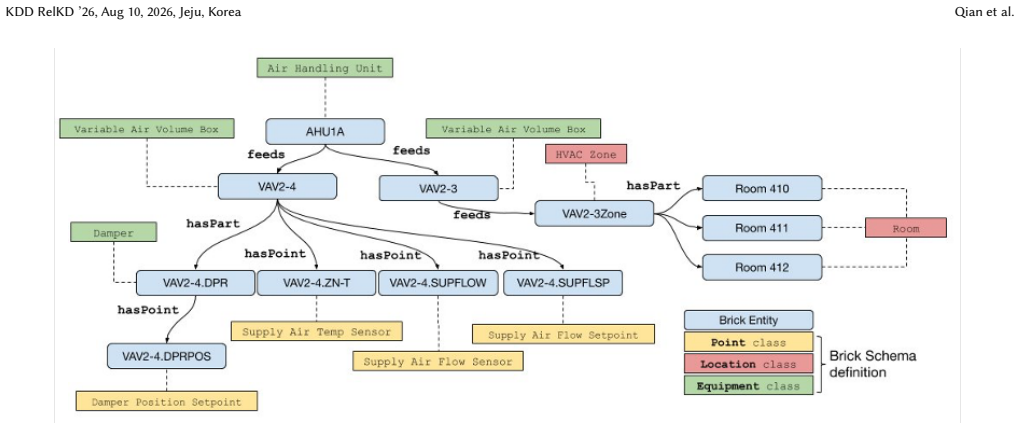
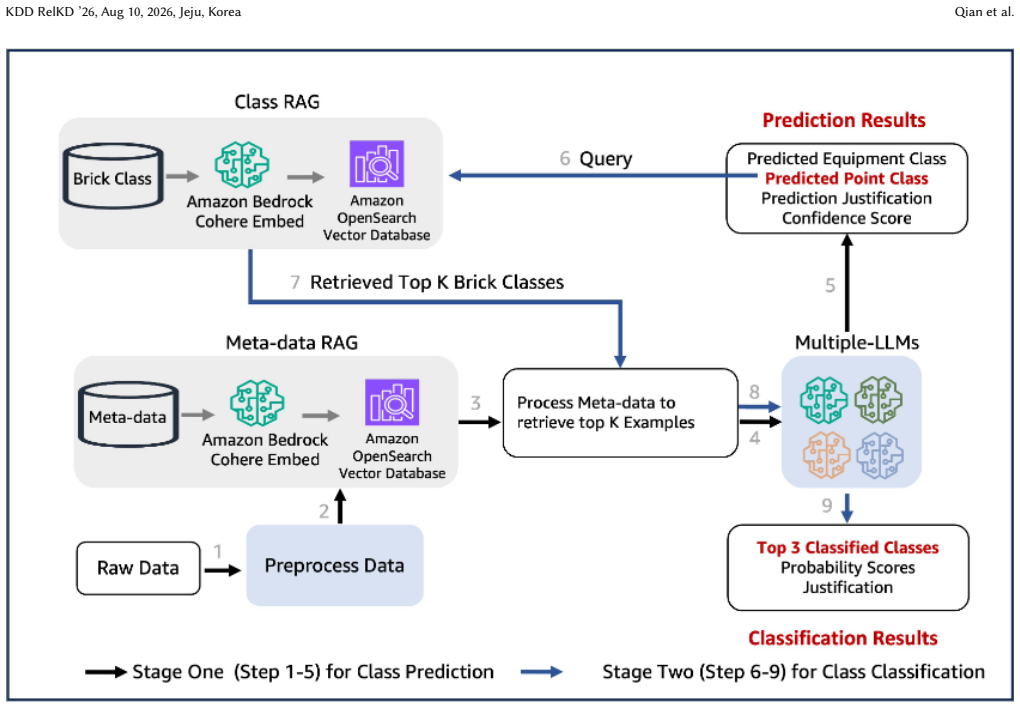
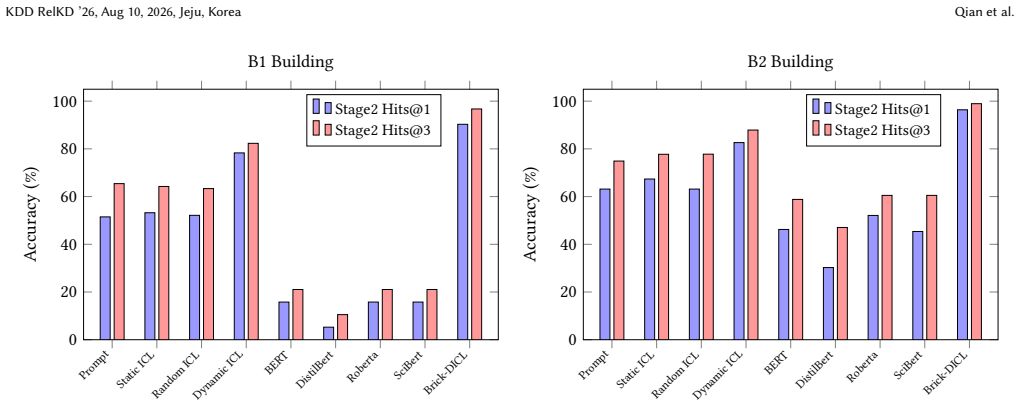
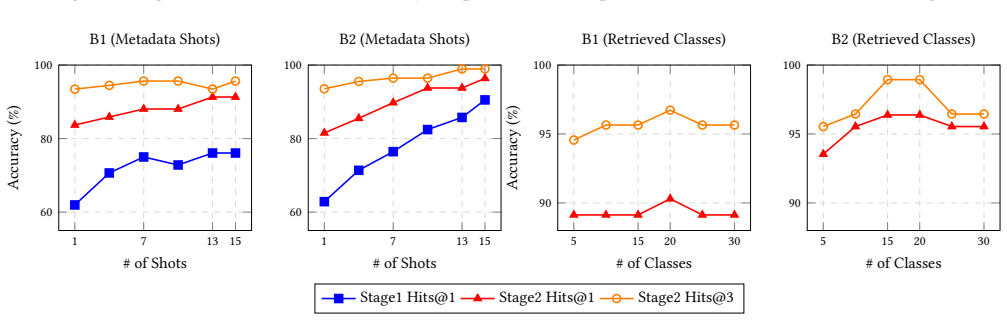

read the original abstract
Building Management Systems (BMS) are essential for optimizing energy efficiency and operational performance in modern buildings. However, the lack of standardization across BMS points from different manufacturers creates significant barriers to integration and data utilization. While the Brick schema offers a standardized ontology for building systems, mapping BMS points to appropriate Brick classes presents three critical challenges: (i) the extensive number of Brick classes (936 in the latest version), (ii) limited domain-specific knowledge in large language models (LLMs), and (iii) substantial manual effort required for verification. To address these challenges, we propose Brick-DICL, a two-stage dynamic in-context learning framework for automated Brick schema classification. Brick-DICL consists of two primary components: metadata-RAG, which retrieves relevant examples to enhance LLMs' domain knowledge, and class-RAG, which narrows down potential Brick classes to address the large classification space. Additionally, we implement a multi-LLM filtering mechanism that compares predictions across multiple models, flagging low-confidence classifications for human review. As a result: (i) General: Brick-DICL is applicable to any building management system regardless of manufacturer or metadata format; (ii) Novel and Powerful: as the first dynamic in-context learning approach for Brick schema classification, Brick-DICL achieves significant classification accuracy improvements on building datasets, outperforming existing methods; (iii) Efficient: our multi-LLM filtering strategy reduces manual verification effort, enabling rapid digital building onboarding. Extensive experiments demonstrate Brick-DICL's effectiveness across diverse building datasets, accelerating the path toward standardized, interoperable building management systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Brick-DICL, a two-stage dynamic in-context learning framework for automated mapping of building management system (BMS) points to Brick schema classes. It combines metadata-RAG to supply domain examples to LLMs, class-RAG to narrow the 936-class space, and a multi-LLM filtering step that flags low-confidence predictions for human review. The authors claim the method is manufacturer-agnostic, achieves significant accuracy gains over prior methods on building datasets, and reduces manual verification effort.
Significance. If the empirical results hold, the work addresses a practical interoperability barrier in BMS by leveraging RAG-based in-context learning to handle a large ontology without fine-tuning. This could reduce onboarding time for standardized building data. The engineering framing (general applicability, multi-LLM consensus) is sensible, though the novelty claim as the first dynamic in-context approach for this task would benefit from explicit positioning against prior RAG or LLM-based schema mapping efforts.
major comments (2)
- [Abstract] Abstract: the central claim that Brick-DICL 'achieves significant classification accuracy improvements on building datasets, outperforming existing methods' is asserted without any reported accuracy numbers, dataset sizes or characteristics, baseline methods, or comparison tables. This absence prevents evaluation of the claim or of generalization across the 936 classes.
- [Abstract] Abstract (method description): the sufficiency of metadata-RAG plus class-RAG for overcoming LLM domain-knowledge gaps is presented as the core mechanism, yet no retrieval metrics (e.g., recall@K for ground-truth class inclusion, embedding similarity distributions) or ablation results isolating the RAG components are supplied. Without these, it is impossible to verify whether the narrowed candidate set reliably contains the correct class for the majority of inputs.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on the abstract. Both points identify legitimate gaps in how the abstract presents our claims and supporting evidence. We will revise the abstract in the next version to incorporate key quantitative results and references to supporting analyses from the experiments section.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Brick-DICL 'achieves significant classification accuracy improvements on building datasets, outperforming existing methods' is asserted without any reported accuracy numbers, dataset sizes or characteristics, baseline methods, or comparison tables. This absence prevents evaluation of the claim or of generalization across the 936 classes.
Authors: We agree that the abstract should provide concrete numbers to substantiate the claim. The full manuscript contains the experimental results (accuracy figures, dataset descriptions, baselines, and tables), but the abstract summarizes them at a high level for brevity. In the revision we will add specific accuracy values, dataset sizes/characteristics, and a brief reference to the baselines and comparison tables from Section 4. revision: yes
-
Referee: [Abstract] Abstract (method description): the sufficiency of metadata-RAG plus class-RAG for overcoming LLM domain-knowledge gaps is presented as the core mechanism, yet no retrieval metrics (e.g., recall@K for ground-truth class inclusion, embedding similarity distributions) or ablation results isolating the RAG components are supplied. Without these, it is impossible to verify whether the narrowed candidate set reliably contains the correct class for the majority of inputs.
Authors: The abstract describes the high-level mechanism without the supporting retrieval statistics or ablations. The experiments section of the manuscript reports overall performance and some component analysis, but does not include the specific retrieval metrics (recall@K, similarity distributions) or dedicated RAG ablations requested. We will revise the abstract to reference the available experimental evidence and, if space permits, add a short statement on retrieval effectiveness; a more complete set of retrieval metrics and ablations can be added to the results section if the referee deems it necessary. revision: partial
Circularity Check
No circularity: engineering framework with empirical results, no derivation chain present.
full rationale
The paper describes an applied two-stage RAG-based classification pipeline (metadata-RAG + class-RAG + multi-LLM filter) evaluated on building datasets. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the method or claims. The accuracy improvements are presented as experimental outcomes on external benchmarks rather than reductions to the method's own inputs. This matches the default expectation of no significant circularity for non-derivational work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models possess limited domain-specific knowledge for Brick schema classification
- domain assumption Retrieving relevant metadata examples can meaningfully augment LLM performance on this task
Reference graph
Works this paper leans on
-
[1]
Many-shot in-context learning
Rishabh Agarwal, Avi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, et al. Many-shot in-context learning. In NeurIPS, volume 37, pages 76930–76966, 2024
2024
-
[2]
Brick: Towards a unified metadata schema for buildings
Bharathan Balaji, Arka Bhattacharya, Gabriel Fierro, Jingkun Gao, Joshua Gluck, Dezhi Hong, Aslak Johansen, Jason Koh, Joern Ploennigs, Yuvraj Agarwal, et al. Brick: Towards a unified metadata schema for buildings. In Proceedings of the 3rd ACM International Conference on Systems for Energy-Efficient Built Environments , pages 41–50, 2016
2016
-
[3]
Brick: Metadata schema for portable smart building applications
Bharathan Balaji, Arka Bhattacharya, Gabriel Fierro, Jingkun Gao, Joshua Gluck, Dezhi Hong, Aslak Johansen, Jason Koh, Joern Ploennigs, Yuvraj Agarwal, et al. Brick: Metadata schema for portable smart building applications. Applied energy, 226:1273–1292, 2018
2018
-
[4]
Scibert: A pretrained language model for scientific text
Iz Beltagy, Kyle Lo, and Arman Cohan. Scibert: A pretrained language model for scientific text. In EMNLP, pages 3615–3620, 2019
2019
-
[5]
Short paper: Analyzing metadata schemas for buildings: The good, the bad, and the ugly
Arka Bhattacharya, Joern Ploennigs, and David Culler. Short paper: Analyzing metadata schemas for buildings: The good, the bad, and the ugly. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, pages 33–34, 2015
2015
-
[6]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In NeurIPS, 2020
2020
-
[7]
Meta-in-context learning in large language models
Julian Coda-Forno, Marcel Binz, Zeynep Akata, Matt Botvinick, Jane Wang, and Eric Schulz. Meta-in-context learning in large language models. In NeurIPS, 2023
2023
-
[8]
Bert: Pre- training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre- training of deep bidirectional transformers for language understanding. In NAACL-HLT, pages 4171–4186, 2019
2019
-
[9]
Metadata standardization in iot-based building energy management systems
Ying Ding, Yi Liu, and Yong Wu. Metadata standardization in iot-based building energy management systems. Journal of Cleaner Production, 210:1234–1243, 2019
2019
-
[10]
Auto- mated classification of building energy metadata using ontology-based natural language processing
Kevin Fiorelli, Kaveh Dehghanpour, and Alberto Sangiovanni-Vincentelli. Auto- mated classification of building energy metadata using ontology-based natural language processing. Applied Energy, 314:118915, 2023
2023
-
[11]
A data-driven meta-data inference framework for building automation systems
Jingkun Gao, Joern Ploennigs, and Mario Berges. A data-driven meta-data inference framework for building automation systems. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, pages 23–32, 2015
2015
-
[12]
Making pre-trained language models better few-shot learners
Tianyu Gao, Adam Fisch, and Danqi Chen. Making pre-trained language models better few-shot learners. arXiv preprint arXiv:2012.15723, 2020
-
[13]
Openagi: When llm meets domain experts
Yingqiang Ge, Wenyue Hua, Kai Mei, Juntao Tan, Shuyuan Xu, Zelong Li, Yongfeng Zhang, et al. Openagi: When llm meets domain experts. In NeurIPS, volume 36, pages 5539–5568, 2023
2023
-
[14]
Evaluation and mitigation of the limitations of large language models in clinical decision-making
Paul Hager, Friederike Jungmann, Robbie Holland, Kunal Bhagat, Inga Hubrecht, Manuel Knauer, Jakob Vielhauer, Marcus Makowski, Rickmer Braren, Georgios Kaissis, et al. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature medicine, 30(9):2613–2622, 2024
2024
-
[15]
Towards auto- matic spatial verification of sensor placement in buildings
Dezhi Hong, Jorge Ortiz, Kamin Whitehouse, and David Culler. Towards auto- matic spatial verification of sensor placement in buildings. In Proceedings of the 5th ACM Workshop on Embedded Systems For Energy-Efficient Buildings , pages 1–8, 2013
2013
-
[16]
Integrating building automation systems for energy efficiency: A review
Ibrahim Katib, Waleed Abdulla, and Mohammed Nasr. Integrating building automation systems for energy efficiency: A review. Renewable and Sustainable Energy Reviews, 59:1571–1581, 2016
2016
-
[17]
Data integration challenges in smart building systems: A review
Seungwon Lee, Hui Li, and Yong Weng. Data integration challenges in smart building systems: A review. Energy and Buildings, 140:241–252, 2017
2017
-
[18]
Henger Li, Shuangjie You, Flavio Di Palo, Yiyue Qian, and Ayush Jain. Verification- guided context optimization for tool calling via hierarchical llms-as-editors.arXiv preprint arXiv:2512.13860, 2025
-
[19]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[20]
Specgen: Automated generation of formal program specifications via large language models
Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu. Specgen: Automated generation of formal program specifications via large language models. arXiv preprint arXiv:2401.08807, 2024
-
[21]
Opbench: A graph benchmark to combat the opioid crisis
Tianyi Ma, Yiyang Li, Yiyue Qian, Zheyuan Zhang, Zehong Wang, Chuxu Zhang, and Yanfang Ye. Opbench: A graph benchmark to combat the opioid crisis. arXiv preprint arXiv:2602.14602, 2026
-
[22]
Non-monotonic autoregressive sequence model
Tianyi Ma, Yiyue Qian, Yiyang Li, Zehong Wang, Yifan Ding, Zheyuan Zhang, Yan Liang, Chuxu Zhang, and Yanfang Ye. Non-monotonic autoregressive sequence model. In ICML, 2026
2026
-
[23]
Llm-empowered class imbalanced graph prompt learning for online drug trafficking detection
Tianyi Ma, Yiyue Qian, Zehong Wang, Zheyuan Zhang, Chuxu Zhang, and Yanfang Ye. Llm-empowered class imbalanced graph prompt learning for online drug trafficking detection. In Findings of ACL, 2025
2025
-
[24]
Bhygnn+: Unsupervised representation learning for heterophilic hypergraphs
Tianyi Ma, Yiyue Qian, Zehong Wang, Zheyuan Zhang, Chuxu Zhang, and Yanfang Ye. Bhygnn+: Unsupervised representation learning for heterophilic hypergraphs. arXiv preprint arXiv:2602.14919, 2026
-
[25]
Hypergraph representation learning with adaptive broad- casting and receiving
Tianyi Ma, Yiyue Qian, Zehong Wang, Zheyuan Zhang, Shinan Zhang, Chuxu Zhang, and Fanny Ye. Hypergraph representation learning with adaptive broad- casting and receiving. In ICDM, 2025
2025
-
[26]
Hypergraph contrastive learning for drug trafficking community detection
Tianyi Ma, Yiyue Qian, Chuxu Zhang, and Yanfang Ye. Hypergraph contrastive learning for drug trafficking community detection. In ICDM, 2023
2023
-
[27]
Adaptive expansion for hypergraph learning
Tianyi Ma, Yiyue Qian, Shinan Zhang, Chuxu Zhang, and Yanfang Ye. Adaptive expansion for hypergraph learning. arXiv preprint arXiv:2502.15564, 2025
-
[28]
Autodata: A multi-agent system for open web data collection
Tianyi Ma, Yiyue Qian, Zheyuan Zhang, Zehong Wang, Xiaoye Qian, Feifan Bai, Yifan Ding, Xuwei Luo, Shinan Zhang, Keerthiram Murugesan, et al. Autodata: A multi-agent system for open web data collection. In NeurIPS, 2025
2025
-
[29]
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Graph Representation Learning Techniques for the Combat Against Online Abusive Activity
Yiyue Qian. Graph Representation Learning Techniques for the Combat Against Online Abusive Activity. University of Notre Dame, 2024
2024
-
[31]
Universal ring-of-abusers detection via multi-modal heterogeneous graph learning
Yiyue Qian, Philip Chen, Song Cui, and De Chen. Universal ring-of-abusers detection via multi-modal heterogeneous graph learning. 2023
2023
-
[32]
Dual-level hypergraph contrastive learning with adaptive temperature enhancement
Yiyue Qian, Tianyi Ma, Chuxu Zhang, and Yanfang Ye. Dual-level hypergraph contrastive learning with adaptive temperature enhancement. In Companion of Brick-DICL: Dynamic In-Context Learning for Automated Brick Schema Classification KDD RelKD ’26, Aug 10, 2026, Jeju, Korea WWW, pages 859–862, 2024
2026
-
[33]
Adaptive graph enhance- ment for imbalanced multi-relation graph learning
Yiyue Qian, Tianyi Ma, Chuxu Zhang, and Yanfang Ye. Adaptive graph enhance- ment for imbalanced multi-relation graph learning. In WSDM, 2025
2025
-
[34]
Co-modality graph contrastive learning for imbalanced node classification
Yiyue Qian, Chunhui Zhang, Yiming Zhang, Qianlong Wen, Yanfang Ye, and Chuxu Zhang. Co-modality graph contrastive learning for imbalanced node classification. In NeurIPS, volume 35, pages 15862–15874, 2022
2022
-
[35]
Enhancing e-commerce representation learning via hypergraph contrastive learning and interpretable llm-driven analysis
Yiyue Qian, Shinan Zhang, Lanhao Chen, Diego Socolinsky, Negin Sokhandan, Song Cui, De Chen, and Suchitra Sathyanarayana. Enhancing e-commerce representation learning via hypergraph contrastive learning and interpretable llm-driven analysis. In Companion WWW, pages 2512–2520, 2025
2025
-
[36]
Collabeval: Enhancing llm-as-a-judge via multi-agent collaboration
Yiyue Qian, Shinan Zhang, Yun Zhou, Haibo Ding, Diego Socolinsky, and Yi Zhang. Collabeval: Enhancing llm-as-a-judge via multi-agent collaboration. arXiv preprint arXiv:2603.00993, 2026
-
[37]
Mali- cious repositories detection with adversarial heterogeneous graph contrastive learning
Yiyue Qian, Yiming Zhang, Nitesh Chawla, Yanfang Ye, and Chuxu Zhang. Mali- cious repositories detection with adversarial heterogeneous graph contrastive learning. In CIKM, 2022
2022
-
[38]
Rep2vec: Repository embedding via heterogeneous graph adversarial contrastive learning
Yiyue Qian, Yiming Zhang, Qianlong Wen, Yanfang Ye, and Chuxu Zhang. Rep2vec: Repository embedding via heterogeneous graph adversarial contrastive learning. In KDD, 2022
2022
-
[39]
Adapting meta knowl- edge with heterogeneous information network for covid-19 themed malicious repository detection
Yiyue Qian, Yiming Zhang, Yanfang Ye, and Chuxu Zhang. Adapting meta knowl- edge with heterogeneous information network for covid-19 themed malicious repository detection. In IJCAI, 2021
2021
-
[40]
Distilling meta knowledge on heterogeneous graph for illicit drug trafficker detection on social media
Yiyue Qian, Yiming Zhang, Yanfang Ye, and Chuxu Zhang. Distilling meta knowledge on heterogeneous graph for illicit drug trafficker detection on social media. In NeurIPS, 2021
2021
-
[41]
Learning to retrieve prompts for in-context learning
Ohad Rubin, Jonathan Herzig, and Jonathan Berant. Learning to retrieve prompts for in-context learning. In NAACL-HLT, pages 2655–2671, 2022
2022
-
[42]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv preprint arXiv:2402.07927, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[44]
Huan Song, Deeksha Razdan, Yiyue Qian, Arijit Ghosh Chowdhury, Parth Patwa, Aman Chadha, Shinan Zhang, Sharlina Keshava, and Hannah Marlowe. Learning from generalization patterns: An evaluation-driven approach to en- hanced data augmentation for fine-tuning small language models. arXiv preprint arXiv:2510.18143, 2025
-
[45]
An approach for the classification of urban building structures based on discriminant analysis techniques
Stefan Steiniger, Tilman Lange, Dirk Burghardt, and Robert Weibel. An approach for the classification of urban building structures based on discriminant analysis techniques. Transactions in GIS, 12(1):31–59, 2008
2008
-
[46]
Bim-to-brick: Using graph modeling for iot/bms and spatial semantic data interoperability within digital data models of buildings
Filippo Vittori, Chuan Fu Tan, Anna Laura Pisello, Adrian Chong, Cristina Piselli, and Clayton Miller. Bim-to-brick: Using graph modeling for iot/bms and spatial semantic data interoperability within digital data models of buildings. Energy and Buildings, 348:116368, 2025
2025
-
[47]
Building information modeling (bim) for existing buildings — literature review and future needs
Roman Volk, Joachim Stengel, and Frank Schultmann. Building information modeling (bim) for existing buildings — literature review and future needs. Au- tomation in Construction, 38:109–127, 2014
2014
-
[48]
To- wards evaluation guidelines for empirical studies involving llms
Stefan Wagner, Marvin Muñoz Barón, Davide Falessi, and Sebastian Baltes. To- wards evaluation guidelines for empirical studies involving llms. arXiv preprint arXiv:2411.07668, 2024
-
[49]
Automated point mapping for building control systems: Recent advances and future research needs
Weimin Wang, Michael R Brambley, Woohyun Kim, Sriram Somasundaram, and Andrew J Stevens. Automated point mapping for building control systems: Recent advances and future research needs. Automation in Construction , 85:107–123, 2018
2018
-
[50]
Emergent abilities of large language models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. Transactions on Machine Learning Research
-
[51]
Enhancing large language models through external domain knowledge
Laslo Welz and Carsten Lanquillon. Enhancing large language models through external domain knowledge. In HCII, pages 135–146. Springer, 2024
2024
-
[52]
Gcvr: reconstruction from cross-view enable sufficient and robust graph contrastive learning
Qianlong Wen, Zhongyu Ouyang, Chunhui Zhang, Yiyue Qian, Chuxu Zhang, and Yanfang Ye. Gcvr: reconstruction from cross-view enable sufficient and robust graph contrastive learning. In UAI, 2024
2024
-
[53]
Disentangled dynamic heterogeneous graph learning for opioid overdose prediction
Qianlong Wen, Zhongyu Ouyang, Jianfei Zhang, Yiyue Qian, Yanfang Ye, and Chuxu Zhang. Disentangled dynamic heterogeneous graph learning for opioid overdose prediction. In KDD, 2022
2022
-
[54]
Inference-time model steering via predictive-state intervention: A survey
Renhao Xue, Rui Wang, Yawei Wang, Yueying Cui, Yiyue Qian, Praneetha Vad- damanu, Huan Song, and Hannah Marlowe. Inference-time model steering via predictive-state intervention: A survey. 2026
2026
-
[55]
Domain knowledge is all you need: A field deployment of llm-powered test case generation in fintech domain
Zhiyi Xue, Liangguo Li, Senyue Tian, Xiaohong Chen, Pingping Li, Liangyu Chen, Tingting Jiang, and Min Zhang. Domain knowledge is all you need: A field deployment of llm-powered test case generation in fintech domain. In ICSE-Companion, pages 314–315, 2024
2024
-
[56]
Crossfit: A few-shot learning challenge for cross-task generalization in nlp
Qinyuan Ye, Bill Yuchen Lin, and Xiang Ren. Crossfit: A few-shot learning challenge for cross-task generalization in nlp. In EMNLP, pages 7163–7189, 2021
2021
-
[57]
Community mitigation: A data-driven system for covid-19 risk assessment in a hierarchical manner
Yanfang Ye, Yujie Fan, Shifu Hou, Yiming Zhang, Yiyue Qian, Shiyu Sun, Qian Peng, Mingxuan Ju, Wei Song, and Kenneth Loparo. Community mitigation: A data-driven system for covid-19 risk assessment in a hierarchical manner. In CIKM, pages 2909–2916, 2020
2020
-
[58]
𝛼-satellite: An ai-driven system and benchmark datasets for hierarchical community-level risk assessment to help combat covid-
Yanfang Ye, Shifu Hou, Yujie Fan, Yiyue Qian, Yiming Zhang, Shiyu Sun, Qian Peng, and Kenneth Laparo. 𝛼-satellite: An ai-driven system and benchmark datasets for hierarchical community-level risk assessment to help combat covid-
- [59]
-
[60]
dstyle-gan: Generative adversarial network based on writing and photog- raphy styles for drug identification in darknet markets
Yiming Zhang, Yiyue Qian, Yujie Fan, Yanfang Ye, Xin Li, Qi Xiong, and Fudong Shao. dstyle-gan: Generative adversarial network based on writing and photog- raphy styles for drug identification in darknet markets. In ACSAC, 2020
2020
-
[61]
Adapting distilled knowledge for few-shot relation reasoning over knowledge graphs
Yiming Zhang, Yiyue Qian, Yanfang Ye, and Chuxu Zhang. Adapting distilled knowledge for few-shot relation reasoning over knowledge graphs. In SDM, pages 666–674. SIAM, 2022
2022
-
[62]
Calibrate before use: Improving few-shot performance of language models
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving few-shot performance of language models. In ICML, pages 12697–12706. PMLR, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.