FinAcumen: Financial Multimodal Reasoning via Self-Evolving Experience Memory Harness
Pith reviewed 2026-06-27 01:12 UTC · model grok-4.3
The pith
FinAcumen equips a frozen 8B vision-language model with selective experience memory to outperform finance-specialized models on four multimodal reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
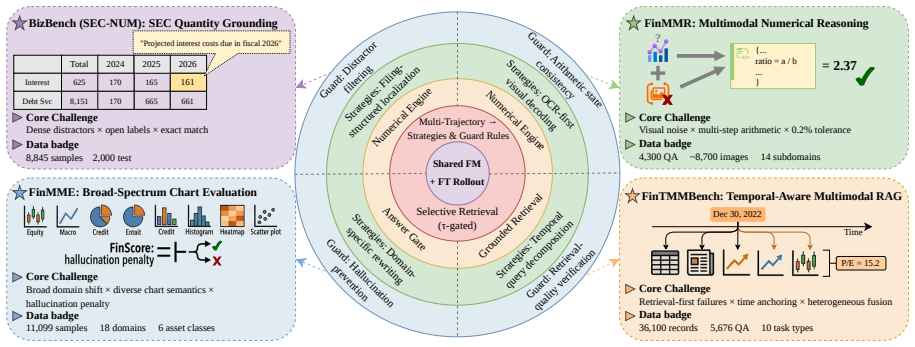
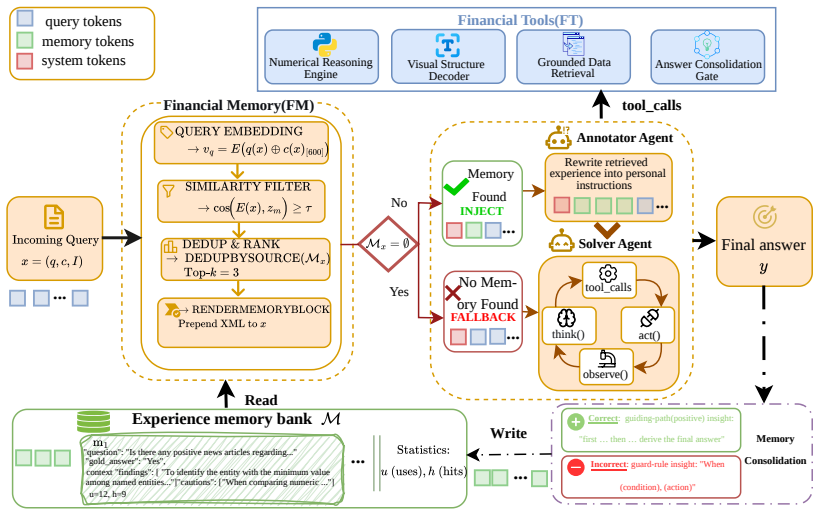
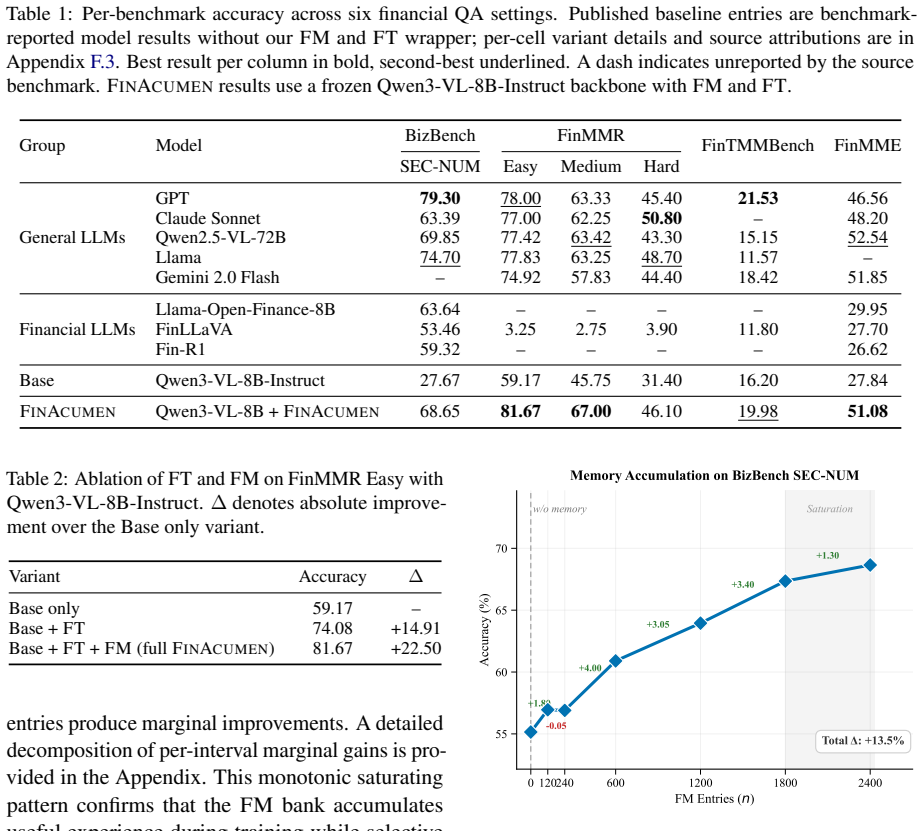
FinAcumen accumulates financially grounded reasoning experience from prior trajectories, distilling successful strategies and failure-derived cautionary rules into a persistent memory bank. During inference, retrieved experiences condition reasoning only when semantic relevance exceeds a calibrated threshold, while irrelevant memory is explicitly suppressed through a fallback mechanism. A deterministic financial tool environment grounds numerical computation, retrieval, visual decoding, and answer verification. Across four financial multimodal reasoning benchmarks, this improves a frozen 8B vision-language model over finance-specialized models and approaches leading proprietary general-purpo
What carries the argument
The selective experience memory bank that activates experiences only when semantic relevance exceeds a calibrated threshold, with explicit fallback suppression for irrelevant entries.
If this is right
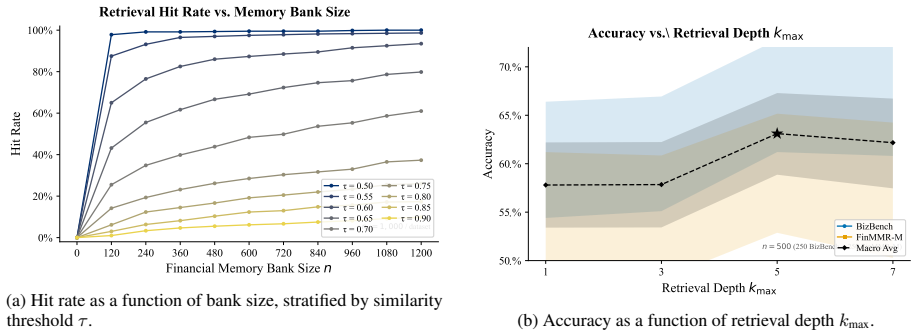
- Selective activation of stored experiences improves reasoning reliability when retrieval is uncertain.
- A frozen 8B model augmented this way surpasses finance-specialized models on the tested benchmarks.
- The deterministic tool environment grounds numerical, visual, and verification steps independently of the memory component.
- Persistent memory of both successes and failures reduces repeated strategy rediscovery across episodes.
Where Pith is reading between the lines
- The same memory-harness pattern could be tested on non-financial multimodal tasks where agents currently repeat errors across episodes.
- If the threshold proves stable across new financial datasets, the method might reduce the need for task-specific prompt engineering.
- Scaling the base model size while keeping the memory layer frozen would show whether the gains compound or plateau.
Load-bearing premise
A single calibrated semantic relevance threshold can reliably separate useful prior experiences from irrelevant ones across tasks without introducing new errors or requiring per-task retuning.
What would settle it
On the four benchmarks, disable the relevance threshold and retrieve experiences at random or not at all; if performance then falls to the level of the base 8B model without memory, the selective mechanism is not the source of the reported gains.
Figures
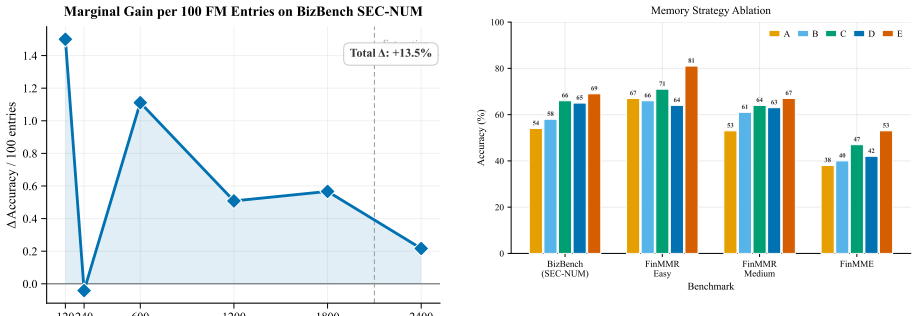

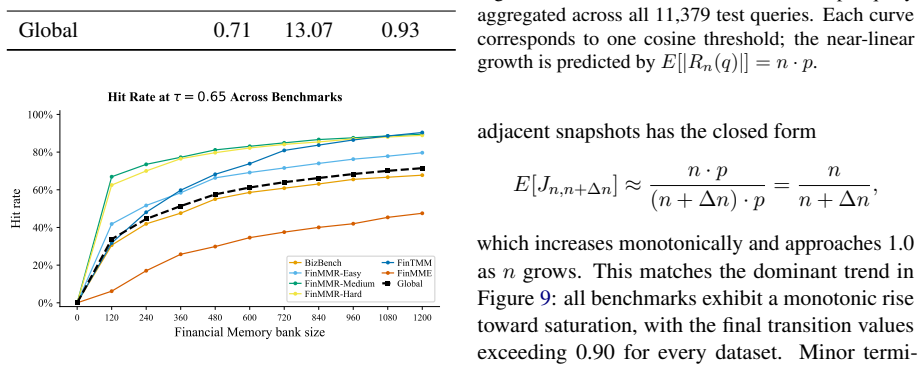



read the original abstract
Financial multimodal reasoning requires agents to coordinate numerical computation, retrieval, visual interpretation, and temporal grounding across heterogeneous evidence sources. Existing tool-augmented agents improve execution fidelity, yet remain largely stateless across episodes, repeatedly rediscovering reasoning strategies and failure patterns. In high-stakes financial settings, this leads to unreliable tool routing, noisy retrieval, and hallucination-prone reasoning. We present FinAcumen, a financial reasoning agent framework centered on selective experience memory for tool-augmented multimodal reasoning. FinAcumen accumulates financially grounded reasoning experience from prior trajectories, distilling successful strategies and failure-derived cautionary rules into a persistent memory bank. During inference, retrieved experiences condition reasoning only when semantic relevance exceeds a calibrated threshold, while irrelevant memory is explicitly suppressed through a fallback mechanism. A deterministic financial tool environment further grounds numerical computation, retrieval, visual decoding, and answer verification.Across four financial multimodal reasoning benchmarks, FinAcumen consistently improves a frozen 8B vision-language model over finance-specialized models and approaches leading proprietary general-purpose models. Further analysis shows that selective experience activation improves reasoning reliability under retrieval uncertainty. Our code is anonymously available at https://anonymous.4open.science/r/FinAcumen
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FinAcumen, a framework for financial multimodal reasoning agents that accumulates successful strategies and failure-derived rules from prior trajectories into a persistent memory bank. During inference, retrieved experiences condition reasoning only when semantic relevance exceeds a calibrated threshold, with explicit fallback suppression for irrelevant memory; a deterministic financial tool environment grounds computation and verification. The central claim is that this selective memory approach consistently improves a frozen 8B vision-language model over finance-specialized models and approaches leading proprietary models across four financial multimodal reasoning benchmarks, while also improving reliability under retrieval uncertainty.
Significance. If the empirical results hold with proper controls, the selective memory mechanism could meaningfully advance reliable tool-augmented agents in high-stakes domains by mitigating stateless rediscovery of strategies without model retraining. The anonymous code release is a positive step toward reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that FinAcumen 'consistently improves' a frozen 8B VLM over finance-specialized models and approaches proprietary ones is load-bearing for the contribution, yet the text supplies no baselines, error bars, controls, ablation results, or even the names of the four benchmarks, rendering the central empirical claim unverifiable from the manuscript.
- [Abstract] Abstract: the selective activation mechanism depends on a 'calibrated semantic relevance threshold' with fallback suppression; this is presented as key to reliability, but no equations, pseudocode, calibration procedure, sensitivity analysis, or ablation data on threshold effects are provided, leaving open whether the mechanism introduces new errors or requires per-benchmark retuning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater self-containment is needed and will revise the abstract accordingly while preserving its length.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that FinAcumen 'consistently improves' a frozen 8B VLM over finance-specialized models and approaches proprietary ones is load-bearing for the contribution, yet the text supplies no baselines, error bars, controls, ablation results, or even the names of the four benchmarks, rendering the central empirical claim unverifiable from the manuscript.
Authors: We acknowledge the abstract is insufficiently informative on its own. The body of the manuscript (Sections 4 and 5, Tables 1–3) contains the benchmark names, full baselines, error bars from repeated runs, controls for retrieval uncertainty, and ablation results. To address the concern directly, we will expand the abstract to name the four benchmarks and summarize the key quantitative improvements with explicit reference to the controls and ablations. revision: yes
-
Referee: [Abstract] Abstract: the selective activation mechanism depends on a 'calibrated semantic relevance threshold' with fallback suppression; this is presented as key to reliability, but no equations, pseudocode, calibration procedure, sensitivity analysis, or ablation data on threshold effects are provided, leaving open whether the mechanism introduces new errors or requires per-benchmark retuning.
Authors: The Methods section provides the relevance scoring equation, the calibration procedure on a held-out validation split, pseudocode for the fallback suppression logic, and ablation results showing threshold sensitivity and cross-benchmark stability without per-benchmark retuning. We will add a concise clause to the abstract describing the calibration approach and noting that ablations confirm robustness. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an agent framework for financial multimodal reasoning that relies on a selective experience memory mechanism with a calibrated relevance threshold and fallback suppression. No equations, derivations, or mathematical claims appear in the provided abstract or description. The central improvements are described as empirical results on benchmarks rather than reductions of predictions to fitted inputs or self-citations. No load-bearing steps match any of the enumerated circularity patterns; the description is self-contained as an engineering contribution without internal definitional loops or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2503.16252 , year=
Fin-r1: A large language model for financial reasoning through reinforcement learning , author=. arXiv preprint arXiv:2503.16252 , year=
-
[2]
arXiv preprint arXiv:2408.11878 , year=
Open-finllms: Open multimodal large language models for financial applications , author=. arXiv preprint arXiv:2408.11878 , year=
-
[3]
arXiv preprint arXiv:2511.08621 , year=
The LLM Pro Finance Suite: Multilingual Large Language Models for Financial Applications , author=. arXiv preprint arXiv:2511.08621 , year=
-
[4]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Towards Temporal-Aware Multi-Modal Retrieval Augemented Generation in Finance , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[5]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Finmme: Benchmark dataset for financial multi-modal reasoning evaluation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Finmmr: make financial numerical reasoning more multimodal, comprehensive, and challenging , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[7]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Reasoningbank: Scaling agent self-evolving with reasoning memory , author=. arXiv preprint arXiv:2509.25140 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Pan, Wenbo and Liu, Shujie and Zhou, Xiangyang and Zhang, Shiwei and Shi, Wanlu and Xu, Mirror and Jia, Xiaohua , journal=. M \^
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Zhang, Ce and He, Jinxi and He, Junyi and Sycara, Katia and Xie, Yaqi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[10]
Bai, Shuai and Cai, Yuxuan and Chen, Ruizhe and Chen, Keqin and Chen, Xionghui and others , title =. arXiv preprint arXiv:2511.21631 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2311.06602 , year =
Koncel-Kedziorski, Rik and Krumdick, Michael and Lai, Viet and Reddy, Varshini and Lovering, Charles and Tanner, Chris , title =. arXiv preprint arXiv:2311.06602 , year =
-
[12]
Advances in Neural Information Processing Systems , volume =
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , title =. Advances in Neural Information Processing Systems , volume =. 2022 , note =
2022
-
[13]
International Conference on Learning Representations (ICLR) , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[14]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[15]
International Conference on Learning Representations , year=
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , author=. International Conference on Learning Representations , year=
-
[16]
International Conference on Machine Learning , pages=
Large language models can be easily distracted by irrelevant context , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Expel: Llm agents are experiential learners , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[18]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[19]
RealFin: How Well Do LLMs Reason About Finance When Users Leave Things Unsaid?
RealFin: How Well Do LLMs Reason About Finance When Users Leave Things Unsaid? , author=. arXiv preprint arXiv:2602.07096 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
arXiv preprint arXiv:2406.11903 , year=
A survey of large language models for financial applications: Progress, prospects and challenges , author=. arXiv preprint arXiv:2406.11903 , year=
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
FinMMDocR: Benchmarking Financial Multimodal Reasoning with Scenario Awareness, Document Understanding, and Multi-Step Computation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
Dong, Yifei and Wu, Fengyi and Zhang, Kunlin and Dai, Yilong and Zhang, Sanjian and Ye, Wanghao and Chen, Sihan and Cheng, Zhi-Qi. Large Language Model Agents in Finance: A Survey Bridging Research, Practice, and Real-World Deployment. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.972
-
[23]
Memgen: Weaving generative latent memory for self-evolving agents , author=. arXiv preprint arXiv:2509.24704 , year=
-
[24]
arXiv preprint arXiv:2603.16112 , year=
ASDA: Automated Skill Distillation and Adaptation for Financial Reasoning , author=. arXiv preprint arXiv:2603.16112 , year=
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
CLER: Improving Multimodal Financial Reasoning by Cross-MLLM Error Reflection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.