Reload-Mamba: Hierarchical Anti-Dilution State-Space Modeling for Multi-Class Semantic Segmentation
Pith reviewed 2026-06-27 01:12 UTC · model grok-4.3
The pith
Reload-Mamba counters response dilution in Mamba state-space models for multi-class semantic segmentation through boundary-supervised priors, uncertainty-aware gates, and hierarchical reloads at multiple decoder levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that propagation-induced response dilution in Mamba-based state-space models for semantic segmentation is mitigated by the Reload-Mamba framework's three segmentation-specific designs, which cumulatively improve over the direct-port baseline by 2.2 mIoU on ADE20K while reaching 47.9 percent single-scale mIoU on ADE20K, 83.2 percent on Cityscapes, and 87.8 percent on PASCAL VOC 2012 val.
What carries the argument
The class-uncertainty-aware Reload Gate combined with hierarchical multi-level Reload, which uses boundary-supervised priors and auxiliary entropy signals to restore attenuated responses at three decoder levels before top-down fusion.
If this is right
- Each of the three designs contributes measurable improvement beyond a direct port of the prior anti-dilution architecture.
- The full model reaches 47.9 percent single-scale mIoU on ADE20K and 83.2 percent on Cityscapes.
- With ResNet-101 and COCO pre-training the same architecture reaches 87.8 percent mIoU on PASCAL VOC 2012 val.
- The class-uncertainty-aware gate is formulated specifically for multi-class dense prediction and is informative only in that setting.
Where Pith is reading between the lines
- The hierarchical reload pattern could be tested on other linear-time sequence models applied to dense prediction tasks where boundary fidelity matters.
- The uncertainty gate might reduce the need for heavy auxiliary supervision if the entropy signal can be derived from the main head itself.
- If the anti-dilution effect holds, similar reload stages could be inserted into Mamba backbones for related tasks such as panoptic segmentation or monocular depth.
Load-bearing premise
The auxiliary entropy head and boundary-supervised prior supply independent signals that genuinely restore diluted responses rather than simply adding capacity or fitting dataset artifacts.
What would settle it
An experiment that replaces the boundary masks and entropy head with random or constant signals and still records the full 2.2 mIoU gain on ADE20K would show the gains come from added capacity rather than targeted anti-dilution.
Figures


read the original abstract
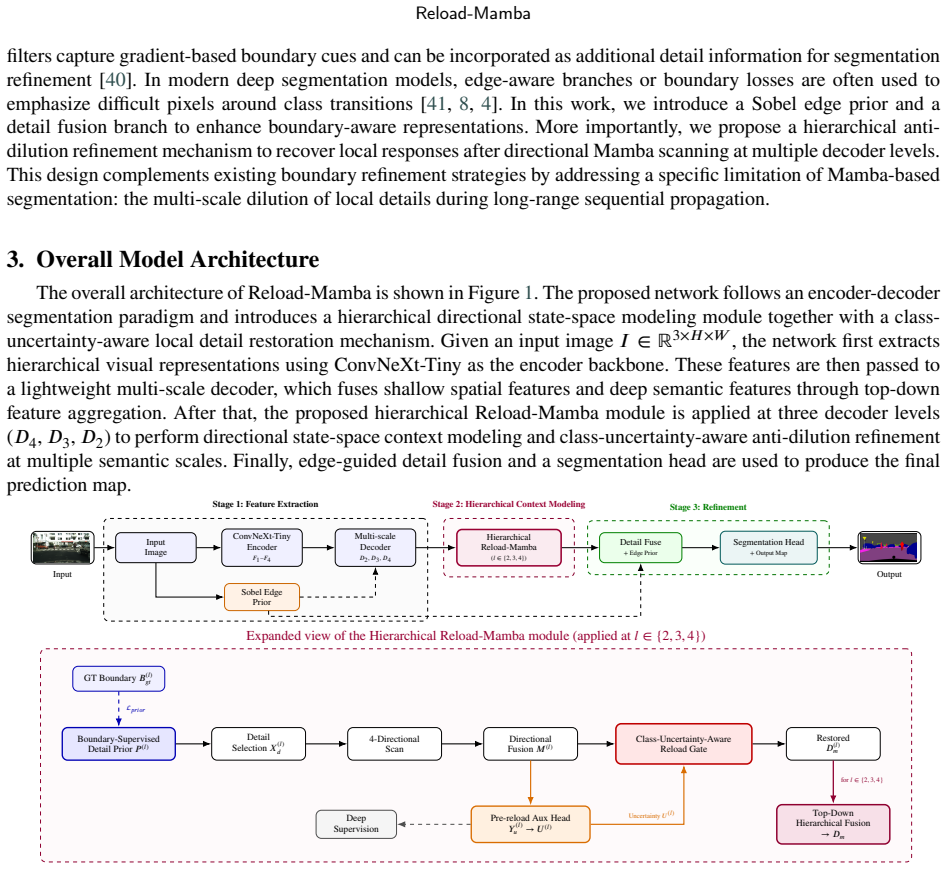
Mamba-based state space models offer linear-time long-range modeling for high-resolution dense prediction, but sequential state-space propagation can attenuate boundary-sensitive and detail-sensitive responses that are critical in multi-class semantic segmentation. We propose Reload-Mamba, a semantic segmentation framework that addresses this propagation-induced response dilution through three segmentation-specific designs: (i) a boundary-supervised local detail prior that is explicitly trained with ground-truth boundary masks to identify regions requiring response restoration; (ii) a class-uncertainty-aware Reload Gate that incorporates per-pixel class entropy from a pre-reload auxiliary head as an additional gating signal, a formulation that is informative only under multi-class dense prediction; and (iii) a hierarchical multi-level Reload mechanism that applies anti-dilution refinement at three decoder levels and fuses the restored representations top-down. Built upon a ConvNeXt-Tiny encoder with a multi-scale decoder and four-directional Mamba scanning with pixel-wise directional attention, Reload-Mamba achieves 47.9% single-scale (48.9% multi-scale) mIoU on ADE20K and 83.2% single-scale mIoU on Cityscapes. With ResNet-101 + COCO pre-training under the standard DeepLab-style protocol, Reload-Mamba reaches 87.8% mIoU on PASCAL VOC 2012 val. Controlled ablations show that each of the three segmentation-specific designs contributes beyond a direct port of the prior anti-dilution architecture proposed for binarization, cumulatively improving over the direct-port baseline by +2.2 mIoU on ADE20K.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Reload-Mamba, a Mamba-based semantic segmentation architecture that counters propagation-induced response dilution via three designs: (i) a boundary-supervised local detail prior trained on GT boundary masks, (ii) a class-uncertainty-aware Reload Gate that uses per-pixel entropy from a pre-reload auxiliary head, and (iii) a hierarchical multi-level reload mechanism applied at three decoder levels with top-down fusion. Built on a ConvNeXt-Tiny encoder with four-directional Mamba scanning and pixel-wise directional attention, the model reports 47.9% single-scale (48.9% multi-scale) mIoU on ADE20K, 83.2% on Cityscapes, and 87.8% on PASCAL VOC 2012 val. Controlled ablations claim the three designs cumulatively deliver +2.2 mIoU over a direct-port baseline.
Significance. If the +2.2 mIoU gain is shown to arise specifically from the anti-dilution mechanisms rather than auxiliary supervision or capacity, the work would offer a practical route for adapting linear-time state-space models to boundary-sensitive dense prediction. The concrete benchmark numbers and the explicit hierarchical reload formulation constitute a strength; the segmentation-specific gating that incorporates class entropy is a targeted contribution for multi-class settings.
major comments (1)
- [Ablation study] Ablation study (corresponding to the controlled ablations referenced in the abstract): the direct-port baseline must be demonstrated to match total parameter count, FLOPs, and auxiliary training protocol (including the entropy head and boundary supervision) of the full Reload-Mamba model. Without this control, the cumulative +2.2 mIoU cannot be unambiguously attributed to the three segmentation-specific designs rather than added capacity or extra supervision signals.
minor comments (2)
- [Abstract and §3] The abstract and methods should explicitly state whether the auxiliary entropy head remains active at inference or is detached, and whether its parameters are counted in the reported model size.
- [Results] No error bars or multi-seed statistics accompany the mIoU figures; adding these would strengthen the reported deltas even if not load-bearing for the central claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for tighter controls in our ablation study. We address this point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Ablation study] Ablation study (corresponding to the controlled ablations referenced in the abstract): the direct-port baseline must be demonstrated to match total parameter count, FLOPs, and auxiliary training protocol (including the entropy head and boundary supervision) of the full Reload-Mamba model. Without this control, the cumulative +2.2 mIoU cannot be unambiguously attributed to the three segmentation-specific designs rather than added capacity or extra supervision signals.
Authors: We agree that unambiguous attribution requires the direct-port baseline to match the full model in parameter count, FLOPs, and auxiliary training protocol. The current manuscript describes the baseline as a direct port of the prior binarization architecture without the three proposed designs, but does not explicitly verify equivalence of auxiliary heads or report matching FLOPs/parameters for all variants. In the revised manuscript we will add a controlled ablation table that (i) reports parameter counts and FLOPs for every configuration, (ii) equips the direct-port baseline with auxiliary entropy and boundary heads under the same training protocol, and (iii) isolates the incremental effect of the boundary-supervised prior, entropy-aware gate, and hierarchical reload. This will confirm that the reported +2.2 mIoU gain arises from the segmentation-specific mechanisms rather than added capacity or supervision. revision: yes
Circularity Check
No circularity: empirical ablation gains are measured outcomes, not derived by construction
full rationale
The paper reports measured mIoU improvements (+2.2 on ADE20K) from three segmentation designs via controlled ablations against a direct-port baseline. No equations, fitted parameters renamed as predictions, or self-definitional reductions appear in the provided text. The boundary prior and entropy head add explicit supervision, but the gains are presented as experimental results rather than forced by the model definition itself. Self-citation to a prior binarization architecture is mentioned but not load-bearing for the current claims, as the evaluation uses external benchmarks (ADE20K, Cityscapes, PASCAL VOC). The derivation chain is self-contained against external data.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Reload Gate
no independent evidence
-
boundary-supervised local detail prior
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Segnet: A deep convolutional encoder-decoder architecture for image segmentation, in: IEEE Transactions on Pattern Analysis and Machine Intelligence, pp
Badrinarayanan, V., Kendall, A., Cipolla, R., 2017. Segnet: A deep convolutional encoder-decoder architecture for image segmentation, in: IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 2481–2495
2017
-
[2]
Chan, S.W., Wang, Y.C., Pan, H.J., Lin, C.M., Chiang, J.S., 2026. Deepmine-mamba: Mitigating information dilution in mamba-based state space models for document image binarization. arXiv preprint arXiv:2606.08781
Pith/arXiv arXiv 2026
-
[3]
Rethinking atrous convolution for semantic image segmentation
Chen, L.C., Papandreou, G., Schroff, F., Adam, H., 2017. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587
Pith/arXiv arXiv 2017
-
[4]
Encoder-decoder with atrous separable convolution for semantic image segmentation, in: Proceedings of the European Conference on Computer Vision, pp
Chen, L.C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H., 2018. Encoder-decoder with atrous separable convolution for semantic image segmentation, in: Proceedings of the European Conference on Computer Vision, pp. 801–818
2018
-
[5]
Tensor low-rank reconstruction for semantic segmentation, in: European Conference on Computer Vision, pp
Chen, W., Zhu, X., Sun, R., He, J., Li, R., Shen, X., Yu, B., 2020. Tensor low-rank reconstruction for semantic segmentation, in: European Conference on Computer Vision, pp. 52–69
2020
-
[6]
Thecityscapesdatasetfor semantic urban scene understanding, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Cordts,M.,Omran,M.,Ramos,S.,Rehfeld,T.,Enzweiler,M.,Benenson,R.,Franke,U.,Roth,S.,Schiele,B.,2016. Thecityscapesdatasetfor semantic urban scene understanding, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3213–3223
2016
-
[7]
Imagenet: A large-scale hierarchical image database, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L., 2009. Imagenet: A large-scale hierarchical image database, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255
2009
-
[8]
Boundary-aware feature propagation for scene segmentation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Ding, H., Jiang, X., Liu, A.Q., Magnenat-Thalmann, N., Wang, G., 2019. Boundary-aware feature propagation for scene segmentation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6819–6829
2019
-
[9]
An image is worth 16x16 words: Transformers for image recognition at scale, in: International Conference on Learning Representations
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N., 2021. An image is worth 16x16 words: Transformers for image recognition at scale, in: International Conference on Learning Representations
2021
-
[10]
Thepascalvisualobjectclasses(voc)challenge
Everingham,M.,VanGool,L.,Williams,C.K.I.,Winn,J.,Zisserman,A.,2010. Thepascalvisualobjectclasses(voc)challenge. International Journal of Computer Vision 88, 303–338
2010
-
[11]
Dualattentionnetworkforscenesegmentation,in:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Fu,J.,Liu,J.,Tian,H.,Li,Y.,Bao,Y.,Fang,Z.,Lu,H.,2019. Dualattentionnetworkforscenesegmentation,in:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3146–3154
2019
-
[12]
SegMAN:Omni-scalecontextmodelingwithstatespacemodelsandlocalattentionforsemanticsegmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fu,Y.,Lou,M.,Yu,Y.,2025. SegMAN:Omni-scalecontextmodelingwithstatespacemodelsandlocalattentionforsemanticsegmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2025
-
[13]
Mamba: Linear-time sequence modeling with selective state spaces
Gu, A., Dao, T., 2023. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752
Pith/arXiv arXiv 2023
-
[14]
Efficiently modeling long sequences with structured state spaces, in: International Conference on Learning Representations
Gu, A., Goel, K., Ré, C., 2022. Efficiently modeling long sequences with structured state spaces, in: International Conference on Learning Representations
2022
-
[15]
Segnext: Rethinking convolutional attention design for semantic segmentation, in: Advances in Neural Information Processing Systems, pp
Guo, M.H., Lu, C.Z., Hou, Q., Liu, Z., Cheng, M.M., Hu, S.M., 2022. Segnext: Rethinking convolutional attention design for semantic segmentation, in: Advances in Neural Information Processing Systems, pp. 1140–1156
2022
-
[16]
Semantic contours from inverse detectors, in: Proceedings of the IEEE International Conference on Computer Vision, pp
Hariharan, B., Arbelaez, P., Bourdev, L., Maji, S., Malik, J., 2011. Semantic contours from inverse detectors, in: Proceedings of the IEEE International Conference on Computer Vision, pp. 991–998. S.W. Chan:Preprint submitted to ElsevierPage 21 of 23 Reload-Mamba
2011
-
[17]
Mambavision:Ahybridmamba-transformervisionbackbone,in:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition
Hatamizadeh,A.,Kautz,J.,2025. Mambavision:Ahybridmamba-transformervisionbackbone,in:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition
2025
-
[18]
Deepresiduallearningforimagerecognition,in:ProceedingsoftheIEEEConferenceonComputer Vision and Pattern Recognition, pp
He,K.,Zhang,X.,Ren,S.,Sun,J.,2016. Deepresiduallearningforimagerecognition,in:ProceedingsoftheIEEEConferenceonComputer Vision and Pattern Recognition, pp. 770–778
2016
-
[19]
Localmamba: Visual state space model with windowed selective scan
Huang, T., Pei, X., You, S., Wang, F., Qian, C., Xu, C., 2024. Localmamba: Visual state space model with windowed selective scan. arXiv preprint arXiv:2403.09338
arXiv 2024
-
[20]
Ccnet: Criss-cross attention for semantic segmentation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., Liu, W., 2019. Ccnet: Criss-cross attention for semantic segmentation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 603–612
2019
-
[21]
Alignseg: Feature-aligned segmentation networks
Huang, Z., Wei, Y., Wang, X., Liu, W., Huang, T.S., Shi, H., 2022. Alignseg: Feature-aligned segmentation networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 44, 550–557
2022
-
[22]
Deeply-supervisednets,in:ProceedingsoftheEighteenthInternationalConference on Artificial Intelligence and Statistics, pp
Lee,C.Y.,Xie,S.,Gallagher,P.,Zhang,Z.,Tu,Z.,2015. Deeply-supervisednets,in:ProceedingsoftheEighteenthInternationalConference on Artificial Intelligence and Statistics, pp. 562–570
2015
-
[23]
Semantic flow for fast and accurate scene parsing, in: European Conference on Computer Vision, Springer
Li, X., You, A., Zhu, Z., Zhao, H., Yang, M., Yang, K., Tong, Y., 2020. Semantic flow for fast and accurate scene parsing, in: European Conference on Computer Vision, Springer. pp. 775–793
2020
-
[24]
Expectation-maximization attention networks for semantic segmentation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Li, X., Zhong, Z., Wu, J., Yang, Y., Lin, Z., Liu, H., 2019. Expectation-maximization attention networks for semantic segmentation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9167–9176
2019
-
[25]
Feature pyramid networks for object detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S., 2017. Feature pyramid networks for object detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2117–2125
2017
-
[26]
Microsoft coco: Common objects in context, in: European Conference on Computer Vision, Springer
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L., 2014. Microsoft coco: Common objects in context, in: European Conference on Computer Vision, Springer. pp. 740–755
2014
-
[27]
Vmamba: Visual state space model, in: Advances in Neural Information Processing Systems
Liu, Y., Tian, Y., Zhao, Y., Yu, H., Xie, L., Wang, Y., Ye, Q., Jiao, J., Liu, Y., 2024. Vmamba: Visual state space model, in: Advances in Neural Information Processing Systems
2024
-
[28]
Swin transformer: Hierarchical vision transformer using shifted windows, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B., 2021. Swin transformer: Hierarchical vision transformer using shifted windows, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10012–10022
2021
-
[29]
Aconvnetforthe2020s,in:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition, pp
Liu,Z.,Mao,H.,Wu,C.Y.,Feichtenhofer,C.,Darrell,T.,Xie,S.,2022. Aconvnetforthe2020s,in:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition, pp. 11976–11986
2022
-
[30]
Fully convolutional networks for semantic segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Long, J., Shelhamer, E., Darrell, T., 2015. Fully convolutional networks for semantic segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3431–3440
2015
-
[31]
Decoupled weight decay regularization, in: International Conference on Learning Representations
Loshchilov, I., Hutter, F., 2019. Decoupled weight decay regularization, in: International Conference on Learning Representations
2019
-
[32]
Lou, M., Fu, Y., Yu, Y., 2024. SparX: A sparse cross-layer connection mechanism for hierarchical vision mamba and transformer networks. arXiv preprint arXiv:2409.09649
arXiv 2024
-
[33]
U-mamba: Enhancing long-range dependency for biomedical image segmentation
Ma, J., Li, F., Wang, B., 2024. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722
Pith/arXiv arXiv 2024
-
[34]
The mapillary vistas dataset for semantic understanding of street scenes, in: Proceedings of the IEEE International Conference on Computer Vision, pp
Neuhold, G., Ollmann, T., Rota Bulo, S., Kontschieder, P., 2017. The mapillary vistas dataset for semantic understanding of street scenes, in: Proceedings of the IEEE International Conference on Computer Vision, pp. 4990–4999
2017
-
[35]
Pytorch: An imperative style, high-performance deep learning library, in: Advances in Neural Information Processing Systems
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S., 2019. Pytorch: An imperative style, high-performance deep learning library, in: Advances in Neural In...
2019
-
[36]
U-net:Convolutionalnetworksforbiomedicalimagesegmentation,in:MedicalImageComputing and Computer-Assisted Intervention, Springer
Ronneberger,O.,Fischer,P.,Brox,T.,2015. U-net:Convolutionalnetworksforbiomedicalimagesegmentation,in:MedicalImageComputing and Computer-Assisted Intervention, Springer. pp. 234–241
2015
-
[37]
Vm-unet: Vision mamba unet for medical image segmentation
Ruan, J., Xiang, S., 2024. Vm-unet: Vision mamba unet for medical image segmentation. arXiv preprint arXiv:2402.02491
arXiv 2024
-
[38]
Multi-scale vmamba: Hierarchy in hierarchy visual state space model
Shi, Y., Dong, M., Xu, C., 2024. Multi-scale vmamba: Hierarchy in hierarchy visual state space model. arXiv preprint arXiv:2405.14174
arXiv 2024
-
[39]
Very deep convolutional networks for large-scale image recognition, in: International Conference on Learning Representations
Simonyan, K., Zisserman, A., 2015. Very deep convolutional networks for large-scale image recognition, in: International Conference on Learning Representations
2015
-
[40]
An isotropic 3x3 image gradient operator
Sobel, I., Feldman, G., 1968. An isotropic 3x3 image gradient operator. Presented at the Stanford Artificial Intelligence Project
1968
-
[41]
Gated-scnn: Gated shape cnns for semantic segmentation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Takikawa, T., Acuna, D., Jampani, V., Fidler, S., 2019. Gated-scnn: Gated shape cnns for semantic segmentation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5229–5238
2019
-
[42]
Spatial-Mamba: Effective visual state space models via structure-aware state fusion
Xiao, C., Li, M., Zhang, Z., Meng, D., Zhang, L., 2024. Spatial-Mamba: Effective visual state space models via structure-aware state fusion. arXiv preprint arXiv:2410.15091
arXiv 2024
-
[43]
Segformer: Simple and efficient design for semantic segmentation with transformers, in: Advances in Neural Information Processing Systems, pp
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P., 2021. Segformer: Simple and efficient design for semantic segmentation with transformers, in: Advances in Neural Information Processing Systems, pp. 12077–12090
2021
-
[44]
Aggregated residual transformations for deep neural networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K., 2017. Aggregated residual transformations for deep neural networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1492–1500
2017
-
[45]
Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation, in: Medical Image Computing and Computer Assisted Intervention, Springer
Xing, Z., Ye, T., Yang, Y., Liu, G., Zhu, L., 2024. Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation, in: Medical Image Computing and Computer Assisted Intervention, Springer. pp. 578–588
2024
-
[46]
Focal self-attention for local-global interactions in vision transformers, in: Advances in Neural Information Processing Systems, pp
Yang, J., Li, C., Zhang, P., Dai, X., Xiao, B., Yuan, L., Gao, J., 2021. Focal self-attention for local-global interactions in vision transformers, in: Advances in Neural Information Processing Systems, pp. 30008–30022
2021
-
[47]
Learning a discriminative feature network for semantic segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Yu, C., Wang, J., Peng, C., Gao, C., Yu, G., Sang, N., 2018. Learning a discriminative feature network for semantic segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1857–1866
2018
-
[48]
Mambaout:Dowereallyneedmambaforvision?,in:ProceedingsoftheIEEE/CVFConferenceonComputerVision and Pattern Recognition
Yu,W.,Wang,X.,2025. Mambaout:Dowereallyneedmambaforvision?,in:ProceedingsoftheIEEE/CVFConferenceonComputerVision and Pattern Recognition
2025
-
[49]
Object-contextual representations for semantic segmentation, in: European Conference on Computer Vision, Springer
Yuan, Y., Chen, X., Wang, J., 2020. Object-contextual representations for semantic segmentation, in: European Conference on Computer Vision, Springer. pp. 173–190. S.W. Chan:Preprint submitted to ElsevierPage 22 of 23 Reload-Mamba
2020
-
[50]
Contextencodingforsemanticsegmentation,in:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Zhang,H.,Dana,K.,Shi,J.,Zhang,Z.,Wang,X.,Tyagi,A.,Agrawal,A.,2018. Contextencodingforsemanticsegmentation,in:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7151–7160
2018
-
[51]
Co-occurrentfeaturesinsemanticsegmentation,in:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition, pp
Zhang,H.,Zhang,H.,Wang,C.,Xie,J.,2019. Co-occurrentfeaturesinsemanticsegmentation,in:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition, pp. 548–557
2019
-
[52]
Pyramidsceneparsingnetwork,in:ProceedingsoftheIEEEConferenceonComputerVision and Pattern Recognition, pp
Zhao,H.,Shi,J.,Qi,X.,Wang,X.,Jia,J.,2017. Pyramidsceneparsingnetwork,in:ProceedingsoftheIEEEConferenceonComputerVision and Pattern Recognition, pp. 2881–2890
2017
-
[53]
Scene parsing through ade20k dataset, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A., 2017. Scene parsing through ade20k dataset, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 633–641
2017
-
[54]
Vision mamba: Efficient visual representation learning with bidirectional state space model
Zhu, L., Liao, B., Zhang, Q., Wang, X., Liu, W., Wang, X., 2024. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv preprint arXiv:2401.09417 . S.W. Chan:Preprint submitted to ElsevierPage 23 of 23
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.