Planning to Hammer: Difficulty-Aware Decomposition for Automating Rocq Proofs
Pith reviewed 2026-06-26 23:37 UTC · model grok-4.3
The pith
Quarry improves Rocq proof success rates by 7% to 13% using solvability-ranked decompositions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Quarry asks an LLM to propose multiple proof decompositions with arbitrary sublemmas, type-checks them in Rocq under admitted sublemmas, ranks the candidates by a proof-state-based difficulty model that predicts hammer solvability, and recursively proves sublemmas within a bounded budget, turning long proofs into sequences of hammer-solvable obligations and delivering 7% to 13% higher success rates than the strongest baseline across three Rocq benchmarks under a uniform 10-minute wall-clock limit.
What carries the argument
The proof-state-based difficulty model that estimates hammer solvability of LLM-proposed decompositions to enable ranking and recursive sublemma proving.
If this is right
- Long proofs reduce to sequences of short obligations that CoqHammer can discharge.
- Success rates rise 7% to 13% over baselines while cost stays predictable inside a fixed time limit.
- The same planning-plus-execution loop works with multiple frontier LLMs on multiple benchmarks.
- Neural planning and symbolic tactics coordinate without one replacing the other.
Where Pith is reading between the lines
- The same decomposition-ranking idea could be tested on Isabelle or other interactive provers that have strong automated tactics.
- If the difficulty model generalizes beyond CoqHammer, it might support hybrid automation for additional tactics or provers.
- Higher automation rates could shorten the time needed to verify larger codebases generated by AI tools.
Load-bearing premise
The difficulty model accurately predicts which decompositions will be solvable by CoqHammer so that ranking selects effective paths.
What would settle it
A set of proof attempts where the model consistently ranks decompositions that later fail hammer solving above ones that succeed, causing overall failure within the 10-minute budget.
Figures
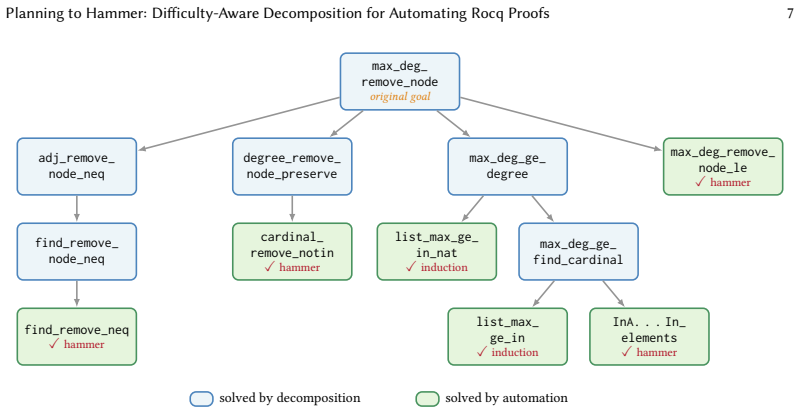
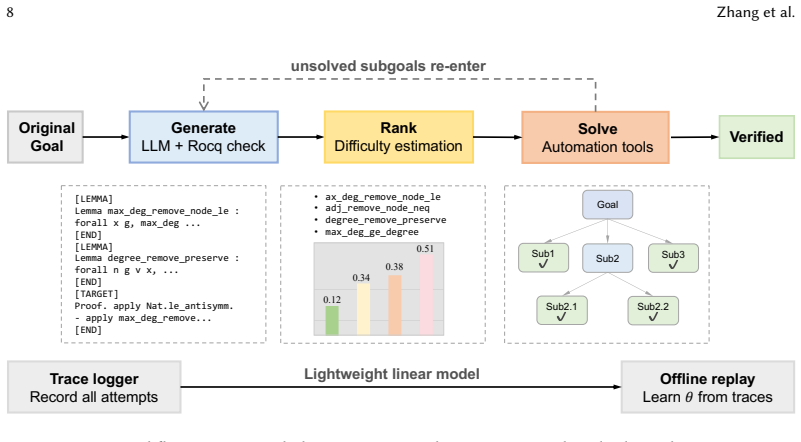

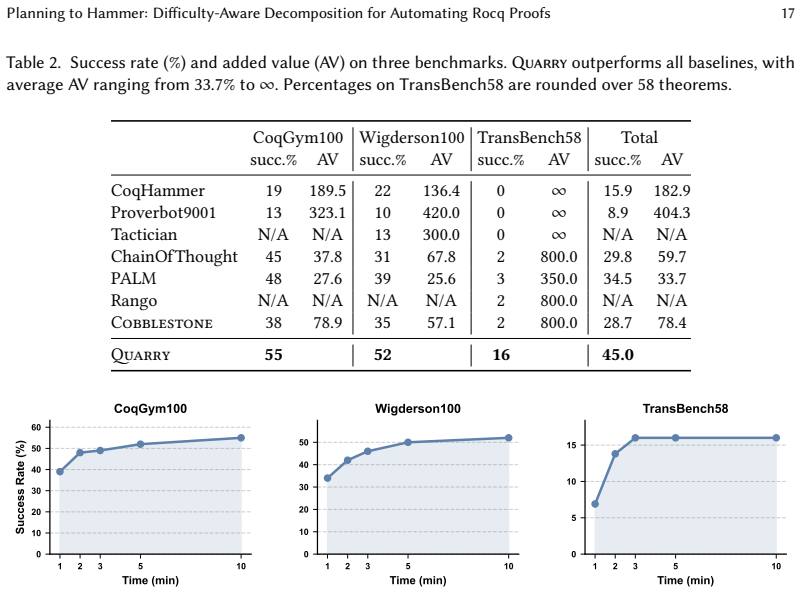
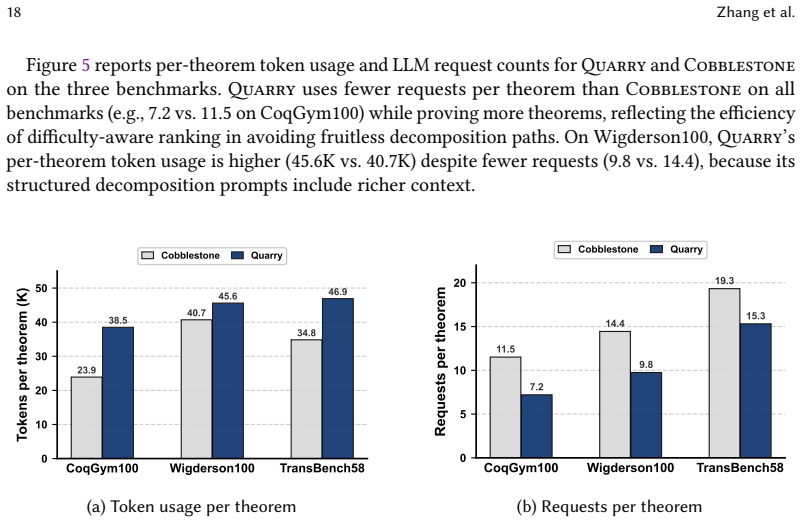
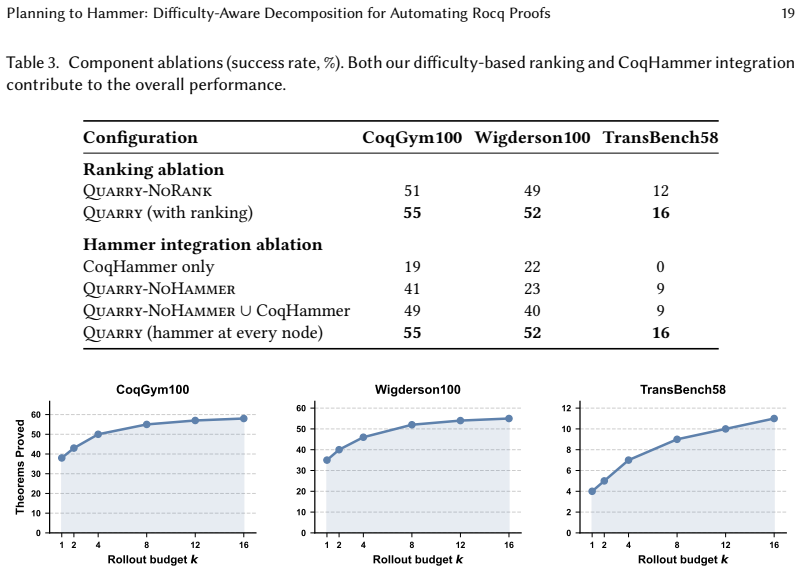
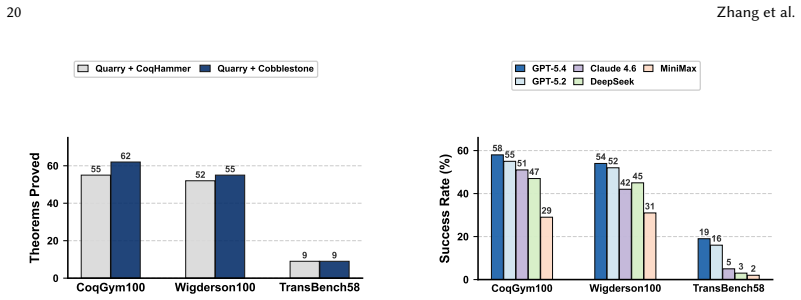
read the original abstract
As AI-generated code proliferates, formal verification, particularly through interactive theorem provers such as Rocq and Isabelle, becomes increasingly important for ensuring software correctness. However, producing machine-checked proofs in such provers remains a bottleneck. Existing solutions bring complementary strengths to proof automation: large language models (LLMs) can propose high-level proof strategies but lack local rigor, while automated tactics such as CoqHammer can reliably discharge many local goals but lack long-range planning capabilities. To combine the best of both worlds, we present Quarry, a planning-based proof synthesis framework that separates proof planning from proof execution. Specifically, Quarry asks an LLM to actively propose multiple proof decompositions with arbitrary sublemmas, type-checks them in Rocq under temporarily admitted sublemmas, and ranks candidates using a proof-state-based difficulty model that estimates hammer solvability. It then recursively proves sublemmas within a bounded budget, effectively turning long proofs into sequences of hammer-solvable obligations. We implement Quarry on top of SerAPI and CoqHammer and evaluate it using multiple frontier LLMs across multiple benchmarks. The experimental results show that planning-based decomposition with solvability-aware ranking substantially improves automation while maintaining predictable cost. Under a uniform 10-minute wall-clock budget, Quarry improves over the strongest baseline by 7% to 13% in success rate across three Rocq benchmarks. These results demonstrate that reliable proof automation can be achieved by coordinating neural planning with symbolic execution rather than replacing either.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Quarry, a planning-based proof synthesis framework for Rocq that separates LLM-driven proof decomposition (proposing sublemmas) from execution. It type-checks candidate decompositions under admitted sublemmas, ranks them via a proof-state-based difficulty model estimating CoqHammer solvability, and recursively discharges sublemmas within a uniform 10-minute wall-clock budget. The central empirical claim is that this yields 7-13% higher success rates than the strongest baseline across three Rocq benchmarks when using frontier LLMs.
Significance. If the results are robust, the work demonstrates a practical hybrid architecture that leverages LLM long-range planning while retaining the local rigor of symbolic tactics such as CoqHammer. This coordination approach, rather than end-to-end replacement, addresses a recognized bottleneck in interactive theorem proving and supplies a concrete, budget-constrained evaluation protocol that could be adopted by subsequent systems.
major comments (2)
- [§3] The difficulty model is load-bearing for the ranking and recursive decomposition claims (§3, difficulty-aware ranking paragraph), yet the manuscript supplies no training procedure, feature definition, or validation against actual hammer outcomes; without these, it is impossible to assess whether the model reliably predicts solvability or merely correlates with superficial proof-state properties.
- [§5] The reported 7-13% gains rest on comparisons to external baselines, but the evaluation section provides no information on benchmark definitions, baseline re-implementations, statistical significance tests, error bars, or data-exclusion rules; this absence prevents verification that the stated improvements support the central claim.
minor comments (2)
- [§3.2] Notation for the difficulty score and the precise interface between SerAPI and the ranking step could be clarified with a small pseudocode listing or equation.
- [Abstract] The abstract and introduction repeat the 7-13% figure without indicating whether it is an absolute or relative improvement; a single clarifying sentence would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness where the concerns are valid.
read point-by-point responses
-
Referee: [§3] The difficulty model is load-bearing for the ranking and recursive decomposition claims (§3, difficulty-aware ranking paragraph), yet the manuscript supplies no training procedure, feature definition, or validation against actual hammer outcomes; without these, it is impossible to assess whether the model reliably predicts solvability or merely correlates with superficial proof-state properties.
Authors: We agree that the current description of the difficulty model in §3 is insufficiently detailed for assessing its reliability. The model is intended as a lightweight estimator of CoqHammer solvability based on proof-state features, but the manuscript does not provide the requested specifics. In the revised version we will expand the section to define the exact features, describe the training procedure (including the dataset construction and learning method), and report validation results comparing model predictions to actual hammer success rates on held-out proof states. This addition will directly address the concern about predictive power versus superficial correlation. revision: yes
-
Referee: [§5] The reported 7-13% gains rest on comparisons to external baselines, but the evaluation section provides no information on benchmark definitions, baseline re-implementations, statistical significance tests, error bars, or data-exclusion rules; this absence prevents verification that the stated improvements support the central claim.
Authors: We acknowledge that §5 currently lacks the level of detail needed for full reproducibility and verification of the reported gains. In the revised manuscript we will augment the evaluation section with: explicit definitions and sources for the three Rocq benchmarks, descriptions of baseline re-implementations (including any adaptations made), results of statistical significance tests with appropriate error bars or confidence intervals, and a clear statement of any data-exclusion criteria. These additions will allow independent assessment of whether the 7-13% improvements are robustly supported. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical system (Quarry) that combines LLM planning with CoqHammer execution and a difficulty model for ranking decompositions. All reported results are direct success-rate comparisons against external baselines under a fixed wall-clock budget; no equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The architecture is presented as a pragmatic engineering combination rather than a mathematical derivation that reduces to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi:10.1007/s10817-013-9286-5 Alexander A
Premise selection for mathematics by corpus analysis and kernel methods.Journal of Automated Reasoning52, 2 (2014), 191–213. doi:10.1007/s10817-013-9286-5 Alexander A. Alemi, François Chollet, Niklas Een, Geoffrey Irving, Christian Szegedy, and Josef Urban
-
[2]
Learning to Reason in Large Theories without Imitation.arXiv preprint arXiv:1905.10501(2019). Lasse Blaauwbroek, Mirek Olšák, Jason Rute, Fidel Ivan Schaposnik Massolo, Jelle Piepenbrock, and Vasily Pestun
arXiv 1905
-
[3]
InInternational Conference on Intelligent Computer Mathematics
The Tactician: A Seamless, Interactive Tactic Learner and Prover for Coq. InInternational Conference on Intelligent Computer Mathematics. 271–277. doi:10.1007/978-3-030-53518-6_17 Chenrui Cao, Liangcheng Song, Zenan Li, Xinyi Le, Xian Zhang, Hui Xue, and Fan Yang
-
[4]
Haogang Chen, Daniel Ziegler, Tej Chajed, Adam Chlipala, M
Reviving DSP for advanced theorem proving in the era of reasoning models.Advances in Neural Information Processing Systems38 (2026), 74116– 74154. Haogang Chen, Daniel Ziegler, Tej Chajed, Adam Chlipala, M. Frans Kaashoek, and Nickolai Zeldovich
2026
-
[5]
InProceedings of the 25th ACM Symposium on Operating Systems Principles (SOSP)
Using Crash Hoare Logic for Certifying the FSCQ File System. InProceedings of the 25th ACM Symposium on Operating Systems Principles (SOSP). ACM, New York, NY, USA, 18–37. doi:10.1145/2815400.2815402 Łukasz Czajka and Cezary Kaliszyk
-
[6]
Hammer for Coq: Automation for Dependent Type Theory.Journal of Automated Reasoning61, 1-4 (2018), 423–453. doi:10.1007/s10817-018-9458-4 Andres Erbsen, Jade Philipoom, Jason Gross, Robert Sloan, and Adam Chlipala
-
[7]
Frontiers in Astronomy and Space Sciences , keywords =
Simple High-Level Code for Crypto- graphic Arithmetic — With Proofs, Without Compromises. InIEEE Symposium on Security and Privacy (S&P). 1202–1219. doi:10.1109/SP.2019.00005 Proc. ACM Program. Lang., Vol. 1, No. 1, Article . Publication date: June
-
[8]
Emily First, Markus N
TacTok: Semantics-aware proof synthesis.Proceedings of the ACM on Programming Languages4, OOPSLA (2020), 1–31. Emily First, Markus N. Rabe, Talia Ringer, and Yuriy Brun
2020
-
[9]
Baldur: Whole-Proof Generation and Repair with Large Language Models. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE ’23), December 3-9, 2023, San Francisco, CA, USA. ACM, New York, NY, USA, 1229–1241. https://doi.org/10.1145/3611643.3616243 Emilio Jesús Galle...
-
[10]
Daniel Huang, Prafulla Dhariwal, Dawn Song, and Ilya Sutskever
Neuro-symbolic proof generation for scaling systems software verification.arXiv preprint arXiv:2603.19715(2026). Daniel Huang, Prafulla Dhariwal, Dawn Song, and Ilya Sutskever
Pith/arXiv arXiv 2026
-
[11]
In Advances in Neural Information Processing Systems
Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers. In Advances in Neural Information Processing Systems. 8360–8373. https://proceedings.neurips.cc/paper_files/paper/2022/ file/377c25312668e48f2e531e2f2c422483-Paper-Conference.pdf Albert Qiaochu Jiang, Sean Welleck, Jin Peng Zhou, Timothee Lacroix, Jiacheng Liu, Wenda Li, Ma...
2022
-
[12]
InProceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE)
Cobblestone: A Divide-and-Conquer Approach for Automating Formal Verification. InProceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE). Rio de Janeiro, Brazil. doi:10.1145/3744916.3773178 Xavier Leroy
-
[13]
doi:10.1145/1538788.1538814 Xupeng Li, Xuheng Li, Wei Qiang, Ronghui Gu, and Jason Nieh
Formal verification of a realistic compiler.Communications of the ACM (CACM)52, 7 (2009), 107–115. doi:10.1145/1538788.1538814 Xupeng Li, Xuheng Li, Wei Qiang, Ronghui Gu, and Jason Nieh
-
[14]
A Survey on Deep Learning for Theorem Proving.arXiv preprint arXiv:2404.09939(2024). Zenan Li, Ziran Yang, Deyuan He, Haoyu Zhao, Andrew Zhao, Shange Tang, Kaiyu Yang, Aarti Gupta, Zhendong Su, and Chi Jin
arXiv 2024
-
[15]
Goedel-code-prover: Hierarchical proof search for open state-of-the-art code verification.arXiv preprint arXiv:2603.19329(2026). Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al
arXiv 2026
-
[16]
Minghai Lu, Benjamin Delaware, and Tianyi Zhang
Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556 (2025). Minghai Lu, Benjamin Delaware, and Tianyi Zhang
Pith/arXiv arXiv 2025
-
[17]
Proof Automation with Large Language Models. In39th IEEE/ACM International Conference on Automated Software Engineering (ASE ’24), October 27-November 1, 2024, Sacramento, CA, USA. ACM, New York, NY, USA, 1509–1520. doi:10.1145/3691620.3695521 Maciej Mikuła, Szymon Tworkowski, Szymon Antoniak, Bartosz Piotrowski, Albert Q. Jiang, Jin Peng Zhou, Christian ...
-
[18]
InThe Twelfth International Conference on Learning Representations
Magnushammer: A Transformer-Based Approach to Premise Selection. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=oYjPk8mqAV MiniMax. 2026.MiniMax M2.5: Built for Real-World Productivity.Technical Report. https://minimaxi.com/news/minimax-m25 Tobias Nipkow, Markus Wenzel, and Lawrence C Paulson. 2002.Isab...
2026
-
[19]
InCompanion Proceedings of the 2023 ACM SIGPLAN International Conference on Systems, Programming, Languages, and Applications: Software Proc
Towards the Formal Verification of Wigderson’s Algorithm. InCompanion Proceedings of the 2023 ACM SIGPLAN International Conference on Systems, Programming, Languages, and Applications: Software Proc. ACM Program. Lang., Vol. 1, No. 1, Article . Publication date: June
2023
-
[20]
for Humanity(Cascais, Portugal)(SPLASH 2023)
26 Zhang et al. for Humanity(Cascais, Portugal)(SPLASH 2023). Association for Computing Machinery, New York, NY, USA, 40–42. doi:10.1145/3618305.3623600 Talia Ringer, RanDair Porter, Nathaniel Yazdani, John Leo, and Dan Grossman
-
[21]
Proof Repair Across Type Equivalences. InProceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation (PLDI ’21), June 20-25, 2021, Virtual, Canada. ACM, New York, NY, USA, 112–127. doi:10.1145/3453483.3454033 Alex Sanchez-Stern, Yousef Alhessi, Lawrence Saul, and Sorin Lerner
-
[22]
Generating Correctness Proofs with Neural Networks. InProceedings of the 4th ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (MAPL ’20), June 15, 2020, London, UK. ACM, New York, NY, USA, 1–10. https://doi.org/10.1145/3394450.3397466 Alex Sanchez-Stern, Emily First, Timothy Zhou, Zhanna Kaufman, Yuriy Brun, and Talia Ringer
-
[23]
Passport: Improving Automated Formal Verification Using Identifiers.ACM Trans. Program. Lang. Syst.45, 2, Article 12 (2023), 30 pages. https://doi.org/10.1145/3593374 The Coq Development Team
-
[24]
Hilbert: Recursively building formal proofs with informal reasoning.arXiv preprint arXiv:2509.22819(2025). Haiming Wang, Huajian Xin, Zhengying Liu, Wenda Li, Yinya Huang, Jianqiao Lu, Zhicheng YANG, Jing Tang, Jian Yin, Zhenguo Li, and Xiaodan Liang. 2024a. Proving Theorems Recursively. InThe Thirty-eighth Annual Conference on Neural Information Processi...
arXiv 2025
-
[25]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.Advances in Neural Information Processing Systems35 (2022), 24824–24837. James R. Wilcox, Doug Woos, Pavel Panchekha, Zachary Tatlock, Xi Wang, Michael D. Ernst, and Thomas Anderson
2022
-
[26]
Verdi: A Framework for Implementing and Formally Verifying Distributed Systems. InProceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). ACM, New York, NY, USA, 357–368. doi:10.1145/2737924.2737958 Chenyuan Yang, Xuheng Li, Md Rakib Hossain Misu, Jianan Yao, Weidong Cui, Yeyun Gong, Chris Hawblitzel, Shuve...
-
[27]
ACM69, 3 (2026), 66–73
Formal reasoning meets llms: Toward ai for mathematics and verification.Commun. ACM69, 3 (2026), 66–73. Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar
2026
-
[28]
21573–21612. Proc. ACM Program. Lang., Vol. 1, No. 1, Article . Publication date: June 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.