AIGS-Net: Compact Illumination Field Modeling via 2D Gaussian Splatting for Fast Low-Light Image Enhancement
Pith reviewed 2026-06-27 00:59 UTC · model grok-4.3
The pith
AIGS-Net builds input-adaptive illumination fields from 2D Gaussian splatting using roughly 40 parameters for low-light enhancement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
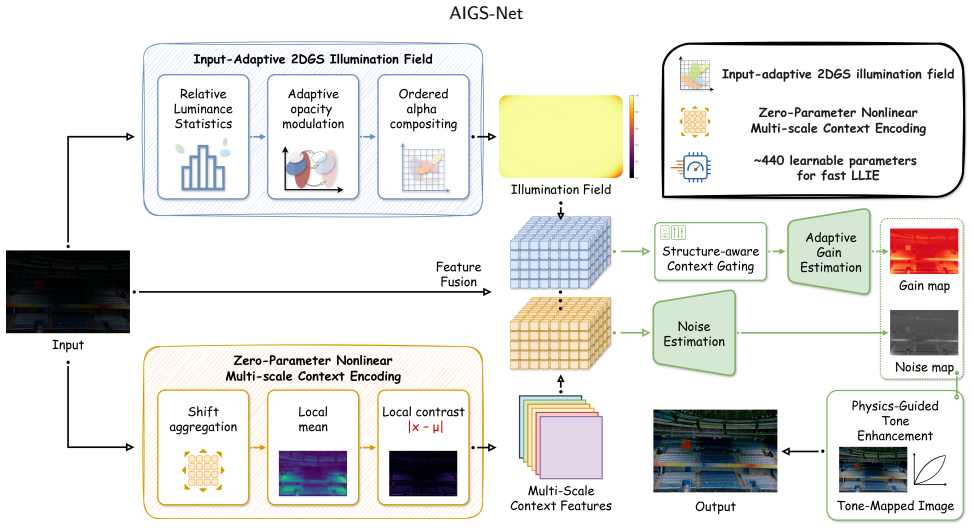
AIGS-Net constructs an input-adaptive 2D Gaussian Splatting illumination field where the opacity of Gaussian basis functions is dynamically modulated by relative luminance statistics of the input image, and spatially varying illumination compensation is rendered through ordered alpha compositing, guided by a zero-parameter nonlinear multiscale contextual encoding module and constrained by noise-mask estimation, locked single-channel Gamma mapping, cross-channel consistency regularization, and target color-alignment constraints.
What carries the argument
Adaptive Illumination Gaussian Splatting, in which 2D Gaussian basis functions receive luminance-modulated opacity and are composited via ordered alpha blending to produce the illumination compensation field.
If this is right
- Low-light enhancement can run with extreme inference efficiency on devices with limited compute.
- Illumination compensation can be represented compactly while retaining spatial variation through Gaussian basis functions.
- Contextual encoding for guiding compensation can be achieved without introducing trainable convolutional weights.
- Noise amplification and color bias can be controlled through integrated mask estimation and cross-channel constraints.
- The trade-off between enhancement quality and parameter count holds on the LOL and LSRW benchmarks.
Where Pith is reading between the lines
- The same luminance-driven Gaussian modulation could be tested for other adaptive field tasks such as exposure correction or dehazing.
- Extending the ordered compositing to temporal sequences might support video enhancement with similar parameter counts.
- The zero-parameter encoding module suggests a route to parameter-free guidance in related restoration networks.
- Deployment on mobile hardware would be a direct next measurement to verify the claimed inference efficiency.
Load-bearing premise
Dynamically modulating the opacity of 2D Gaussian basis functions by relative luminance statistics of the input and rendering via ordered alpha compositing will produce effective spatially varying illumination compensation without artifacts or noise amplification.
What would settle it
Evaluating AIGS-Net on the LOL or LSRW test sets and observing either no measurable gain in detail recovery or color fidelity metrics or a parameter count substantially above 40 would falsify the central efficiency and effectiveness claim.
Figures



read the original abstract
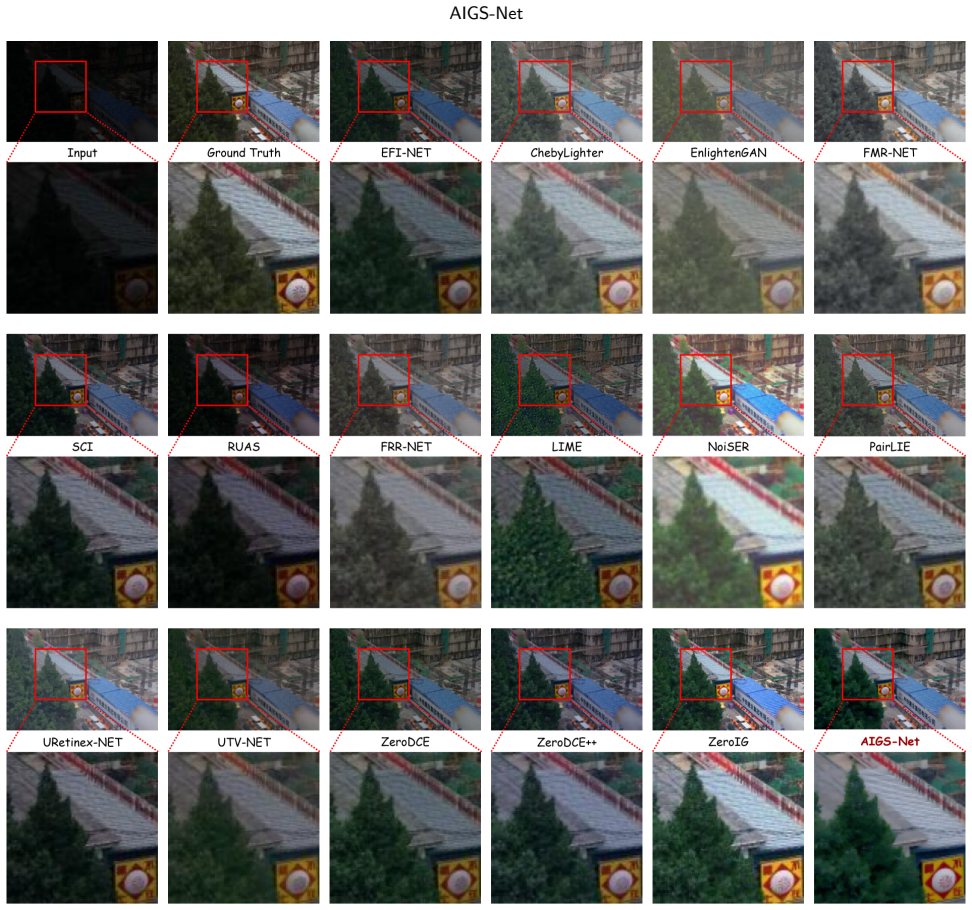
Existing low-light image enhancement methods often face a bottleneck between the representation capacity of illumination-field modeling and computational complexity. To address this issue, this paper proposes an Adaptive Illumination Gaussian Splatting Network (AIGS-Net), an ultra-lightweight architecture for fast low-light enhancement. Unlike conventional static priors, AIGS-Net constructs an input-adaptive 2D Gaussian Splatting illumination field. The opacity of Gaussian basis functions is dynamically modulated by relative luminance statistics of the input image, and spatially varying illumination compensation is rendered through ordered alpha compositing. To guide adaptive illumination compensation efficiently, a zero-parameter nonlinear multiscale contextual encoding module is introduced to extract low-frequency structures and local contrast cues without additional convolutional weights. To suppress noise amplification and sensor-induced color bias, AIGS-Net integrates noise-mask estimation, locked single-channel Gamma mapping, cross-channel consistency regularization, and target color-alignment constraints. Experiments on LOL and LSRW benchmarks show that AIGS-Net improves detail recovery and color fidelity while requiring only approximately 40 learnable parameters, achieving an effective trade-off between enhancement quality and extreme inference efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AIGS-Net, an ultra-lightweight architecture for low-light image enhancement that constructs an input-adaptive 2D Gaussian Splatting illumination field. Opacities of the Gaussian basis functions are dynamically modulated by relative luminance statistics of the input, with spatially varying compensation rendered via ordered alpha compositing. A zero-parameter nonlinear multiscale contextual encoding module extracts low-frequency structures and local contrast cues. Additional components include noise-mask estimation, locked single-channel Gamma mapping, cross-channel consistency regularization, and target color-alignment constraints. Experiments on LOL and LSRW benchmarks report improved detail recovery and color fidelity with approximately 40 learnable parameters, emphasizing an efficiency-quality trade-off.
Significance. If the reported results and efficiency claims hold under full verification, the work is significant for showing that effective spatially varying illumination modeling is possible with an extremely small parameter count (~40), far below typical CNN- or transformer-based low-light enhancers. The combination of luminance-modulated 2D Gaussian splatting with a zero-parameter encoder offers a coherent, novel route to real-time enhancement on edge devices. Explicit credit is due for the parameter-free encoding module and the set of targeted regularizations addressing noise and color bias.
minor comments (3)
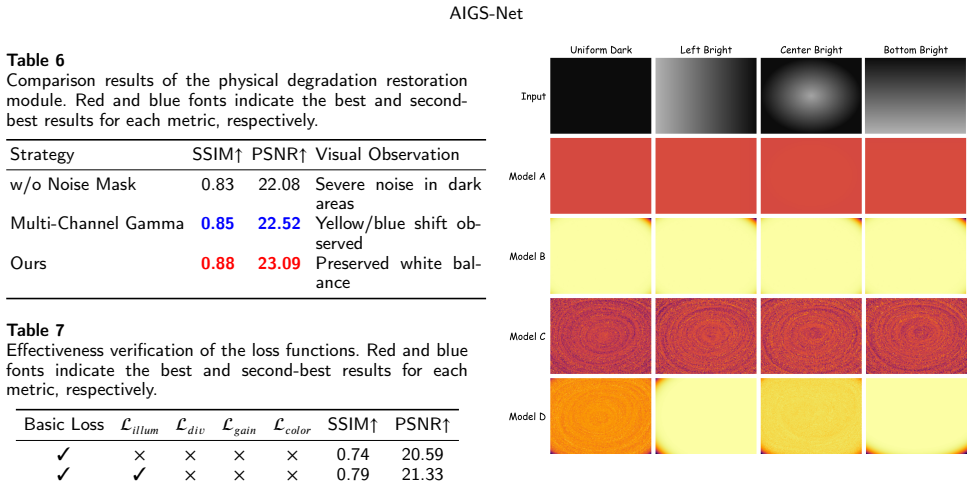
- [Abstract, §3] Abstract and §3: the 'approximately 40 learnable parameters' claim requires an explicit breakdown (e.g., a table listing each parameter group and its count) so readers can reproduce the tally; without it the efficiency claim remains hard to verify precisely.
- [§4] §4 (Experiments): quantitative tables on LOL and LSRW should report standard deviations across multiple random seeds or runs; single-point metrics alone leave the statistical reliability of the reported gains unclear.
- [§3.2] Figure captions and §3.2: the ordered alpha compositing procedure and the exact form of the luminance-based opacity modulation should be accompanied by a short pseudocode snippet or explicit equation reference to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance of the ~40-parameter design, and the recommendation for minor revision. We appreciate the explicit credit given to the parameter-free encoding module and the targeted regularizations.
Circularity Check
No significant circularity detected
full rationale
The paper describes a constructed architecture: an input-adaptive 2D Gaussian splatting field whose opacities are modulated by luminance statistics, rendered via alpha compositing, guided by a zero-parameter multiscale encoder, plus explicit regularization terms for noise and color. These are presented as design choices whose effectiveness is then measured empirically on LOL and LSRW benchmarks. No equation reduces a claimed result to its own fitted inputs by definition, no prediction is statistically forced by a prior fit, and no load-bearing premise rests on a self-citation chain. The derivation chain is therefore self-contained as an empirical construction rather than a tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- approximately 40 learnable parameters
axioms (2)
- domain assumption Gaussian basis functions with input-dependent opacity can model spatially varying illumination compensation via alpha compositing.
- domain assumption A zero-parameter nonlinear multiscale contextual encoding module can extract low-frequency structures and local contrast cues.
Reference graph
Works this paper leans on
-
[1]
Low-light image and video enhance- mentusingdeeplearning:Asurvey,
C. Li, C. Guo, L. Han, et al., “Low-light image and video enhance- mentusingdeeplearning:Asurvey,”IEEETransactionsonPattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 9396–9416, 2022
2022
-
[2]
Deep learning for low-light vision: A comprehensive survey,
Q. Zhao, G. Li, B. He, et al., “Deep learning for low-light vision: A comprehensive survey,”IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[3]
Loli-street: Benchmarking low-light image enhance- ment and beyond,
M. T. Islam, I. Alam, S. S. Woo, S. Anwar, I. K. H. Lee, and K. Muhammad, “Loli-street: Benchmarking low-light image enhance- ment and beyond,” inProc. Asian Conference on Computer Vision (ACCV), 2024, pp. 1250–1267
2024
-
[4]
Towards lightest low-light image enhancementarchitectureformobiledevices,
G. Bai, H. Yan, W. Liu, et al., “Towards lightest low-light image enhancementarchitectureformobiledevices,”ExpertSystemswith Applications, vol. 296, p. 129125, 2026
2026
-
[5]
LIME:Low-lightimageenhancement via illumination map estimation,
X.Guo,Y.Li,andH.Ling,“LIME:Low-lightimageenhancement via illumination map estimation,”IEEE Transactions on Image Processing, vol. 26, no. 2, pp. 982–993, 2017
2017
-
[6]
Learningtoenhancelow-lightimage via zero-reference deep curve estimation,
C.Li,C.Guo,andC.C.Loy,“Learningtoenhancelow-lightimage via zero-reference deep curve estimation,”IEEE Transactions on PatternAnalysisandMachineIntelligence,vol.44,no.8,pp.4225– 4238, 2022
2022
-
[7]
Zero-reference deep curve estimation for low-light image enhancement,
C. Guo, C. Li, J. Guo, et al., “Zero-reference deep curve estimation for low-light image enhancement,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1780–1789
2020
-
[8]
Toward fast, flexible, and robust low-light image enhancement,
L. Ma, T. Ma, R. Liu, et al., “Toward fast, flexible, and robust low-light image enhancement,” inProc. IEEE/CVF Conference on ComputerVisionandPatternRecognition(CVPR),2022,pp.5637– 5646
2022
-
[9]
Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhance- ment,
R. Liu, L. Ma, J. Zhang, et al., “Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhance- ment,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 10561–10570
2021
-
[10]
EnlightenGAN: Deep light enhancement without paired supervision,
Y. Jiang, et al., “EnlightenGAN: Deep light enhancement without paired supervision,”IEEE Transactions on Image Processing, vol. 30, pp. 2340–2349, 2021
2021
-
[11]
FMR-Net: A fast multi-scale residual network for low-light image enhancement,
Y. Chen, G. Zhu, X. Wang, et al., “FMR-Net: A fast multi-scale residual network for low-light image enhancement,”Multimedia Systems, vol. 30, p. 73, 2024
2024
-
[12]
FRR-NET: A fast reparame- terizedresidualnetworkforlow-lightimageenhancement,
Y. Chen, G. Zhu, X. Wang, et al., “FRR-NET: A fast reparame- terizedresidualnetworkforlow-lightimageenhancement,”Signal, Image and Video Processing, vol. 18, pp. 4925–4934, 2024
2024
-
[13]
Adaptive unfolding total variation network for low-light image enhancement,
C. Zheng, D. Shi, and W. Shi, “Adaptive unfolding total variation network for low-light image enhancement,” inProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 4439–4448
2021
-
[14]
ChebyLighter:Optimalcurveestima- tionforlow-lightimageenhancement,
J.Pan,D.Zhai,Y.Bai,etal.,“ChebyLighter:Optimalcurveestima- tionforlow-lightimageenhancement,”inProc.ACMInternational Conference on Multimedia, 2022, pp. 1358–1366
2022
-
[15]
EFINet:Restorationforlow-lightim- agesviaenhancement-fusioniterativenetwork,
C.Liu,F.Wu,andX.Wang,“EFINet:Restorationforlow-lightim- agesviaenhancement-fusioniterativenetwork,”IEEETransactions on Circuits and Systems for Video Technology, vol. 32, no. 12, pp. 8486–8499, 2022
2022
-
[16]
Learning a simple low-light image enhancer from paired low-light instances,
Z. Fu, Y. Yang, X. Tu, et al., “Learning a simple low-light image enhancer from paired low-light instances,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 22252–22261
2023
-
[17]
Noise self-regression: A new learning paradigm toenhancelow-lightimageswithouttask-relateddata,
Z. Zhang, et al., “Noise self-regression: A new learning paradigm toenhancelow-lightimageswithouttask-relateddata,”IEEETrans- actions on Pattern Analysis and Machine Intelligence, vol. 47, no. 2, pp. 1073–1088, 2025
2025
-
[18]
URetinex-Net: Retinex-based deepunfoldingnetworkforlow-lightimageenhancement,
W. Wu, J. Weng, P. Zhang, et al., “URetinex-Net: Retinex-based deepunfoldingnetworkforlow-lightimageenhancement,”inProc. IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2022, pp. 5901–5910
2022
-
[19]
ZERO-IG:Zero-shotillumination- guided joint denoising and adaptive enhancement for low-light images,
Y.Shi,D.Liu,L.Zhang,etal.,“ZERO-IG:Zero-shotillumination- guided joint denoising and adaptive enhancement for low-light images,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 3015–3024
2024
-
[20]
A lightweight real-time low-light enhancement network for embedded automotive vision systems,
Y. Chen, Y. Shi, G. Li, et al., “A lightweight real-time low-light enhancement network for embedded automotive vision systems,” arXiv preprint arXiv:2512.02965, 2025
-
[21]
LightenDiffusion: Unsupervised low-light image enhancement with latent-Retinex diffusion models,
H. Jiang, A. Luo, X. Liu, S. Han, and S. Liu, “LightenDiffusion: Unsupervised low-light image enhancement with latent-Retinex diffusion models,” inProc. European Conference on Computer Vision(ECCV),Cham:SpringerNatureSwitzerland,2024,pp.161– 179
2024
-
[22]
AGLLDiff: Guiding diffusion mod- els towards unsupervised training-free real-world low-light image enhancement,
Y. Lin, T. Ye, S. Chen, et al., “AGLLDiff: Guiding diffusion mod- els towards unsupervised training-free real-world low-light image enhancement,”inProc.AAAIConferenceonArtificialIntelligence, vol. 39, no. 5, 2025, pp. 5307–5315
2025
-
[23]
Zero-shot low-light image en- hancement via latent diffusion models,
Y. Huang, X. Liao, J. Liang, et al., “Zero-shot low-light image en- hancement via latent diffusion models,” inProc. AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 3815–3823
2025
-
[24]
Implicit neural representation for cooperative low-light image enhancement,
S. Yang, M. Ding, Y. Wu, Z. Li, and J. Zhang, “Implicit neural representation for cooperative low-light image enhancement,” in Proc. IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 12918–12927
2023
-
[25]
Fast context-basedlow-lightimageenhancementvianeuralimplicitrep- resentations,
T. Chobola, Y. Liu, H. Zhang, J. A. Schnabel, and T. Peng, “Fast context-basedlow-lightimageenhancementvianeuralimplicitrep- resentations,” inProc. European Conference on Computer Vision (ECCV), Cham: Springer Nature Switzerland, 2024, pp. 413–430
2024
-
[26]
Deep Retinex Decomposition for Low-Light Enhancement
C.Wei,etal.,“DeepRetinexdecompositionforlow-lightenhance- ment,” arXiv preprint arXiv:1808.04560, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
R2RNet: Low-light image enhancement via real- lowtoreal-normalnetwork,
J. Hai, et al., “R2RNet: Low-light image enhancement via real- lowtoreal-normalnetwork,”JournalofVisualCommunicationand Image Representation, vol. 90, p. 103712, 2023
2023
-
[28]
3D Gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3D Gaussian splatting for real-time radiance field rendering,”ACM Transactions on Graphics, vol. 42, no. 4, p. 139, 2023
2023
-
[29]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ra- mamoorthi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[30]
2D Gaussian splatting for geometrically accurate radiance fields,
B. Huang, Z. Yu, A. Chen, A. Geiger, and S. Gao, “2D Gaussian splatting for geometrically accurate radiance fields,” inProc. ACM SIGGRAPH, 2024, pp. 1–11
2024
-
[31]
Implicitneuralrepresentationswithperiodicactivationfunctions,
V. Sitzmann, J. Martel, A. Bergman, D. Lindell, and G. Wetzstein, “Implicitneuralrepresentationswithperiodicactivationfunctions,” Advances in Neural Information Processing Systems, vol. 33, pp. 7462–7473, 2020
2020
-
[32]
Street Gaussians: Modeling dynamic urban scenes with Gaussian splatting,
Y. Yan, H. Lin, C. Zhou, et al., “Street Gaussians: Modeling dynamic urban scenes with Gaussian splatting,” inProc. European Conference on Computer Vision (ECCV), Cham: Springer Nature Switzerland, 2024, pp. 156–173
2024
-
[33]
Speedy-Splat: Fast 3D Gaussian splatting with sparse pixels and sparse primitives,
A.Hanson,A.Tu,G.Lin,V.Singla,M.Zwicker,andT.Goldstein, “Speedy-Splat: Fast 3D Gaussian splatting with sparse pixels and sparse primitives,” inProc. Computer Vision and Pattern Recogni- tion Conference, 2025, pp. 21537–21546
2025
-
[34]
MVSGaussian: Fast generaliz- able Gaussian splatting reconstruction from multi-view stereo,
T. Liu, G. Wang, S. Hu, et al., “MVSGaussian: Fast generaliz- able Gaussian splatting reconstruction from multi-view stereo,” in Proc. European Conference on Computer Vision (ECCV), Cham: Springer Nature Switzerland, 2024, pp. 37–53
2024
-
[35]
Y.Xu,J.Zhang,Y.Chen,D.Wang,L.Yu,andC.He,“PMGS:Re- construction of projectile motion across large spatiotemporal spans via 3D Gaussian Splatting,” arXiv preprint arXiv:2508.02660, 2025
-
[36]
PEGS:Physics-eventenhancedlarge spatiotemporal motion reconstruction via 3D Gaussian Splatting,
Y.Xu,J.Zhang,H.Liu,etal.,“PEGS:Physics-eventenhancedlarge spatiotemporal motion reconstruction via 3D Gaussian Splatting,” arXiv preprint arXiv:2511.17116, 2025
-
[37]
Periodic vibra- tion Gaussian: Dynamic urban scene reconstruction and real-time rendering,
Y. Chen, C. Gu, J. Jiang, X. Zhu, and L. Zhang, “Periodic vibra- tion Gaussian: Dynamic urban scene reconstruction and real-time rendering,” arXiv preprint arXiv:2311.18561, 2023
-
[38]
DrivingGaussian: Composite Gaussian splatting for surrounding dynamic autonomous driving scenes,
X. Zhou, Z. Lin, X. Shan, Y. Wang, D. Sun, and M. H. Yang, “DrivingGaussian: Composite Gaussian splatting for surrounding dynamic autonomous driving scenes,” inProc. IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 21634–21643
2024
-
[39]
GaussianPro: 3D Gaussian splattingwithprogressivepropagation,
K. Cheng, X. Long, K. Yang, et al., “GaussianPro: 3D Gaussian splattingwithprogressivepropagation,”inProc.InternationalCon- ference on Machine Learning (ICML), 2024
2024
-
[40]
CityGaussian:Real-timehigh-quality large-scale scene rendering with Gaussians,
Y.Liu,C.Luo,L.Fan,etal.,“CityGaussian:Real-timehigh-quality large-scale scene rendering with Gaussians,” inProc. European Conference on Computer Vision (ECCV), Cham: Springer Nature Switzerland, 2024, pp. 265–282. Yuhan Chen et al.:Preprint submitted to ElsevierPage 13 of 14 AIGS-Net
2024
-
[41]
Momentum-GS: Momentum Gaussian self-distillation for high-quality large scene reconstruction,
J. Fan, W. Li, Y. Han, T. Dai, and Y. Tang, “Momentum-GS: Momentum Gaussian self-distillation for high-quality large scene reconstruction,” inProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 25250–25260
2025
-
[42]
DriveDreamer4D: World models areeffectivedatamachinesfor4Ddrivingscenerepresentation,
G. Zhao, C. Ni, X. Wang, et al., “DriveDreamer4D: World models areeffectivedatamachinesfor4Ddrivingscenerepresentation,”in Proc. Computer Vision and Pattern Recognition Conference, 2025, pp. 12015–12026
2025
-
[43]
ReconDreamer: Crafting world models for driving scene reconstruction via online restoration,
C. Ni, G. Zhao, X. Wang, et al., “ReconDreamer: Crafting world models for driving scene reconstruction via online restoration,” in Proc. Computer Vision and Pattern Recognition Conference, 2025, pp. 1559–1569
2025
-
[44]
GaussianDreamer: Fast generation fromtextto3DGaussiansbybridging2Dand3Ddiffusionmodels,
T. Yi, J. Fang, J. Wang, et al., “GaussianDreamer: Fast generation fromtextto3DGaussiansbybridging2Dand3Ddiffusionmodels,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 6796–6807
2024
-
[45]
LL-Gaussian: Low- light scene reconstruction and enhancement via Gaussian Splatting for novel view synthesis,
H. Sun, F. Yu, H. Xu, T. Zhang, and C. Zou, “LL-Gaussian: Low- light scene reconstruction and enhancement via Gaussian Splatting for novel view synthesis,” inProc. ACM International Conference on Multimedia, 2025, pp. 4261–4270
2025
-
[46]
H. Wang, J. Huang, L. Yang, T. Deng, G. Zhang, and M. Li, “LLGS: Unsupervised Gaussian Splatting for image enhancement and reconstruction in pure dark environment,” arXiv preprint arXiv:2503.18640, 2025
-
[47]
Y. Chen, W. Yu, G. Li, et al., “LL-GaussianImage: Efficient image representation for zero-shot low-light enhancement with 2D Gaus- sian Splatting,” arXiv preprint arXiv:2601.15772, 2026
-
[48]
LL-GaussianMap: Zero-shot low- light image enhancement via 2D Gaussian Splatting guided gain maps,
Y. Chen, Y. Fang, G. Li, et al., “LL-GaussianMap: Zero-shot low- light image enhancement via 2D Gaussian Splatting guided gain maps,” arXiv preprint arXiv:2601.15766, 2026
-
[49]
Large images are Gaussians: High-qualitylargeimagerepresentationwithlevelsof2DGaussian Splatting,
L. Zhu, G. Lin, J. Chen, et al., “Large images are Gaussians: High-qualitylargeimagerepresentationwithlevelsof2DGaussian Splatting,” inProc. AAAI Conference on Artificial Intelligence, 2025, pp. 10977–10985
2025
-
[50]
Instant GaussianImage: A generalizable and self-adaptive image representation via 2D Gaus- sian Splatting,
Z. Zeng, Y. Wang, T. Guan, et al., “Instant GaussianImage: A generalizable and self-adaptive image representation via 2D Gaus- sian Splatting,” inProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 27896–27905
2025
-
[51]
GaussianImage: 1000 FPS image representation and compression by 2D Gaussian Splatting,
X. Zhang, X. Ge, T. Xu, et al., “GaussianImage: 1000 FPS image representation and compression by 2D Gaussian Splatting,” in Proc. European Conference on Computer Vision (ECCV), Cham: Springer Nature Switzerland, 2024, pp. 327–345
2024
-
[52]
Beyondpixels: Efficient dataset distillation via sparse Gaussian representation,
C.Jiang,Z.Li,H.Zhao,Q.Shan,S.Wu,andJ.Su,“Beyondpixels: Efficient dataset distillation via sparse Gaussian representation,” arXiv preprint arXiv:2509.26219, 2025
-
[53]
Vision-language alignment from compressed image representations using 2D Gaus- sian Splatting,
Y. Omri, C. Ding, T. Weissman, and T. Tambe, “Vision-language alignment from compressed image representations using 2D Gaus- sian Splatting,” arXiv preprint arXiv:2509.22615, 2025
-
[54]
GaussianSR: Highfidelity2DGaussianSplattingforarbitrary-scaleimagesuper- resolution,
J. Hu, B. Xia, B. Chen, W. Yang, and L. Zhang, “GaussianSR: Highfidelity2DGaussianSplattingforarbitrary-scaleimagesuper- resolution,”inProc.AAAIConferenceonArtificialIntelligence,vol. 39, no. 4, 2025, pp. 3554–3562
2025
-
[55]
MambaLLIE: Implicit Retinex- aware low-light enhancement with global-then-local state space,
J. Weng, Z. Yan, Y. Tai, et al., “MambaLLIE: Implicit Retinex- aware low-light enhancement with global-then-local state space,” Advances in Neural Information Processing Systems, vol. 37, pp. 27440–27462, 2024
2024
-
[56]
Y. Chen, Y. Shi, G. Li, L. Zhang, J. Li, J. Gao, and W. Chu, “KGS-GCN: Enhancing sparse skeleton sensing via kinematics- driven Gaussian Splatting and probabilistic topology for action recognition,” arXiv preprint arXiv:2603.16943, 2026. Yuhan Chen et al.:Preprint submitted to ElsevierPage 14 of 14
work page internal anchor Pith review arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.