Recursive Scaling in Masked Diffusion Models
Pith reviewed 2026-06-27 01:41 UTC · model grok-4.3
The pith
Recursive reuse of the same denoising transformer in masked diffusion models matches the performance of models with L times more parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
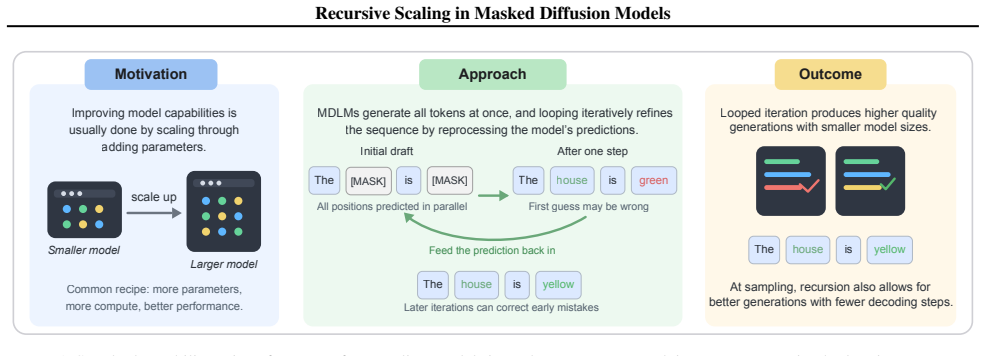
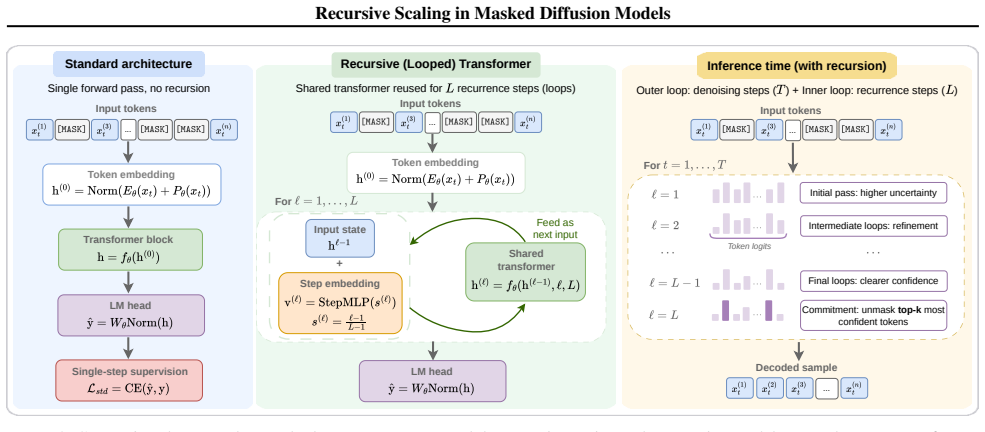
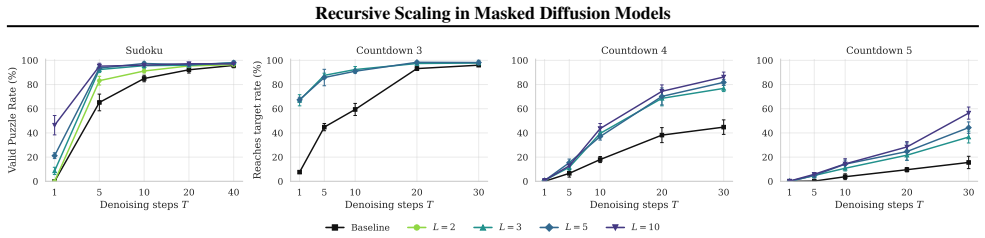
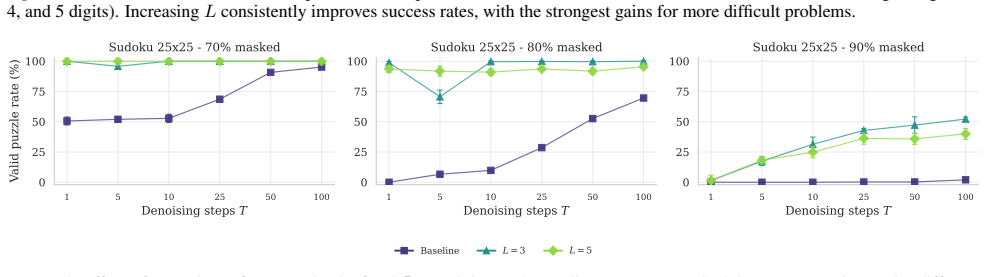
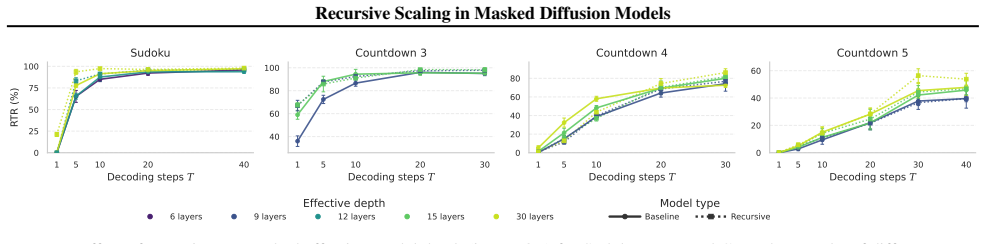
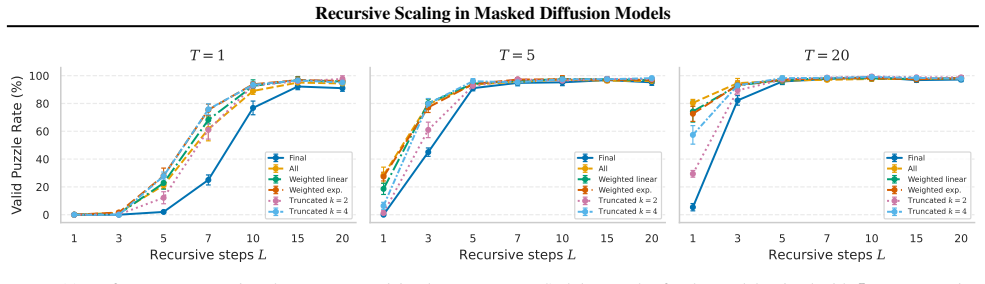
Recursive Masked Diffusion Models (R-MDMs) introduce recursive depth by repeatedly applying the same denoising transformer within each diffusion step. This produces iterative refinement of the generated sequence through parameter reuse, increasing effective model depth without increasing the parameter count. Across Sudoku and Countdown tasks, an R-MDM with L recursive iterations matches the performance of non-recursive baselines that use roughly L times more parameters. Recursive refinement can also substitute for additional denoising steps, allowing the same generation quality to be reached with fewer forward passes during inference.
What carries the argument
Recursive depth, implemented as repeated application of the identical denoising transformer inside each diffusion step to produce iterative refinement via parameter reuse.
If this is right
- An R-MDM with L recursive iterations reaches performance comparable to a non-recursive model with L times more parameters on Sudoku and Countdown.
- Recursive refinement allows the same generation quality to be obtained with fewer denoising steps at inference time.
- Recursive depth increases effective model depth without any increase in parameter count.
- Recursive scaling supplies a third axis alongside parameter count and denoising steps for improving MDM performance.
Where Pith is reading between the lines
- The same recursive mechanism may allow training larger effective models on hardware with limited memory by avoiding simultaneous storage of L distinct parameter sets.
- Adaptive choice of recursion depth per input could further optimize the trade-off between quality and inference cost.
- The observed substitution between recursion and denoising steps suggests that total test-time compute can be reallocated between depth and step count.
Load-bearing premise
That repeated application of the identical denoising transformer within a diffusion step produces stable iterative refinement without introducing compounding errors or mode collapse on the target tasks.
What would settle it
If a recursive model with L=4 iterations on the Sudoku task performs worse than a non-recursive baseline with exactly 4 times as many parameters, the central efficiency claim would be falsified.
Figures


read the original abstract
Masked diffusion models (MDMs) have recently emerged as a promising paradigm for sequence generation. Scaling MDMs is conventionally achieved by increasing the parameter count or the number of denoising steps. We introduce Recursive Masked Diffusion Models (R-MDMs), which add recursive depth as a third scaling axis by repeatedly applying the same denoising transformer within each diffusion step. Recursion enables iterative refinement of the output through parameter reuse, increasing effective model depth without increasing parameter count. Across structured generation tasks, including Sudoku and Countdown, we show that R-MDMs achieve substantially improved parameter efficiency: a model with $L$ recursive iterations often matches the performance of non-recursive baselines with roughly $L\times$ more parameters. Moreover, recursive refinement can partially substitute for additional denoising steps, allowing recursive models to reach the same generation quality with fewer forward passes at inference time. These results suggest that recursive depth is a practically useful scaling mechanism for MDMs, improving both parameter efficiency and the allocation of test-time compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Recursive Masked Diffusion Models (R-MDMs) that scale masked diffusion models along a third axis by repeatedly applying the identical denoising transformer within each diffusion step. The central empirical claim is that L recursive iterations on a fixed model often match the performance of non-recursive baselines with roughly L× more parameters on structured tasks such as Sudoku and Countdown, while recursive refinement can also trade off against the number of denoising steps to reach equivalent quality with fewer forward passes.
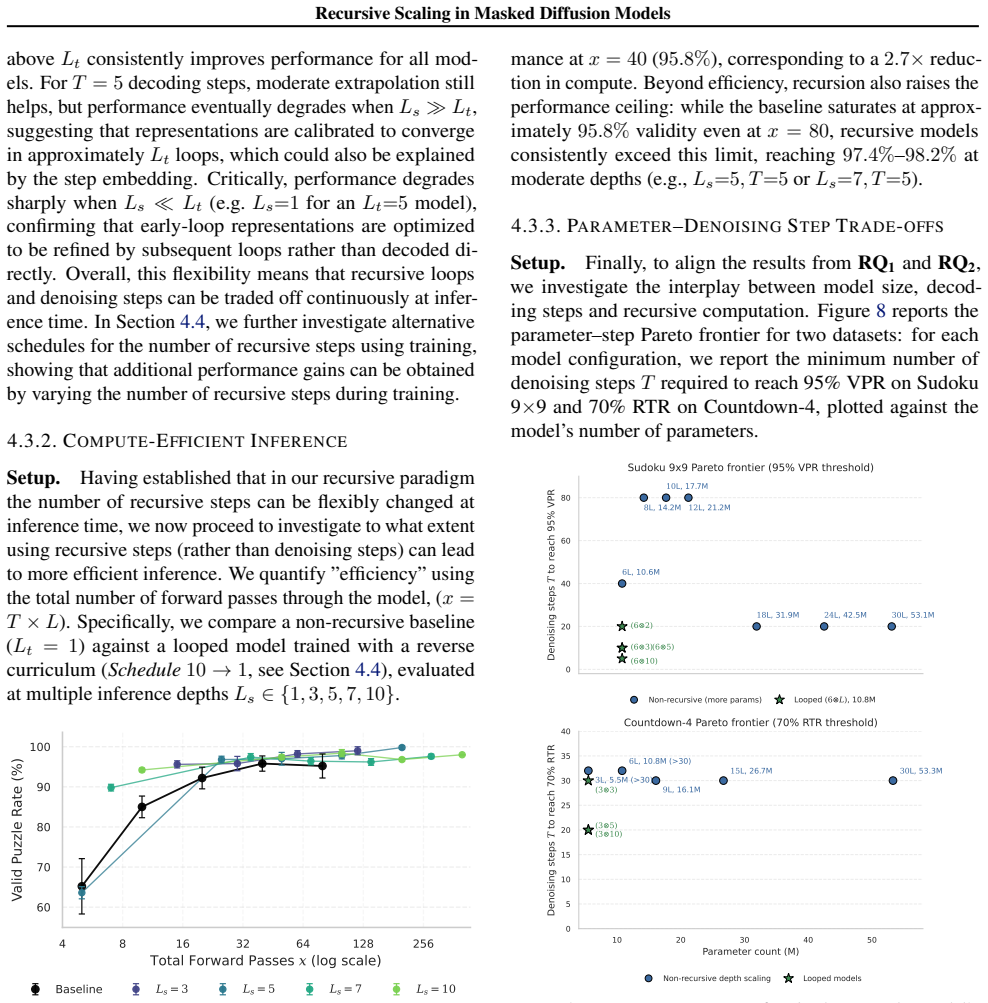
Significance. If the reported efficiency gains prove robust, the work identifies recursive depth as a practical scaling mechanism for MDMs that improves parameter efficiency and test-time compute allocation through parameter reuse. This is a straightforward empirical contribution with potential applicability to other structured generation settings, though its significance would increase with explicit controls for total compute and validation beyond the two named tasks. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described.
major comments (2)
- [Experiments] The central claim rests on the stability of repeated identical transformer application without compounding errors or mode collapse. The experiments section must include ablations that track output divergence or quality degradation as a function of recursion depth L, together with statistical significance across multiple runs, to substantiate that the observed matching to L×-parameter baselines is not an artifact of task-specific stability.
- [Experiments] Table or figure reporting the main Sudoku/Countdown results: the claim of 'roughly L× more parameters' requires explicit reporting of total parameter counts, FLOPs per forward pass, and whether the non-recursive baselines were trained with equivalent total compute; without these, the parameter-efficiency conclusion cannot be isolated from possible confounds in training budget.
minor comments (2)
- [Introduction] The abstract states results hold 'across structured generation tasks' yet names only two; the introduction or related-work section should clarify the precise scope of tasks evaluated and any negative results on additional domains.
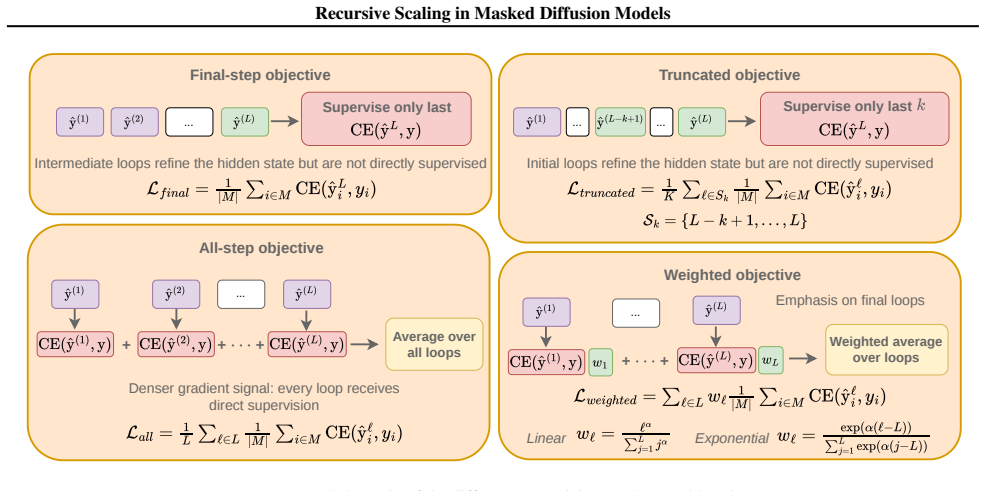
- Notation for the recursion operator and its integration inside a diffusion step should be defined once with a clear equation or pseudocode block to avoid ambiguity when comparing recursive and non-recursive forward passes.
Simulated Author's Rebuttal
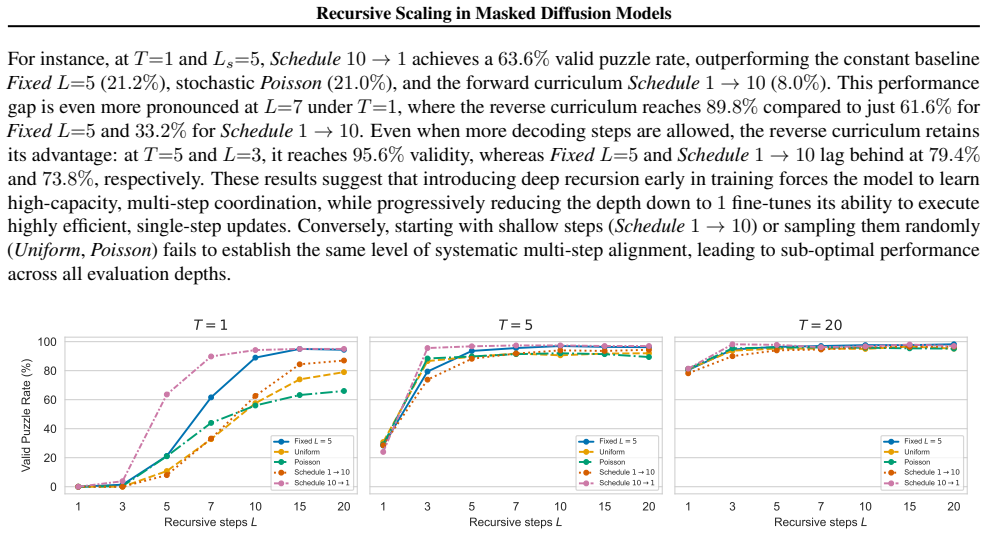
We thank the referee for their thoughtful comments. We address each major comment below and plan to revise the manuscript accordingly to strengthen the experimental section.
read point-by-point responses
-
Referee: [Experiments] The central claim rests on the stability of repeated identical transformer application without compounding errors or mode collapse. The experiments section must include ablations that track output divergence or quality degradation as a function of recursion depth L, together with statistical significance across multiple runs, to substantiate that the observed matching to L×-parameter baselines is not an artifact of task-specific stability.
Authors: We agree with the importance of verifying stability under recursion. In the revised version, we will add ablations that plot quality metrics versus recursion depth L, include measures of output divergence, and report means and standard deviations over at least 5 independent runs with different seeds to demonstrate statistical reliability. revision: yes
-
Referee: [Experiments] Table or figure reporting the main Sudoku/Countdown results: the claim of 'roughly L× more parameters' requires explicit reporting of total parameter counts, FLOPs per forward pass, and whether the non-recursive baselines were trained with equivalent total compute; without these, the parameter-efficiency conclusion cannot be isolated from possible confounds in training budget.
Authors: We will revise the manuscript to include a dedicated table or section explicitly listing the total parameter counts for recursive and non-recursive models, approximate FLOPs per forward pass, and details on the training compute budget used for all baselines to ensure fair comparison. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical demonstration of recursive masked diffusion models on structured generation tasks. No equations, derivations, or first-principles claims are present in the provided text or abstract. The central results consist of experimental comparisons showing that L recursive iterations match non-recursive baselines with ~L× parameters; these are direct observations from training and evaluation runs rather than quantities that reduce to fitted inputs or self-citations by construction. No load-bearing self-citation chains, ansatzes, or uniqueness theorems are invoked.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , title =
Jacob Austin and Daniel D. Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[2]
Chiu and Alexander Rush and Volodymyr Kuleshov , title =
Subham Sekhar Sahoo and Marianne Arriola and Yair Schiff and Aaron Gokaslan and Edgar Marroquin and Justin T. Chiu and Alexander Rush and Volodymyr Kuleshov , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Shen Nie and Fengqi Zhu and Zebin You and Xiaolu Zhang and Jingyang Ou and Jun Hu and Jun Zhou and Yankai Lin and Ji-Rong Wen and Chongxuan Li , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[4]
2025 , journal =
Dream 7B: Diffusion Large Language Models , author=. 2025 , journal =
2025
-
[5]
2026 , journal =
Esoteric Language Models: Bridging Autoregressive and Masked Diffusion LLMs , author=. 2026 , journal =
2026
-
[6]
Promises, Outlooks and Challenges of
Justin Deschenaux and Caglar Gulcehre , year=. Promises, Outlooks and Challenges of. arXiv preprint arXiv:2406.11473 , eprint=
-
[7]
International Conference on Learning Representations (ICLR) , year=
On the Reasoning Abilities of Masked Diffusion Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[8]
Universal Transformers , journal =
Mostafa Dehghani and Stephan Gouws and Oriol Vinyals and Jakob Uszkoreit and. Universal Transformers , journal =. 2019 , url =
2019
-
[9]
International Conference on Learning Representations (ICLR) , year =
Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut , title =. International Conference on Learning Representations (ICLR) , year =
-
[10]
Lee and Dimitris Papailiopoulos , title =
Angeliki Giannou and Shashank Rajput and Jy-yong Sohn and Kangwook Lee and Jason D. Lee and Dimitris Papailiopoulos , title =. International Conference on Machine Learning (ICML) , year =
-
[11]
Reddi , title =
Nikunj Saunshi and Nishanth Dikkala and Zhiyuan Li and Sanjiv Kumar and Sashank J. Reddi , title =. International Conference on Learning Representations (ICLR) , year =
-
[12]
arXiv preprint arXiv:2502.08482 , year =
Qifan Yu and Zhenyu He and Sijie Li and Xun Zhou and Jun Zhang and Jingjing Xu and Di He , title =. arXiv preprint arXiv:2502.08482 , year =
-
[13]
arXiv preprint arXiv:2603.08082 , year =
Paulius Rauba and Claudio Fanconi and Mihaela van der Schaar , title =. arXiv preprint arXiv:2603.08082 , year =
-
[14]
2025 , journal =
Less is More: Recursive Reasoning with Tiny Networks , author=. 2025 , journal =
2025
-
[15]
arXiv preprint arXiv:2506.21734 , year =
Guan Wang and Jin Li and Yuhao Sun and Xing Chen and Changling Liu and Yue Wu and Meng Lu and Sen Song and Yasin Abbasi Yadkori , title =. arXiv preprint arXiv:2506.21734 , year =
-
[16]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Jonathan Ho and Ajay Jain and Pieter Abbeel , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[17]
Kingma and Abhishek Kumar and Stefano Ermon and Ben Poole , title =
Yang Song and Jascha Sohl-Dickstein and Diederik P. Kingma and Abhishek Kumar and Stefano Ermon and Ben Poole , title =. International Conference on Learning Representations (ICLR) , year =
-
[18]
and Maheswaranathan, Niru and Ganguli, Surya , journal =
Sohl-Dickstein, Jascha and Weiss, Eric A. and Maheswaranathan, Niru and Ganguli, Surya , journal =. Deep
-
[19]
Gomez and
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and. Attention Is All You Need , year =. Advances in Neural Information Processing Systems (NeurIPS) , url =
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Guhao Feng and Bohang Zhang and Yuntian Gu and Haotian Ye and Di He and Liwei Wang , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[22]
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =. arXiv preprint arXiv:2001.08361 , year =
Pith/arXiv arXiv 2001
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Rasmus Berg Palm and Ulrich Paquet and Ole Winther , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[24]
Zico Kolter and Vladlen Koltun , title =
Shaojie Bai and J. Zico Kolter and Vladlen Koltun , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[25]
2014 , journal=
Deeply-Supervised Nets , author=. 2014 , journal=
2014
-
[26]
arXiv preprint arXiv:1603.08983 , year =
Alex Graves , title =. arXiv preprint arXiv:1603.08983 , year =
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Biao Zhang and Rico Sennrich , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[28]
Weinberger , title =
Gao Huang and Yu Sun and Zhuang Liu and Daniel Sedra and Kilian Q. Weinberger , title =. European Conference on Computer Vision (ECCV) , year =
-
[29]
arXiv preprint arXiv:1608.05859 , year =
Ofir Press and Lior Wolf , title =. arXiv preprint arXiv:1608.05859 , year =
-
[30]
arXiv preprint arXiv:2409.10502 , url=
Causal Language Modeling Can Elicit Search and Reasoning Capabilities on Logic Puzzles , author=. arXiv preprint arXiv:2409.10502 , url=. 2024 , eprint=
arXiv 2024
-
[31]
International Conference on Machine Learning (ICML) , year =
Aaron Lou and Chenlin Meng and Stefano Ermon , title =. International Conference on Machine Learning (ICML) , year =
-
[32]
International Conference on Machine Learning (ICML) , year =
Andrew Campbell and Jason Yim and Regina Barzilay and Tom Rainforth and Tommi Jaakkola , title =. International Conference on Machine Learning (ICML) , year =
-
[33]
arXiv preprint arXiv:2511.21338 , year =
Julianna Piskorz and Cristina Pinneri and Alvaro Correia and Motasem Alfarra and Risheek Garrepalli and Christos Louizos , title =. arXiv preprint arXiv:2511.21338 , year =
-
[34]
arXiv preprint arXiv:2602.15014 , year =
Subham Sekhar Sahoo and Jean-Marie Lemercier and Zhihan Yang and Justin Deschenaux and Jingyu Liu and John Thickstun and Ante Jukic , title =. arXiv preprint arXiv:2602.15014 , year =
-
[35]
Chiu and Volodymyr Kuleshov , title =
Subham Sekhar Sahoo and Justin Deschenaux and Aaron Gokaslan and Guanghan Wang and Justin T. Chiu and Volodymyr Kuleshov , title =. International Conference on Machine Learning (ICML) , year =
-
[36]
Krishnan , title =
Chen-Hao Chao and Wei-Fang Sun and Hanwen Liang and Chun-Yi Lee and Rahul G. Krishnan , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[37]
arXiv preprint arXiv:2602.23968 , year =
David Fox and Sam Bowyer and Song Liu and Laurence Aitchison and Raul Santos-Rodriguez and Mengyue Yang , title =. arXiv preprint arXiv:2602.23968 , year =
-
[38]
Naesseth and Grigory Bartosh , title =
Nesta Midavaine and Christian A. Naesseth and Grigory Bartosh , title =. EuRIPs 2025 Workshop on Principles of Generative Modeling , year =
2025
-
[39]
International Conference on Learning Representations (ICLR) , year =
Huangjie Zheng and Shansan Gong and Ruixiang Zhang and Tianrong Chen and Jiatao Gu and Mingyuan Zhou and Navdeep Jaitly and Yizhe Zhang , title =. International Conference on Learning Representations (ICLR) , year =
-
[40]
Boffi and Jinwoo Kim , title =
Chanhyuk Lee and Jaehoon Yoo and Manan Agarwal and Sheel Shah and Jerry Huang and Aditi Raghunathan and Seunghoon Hong and Nicholas M. Boffi and Jinwoo Kim , title =. arXiv preprint arXiv:2602.16813 , year =
-
[41]
arXiv preprint arXiv:2510.03206 , year =
Cai Zhou and Chenxiao Yang and Yi Hu and Chenyu Wang and Chubin Zhang and Muhan Zhang and Lester Mackey and Tommi Jaakkola and Stephen Bates and Dinghuai Zhang , title =. arXiv preprint arXiv:2510.03206 , year =
-
[42]
International Conference on Learning Representations (ICLR) , year =
Jiacheng Ye and Jiahui Gao and Shansan Gong and Lin Zheng and Xin Jiang and Zhenguo Li and Lingpeng Kong , title =. International Conference on Learning Representations (ICLR) , year =
-
[43]
arXiv preprint arXiv:2602.03769 , year =
Andre He and Sean Welleck and Daniel Fried , title =. arXiv preprint arXiv:2602.03769 , year =
-
[44]
arXiv preprint arXiv:2509.25239 , year =
Kevin Xu and Issei Sato , title =. arXiv preprint arXiv:2509.25239 , year =
-
[45]
Bartoldson and Bhavya Kailkhura and Abhinav Bhatele and Tom Goldstein , title =
Jonas Geiping and Sean McLeish and Neel Jain and John Kirchenbauer and Siddharth Singh and Brian R. Bartoldson and Bhavya Kailkhura and Abhinav Bhatele and Tom Goldstein , title =. arXiv preprint arXiv:2502.05171 , year =
-
[46]
arXiv preprint arXiv:2604.12946 , url=
Parcae: Scaling Laws For Stable Looped Language Models , author=. arXiv preprint arXiv:2604.12946 , url=. 2026 , eprint=
Pith/arXiv arXiv 2026
-
[47]
arXiv preprint arXiv:2409.15647 , year =
Ying Fan and Yilun Du and Kannan Ramchandran and Kangwook Lee , title =. arXiv preprint arXiv:2409.15647 , year =
-
[48]
arXiv preprint arXiv:2311.12424 , year =
Liu Yang and Kangwook Lee and Robert Nowak and Dimitris Papailiopoulos , title =. arXiv preprint arXiv:2311.12424 , year =
-
[49]
2023 , journal =
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. 2023 , journal =
2023
-
[50]
Kanishk Gandhi and Denise Lee and Gabriel Grand and Muxin Liu and Winson Cheng and Archit Sharma and Noah D. Goodman , year=. Stream of Search (. arXiv preprint arXiv:2404.03683 , url=
-
[51]
2023 , journal =
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author =. 2023 , journal =
2023
-
[52]
2021 , license=
Wang, Ben and Komatsuzaki, Aran , title=. 2021 , license=
2021
-
[53]
2006 , url =
Matt Mahoney , title =. 2006 , url =
2006
-
[54]
2023 , journal=
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. 2023 , journal=
2023
-
[55]
2026 , journal=
Categorical Flow Maps , author=. 2026 , journal=
2026
-
[56]
Yu, Chengting and Shu, Xiaobo and Wang, Yadao and Zhang, Yizhen and Wu, Haoyi and Wu, You and Long, Rujiao and Chen, Ziheng and Xu, Yuchi and Su, Wenbo and Zheng, Bo , year =
-
[57]
Jeddi, Ahmadreza and Ciccone, Marco and Taati, Babak , year=
-
[58]
Bai, Xingjian and Melas-Kyriazi, Luke , year =. Fixed
-
[59]
Zico , year=
Geng, Zhengyang and Pokle, Ashwini and Kolter, J. Zico , year=. One-
-
[60]
Bae, Sangmin and Fisch, Adam and Harutyunyan, Hrayr and Ji, Ziwei and Kim, Seungyeon and Schuster, Tal , year=. Relaxed
-
[61]
2018 , journal=
Learning Anytime Predictions in Neural Networks via Adaptive Loss Balancing , author=. 2018 , journal=
2018
-
[62]
2026 , journal=
Looping Back to Move Forward: Recursive Transformers for Efficient and Flexible Large Multimodal Models , author=. 2026 , journal=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.